理论恒叨立体匹配系列经典AD-Census: 扫描线优化(Scanline Optimization)
Posted 李迎松~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理论恒叨立体匹配系列经典AD-Census: 扫描线优化(Scanline Optimization)相关的知识,希望对你有一定的参考价值。
下载AD-Census完整源码,点击进入: https://github.com/ethan-li-coding/AD-Census
欢迎同学们在Github项目里讨论,如果觉得博主代码质量不错,右上角star一下!感谢!
AD-Census算法来自于中国学者Xing Mei等在ICCV2011发表的论文《On Building an Accurate Stereo Matching System on Graphics Hardware》1。算法效率高、效果出色,Intel RealSense D400就是基于该算法实现的立体匹配 2。
本系列将带大家深入了解AD-Census的理论,希望能够对同学们的立体匹配算法研究有所帮助。
AD-Census是一个将局部算法和半全局算法相结合的算法,它包含四个步骤:1 初始代价计算、2 代价聚合、3 扫描线优化、4 视差优化。本篇的内容是扫描线优化部分。
Step 1. AD-Census Cost Initialization
Step 2. Cross-based Cost Aggregation
Step 3. Scanline Optimization
Step 4. Multi-step Disparity Refinement
【理论恒叨】【立体匹配系列】经典AD-Census: (3)扫描线优化
如果了解另外一个立体匹配经典算法:SemiGlobalMatching,对扫描线优化肯定是不陌生的,大家可以重温下我前面的博客:
SGM的代价聚合就是使用的扫描线优化思路,而AD-Census的扫描线优化思路正是借鉴于SGM,思路具有高度一致性。
We employ a multi-direction scanline optimizer based on Hirschmuller’s semi-global matching method
做扫描线优化的目的是要进一步提高代价的准确性,减少匹配错误。优化思路和SGM的代价聚合思路一模一样(注意SGM的扫描线优化叫代价聚合,而AD-Census就叫扫描线优化,实际上本质是一样的操作,只是叫法不同而已)。优化的方向数为4,分别是左、右、上、下。
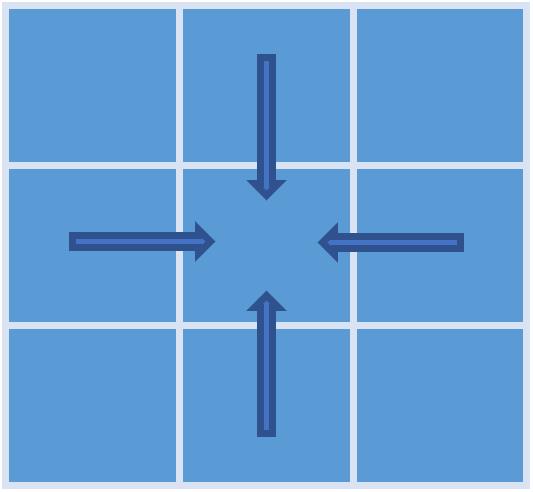
像素 p p p 某一方向 r r r的优化公式为:
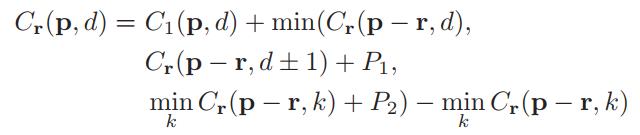
和SGM的公式一样的,如果大家想了解详细,请查看下面贴出的博客地址,这里就不细说了。
AD-Census所做的修改在于 P 1 P_1 P1和 P 2 P_2 P2值的设定方式,在SGM中, P 1 P_1 P1、 P 2 ′ P_2' P2′是预设的固定值,实际使用的 P 2 P_2 P2是根据左视图相邻两个像素的亮度差值而实时调整的,调整公式为 P 2 = P 2 ′ / ( I p − I q ) P_2=P_2'/(I_p-I_q) P2=P2′/(Ip−Iq)。
而在Ad-Census中, P 1 P_1 P1、 P 2 P_2 P2不只是和左视图的相邻像素颜色差 D 1 = D c ( p , p − r ) D_1=D_c(p,p-r) D1=Dc(p,p−r)有关,而且和右视图对应同名点的相邻像素颜色差 D 2 = D c ( p d , p d − r ) D_2=D_c(pd,pd-r) D2=Dc(pd,pd−r)有关。
(注1:AD-Census算法默认输入彩色图,所以是算颜色差,如果是输入灰度图,则是亮度差,颜色差的定义是
D
c
(
p
l
,
p
)
=
m
a
x
i
=
R
,
G
,
B
∣
I
i
(
p
l
)
−
I
i
(
p
)
∣
D_c(p_l,p)=max_i=R,G,B|I_i(p_l)-I_i(p)|
Dc(pl,p)=maxi=R,G,B∣Ii(pl)−Ii(p)∣,即三个颜色分量差值的最大值)
(注2:
p
d
pd
pd 实际就是像素
p
p
p 通过视差
d
d
d 找到的右视图上的同名点
q
=
p
−
d
q=p-d
q=p−d)
(注3:
p
−
r
p-r
p−r代表聚合方向上的上一个像素,比如从左到右聚合,则
p
−
r
p-r
p−r就是
p
−
1
p-1
p−1;从右到左聚合,则
p
−
r
p-r
p−r就是
p
+
1
p+1
p+1)
具体设定规则如下:
- P 1 = Π 1 , P 2 = Π 2 , i f D 1 < τ S O , D 2 < τ S O P_1=Π_1,P_2=Π_2, if D_1<τ_SO,D_2<τ_SO P1=Π1,P2=Π2,ifD1<τSO,D2<τSO
- P 1 = Π 1 / 4 , P 2 = Π 2 / 4 , i f D 1 < τ S O , D 2 > τ S O P_1=Π_1/4,P_2=Π_2/4, if D_1<τ_SO,D_2>τ_SO P1=Π1/4,P2=Π2/4,ifD1<τSO,D2>τSO
- P 1 = Π 1 / 4 , P 2 = Π 2 / 4 , i f D 1 > τ S O , D 2 < τ S O P_1=Π_1/4,P_2=Π_2/4, if D_1>τ_SO,D_2<τ_SO P1=Π1/4,P2=Π2/4,ifD1>τSO,D2<τSO
- P 1 = Π 1 / 10 , P 2 = Π 2 / 10 , i f D 1 > τ S O , D 2 > τ S O P_1=Π_1/10,P_2=Π_2/10, if D_1>τ_SO,D_2>τ_SO P1=Π1/10,P2=Π2/10,ifD1>τSO,D