『MongoDB』MongoDB高可用部署架构——分片集群篇(Sharding)
Posted 老陈聊架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了『MongoDB』MongoDB高可用部署架构——分片集群篇(Sharding)相关的知识,希望对你有一定的参考价值。

📣读完这篇文章里你能收获到
- 为什么要使用分片
- Mongodb分片集群有哪些特点
- Mongodb分片集群的完整架构
- Mongodb分片集群数据分布方式
- Mongodb分片集群的设计思路
- Mongodb分片集群搭建及扩容
- 这篇文章强烈建议收藏!!!免得下次找不到
文章目录
一、初识分片集群
- 基础概念本文就不讲了,百度百科了解即可
1 为什么要使用分片集群
- 数据容量日益增大,访问性能日渐降低,怎么破?
- 新品上线异常火爆,如何支撑更多的并发用户?
- 单库已有 10TB 数据,恢复需要1-2天,如何加速?
- 地理分布数据
2 分片如何解决[案例]
- 银行交易单表内10亿笔资料 超负荷运转

- 把数据分成两半,放到2个库物理里
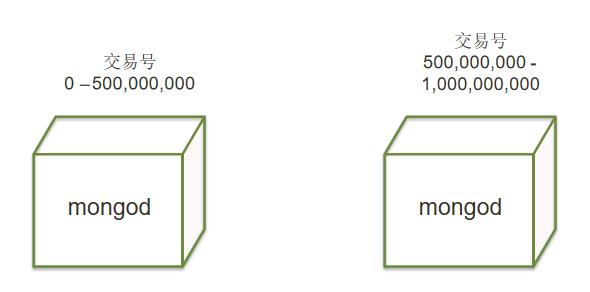
- 把数据分成4部分,放到4个物理库里(以此类推)

3 MongoDB 分片集群有哪些特点
- 应用全透明,无特殊处理
- 数据自动均衡
- 动态扩容,无须下线
- 提供三种分片方式
二、Mongodb分片集群架构解剖
1 完整的分片集群

2 分片集群解剖:路由节点 mongos(Router)
- 路由节点
- 提供集群单一入口转发应用端请求
- 选择合适数据节点进行读写合并多个数据节点的返回
- 无状态
- 建议至少2个

3 分片集群解剖:配置节点 Config
- 配置(目录)节点
- 提供集群元数据存储分片数据分布的映射
- 普通复制集架构

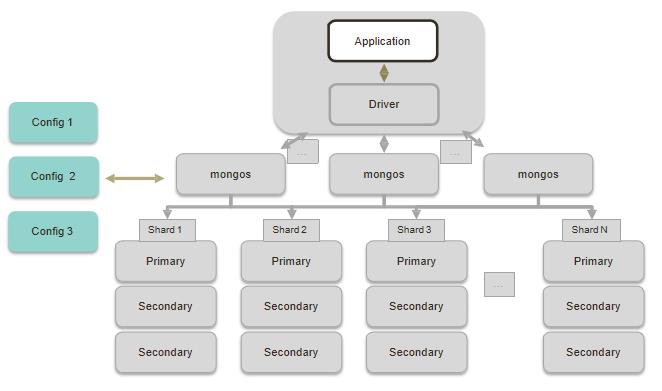
4 分片集群解剖:数据节点 Shard
- 数据节点
- 以复制集为单位横向扩展
- 最大1024分片
- 分片之间数据不重复所有分片在一起才可完整工作

三、Mongodb分片集群数据分布方式
1 分片集群数据分布方式 – 基于范围


2 分片集群数据分布方式 – 基于哈希


3 分片集群数据分布方式 – 自定义Zone(区域/范围)

四、分片集群设计-如何用好分片集群
- 分片集群可以有效解决性能瓶颈及系统扩容问题
- 分片额外消耗较多,管理复杂,能不分片尽量不要分片
1 合理的架构

1.1 合理的架构 – 分片大小
- 分片的基本标准:
-
关于数据:数据量不超过3TB,尽可能保持在2TB一个片
-
关于索引:常用索引必须容纳进内存
- 按照以上标准初步确定分片后,还需要考虑业务压力,随着压力增大,CPU、RAM、磁盘中的任何一项出现瓶颈时,都可以通过添加更多分片来解决
1.2 合理的架构 – 需要多少个分片
- A = 所需存储总量 / 单服务器可挂载容量
- B = 工作集大小 / (单服务器内存容量 * 0.6)
- C = 并发量总数 / (单服务器并发量 * 0.7)
- 分片数量 = max(A, B, C)
举例:
所需存储总量8TB
单服务器可挂载容量 2TB
工作集大小 400GB
单服务器内存容量 256GB
并发量总数 30000
单服务器并发量 9000
除了单服务器并发量需要实际压测外,其余均可预估
A = 8TB / 2TB = 4
B = 400GB / (256G * 0.6) = 3
C = 30000 / (9000*0.7) = 6
分片数量 = max(A, B, C) = 6
1.3 合理的架构 – 其他需求
- 考虑分片的分布:
-
是否需要跨机房分布分片?
-
是否需要容灾?
-
高可用的要求如何?
2 正确的姿势

- 各种概念由小到大:
-
片键 shard key:文档中的一个字段
-
文档 doc :包含 shard key 的一行数据
-
块 Chunk :包含 n 个文档
-
分片 Shard:包含 n 个 chunk
-
集群 Cluster: 包含 n 个分片

2.1 正确的姿势 - 选择合适片键
- 影响片键效率的主要因素:
- 取值基数(Cardinality)
- 取值分布
- 分散写,集中读
- 被尽可能多的业务场景用到
- 避免单调递增或递减的片键
2.2 正确的姿势 - 选择基数大的片键
- 对于小基数的片键:
-
因为备选值有限,那么块的总数量就有限
-
随着数据增多,块的大小会越来越大
-
水平扩展时移动块会非常困难
-
例如:存储一个高中的师生数据,以年龄(假设年龄范围为15~65岁)作为片键,那么:15<=年龄<=65,且只为整数最多只会有51个 chunk
-
结论:取值基数要大!
2.3 正确的姿势 – 选择分布均匀的片键
- 对于分布不均匀的片键:
- 造成某些块的数据量急剧增大
- 这些块压力随之增大
- 数据均衡以 chunk 为单位,所以系统无能为力
-
例如:存储一个学校的师生数据,以年龄(假设年龄范围为1565岁)作为片键,那么:15<=年龄<=65,且只为整数,大部分人的年龄范围为1518岁(学生)
15、16、17、18四个 chunk 的数据量、访问压力远大于其他 chunk -
结论:取值分布应尽可能均匀
3 足够的资源

-
mongos 与 config 通常消耗很少的资源,可以选择低规格虚拟机
-
资源的重点在于 shard 服务器:
-
需要足以容纳热数据索引的内存
-
正确创建索引后 CPU 通常不会成为瓶颈,除非涉及非常多的计算
-
磁盘尽量选用 SSD
-
最后,实际测试是最好的检验,来看你的资源配置是否完备
-
即使项目初期已经具备了足够的资源,仍然需要考虑在合适的时候扩展。建议监控各项资源使用情况,无论哪一项达到
60%以上,则开始考虑扩展,因为:
- 扩展需要新的资源,申请新资源需要时间
- 扩展后数据需要均衡,均衡需要时间。应保证新数据入库速度慢于均衡速度
- 均衡需要资源,如果资源即将或已经耗尽,均衡也是会很低效的
五、分片集群搭建及扩容
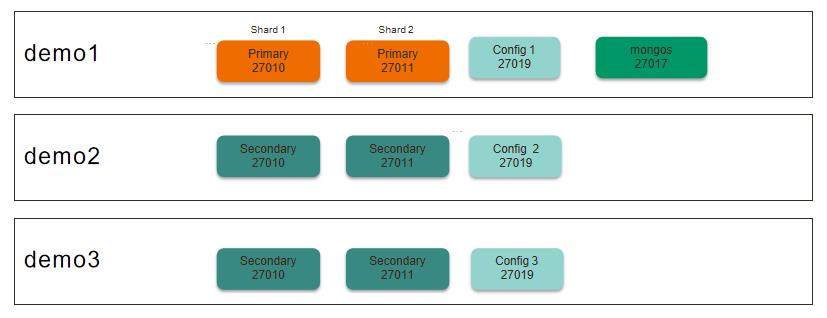
1 目标及流程
-
目标:学习如何搭建一个2分片的分片集群
-
环境:3台 Linux 虚拟机, 4 Core 8 GB
-
步骤:

2 实验架构

3 开始搭建
3.1 配置域名解析
- 在3台虚拟机上分别执行以下3条命令,注意替换实际 IP 地址
echo "192.168.1.1 demo1 member1.example.com member2.example.com" >> /etc/hosts
echo "192.168.1.2 demo2 member3.example.com member4.example.com" >> /etc/hosts
echo "192.168.1.3 demo3 member5.example.com member6.example.com" >> /etc/hosts
3.2 准备分片目录
- 在各服务器上创建数据目录,我们使用
/data,请按自己需要修改为其他目录:
在member1 / member3 / member5 上执行以下命令:
mkdir -p /data/shard1/ mkdir -p /data/config/
在member2 / member4 / member6 上执行以下命令:
mkdir -p /data/shard2/ mkdir -p /data/mongos/
3.3 创建第一个分片用的复制集
在 member1 / member3 / member5 上执行以下命令:
mongod --bind_ip 0.0.0.0 --replSet shard1 --dbpath /data/shard1 --logpath
/data/shard1/mongod.log --port 27010 --fork --shardsvr --wiredTigerCacheSizeGB 1
3.4 初始化第一个分片复制集
mongo --host member1.example.com:27010 rs.initiate(
_id: "shard1",
"members": [
"_id": 0,
"host": "member1.example.com:27010"
,
"_id": 1,
"host": "member3.example.com:27010"
,
"_id": 2,
"host": "member5.example.com:27010"
]
);
3.5 创建 config server 复制集
- 在 member1 / member3 / member5 上执行以下命令:
mongod --bind_ip 0.0.0.0 --replSet config --dbpath /data/config --logpath
/data/config/mongod.log --port 27019 --fork --configsvr --wiredTigerCacheSizeGB 1
3.6 初始化 config server 复制集
# mongo --host member1.example.com:27019 rs.initiate(
_id: "config",
"members": [
"_id": 0,
"host": "member1.example.com:27019"
,
"_id": 1,
"host": "member3.example.com:27019"
,
"_id": 2,
"host": "member5.example.com:27019"
]
);
3.7 在第一台机器上搭建 mongos
# mongos --bind_ip 0.0.0.0 --logpath /data/mongos/mongos.log --port 27017 --fork
--configdb config/member1.example.com:27019,member3.example.com:27019,member5.example.com:27019
# 连接到mongos, 添加分片
# mongo --host member1.example.com:27017
mongos > sh.addShard("shard1/member1.example.com:27010,member3.example.com:27010,member5
.example.com:27010");
3.8 创建分片表
# 连接到mongos, 创建分片集合
# mongo --host member1.example.com:27017
mongos > sh.status()
mongos > sh.enableSharding("foo");
mongos > sh.shardCollection("foo.bar", _id: 'hashed'); mongos > sh.status();
# 插入测试数据
use foo
for (var i = 0; i < 10000; i++) db.bar.insert(i: i);
3.9 创建第2个分片的复制集
- 在 member2 / member4 / member6 上执行以下命令:
mongod --bind_ip 0.0.0.0 --replSet shard2 --dbpath /data/shard2
--logpath /data/shard2/mongod.log --port 27011 --fork --shardsvr
--wiredTigerCacheSizeGB 1
3.10 初始化第二个分片的复制集
# mongo --host member2.example.com:27011
mongo --host member1.example.com:27010 rs.initiate(
_id: "shard2",
"members": [
"_id": 0,
"host": "member2.example.com:27011"
,
"_id": 1,
"host": "member4.example.com:27011"
,
"_id": 2,
"host": "member6.example.com:27011"
]
);
3.11 加入第2个分片
# 连接到mongos, 添加分片
# mongo --host member1.example.com:27017
mongos > sh.addShard("shard2/member2.example.com:27011,member4.example.com:27011,member6.example.com:27011");
mongos > sh.status()
如何利用MongoDB实现高性能,高可用的双活应用架构?
投资界有一句至理名言——“不要把鸡蛋放在同一个篮子里”。说的是投资需要分解风险,以免孤注一掷失败之后造成巨大的损失。
随着企业服务窗口的不断增加,业务中断对很多企业意味着毁灭性的灾难,因此,跨多个数据中心的应用部署成为了当下最热门的话题之一。
如今,在跨多个数据中心的应用部署最佳实践中,数据库通常负责处理多个地理区域的读取和写入,对数据变更的复制,并提供尽可能高的可用性、一致性和持久性。
但是,并非所有的技术在选择上都是平等的。例如,一种数据库技术可以提供更高的可用性保证,却同时只能提供比另一种技术更低的数据一致性和持久性保证。
本文先分析了在现代多数据中心中应用对于数据库架构的需求。随后探讨了数据库架构的种类及优缺点,最后专门研究 MongoDB 如何适用于这些类别,并最终实现双活的应用架构。
双活的需求
当组织考虑在多个跨数据中心(或区域云)部署应用时,他们通常会希望使用“双活”的架构,即所有数据中心的应用服务器同时处理所有的请求。
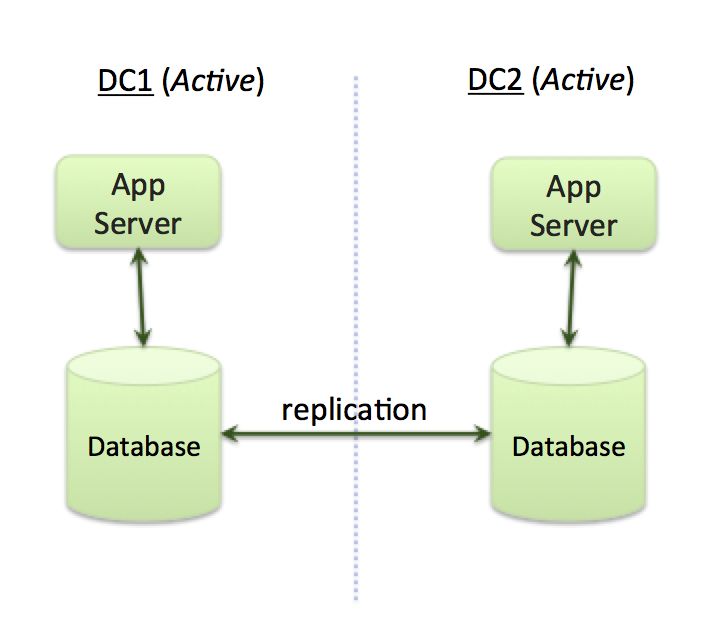
图 1:“双活”应用架构
如图 1 所示,该架构可以实现如下目标:
通过提供本地处理(延迟会比较低),为来自全球的请求提供服务。
即使出现整个区域性的宕机,也能始终保持高可用性。
通过对多个数据中心里服务器资源的并行使用,来处理各类应用请求,并达到最佳的平台资源利用率。
“双活”架构的替代方案是由一个主数据中心(区域)和多个灾备(DR)区域(如图 2 所示)所组成的主-DR(也称为主-被)架构。
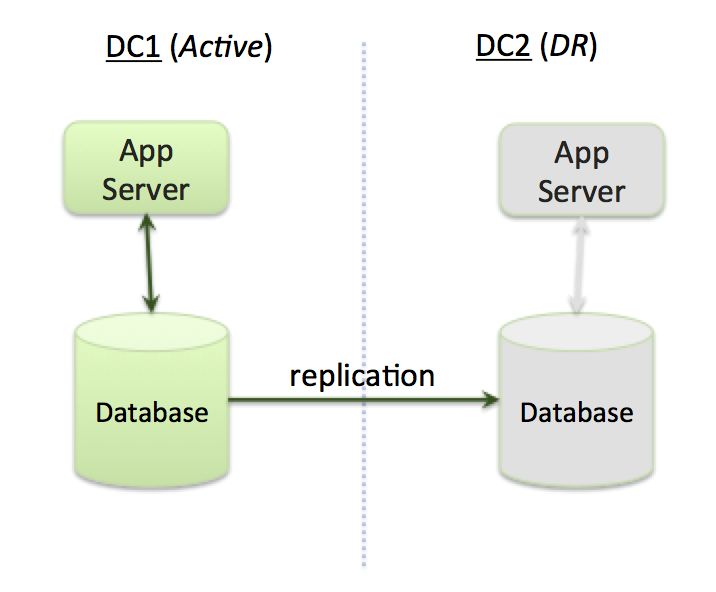
图 2:主-DR 架构
在正常运行条件下,主数据中心处理请求,而 DR 站点处于空闲状态。如果主数据中心发生故障,DR 站点立即开始处理请求(同时变为活动状态)。
一般情况下,数据会从主数据中心复制到 DR 站点,以便在主数据中心出现故障时,能够迅速实施接管。
如今,对于双活架构的定义尚未得到业界的普遍认同,上述主-DR 的应用架构有时也被算作“双活”。
区别在于从主站到 DR 站点的故障转移速度是否够快(通常为几秒),并且是否能够自动化(无需人为干预)。在这样的解释中,双活体系架构意味着应用停机时间接近于零。
有一种常见的误解,认为双活的应用架构需要有多主数据库。这样理解是错误的,因为它曲解了多个主数据库对于数据一致性和持久性的把握。
一致性确保了能读取到先前写入的结果,而数据持久性则确保了提交的写入数据能够被永久保存,不会产生冲突写入;或是由于节点故障所产生的数据丢失。
双活应用的数据库需求
在设计双活的应用架构时,数据库层必须满足如下四个方面的架构需求(当然,也要具备标准数据库的功能,如具有:丰富的二级索引能力的查询语言,低延迟地访问数据,本地驱动程序,全面的操作工具等):
性能,低延迟读取和写入操作。这意味着:能在本地数据中心应用的节点上,处理读取和写入操作。
数据持久性,通过向多个节点的复制写入来实现,以便在发生系统故障时,数据能保持不变。
一致性,确保能读取之前写入的结果,而且在不同地区和不同节点所读到的结果应该相同。
可用性,当某个节点、数据中心或网络连接中断时,数据库必须能继续运行。另外,从此类故障中恢复的时间应尽可能短,一般要求是几秒钟。
分布式数据库架构
针对双活的应用架构,一般有三种类型的数据库结构:
使用两步式提交的分布式事务。
多主数据库模式,有时也被称为“无主库模式”。
分割(分片)数据库具有多个主分片,每个主分片负责数据的某个唯一片区。
下面让我们来看看每一种结构的优缺点。
两步式提交的分布式事务
分布式事务方法是在单次事务中更新所有包含某个记录的节点,而不是写完一个节点后,再(异步)复制到其他节点。
该事务保证了所有节点都会接收到更新,否则如果某个事务失败,则所有节点都恢复到之前的状态。
虽然两步式提交协议可以确保持久性和多节点的一致性,但是它牺牲了性能。
两步式提交协议要求在事务中所有参与的节点之间都要进行两步式的通信。即在操作的每个阶段,都要发送请求和确认,以确保每个节点同时完成了相同的写入。
当数据库节点分布在多个数据中心时,会将查询的延迟从毫秒级别延长到数秒级别。
而在大多数应用,尤其是那些客户端是用户设备(移动设备、Web 浏览器、客户端应用等)的应用中,这种响应级别是不可接受的。
多主数据库
多主数据库是一种分布式的数据库,它允许某条记录只在多个群集节点中一个之上被更新。而写操作通常会复制该记录到多个数据中心的多个节点上。
从表面上看,多主数据库应该是实现双活架构的理想方案。它使得每个应用服务器都能不受限地读取和写入本地数据的副本。但是,它在数据一致性上却有着严重的局限性。
由于同一记录的两个(或更多)副本可能在不同地点被不同的会话同时更新。这就会导致相同的记录会出现两个不同的版本,因此数据库(有时是应用本身)必须通过解决冲突来解决不一致的问题。
常用的冲突解决策略是:最近的更新“获胜”,或是具有更多修改次数的记录“获胜”。因为如果使用其他更为复杂的解决策略,则性能上将受到显著的影响。
这也意味着,从进行写入到完成冲突解决机制的这个时间段内,不同的数据中心会读取到某个相同记录的不同值和冲突值。
分区(分片)数据库
分区数据库将数据库分成不同的分区,或称为分片。每个分片由一组服务器来实现,而每个服务器都包含一份分区数据的完整副本。这里关键在于每个分片都保持着对数据分区的独有控制权。
对于任何给定时间内的每个分片来说,由一台服务器充当主服务器,而其他服务器则充当其副本。数据的读取和写入被发布到主数据库上。
如果主服务器出于任何原因的(例如硬件或网络故障)失败,则某一台备用服务器会自动接任为主服务器的角色。
数据库中的每条记录都属于某个特定的分区,并由一个分片来进行管理,以确保它只会被主分片进行写入。分片内的记录映射到每个分片的一个主分片,以确保一致性。
由于集群内包含多个分片,因此会有多个主分片(多个主分区),因此这些主分片可以被分配到不同的数据中心,以确保都在每个数据中心的本地都能发生写入操作,如图 3 所示:
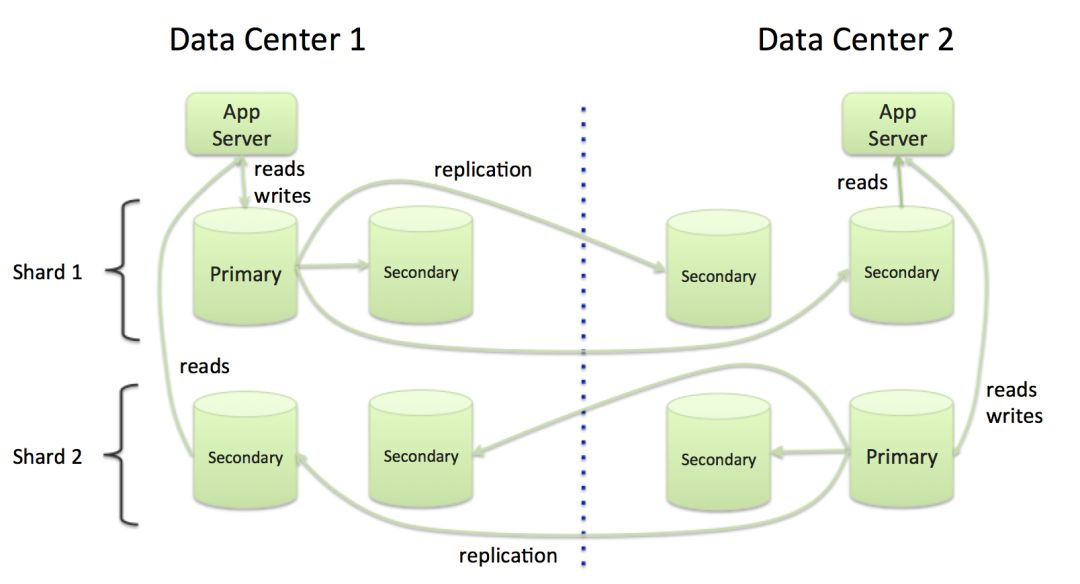
图 3:分区数据库
分片数据库可用于实现双活的应用架构,其方法是:至少部署与数据中心一样多的分片,并为分片分配主分片,以便每个数据中心至少有一个主分片,如图 4 所示:
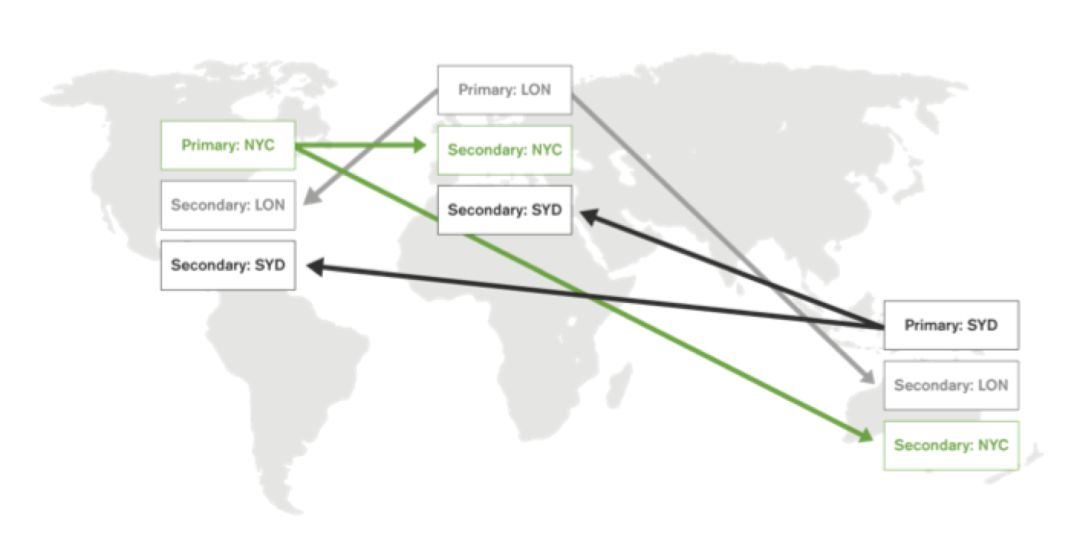
图 4:具有分片数据库的双活架构
另外,通过配置分片能保证每个分片在各种数据中心里至少有一个副本(数据的副本)。
例如,图 4 中的图表描绘了跨三个数据中心的分布式数据库架构:
纽约(NYC)
伦敦(LON)
悉尼(SYD)
群集有三个分片,每个分片有三个副本:
NYC 分片在纽约有一个主分片,在伦敦和悉尼有副本。
LON 分片在伦敦有一个主分片,在纽约和悉尼有副本。
SYD 分片在悉尼有一个主分片,在伦敦和纽约有副本。
通过这种方式,每个数据中心都有来自所有分片的副本,因此本地应用服务器可以读取整个数据集和一个分片的主分片,以便在其本地进行写入操作。
分片数据库能满足大多数使用场景的一致性和性能要求。由于读取和写入发生在本地服务器上,因此性能会非常好。
从主分片中读取时,由于每条记录只能分配给一个主分片,因此保证了一致性。
例如:我们在美国的新泽西州和俄勒冈州有两个数据中心,那么我们可以根据地理区域(东部和西部)来分割数据集,并将东海岸用户的流量路由到新泽西州的数据中心。
因为该数据中心包含的是主要用于东部的分片;并将西海岸用户的流量路由到俄勒冈州数据中心,因为该数据中心包含的是主要用于西部的分片。
我们可以看到分片的数据库为我们提供了多个主数据库的所有好处,而且避免了数据不一致所导致的复杂性。
应用服务器可以从本地主服务器上进行读取和写入,由于每个主服务器拥有各自的记录,因此不会出现任何的不一致。相反,多主数据库的解决方案则可能会造成数据丢失和读取的不一致。
数据库架构比较
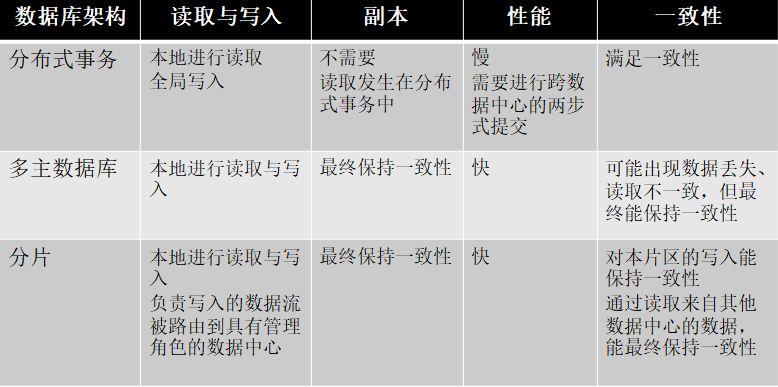
图 5:数据库架构比较
图 5 提供了每一种数据库架构在满足双活应用需求时所存在的优缺点。在选择多主数据库和分区数据库时,其决定因素在于应用是否可以容忍可能出现的读取不一致和数据的丢失问题。
如果答案是肯定的,那么多主数据库可能会稍微容易部署些。而如果答案是否定的,那么分片数据库则是最好的选择。
由于不一致性和数据丢失对于大多数应用来说都是不可接受的,因此分片数据库通常是最佳的选择。
MongoDB 双活应用
MongoDB 是一个分片数据库架构的范例。在 MongoDB 中,主服务器和次服务器集的构造被称为副本集。副本集为每个分片提供了高可用性。
一种被称为区域分片(Zone Sharding)的机制被配置为:由每个分片去管理的数据集。如前面所提到的,ZoneSharding 可以实现地域分区。
白皮书《MongoDB多数据中心部署》:
https://www.mongodb.com/collateral/mongodb-multi-data-center-deployments?utm_medium=dzone-synd&utm_source=dzone&utm_content=active-application&jmp=dzone-ref
Zone Sharding 相关文档:
https://docs.mongodb.com/manual/tutorial/sharding-segmenting-data-by-location/的“分区(分片)数据库”部分描述了 MongoDB 具体实现和运作的细节。
其实许多组织,包括:Ebay、YouGov、Ogilvyand Maher 都正在使用 MongoDB 来实现双活的应用架构。
除了标准的分片数据库功能之外,MongoDB 还提供对写入耐久性和读取一致性的细粒度控制,并使其成为多数据中心部署的理想选择。对于写入,我们可以指定写入关注(write concern)来控制写入的持久性。
Writeconcern 使得应用在 MongoDB 确认写入之前,就能指定写入的副本数量,从而在一个或多个远程数据中心内的服务器上完成写入操作。籍此,它保证了在节点或数据中心发生故障时,数据库的变更不会被丢失。
另外,MongoDB 也补足了分片数据库的一个潜在缺点:写入可用性无法达到 100%。
由于每条记录只有一个主节点,因此如果该主节点发生故障,则会有一段时间不能对该分区进行写入。
MongoDB 通过多次尝试写入,大幅缩短了故障切换的时间。通过多次尝试的写入操作,MongoDB 能够自动应对由于网络故障等暂时性系统错误而导致的写入失败,因此也大幅简化了应用的代码量。
MongoDB 的另一个适合于多数据中心部署的显著特征是:MongoDB 自动故障切换的速度。
当节点或数据中心出现故障或发生网络中断时,MongoDB 能够在 2-5 秒内(当然也取决于对它的配置和网络本身的可靠性)进行故障切换。
发生故障后,剩余的副本集将根据配置去选择一个新的主切片和 MongoDB 驱动程序,从而自动识别出新的主切片。一旦故障切换完成,其恢复进程将自动履行后续的写入操作。
对于读取,MongoDB 提供了两种功能来指定所需的一致性级别。
首先,从次数据进行读取时,应用可以指定最大时效值(maxStalenessSeconds)。
这可以确保次节点从主节点复制的滞后时间不能超过指定的时效值,从而次节点所返回的数据具有其时效性。
另外,读取也可以与读取关注(ReadConcern)相关联,来控制查询到的返回数据的一致性。
例如,ReadConcern 能通过一些返回值来告知 MongoDB,那些被复制到副本集中的多数节点上的数据。
这样可以确保查询只读取那些没有因为节点或数据中心故障而丢失的数据,并且还能为应用提供一段时间内数据的一致性视图。
MongoDB 3.6 还引入了“因果一致性(causal consistency)”的概念,以保证客户端会话中的每个读取操作,都始终只“关注”之前的写入操作是否已完成,而不管具体是哪个副本正在为请求提供服务。
通过在会话中对操作进行严格的因果排序,这种因果一致性可以确保每次读取都始终遵循逻辑上的一致,从而实现分布式系统的单调式读取(monotonic read)。而这正是各种多节点数据库所无法满足的。
因果一致性不但使开发人员,能够保留过去传统的单节点式关系型数据库,在实施过程中具备的数据严格一致性的优势;又能将时下流行架构充分利用到可扩展和具有高可用性的分布式数据平台之上。
精彩活动预告
人工智能在智能对话方面的长足进步,在几乎所有行业的垂直领域都有应用和用例,被认为是下一个重大的技术转变,从移动互联网 GUI 时代到人工智能 CUI 时代,对话机器人如何实现革命性的改变?在对话机器人这个领域中有哪些技术在背后作为支撑,商业应用中又有哪些具体的实现形式?我们邀请到智能一点CTO莫瑜老师,将对人工智能 Chatbot 技术进行深度解析。

编辑:陶家龙、孙淑娟
投稿:有投稿、寻求报道意向技术人请联络 editor@51cto.com
原文链接:https://dzone.com/articles/active-active-application-architectures-with-mongo、https://dzone.com/articles/active-active-application-architectures-with-mongo-1
陈峻(Julian Chen) ,有着十多年的 IT 项目、企业运维和风险管控的从业经验,日常工作深入系统安全各个环节。作为 CISSP 证书持有者,他在各专业杂志上发表了《IT运维的“六脉神剑”》、《律师事务所IT服务管理》 和《股票交易网络系统中的安全设计》等论文。他还持续分享并更新《廉环话》系列博文和各种外文技术翻译,曾被(ISC)2 评为第九届亚太区信息安全领袖成就表彰计划的“信息安全践行者”和 Future-S 中国 IT 治理和管理的 2015 年度践行人物。
精彩文章推荐:
以上是关于『MongoDB』MongoDB高可用部署架构——分片集群篇(Sharding)的主要内容,如果未能解决你的问题,请参考以下文章