基于MockingBird声音克隆
Posted Mr数据杨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于MockingBird声音克隆相关的知识,希望对你有一定的参考价值。
Mockingbird 是一种声音克隆软件,可以复制和编辑人类语音。这种软件通常用于语音模拟和生成新语音,但也可能用于欺骗和恶作剧。由于技术的进步,声音克隆软件越来越逼真,因此应谨慎使用。
目前网络上的版本有很多,教程也是各种五花八门,我尝试看了几个代码都跑不通,自己折腾了一天终于完成了数据集预处理、模型训练应用的过程,效果还算可以,想要真的完美的克隆声音还需要技术的进步才可以。
文章目录
5 秒实现 AI 语音克隆(Python)

作者 | 花鱼
来源丨算法进阶
今天就是纯推荐,水一下~推荐一个有趣的AI黑科技--MockingBird,该项目集成了Python开发,语音提取、录制、调试、训练一体化GUI操作,号称只需要你的 5 秒钟的声音,就能实时克隆出你的任意声音。
一、实时语音克隆原理简介
该项目实时语音克隆原理基于谷歌2017年发布的论文《Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis》
技术实现分成三个模块(Encoder、Synthesizer、Vocoder),
encoder模块将说话人的声音转换成人声的数字编码(speaker embedding)
synthesis 模块将文本转换成梅尔频谱(mel-spectrogram)
vocoder模块将梅尔频谱(mel-spectrogram)转换成(波形)waveform 先提取说话者的声音提取音色向量(Speaker Encoder部分),然后用这部分内容加上Synthesizer和Vocoder一起完成语音合成。
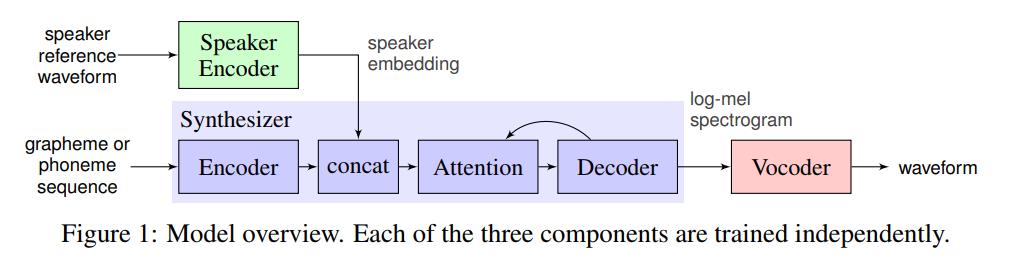
二、MockingBird项目动手实践
MockingBird项目地址:github.com/babysor/MockingBird或者文末阅读原文可以访问
MockingBird的安装比较简单,按说明把Python环境(需要3.7及以上版本)、著名的机器学习框架PyTorch、著名的多媒体处理组件FFmpeg(实测在仅使用简单训练的时候是不需要它的)、pip安装下项目依赖库,再准备预训练模型就差不多了。
2.1 安装要求
> 按照原始存储库测试您是否已准备好所有环境。 **Python 3.7 或更高版本** 需要运行工具箱。
* 安装 [PyTorch](https://pytorch.org/get-started/locally/)。
> 如果在用 pip 方式安装的时候出现 `ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2)` 这个错误可能是 python 版本过低,3.9 可以安装成功
* 安装 [ffmpeg](https://ffmpeg.org/download.html#get-packages)。
* 运行`pip install -r requirements.txt` 来安装剩余的必要包。
* 安装 webrtcvad `pip install webrtcvad-wheels`。
### [](https://github.com/babysor/MockingBird/blob/main/README-CN.md#2-%E5%87%86%E5%A4%87%E9%A2%84%E8%AE%AD%E7%BB%83%E6%A8%A1%E5%9E%8B)2\\. 准备预训练模型
考虑训练您自己专属的模型或者下载社区他人训练好的模型:
> 近期创建了[知乎专题](https://www.zhihu.com/column/c_1425605280340504576) 将不定期更新炼丹小技巧or心得,也欢迎提问
#### [](https://github.com/babysor/MockingBird/blob/main/README-CN.md#21-%E4%BD%BF%E7%94%A8%E6%95%B0%E6%8D%AE%E9%9B%86%E8%87%AA%E5%B7%B1%E8%AE%AD%E7%BB%83encoder%E6%A8%A1%E5%9E%8B-%E5%8F%AF%E9%80%89)2.1 使用数据集自己训练encoder模型 (可选)
* 进行音频和梅尔频谱图预处理: `python encoder_preprocess.py <datasets_root>` 使用`-d dataset` 指定数据集,支持 librispeech_other,voxceleb1,aidatatang_200zh,使用逗号分割处理多数据集。
* 训练encoder: `python encoder_train.py my_run <datasets_root>/SV2TTS/encoder`
> 训练encoder使用了visdom。你可以加上`-no_visdom`禁用visdom,但是有可视化会更好。在单独的命令行/进程中运行"visdom"来启动visdom服务器。
#### [](https://github.com/babysor/MockingBird/blob/main/README-CN.md#22-%E4%BD%BF%E7%94%A8%E6%95%B0%E6%8D%AE%E9%9B%86%E8%87%AA%E5%B7%B1%E8%AE%AD%E7%BB%83%E5%90%88%E6%88%90%E5%99%A8%E6%A8%A1%E5%9E%8B%E4%B8%8E23%E4%BA%8C%E9%80%89%E4%B8%80)2.2 使用数据集自己训练合成器模型(与2.3二选一)
* 下载 数据集并解压:确保您可以访问 *train* 文件夹中的所有音频文件(如.wav)
* 进行音频和梅尔频谱图预处理: `python pre.py <datasets_root> -d dataset -n number` 可传入参数:
* `-d dataset` 指定数据集,支持 aidatatang_200zh, magicdata, aishell3, data_aishell, 不传默认为aidatatang_200zh
* `-n number` 指定并行数,CPU 11770k + 32GB实测10没有问题
> 假如你下载的 `aidatatang_200zh`文件放在D盘,`train`文件路径为 `D:\\data\\aidatatang_200zh\\corpus\\train` , 你的`datasets_root`就是 `D:\\data\\`
* 训练合成器: `python synthesizer_train.py mandarin <datasets_root>/SV2TTS/synthesizer`
* 当您在训练文件夹 *synthesizer/saved_models/* 中看到注意线显示和损失满足您的需要时,请转到`启动程序`一步。
#### [](https://github.com/babysor/MockingBird/blob/main/README-CN.md#23%E4%BD%BF%E7%94%A8%E7%A4%BE%E5%8C%BA%E9%A2%84%E5%85%88%E8%AE%AD%E7%BB%83%E5%A5%BD%E7%9A%84%E5%90%88%E6%88%90%E5%99%A8%E4%B8%8E22%E4%BA%8C%E9%80%89%E4%B8%80)2.3使用社区预先训练好的合成器(与2.2二选一)
> 当实在没有设备或者不想慢慢调试,可以使用社区贡献的模型( 下载后传入synthesizer/saved_models/ ):
| 作者 | 下载链接 | 效果预览 | 信息 |
| --- | --- | --- | --- |
| 作者 | [https://pan.baidu.com/s/1iONvRxmkI-t1nHqxKytY3g](https://pan.baidu.com/s/1iONvRxmkI-t1nHqxKytY3g) [百度盘链接](https://pan.baidu.com/s/1iONvRxmkI-t1nHqxKytY3g) 4j5d | | 75k steps 用3个开源数据集混合训练 |
| 作者 | [https://pan.baidu.com/s/1fMh9IlgKJlL2PIiRTYDUvw](https://pan.baidu.com/s/1fMh9IlgKJlL2PIiRTYDUvw) [百度盘链接](https://pan.baidu.com/s/1fMh9IlgKJlL2PIiRTYDUvw) 提取码:om7f | | 25k steps 用3个开源数据集混合训练, 切换到tag v0.0.1使用 |
| @FawenYo | [https://drive.google.com/file/d/1H-YGOUHpmqKxJ9FRc6vAjPuqQki24UbC/view?usp=sharing](https://drive.google.com/file/d/1H-YGOUHpmqKxJ9FRc6vAjPuqQki24UbC/view?usp=sharing) [百度盘链接](https://pan.baidu.com/s/1vSYXO4wsLyjnF3Unl-Xoxg) 提取码:1024 | [input](https://github.com/babysor/MockingBird/wiki/audio/self_test.mp3) [output](https://github.com/babysor/MockingBird/wiki/audio/export.wav) | 200k steps 台湾口音需切换到tag v0.0.1使用 |
| @miven | [https://pan.baidu.com/s/1PI-hM3sn5wbeChRryX-RCQ](https://pan.baidu.com/s/1PI-hM3sn5wbeChRryX-RCQ) 提取码:2021 | [https://www.bilibili.com/video/BV1uh411B7AD/](https://www.bilibili.com/video/BV1uh411B7AD/) | 150k steps 注意:根据[issue](https://github.com/babysor/MockingBird/issues/37)修复 并切换到tag v0.0.1使用 |
#### [](https://github.com/babysor/MockingBird/blob/main/README-CN.md#24%E8%AE%AD%E7%BB%83%E5%A3%B0%E7%A0%81%E5%99%A8-%E5%8F%AF%E9%80%89)2.4训练声码器 (可选)
对效果影响不大,已经预置3款,如果希望自己训练可以参考以下命令。
* 预处理数据: `python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>`
> `<datasets_root>`替换为你的数据集目录,`<synthesizer_model_path>`替换为一个你最好的synthesizer模型目录,例如 *sythensizer\\saved_mode\\xxx*
* 训练wavernn声码器: `python vocoder_train.py <trainid> <datasets_root>`
> `<trainid>`替换为你想要的标识,同一标识再次训练时会延续原模型
* 训练hifigan声码器: `python vocoder_train.py <trainid> <datasets_root> hifigan`
> `<trainid>`替换为你想要的标识,同一标识再次训练时会延续原模型2.2 启动程序或工具箱
MockingBird在本地提供了一个B/S使用环境,运行python web.py后,用浏览器访问本地8080端口。输入框里的就是要合成的话术,传入的声音可以当场录音或者上传已录好的声音(需要wav格式),点击上传合成就可以稍后就可以听到AI克隆的声音。

除了可以运行web程序调试,还有功能更为丰富的工具箱可以自行试试。启动工具箱:python demo_toolbox.py -d <datasets_root>
三、一点感想
随着AI、元宇宙(AR/VR)技术的普及,虚拟世界的内容和形式都显得越来越真实,和真实世界的边界越来越模糊,交互也越来越容易。一方面,人类活动的疆界越来越大了,生活越加丰富。另一方面,我们可能更容易迷失于虚拟事物中,乱花渐欲迷人眼!
类似与AI模型从海量数据中,发现本质特征做合理的决策的过程,我们也需要维护好自己的“信息筛选及决策系统”,去客观地认识事物及笃定内心深处的追求。

往
期
回
顾
技术
资讯
技术
技术

分享

点收藏

点点赞

点在看
以上是关于基于MockingBird声音克隆的主要内容,如果未能解决你的问题,请参考以下文章