干货 | Elasticsearch 检索类型选型指南
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货 | Elasticsearch 检索类型选型指南相关的知识,希望对你有一定的参考价值。
之前在 DSL 中一次问卷调查中,收集到如下几个和搜索类型相关的问题。
Q1:麻烦讲一下es常用的查询关键词,及使用场景,比如term、match、should、filter等等,谢谢老大......
Q2:讲下查询term,match,match_pharse,operator,mget,multi_match等的用法和区别?
Q3:term、match、phrase、bool query等常用语法,及对不同类型数据字段的支持。在分词场景下的区别?
Q4:fuzzy查询的fuzziness参数不同取值,minimumshouldmatch不同取值负数,百分比等…...
Q5:希望可以通俗一点。可以有视频和文档~~
这些问题经常会被问到,今天我们从如下几个方面详细解读一下。
宏观俯瞰 Elasticsearch 检索分类;
分类解读各个搜索类型特点及应用场景;
各个检索类型的区别。
1、宏观俯瞰 Elasticsearch 检索分类
以 Elasticsearch 8.1 官方文档为例,检索分类不会也不可能超出这个范围。

这么看,貌似不够清晰,来张脑图梳理一下。
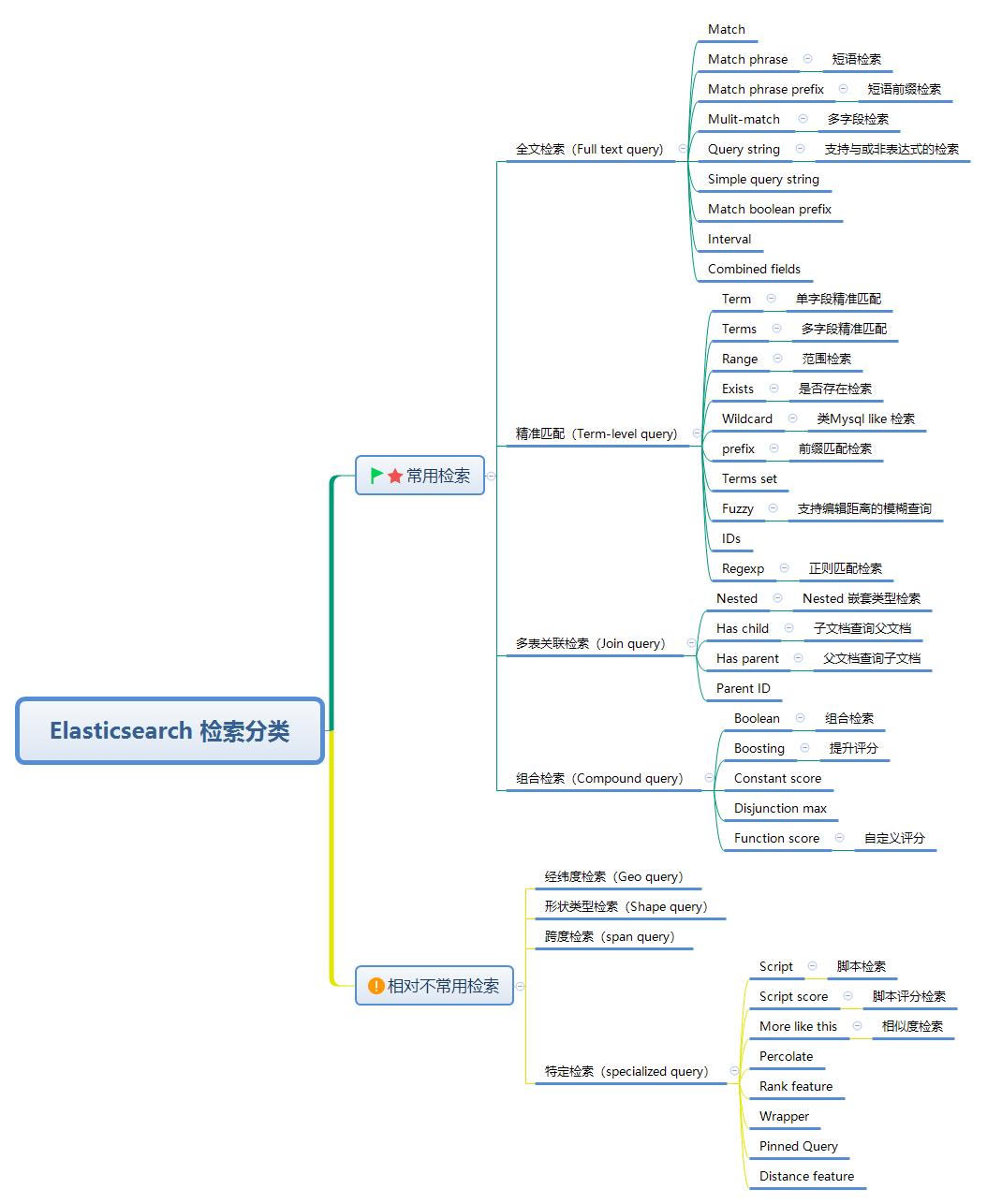
常用的部分下文会详细解读,不常用的建议大家使用前优先阅读一遍官方文档,做到“知己知彼、有的放矢”。
貌似清晰了很多。
说一下,我在初学 Elasticsearch 犯过的“错误”或者遇到的问题,看看大家有没有“中招”。
第一:一把梭用法
Match 检索很好用,召回数据又多。业务凡是涉及检索都是 Match query。
用星爷的话非常应景:“曾经有一堆检索类型放在我面前,我没有珍惜。我挑出 use 最多最爽的 Match query 用的乐此不疲。当召回了一大批不相关的数据才后悔莫及!如果老天再给我一次选型的机会的话,我会优先考虑 Match_phrase"。

图片来自网络
这么说,大家可能没有感觉,后文会有详细示例说明。
第二:自己代码实现“与或非”检索。
由于对于检索类型了解不全,只知道有限的几种类型:term、match、terms等。
不知道 query string 检索类型已经实现了:“AND OR NOT” 与或非检索。
自己实现花了时间不说,也不如 query string 自身实现考虑的全面。
第三:数百个 wildcard 模糊匹配组合导致演示现场集群宕机
这个我在这篇文章有过详细说明,不再赘述。
如上,回头看,出现问题体现在:
检索类型了解不全,拿来就用;
不能分辨不同检索类型的应用场景和可能的副作用;
项目着急只关注了能用,没有关注“用好”、“好用”。
2、精准匹配检索和全文检索的本质区别
本文继续缩小范围,把重心缩小为最常用的:精准匹配检索、全文检索、组合检索三种类型。
精准匹配检索和全文检索的本质区别:
精准匹配把检索的整个文本不做分词处理,当前一个串整体处理。
而全文检索需要分词处理,对分词后的每个词单独检索然后大bool组合检索。
文章后续内容以如下数据示例展开讨论:
PUT test-0415
"mappings":
"properties":
"title":
"type": "text",
"analyzer": "ik_max_word",
"fields":
"keyword":
"type": "keyword"
POST test-0415/_bulk
"index":"_id":1
"title":"乌兰图雅经典歌曲30首连播 标清_手机乐视视频"
"index":"_id":2
"title":"乌兰县地区生产总值22.9亿元 "
"index":"_id":3
"title":"乌兰新闻网欢迎您!"
"index":"_id":4
"title":"乌兰:你说急什么呢,我30岁了"
"index":"_id":5
"title":"千城胜景丨胜境美誉 多彩乌兰"精准匹配和全文检索的区别,如下一例说得清楚:
POST test-0415/_search
"query":
"match":
"title": "乌兰新闻网欢迎您!"
召回数据(只截取了title)如下:

也就是说:检索“乌兰新闻网欢迎您!”召回了全部数据!
为啥?
检索语句加上“profile:true”,一探究竟:
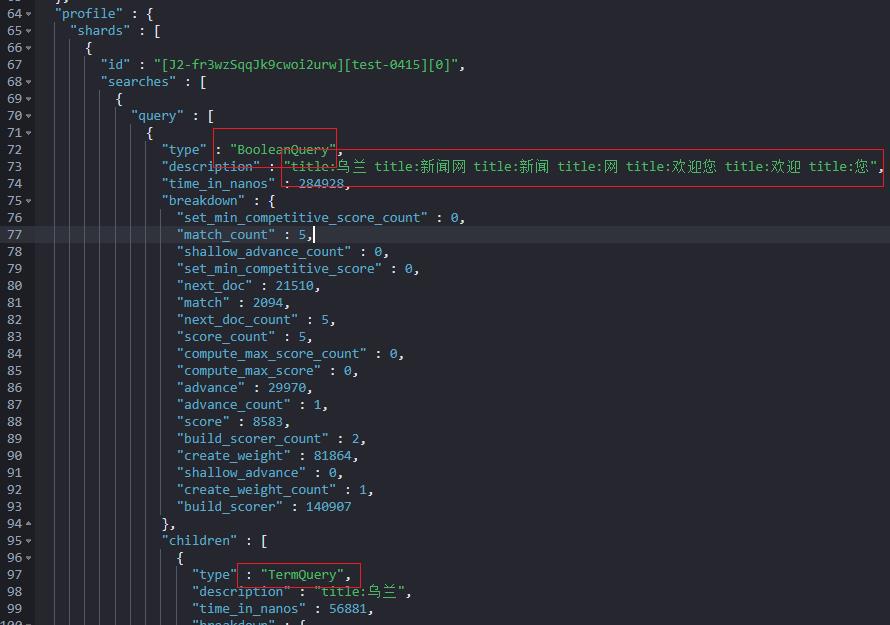
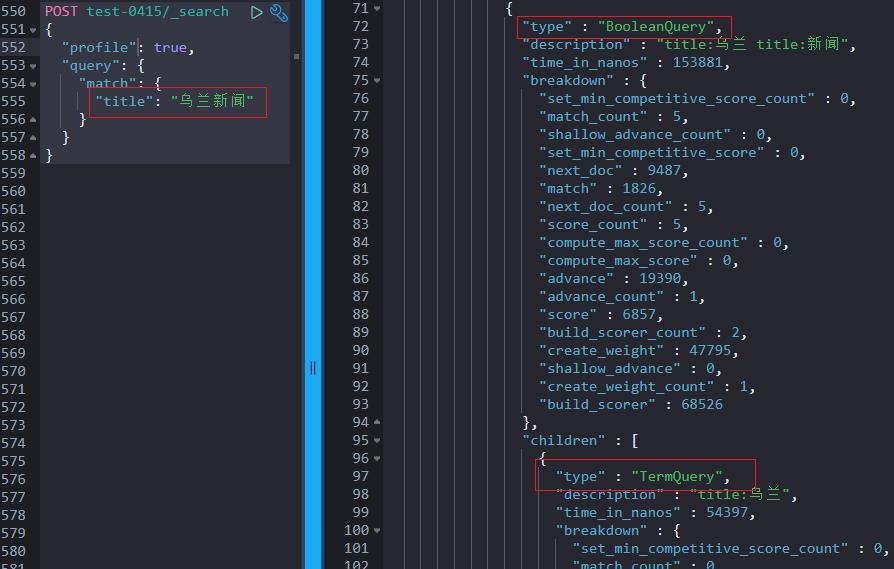
一句话:match_query 在检索的时候将待检索字符串做了分词处理。
如上所示:检索的时候“乌兰新闻网欢迎您”切词后变成 [ “乌兰”, "新闻网", "新闻”,“网”,“欢迎您”, “欢迎”, “您”]。
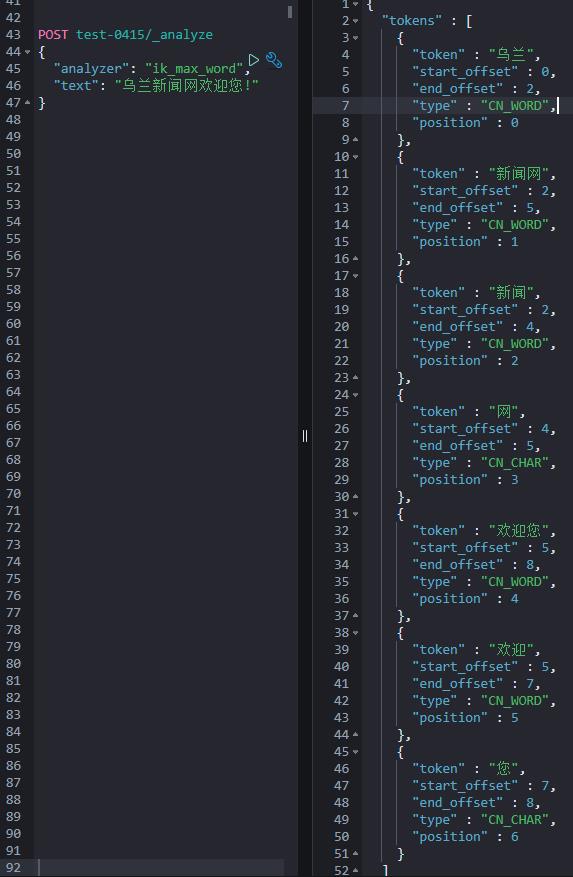
有同学会问,咋分的呢?通过 analyzer API 可以看出。
然后,我们再看一下精准匹配的检索实现。
POST test-0415/_search
"profile": true,
"query":
"term":
"title.keyword": "乌兰新闻网欢迎您!"
profile:true 看到结果如下:
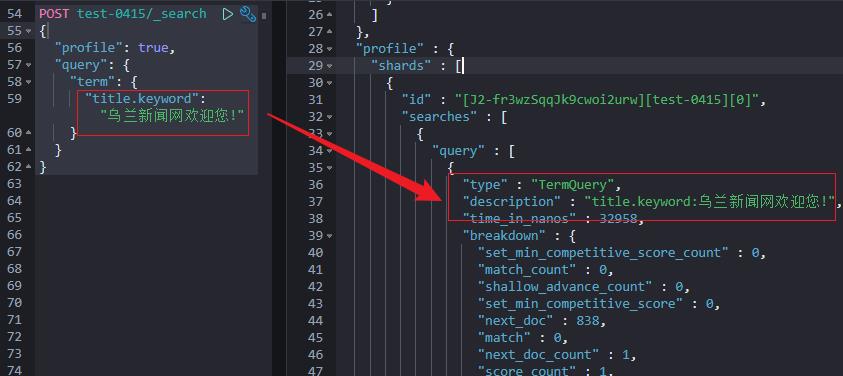
也就是说,精准匹配是拿整个文本串一起 term query检索的,不做分词处理。
有了这个大前提,后面才好理解一些。
接下来,分类解读各个搜索特点及应用场景。
3 精准匹配检索
3.1 Term 单字段精准匹配、
Term query 应用场景:单值精准匹配。
注意点:避免将 term query 应用到 text 类型的检索。
再延伸一些,Term 检索针对的是非 text 类型,term 针对 text 类型并不会报错,但结果会达不到预期。
有同学说:我非要将 text 类型应用 term query会怎么样?来吧,看一下效果:
DELETE my-index-000001
# 不指定分词器就使用默认:standard 分词器。
PUT my-index-000001
"mappings":
"properties":
"full_text":
"type": "text"
# 写入数据
PUT my-index-000001/_doc/1
"full_text": "Quick Brown Foxes!"
# 执行检索,并不会召回数据
GET my-index-000001/_search?pretty
"profile": true,
"query":
"term":
"full_text": "Quick Brown Foxes!"

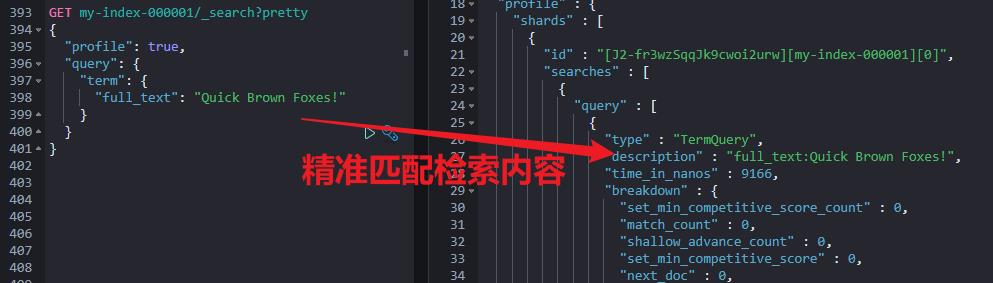
检索结果如上图所示,为啥没有召回结果数据?
原因在于:写入的时候,Quick Brown Foxes! 经过默认分词器 standard 处理后,转化为:quick、brown、foxes 存储。
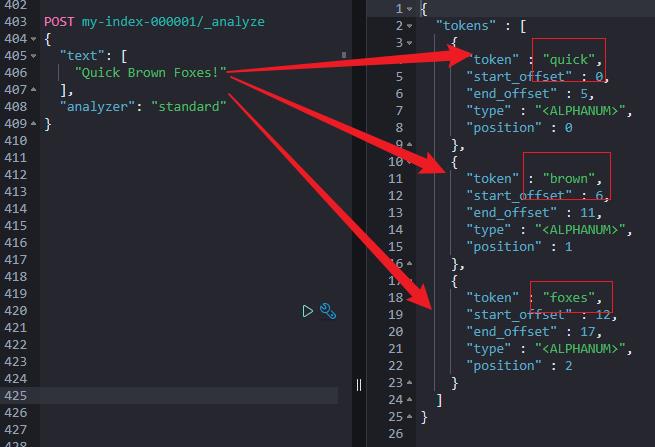
而检索的时候,咱们检索的是:“Quick Brown Foxes”,如下所示。所以:没有数据召回。
3.2 Terms 多字段精准匹配
Terms query 应用场景:多值精准匹配。
注意点:同 term query核心区别:terms query 支持多个值,而 term query 仅支持单个值。
3.3 Range 范围检索
Range query 应用场景:区间范围检索。
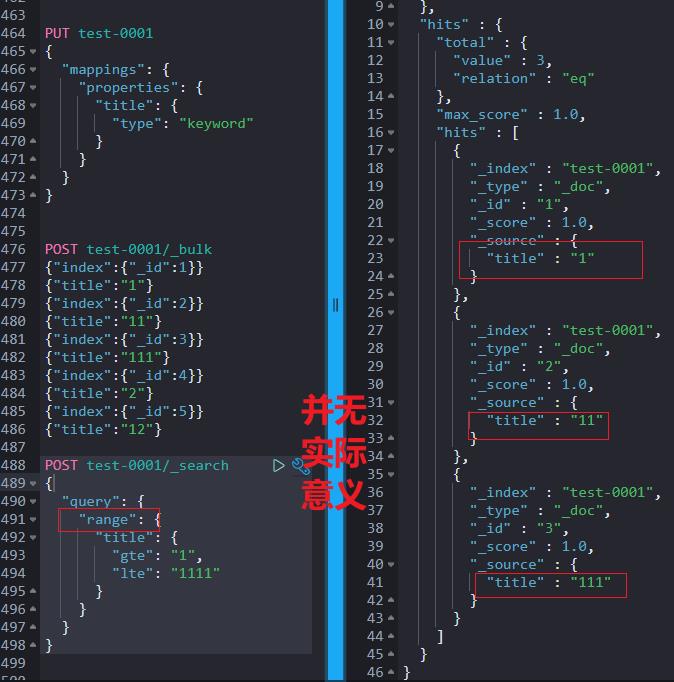
注意点1:当“search.allow_expensive_queries”设置为 false 时,range query 在 text 和 keyword 类型的检索不能被执行。
注意点2:range query 对 text、keyword 类型的区间检索实际意义不大。
3.4 Exists 是否存在检索
Exists query 应用场景:判定字段是否有值。
特例很多,建议参考官方文档,这里仅强调一个:
DELETE test-0001
PUT test-0001
"mappings":
"properties":
"title":
"type": "text",
"index": false
POST test-0001/_bulk
"index":"_id":1
"title":"1"
POST test-0001/_search
"profile": true,
"query":
"exists":
"field": "title"
如上的 exists query 本质上走的是:“ConstantScore(NormsFieldExistsQuery [field=title])“ 检索,由于 title 字段没有被索引,所以没有结果召回。
3.5 Wildcard 类mysql like 检索
Wildcard 应用场景:通配符检索,类似 MySQL like 查询。
注意:非必要,不使用。看下面截图就知道原因。

推荐阅读:Elasticsearch 警惕使用 wildcard 检索!然后呢?
3.6 prefix 前缀匹配检索
prefix Query应用场景:前缀匹配。
先看一个社区实战问题:https://elasticsearch.cn/question/12595
比如我有3个文档,采用ik_max_word分词。
1. 考试专题
2. 测试考试成绩
3. 新动能考试如何做到真正的前缀搜索?
prefix 可以搞定,针对 keyword 类型才可以。
DELETE test0416
PUT test0416
"mappings":
"properties":
"title":
"type": "text",
"analyzer": "ik_max_word",
"fields":
"keyword":
"type": "keyword"
POST test0416/_bulk
"index":"_id":1
"title":"考试专题"
"index":"_id":2
"title":"测试考试成绩题"
"index":"_id":3
"title":"新动能考试"
POST test0416/_search
"query":
"prefix":
"title.keyword":
"value": "考试"
3.7 Terms set 检索
Terms set Query 应用场景:term query 检索 1个满足条件,terms query检索多个满足条件,而 Terms set query 介于两者中间。
3.8 Fuzzy 支持编辑距离的模糊查询
Fuzzy Query 应用场景:返回包含与搜索词相似的词的文档,也就是说:有一定的类似纠错功能。
3.9 IDs 检索
IDS query:基于 ID 组召回数据。
3.10 Regexp 正则匹配检索
Regexp Query:基于正则表达式的检索。
使用建议:非必要不使用。
4、全文检索类型
4.1 Match 检索
Match Query 应用场景:召回率要求高、精准度要求不高的场景。
使用建议:精准度要求高的场景慎用。
如前所述,Match 的本质:大 bool + term query 组合体。
4.2 Match phrase 短语检索
Match phrase Query 应用场景:更注重精准度召回的场景,match query 如果叫做分词检索的话,match phrase 叫短语匹配检索更为合适。
注意1:检索的时候可以指定分词器。
注意2:分词器指定不同,拼接的串中字符的切分粒度不同。
如下两个截图分别使用了:standard 标准分词器以及 ik_smart 粗粒度 IK 分词器。
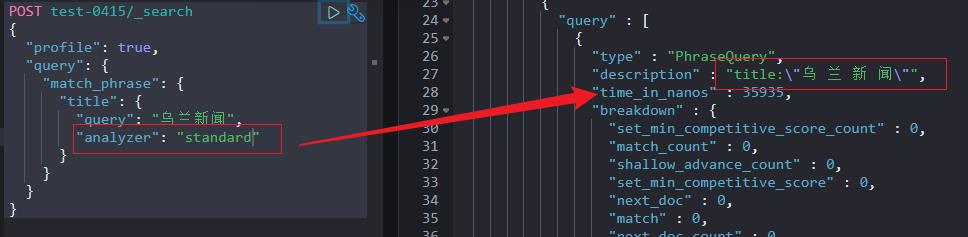
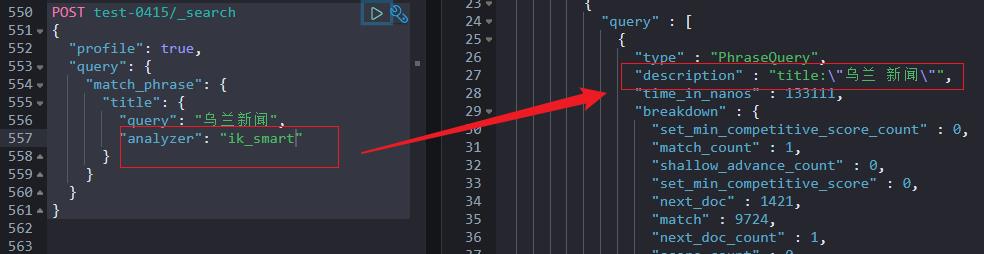
4.3 Multi-match 检索
Multi-match query 应用场景:多字段的 match query。
注意:多字段就涉及评分的整合,所以会有:most_fields、best_fields、cross_fields 等评分方式。
4.4 Match_phrase_prefix 检索
Match_phrase_prefix query 应用场景:短语匹配+前缀匹配的组合体,适用于短语前缀匹配。
如下所示:
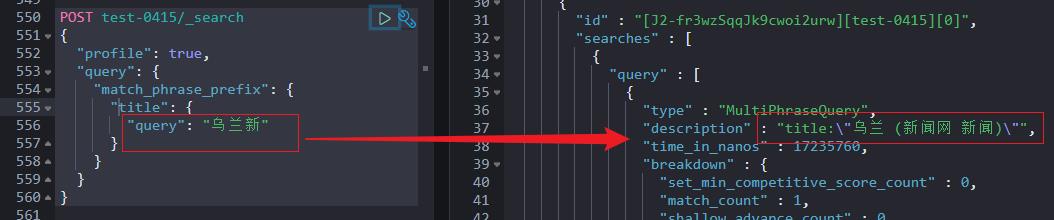
个人认为,新闻、新闻网是根据已有文本的 IK 分词(写入时指定的分词器 ik_max_word)的结果。
4.5 query_string 检索
query_string query 应用场景:与或非表达式的检索。
AND:代表与,OR 代表或,NOT 代表非。
非常复杂的语法,建议参考官方文档。
4.6 simple_query_string 检索
simple_query_string 应用场景:同 query_string 。
核心不同点:simple_query_string 在语法不对时,并不会报错。

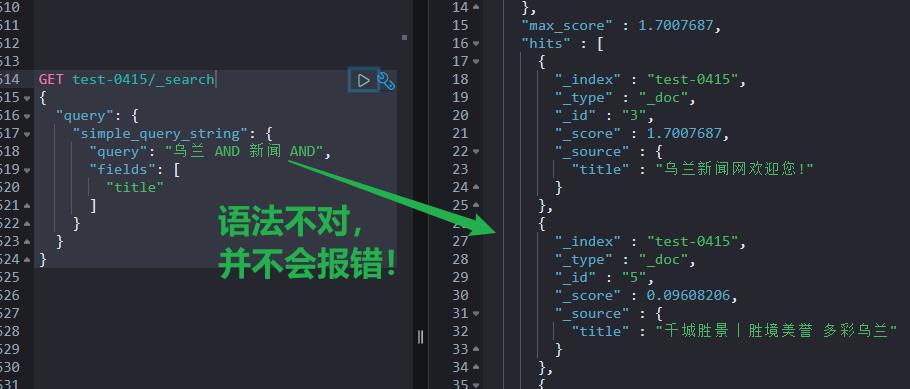
还有几种:Intervals query、Match boolean prefix query、Combined fields query,应用场景相对受限,我没有展开,大家根据官方文档选型即可。
5 组合检索类型
如果把上文的“精准匹配检索”和“全文检索”比作单兵种作战,那么组合检索就可以看做“海陆空”全方位作战。
组合检索主要分为两大类:bool 组合检索和自定义评分检索。
5.1 bool 组合检索
适用场景:复杂条件的组合检索。当单个或者单类检索条件不能适配复杂组合检索的时候,优先考虑 bool 组合条件检索。
其下可以包含但不限于:
must:必须满足条件。
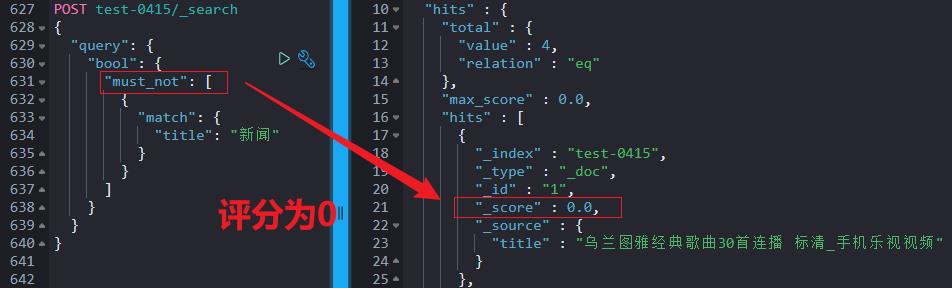
must_not:必须不满足条件(忽略评分,召回数据评分为0)。
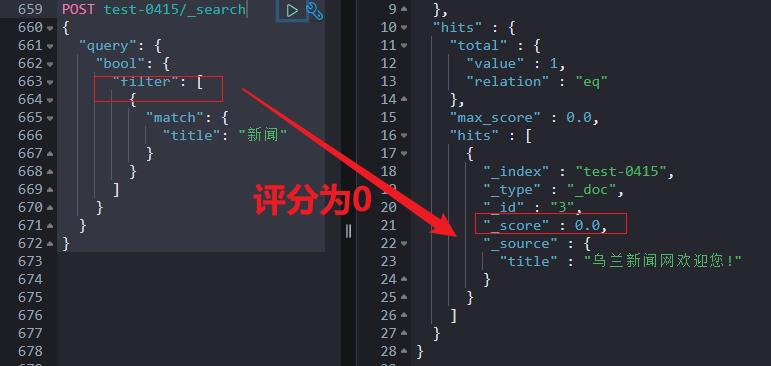
filter:过滤条件(忽略评分,召回数据评分为0),可以借助缓存提升性能。
should:部分条件满足,由minmum_should_match控制。
5.2 自定义评分检索
适用场景:传统基于BM25(词频TF、逆文档频率IDF)机制不能满足评分要求,某一个或者多个字段需要提升、降低或者修改权重比例的时候,优先考虑自定义评分实现。
如果自定义评分也无法满足,那只能自己开发评分插件实现。
自定义评分推荐阅读:实战 | Elasticsearch自定义评分的N种方法
6、总结
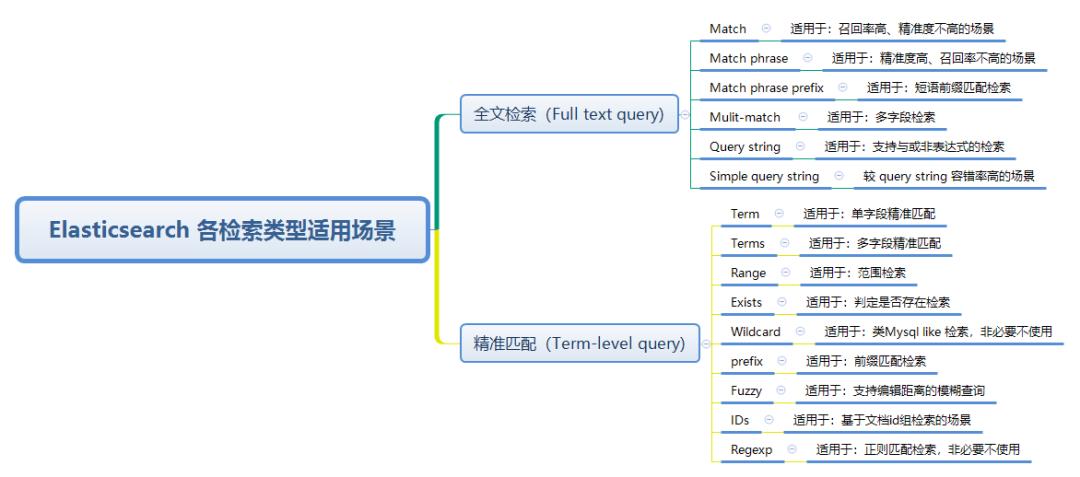
说到这里,开篇问题基本都能回答上了。检索类型选型流程参考如下:

全文检索(Full text query)类检索
- Match 适用于:召回率高、精准度不高的场景;
- Match phrase 适用于:精准度高、召回率不高的场景;
- Match phrase prefix 适用于:短语前缀匹配检索;
- Mulit-match 适用于:多字段检索;
- Query string 适用于:支持与或非表达式的检索;
- Simple query string:较 query string 容错率高的场景;
精准匹配(Term-level query)类检索
- Term 适用于:单字段精准匹配;
- Terms 适用于:多字段精准匹配;
- Range 适用于:范围检索;
- Exists 适用于:判定是否存在检索;
- Wildcard 适用于:类Mysql like 检索,非必要不使用;
- prefix 适用于:前缀匹配检索;
- Fuzzy 适用于:支持编辑距离的模糊查询;
- IDs 适用于:基于文档id组检索的场景;
- Regexp 适用于:正则匹配检索,非必要不使用。
大家有好的选型意见和建议,欢迎留言讨论。
参考
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html
推荐
1、重磅 | 死磕 Elasticsearch 方法论认知清单(2021年国庆更新版)
2、如何从0到1打磨一门 Elasticsearch 线上直播课?(口碑不错)

更短时间更快习得更多干货!
和全球 1600+ Elastic 爱好者一起精进!

比同事抢先一步学习进阶干货!
以上是关于干货 | Elasticsearch 检索类型选型指南的主要内容,如果未能解决你的问题,请参考以下文章