GPUNvidia CUDA 编程基础教程——异步流及 CUDA C/C++ 应用程序的可视化性能分析
Posted 从善若水
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPUNvidia CUDA 编程基础教程——异步流及 CUDA C/C++ 应用程序的可视化性能分析相关的知识,希望对你有一定的参考价值。
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持!
博主链接
本人就职于国际知名终端厂商,负责modem芯片研发。
在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。
博客内容主要围绕:
5G/6G协议讲解
算力网络讲解(云计算,边缘计算,端计算)
高级C语言讲解
Rust语言讲解
异步流及 CUDA C/C++ 应用程序的可视化性能分析

CUDA工具包附带了 Nsight Systems,这是一个功能强大的GUI应用程序,可支持CUDA应用程序的开发。 Nsight Systems为被加速的应用程序生成图形化的活动时间表,其中包含有关CUDA API调用、内核执行、内存活动以及CUDA流的使用的详细信息。
运行Nsight Systems
我们先使用nvcc编译下面的code:
#include <stdio.h>
void initWith(float num, float *a, int N)
for(int i = 0; i < N; ++i)
a[i] = num;
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
result[i] = a[i] + b[i];
void checkElementsAre(float target, float *vector, int N)
for(int i = 0; i < N; i++)
if(vector[i] != target)
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\\n", i, vector[i], target);
exit(1);
printf("Success! All values calculated correctly.\\n");
int main()
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
initWith(3, a, N);
initWith(4, b, N);
initWith(0, c, N);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
cudaMemPrefetchAsync(c, size, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\\n", cudaGetErrorString(asyncErr));
checkElementsAre(7, c, N);
cudaFree(a);
cudaFree(b);
cudaFree(c);
编译命令:
nvcc -o vector-add-prefetch 01-vector-add/solutions/01-vector-add-prefetch-solution.cu -run
生成分析文件:
nsys profile --stats=true -o vector-add-prefetch-report ./vector-add-prefetch
新启一个命令行,执行nsight-sys,

出现nsight system界面,
选择上面生成的报告文件vector-add-prefetch-report.qdrep,
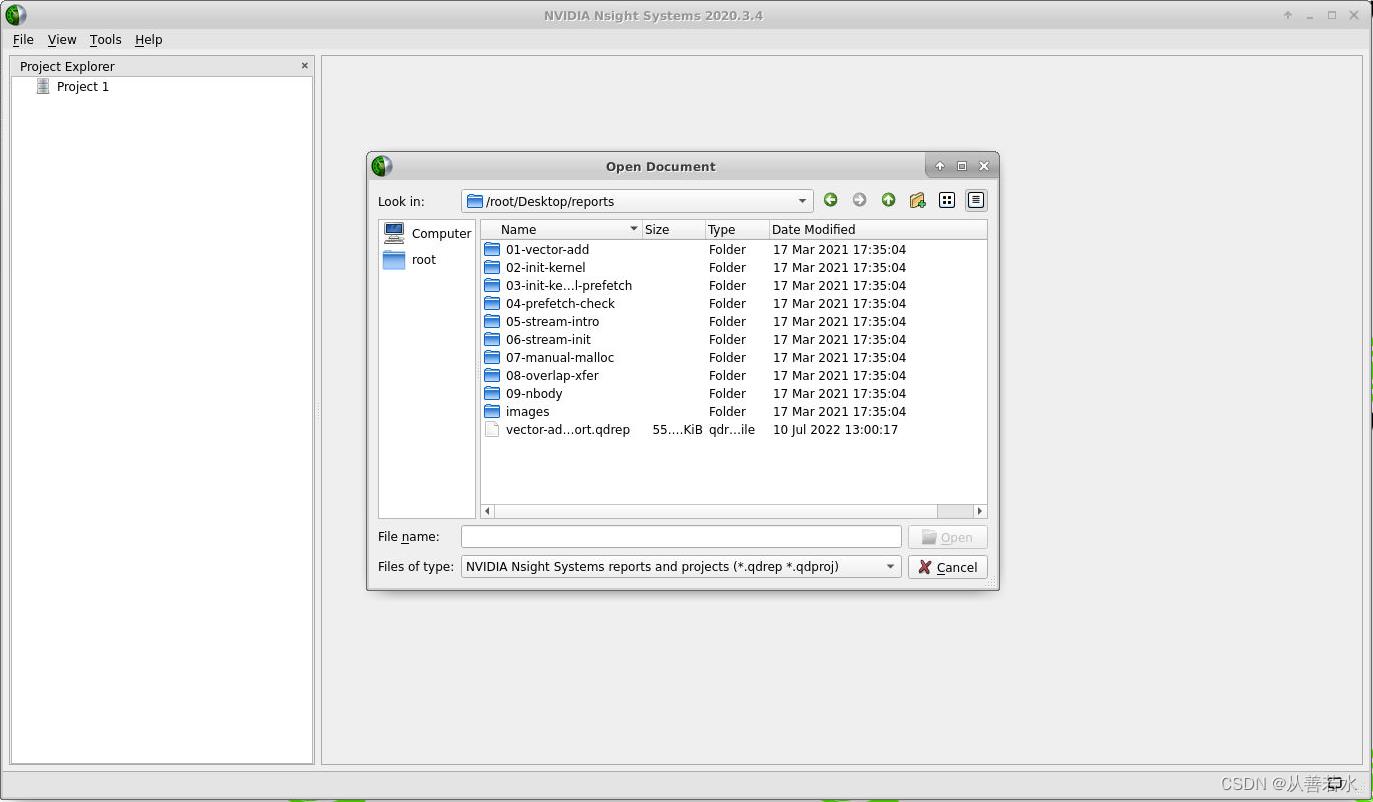
显示的结果如下:
并发CUDA流
您现在将学习一个新概念 CUDA Streams。 在对它们进行介绍之后,您将返回使用Nsight Systems来更好地评估它们对应用程序性能的影响。
流是指一系列指令,且 CUDA 具有默认流。默认情况下,CUDA 核函数会在默认流中运行,

在任何流(包括默认流)中,其所含指令(此处为核函数启动)必须在下一个流开始之前完成。

我们还可创建非默认流,以便核函数执行,

任一流中的核函数均须按顺序执行。不过,不同的非默认流中的核函数则可同时交互,
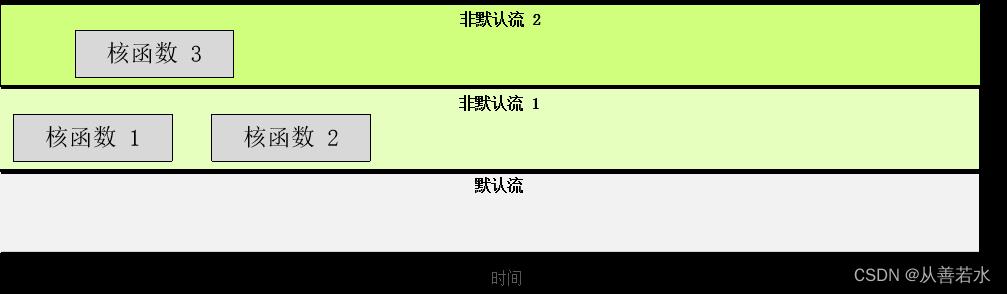
默认流较为特殊:它会阻止其他流中的所有核函数。
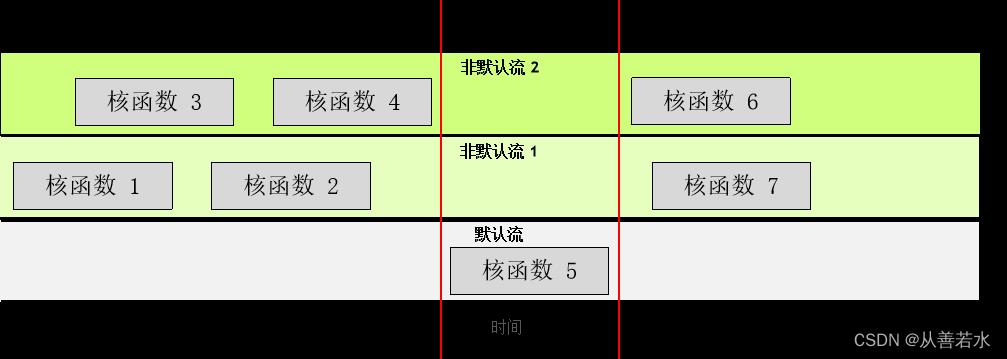
在 CUDA 编程中,流是由按顺序执行的一系列命令构成。在 CUDA 应用程序中,核函数的执行以及一些内存传输均在 CUDA 流中进行。不过直至此时,您仍未直接与 CUDA 流打交道;但实际上您的 CUDA 代码已在名为默认流的流中执行了其核函数。
除默认流以外,CUDA 程序员还可创建并使用非默认 CUDA 流,此举可支持执行多个操作,例如在不同的流中并发执行多个核函数。多流的使用可以为您的加速应用程序带来另外一个层次的并行,并能提供更多应用程序的优化机会。
创建,使用和销毁非默认CUDA流
以下代码段演示了如何创建,利用和销毁非默认CUDA流。您会注意到,要在非默认CUDA流中启动CUDA核函数,必须将流作为执行配置的第4个可选参数传递给该核函数。到目前为止,您仅利用了执行配置的前两个参数:
cudaStream_t stream; // CUDA流的类型为 `cudaStream_t`
cudaStreamCreate(&stream); // 注意,必须将一个指针传递给 `cudaCreateStream`
someKernel<<<number_of_blocks, threads_per_block, 0, stream>>>(); // `stream` 作为第4个EC参数传递
cudaStreamDestroy(stream); // 注意,将值(而不是指针)传递给 `cudaDestroyStream`
但值得一提的是,执行配置的第3个可选参数超出了本博客的范围。此参数允许程序员提供共享内存(当前将不涉及的高级主题)中为每个内核启动动态分配的字节数。分配给每个块的共享内存的默认字节数为 “0”。
一个多流的例子
#include <stdio.h>
__global__
void initWith(float num, float *a, int N)
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
a[i] = num;
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
result[i] = a[i] + b[i];
void checkElementsAre(float target, float *vector, int N)
for(int i = 0; i < N; i++)
if(vector[i] != target)
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\\n", i, vector[i], target);
exit(1);
printf("Success! All values calculated correctly.\\n");
int main()
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
cudaMemPrefetchAsync(c, size, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
/*
* Create 3 streams to run initialize the 3 data vectors in parallel.
*/
cudaStream_t stream1, stream2, stream3;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaStreamCreate(&stream3);
/*
* Give each `initWith` launch its own non-standard stream.
*/
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream1>>>(3, a, N);
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream2>>>(4, b, N);
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream3>>>(0, c, N);
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\\n", cudaGetErrorString(asyncErr));
cudaMemPrefetchAsync(c, size, cudaCpuDeviceId);
checkElementsAre(7, c, N);
/*
* Destroy streams when they are no longer needed.
*/
cudaStreamDestroy(stream1);
cudaStreamDestroy(stream2);
cudaStreamDestroy(stream3);
cudaFree(a);
cudaFree(b);
cudaFree(c);
手动内存分配和复制
尽管 cudaMallocManaged 和 cudaMemPrefetchAsync 函数性能出众并能大幅简化内存迁移,但有时也有必要使用更多手动内存分配方法。这在已知只需在设备或主机上访问数据时尤其如此,并且因免于进行自动按需迁移而能够收回数据迁移成本。
此外,通过手动内存管理,您可以使用非默认流同时开展数据传输与计算工作。在本节中,您将学习一些基本的手动内存分配和拷贝技术,之后会延伸应用这些技术以同时开展数据拷贝与计算工作。
以下是一些用于手动内存管理的 CUDA 命令:
cudaMalloc命令将直接为处于活动状态的 GPU 分配内存。这可防止出现所有 GPU 分页错误,而代价是主机代码将无法访问该命令返回的指针;cudaMallocHost命令将直接为 CPU 分配内存。该命令可 “固定” 内存(pinned memory)或 “页锁定” 内存(page-locked memory),此举允许将内存异步拷贝至 GPU 或从 GPU 异步拷贝至内存。固定内存过多则会干扰 CPU 性能,因此请勿无端使用该命令。释放固定内存时应使用cudaFreeHost命令;- 无论是从主机到设备还是从设备到主机,
cudaMemcpy命令均可拷贝(而非传输)内存。
手动内存管理示例
以下是一段演示使用上述 CUDA API 调用的代码。
int *host_a, *device_a; // Define host-specific and device-specific arrays.
cudaMalloc(&device_a, size); // `device_a` is immediately available on the GPU.
cudaMallocHost(&host_a, size); // `host_a` is immediately available on CPU, and is page-locked, or pinned.
initializeOnHost(host_a, N); // No CPU page faulting since memory is already allocated on the host.
// `cudaMemcpy` takes the destination, source, size, and a CUDA-provided variable for the direction of the copy.
cudaMemcpy(device_a, host_a, size, cudaMemcpyHostToDevice);
kernel<<<blocks, threads, 0, someStream>>>(device_a, N);
// `cudaMemcpy` can also copy data from device to host.
cudaMemcpy(host_a, device_a, size, cudaMemcpyDeviceToHost);
verifyOnHost(host_a, N);
cudaFree(device_a);
cudaFreeHost(host_a); // Free pinned memory like this.
使用流实现数据传输和代码的重叠执行
cudaMemcpyAsync 可以通过非默认流异步传输内存,此操作可实现内存拷贝与计算的重叠。

除了 cudaMemcpy 之外,还有 cudaMemcpyAsync,只要固定了主机内存,它就可以从主机到设备或从设备到主机异步复制内存,这可以通过使用 cudaMallocHost 分配它来完成。
与核函数的执行类似,cudaMemcpyAsync 在默认情况下仅相对于主机是异步的。默认情况下,它在默认流中执行,因此对于GPU上发生的其他CUDA操作而言,它是阻塞操作。但是,cudaMemcpyAsync 函数将非默认流作为可选的第5个参数。通过向其传递非默认流,可以将内存传输与其他非默认流中发生的其他CUDA操作并发。
一种常见且有用的模式是结合使用固定主机内存,非默认流中的异步内存副本和非默认流中的核函数执行,以使内存传输与核函数的执行重叠。
在以下示例中,我们并非在等待整个内存拷贝完成之后再开始运行核函数,而是拷贝并处理所需的数据段,并让每个拷贝/处理中的数据段均在各自的非默认流中运行。通过使用此技术,您可以开始处理部分数据,同时为后续段并发执行内存传输。使用此技术计算操作次数的数据段特定值和数组内的偏移位置时必须格外小心,如下所示:
int N = 2<<24;
int size = N * sizeof(int);
int *host_array;
int *device_array;
cudaMallocHost(&host_array, size); // Pinned host memory allocation.
cudaMalloc(&device_array, size); // Allocation directly on the active GPU device.
initializeData(host_array, N); // Assume this application needs to initialize on the host.
const int numberOfSegments = 4; // This example demonstrates slicing the work into 4 segments.
int segmentN = N / numberOfSegments; // A value for a segment's worth of `N` is needed.
size_t segmentSize = size / numberOfSegments; // A value for a segment's worth of `size` is needed.
// For each of the 4 segments...
for (int i = 0; i < numberOfSegments; ++i)
// Calculate the index where this particular segment should operate within the larger arrays.
segmentOffset = i * segmentN;
// Create a stream for this segment's worth of copy and work.
cudaStream_t stream;
cudaStreamCreate(&stream);
// Asynchronously copy segment's worth of pinned host memory to device over non-default stream.
cudaMemcpyAsync(&device_array[segmentOffset], // Take care to access correct location in array.
&host_array[segmentOffset], // Take care to access correct location in array.
segmentSize, // Only copy a segment's worth of memory.
cudaMemcpyHostToDevice,
stream); // Provide optional argument for non-default stream.
// Execute segment's worth of work over same non-default stream as memory copy.
kernel<<<number_of_blocks, threads_per_block, 0, stream>>>(&device_array[segmentOffset], segmentN);
// `cudaStreamDestroy` will return immediately (is non-blocking), but will not actually destroy stream until
// all stream operations are complete.
cudaStreamDestroy(stream);
核函数和内存复制回主机重叠执行例子
#include <stdio.h>
__global__
void initWith(float num, float *a, int N)
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
a[i] = num;
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
result[i] = a[i] + b[i];
void checkElementsAre(float target, float *vector, int N)
for(int i = 0; i < N; i++)
if(vector[i] != target)
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\\n", i, vector[i], target);
exit(1);
printf("Success! All values calculated correctly.\\n");
int main()
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
float *h_c;
cudaMalloc(&a, size);
cudaMalloc(&b, size);
cudaMalloc(&c, size);
cudaMallocHost(&h_c, size);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
/*
* Create 3 streams to run initialize the 3 data vectors in parallel.
*/
cudaStream_t stream1, stream2, stream3;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaStreamCreate(&stream3);
/*
* Give each `initWith` launch its own non-standard stream.
*/
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream1>>>(3, a, N);
initWith<<<numberOfBlocks, threadsPerBlock, 0, stream2>>>(4, b, N);
initWith<<<numberOfBlocksGPUNvidia CUDA 编程基础教程——使用 CUDA C/C++ 加速应用程序
GPUNvidia CUDA 编程基础教程——使用 CUDA C/C++ 加速应用程序
GPUNvidia CUDA 编程基础教程——利用基本的 CUDA 内存管理技术来优化加速应用程序
GPUNvidia CUDA 编程基础教程——利用基本的 CUDA 内存管理技术来优化加速应用程序