前端面试中经常提到的LRU缓存策略详解
Posted 不叫猫先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端面试中经常提到的LRU缓存策略详解相关的知识,希望对你有一定的参考价值。
🐱 个人主页:不叫猫先生
🙋♂️ 作者简介:2022年度博客之星前端领域TOP 2,前端领域优质作者、阿里云专家博主,专注于前端各领域技术,共同学习共同进步,一起加油呀!
💫优质专栏:vue3从入门到精通、TypeScript从入门到实践
📢 资料领取:前端进阶资料以及文中源码可以找我免费领取
🔥 前端学习交流:博主建立了一个前端交流群,汇集了各路大神,一起交流学习,期待你的加入!(文末有我wx或者私信)
目录
LRU
LRU(Least Recently Used)最近最少使用缓存策略,根据历史数据记录,当数据超过了限定空间的时候对数据清理,清理的原则是对很久没有使用到过的数据进行清除。
一、为什么要使用Map是来定义容器
Map在保存数据时会按照记住存储数据时候的顺序,这样存储的数据是有序列的,并且会维护键值对的插入顺序,Map存储数据的键值可以是任意类型(对象或者基本类型都可),Map提供了get、set、delete方法十分方便;而Object的话是无序,当然也可以使用Array。另外Map的算法复杂度是O(1),处理数据更迅速。
二、应用场景
- redis
- 浏览器浏览记录
- vue中内置组件keep-alive
三、代码实现
实现的大概思路如下:
- 创建一个LRUCache类
- 定义容器以及容器的容量
- 定义set方面,设置容器中的数据
- 定义get方法,获取容器中的数据
class LRUCache
constructor(length)
// 定义容器容量
this.length = length;
// 创建数据容器,生成一个空映射
this.map = new Map();
// 设置key值
set(key, value)
// 获取key值
get(key)
接下来就是对set方法和get方法的处理:
-
set
- 当容器长度不超过设定的长度:设置key值,但是为了达到缓存策略的效果,需要我们先删除数据,后添加到容器的最后一条
- 当容器长度超过设定的长度:先删除掉容器中的第一条数据
-
get
- 先获取数据值,然后删除该条数据,再设置数据到最后
class LRUCache
constructor(length)
// 定义容器容量
this.length = length;
// 定义数据容器
this.map = new Map();
// 设置key值
set(key, value)
// 如果容器容量超过设定的容量
if (this.map.size >= this.length)
// 等价于:let firstKey = this.map.keys()[0]
//map.keys().next()查询容器中第一条数据的key值
//keys()会返回一个迭代器对象,包含了实力对象中的每一个key值
let firstKey = this.map.keys().next().value;
//删除容器中第一条数据
this.map.delete(firstKey);
// 容器中存在key就先删除掉
if (this.map.has(key))
this.map.delete(key);
// 删除后重新加入该条数据
this.map.set(key, value);
// 获取key值
get(key)
// 获取key值不存在返回null
if (!this.map.has(key))
return null;
// 获取key值
let value = this.map.get(key);
//删除容器中的该条数据
this.map.delete(key);
//重新把该条数据添加到容器中
this.map.set(key, value);
return value
// 创建实例对象并设置容器大小
const lruCache = new LRUCache(5)
添加6条数据
lruCache.set('name', 'zhangsan')
lruCache.set('class', 'xinguan')
lruCache.set('age', 19)
lruCache.set('sex', '男')
lruCache.set('occupation', '前端工程师')
lruCache.set('year', '2023')
console.log(lruCache, 'lruCache')
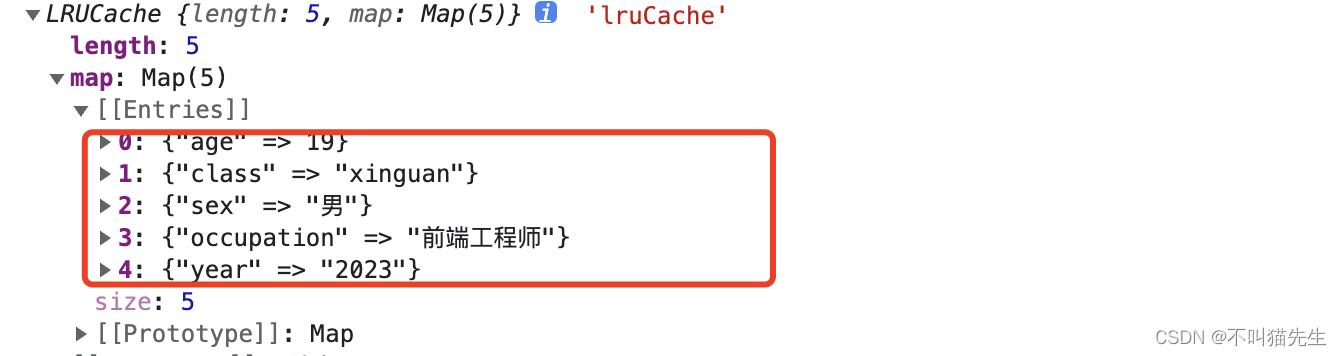
对lruCache添加了6条数据并按顺序排列,打印出来只剩5条数据,添加的第一条(‘name’, ‘zhangsan’)被删除了。
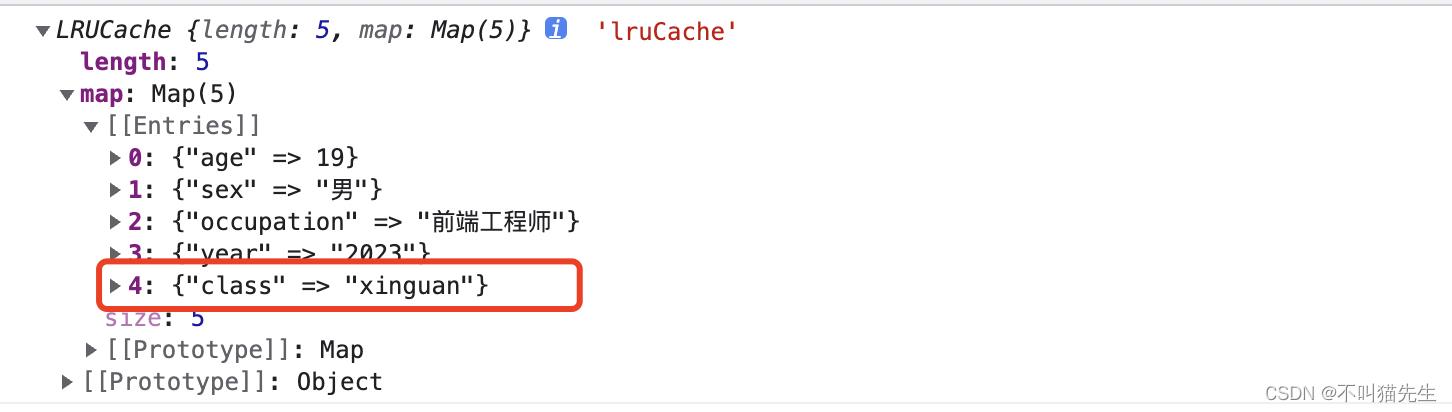
然后获取class的值,发现key为class的这条数据跑最后了。因为在get时候先delete后set了。
console.log(lruCache.get('class'), 'lruCache')//xinguan
从源码出发,分析LRU缓存淘汰策略的实现!
关注不迷路
01
前情提要
在之前的一文中,我们曾经提到过,利用java.util包中的LinkedHashMap可以很容易地实现LRU(最近最少使用)的缓存淘汰策略。这主要得益于LinkedHashMap底层维护的双向链表以及继承自HashMap的数据结构。
在大厂面试过程中,经常会遇到手写一个LRU缓存淘汰策略的题目。这时候,如果应聘者使用LinkedHashMap加以实现之后,面试官很有可能进一步发问!为什么可以实现?这一前一后两个问题,不仅考察了应聘者的代码能力,还考察了对基础和原理的把握,算得上是一道典型面试题目了。
之前已经讲过LRU的实现思路了,本文将重点从源码层面出发,分析一下为什么LinkedHashMap可以实现LRU。为了方便分析,我们将LRU缓存淘汰策略的实现代码作如下展示:
import java.util.LinkedHashMap;import java.util.Map;/*** 本程序及其注释在JDK11验证通过* @param <K>* @param <V>*/public class LRUCache<K, V> {// 默认负载因子private static final float DEFAULT_LOAD_FACTOR = 0.75f;// 缓存最大容量private final int MAX_CACHE_SIZE;// 自定义负载因子private final float LOAD_FACTOR;// 缓存主体LinkedHashMapprivate final LinkedHashMap<K, V> cacheMap;public LRUCache(int maxCacheSize, float loadFactor) {MAX_CACHE_SIZE = maxCacheSize;// 可根据具体情况自定义负载因子LOAD_FACTOR = loadFactor;// 根据缓存最大容量计算Map的初始化容量,避免扩容影响性能int capacity = (int)Math.ceil(MAX_CACHE_SIZE / LOAD_FACTOR) + 1;// accessOrder设置为true,表示在插入或者访问的时候,都会更新缓存,将该数据插入链表尾部或者移动至链表尾部cacheMap = new LinkedHashMap<>(capacity, LOAD_FACTOR, true) {private static final long serialVersionUID = 1001L;// 重写removeEldestEntry方法,当cacheMap的size超过缓存最大容量时,将链表头部数据移除protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {return size() > MAX_CACHE_SIZE;}};}public LRUCache(int maxCacheSize) {// 使用默认负载因子this(maxCacheSize, DEFAULT_LOAD_FACTOR);}public void put(K key, V value) {cacheMap.put(key, value);}public V get(K key) {return cacheMap.get(key);}}
02
非线程安全
LRUCache工具类在单线程情况下可以很好地工作(在面试过程中,往往也可以很好地工作!),但不幸的是,本地缓存的实际使用场景,往往伴随着多线程的环境,原因是因为,无论是缓存,还是多线程,都是为了提升性能,因此,二者大概率是会同时存在于系统中的,这时候类似于上述LRUCache的实现便不再适用。
由于LinkedHashMap是非线程安全的,因此,为了实现线程安全的LRU缓存淘汰策略,一种思路是对LinkedHashMap的公共方法制定并发访问策略(加锁)。比较明显的是,对LinkedHashMap的写操作是非线程安全的。但事实上,在按结点访问顺序排序的策略下,对LinkedHashMap的读操作也是非线程安全的。因此,在制定有效的并发访问策略之前,首先需要了解其内部的实现。
而工作中更常用的本地缓存实现,则是Google开源的Guava Cache,它并非采用上述方式进行实现,而是采用了效率更高的类似于ConcurrentHashMap分段锁的实现。Guava Cache的内容值得单独写一篇文章来讲述,在此就不展开。
在分析源码之前,我们首先看一下LinkedHashMap在Map大家族中的位置:
从上图我们可以看到,LinkedHashMap继承了HashMap,并实现了Map接口。
03
源码解读
接下来我们从LinkedHashMap的源码(JDK11版本)入手,对其内部实现进行解读。
首先需要了解的是,LinkedHashMap内部一个关键的数据结构:
static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);}}
这个名为Entry的静态内部类继承自HashMap的静态内部类Node,并通过before和after实现了双向链表的功能。
基于Entry的数据结构,LinkedHashMap通过head维护双向链表的头结点,通过tail维护双向链表的尾结点,并利用布尔值accessOrder实现对结点排序策略的控制,具体代码如下:
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {/*** 双向链表的头结点(LRU中最先被淘汰的结点)*/transient LinkedHashMap.Entry<K,V> head;/*** 双向链表的尾结点(LRU中最后被淘汰的结点)*/transient LinkedHashMap.Entry<K,V> tail;/*** 结点的排序策略:基于访问顺序(true),基于插入顺序(false)*/final boolean accessOrder;}
至此,我们对LinkedHashMap的属性已经有了比较清晰的了解。接下来,让我们重点关注一下,在LRUCache类中使用到的LinkedHashMap的方法。
public V get(Object key) {Node<K,V> e;// 判断key是否存在if ((e = getNode(hash(key), key)) == null)return null;// 若结点的排序策略为基于访问顺序排序,则执行afterNodeAccess方法if (accessOrder)// 将本次访问的结点,移动到链表的尾结点afterNodeAccess(e);return e.value;}
在get方法的源码中,我们看到,它调用了父类HashMap中getNode的方法来判断key是否存在,然后在accessOrder为true时,执行afterNodeAccess方法。
值得注意的是,由于afterNodeAccess方法的功能是将本次访问的结点,移动到链表的尾结点,因此,当accessOrder为true时,get方法实际上存在写操作!这直接影响了并发访问控制策略的制定。
LinkedHashMap的put方法直接继承自父类HashMap,但值得注意的是,LinkedHashMap重写了afterNodeInsertion方法,这使得在put操作在满足removeEldestEntry方法(需要被重写,否则默认返回false)所指定的条件的时候,就会触发removeNode方法,最终删除被淘汰的结点。
void afterNodeInsertion(boolean evict) { // possibly remove eldestLinkedHashMap.Entry<K,V> first;if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;removeNode(hash(key), key, null, false, true);}}
至此,我们对实现LRU缓存过程中所使用到的LinkedHashMap的特性,均已从源码层面进行了解读。
本文关于LinkedHashMap的源码分析总结就到这里了。
欢迎大家一起讨论技术,共同成长!
学习 | 工作 | 分享
以上是关于前端面试中经常提到的LRU缓存策略详解的主要内容,如果未能解决你的问题,请参考以下文章