17 记一次 spark 读取大数据表 OOM OutOfMemoryError: GC overhead limit exceeded
Posted 蓝风9
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了17 记一次 spark 读取大数据表 OOM OutOfMemoryError: GC overhead limit exceeded相关的知识,希望对你有一定的参考价值。
前言
// 呵呵 一天的车, 这就是过年吧!, 但是你还能看到 那一盏为你留的灯, 这可能就是羁绊吧
// 草稿箱 抽一波
呵呵 最近因为一次 测试造了一张 200w 数据记录的表
然后 业务上需要分析 这张表, 然后 使用 spark 来进行处理的时候 发生了 "GC overhead limit exceeded"
当然 问题的本质原因 似乎是和我最开始 期望的原因 有一些差别, 呵呵
测试代码
测试代码 大致如下, rdd 是根据这张大的数据表记录构造的 " select * from big_record ", big_record 差不多是 38 个字段, 200w 的数据
看到这里, 我看了一下 都是基于迭代的操作阿? 没有什么问题阿
我怀疑的第一个点时 shuffle 的时候写出数据的时候 sorter.insertAll 是基于内存的, 但是仔细看了一下 这块的代码是 内存 + 磁盘 组合使用的, 按理论上来说 不应该是这里造成的 oom
其他的点, 暂时从代码层面上 似乎是看不出什么了
return rdd
.filter(filterFunc)
.flatMap(flatmapFunc)
.mapToPair(mapToPairFunc)
.reduceByKey(reductByKeyFunc)
.map(mapFunc)
.sortBy(sortByFunc)
.take(20);只能调试一下了, 呵呵 复现问题至项目接近卡主
然后 查看一下 这些线程的信息 查看一下执行 ShuffleMapTask 的线程, 呵呵 居然还在和数据库交互 尝试获取数据 ?
呵呵 我觉得这个问题并不简单, 可能是之前没有见过的问题, 呵呵 然后 这里是吧问题转换到了 数据库的查询上面
因此 我重新写了一个测试用例, 大致是如下
测试用例转换
测试用例大致是如下, 为了效果更佳清晰, 调整了一下 vm 参数 : -Xmx512M -Xms512M
/**
* Test04QueryByStat
*
* @author Jerry.X.He
* @version 1.0
* @date 2021-01-23 19:22
*/
public class Test04QueryByStat
// Test04QueryByStat
public static void main(String[] args) throws Exception
JdbcTemplate jdbcTemplate = Test02QueryImportedTask.getPostgresJdbcTemplate();
DataSource dataSource = jdbcTemplate.getDataSource();
// 38 * 10_0000
String sql = "SELECT * FROM big_record t WHERE t.ENABLED = true AND t.DELETED = false limit 500000 ";
Connection con = dataSource.getConnection();
PreparedStatement ps = con.prepareStatement(sql);
long start = System.currentTimeMillis();
// Tools.sleep(10_000);
ResultSet rs = ps.executeQuery();
long spent = Tools.spent(start);
System.out.println(formatLogInfoWithIdx(" spent : 0 ms ", spent));
// Tools.sleep(10_000);
if (rs.next())
System.out.println(JSON.toJSONString(new ResultSet2MapAdapter(rs).toMap()));
另外 big_record 的数据我也稍微减少了一些 50w, 不过这足以复现出问题了

爆出的错误信息大致是如下
可以看到这里 是在处理服务器返回的结果的数据的时候 oom 了?
关于 postgres 客户端, 服务端交互协议这块可以参见, 稍微了解一下 : Tried to send an out-of-range integer as a 2-byte value: 40003
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
at sun.misc.URLClassPath$JarLoader.getResource(URLClassPath.java:1061)
at sun.misc.URLClassPath.getResource(URLClassPath.java:249)
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:363)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:362)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:1882)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:173)
at org.postgresql.jdbc.PgStatement.execute(PgStatement.java:622)
at org.postgresql.jdbc.PgStatement.executeWithFlags(PgStatement.java:472)
at org.postgresql.jdbc.PgStatement.executeQuery(PgStatement.java:386)
at com.hx.test11.Test04QueryByStat.main(Test04QueryByStat.java:44)接着 我把 limit 限制的数据稍微改小一些, 然后在 服务端返回 “Command Status” 的地方打上断点看看
看一下 具体传递的数据的上下文的信息
从下面的 tuples 里面可以看到, 我需要的是 100000 条 big_record, 服务器是直接返回了 100000 条数据过来, 然后装载到内存, 难不怪是 oom 了
jvm 512m 内存限制, 对于 100000 条 big_record 还足以容纳, 但是对于 500000 就容纳不了了, 然后 不断的尝试进行 gc, 最终每次 gc 的收益少之又少, 最后抛出了 OutOfMemoryError: GC overhead limit exceeded

接下来我们再看一看内存中的对象相关信息, 这就是为什么 我测试用例增加了一个 sleep 的原因
先看看执行查询之前的 top10
master:~ jerry$ jmap -histo 3929
num #instances #bytes class name
----------------------------------------------
1: 190013 41059104 [B
2: 145916 18460400 [C
3: 3072 14807368 [I
4: 39702 952848 java.lang.String
5: 4317 331736 [Ljava.lang.Object;
6: 6545 314160 java.util.HashMap
7: 1681 192464 java.lang.Class
8: 2733 174912 java.net.URL
9: 1966 157280 [S
10: 4768 114432 java.lang.StringBuilder再来看一下 查询之后的 top10
可以看到 执行了查询之后, 内存中的 byte[] 猛增到了 3704818, 内存占用几乎为 117M, 另外还有 byte[][] 内存占用几乎为 16M
3704818 大致拆解一下大致应该是 (38-1) * 100000 + vm 中其他 byte[], 前面 -1 是因为每条记录至少会有一个字段为 null
master:~ jerry$ jmap -histo 3929
num #instances #bytes class name
----------------------------------------------
1: 3704818 117795104 [B
2: 100002 16801584 [[B
3: 6258 5787168 [I
4: 11028 1097240 [C
5: 1617 1020144 [Ljava.lang.Object;
6: 10510 252240 java.lang.String
7: 1787 204448 java.lang.Class
8: 3036 121440 java.lang.ref.Finalizer
9: 3475 111200 java.util.HashMap$Node
10: 2095 67040 java.util.concurrent.ConcurrentHashMap$Node接着我们看一下 vm 的内存分配, 可以看到 这里还是能够容得下 117M 的对象的, 所以我们这里 limit 100000 之后能够正常运行
但是 假设我们 100000 * 5 呢?, 需要的大致是 117 * 5 = 585M, 呵呵 果然是 不行

问题的解决
那么问题怎么解决呢?
还是搜索了一下, 查看了一下 处理方式, 设置 fetchSize
呵呵 接着调整一下测试用例, 跑一下 ok 了
/**
* Test04QueryByStat
*
* @author Jerry.X.He
* @version 1.0
* @date 2021-01-23 19:22
*/
public class Test04QueryByStat
// Test17QueryPerTask
public static void main(String[] args) throws Exception
JdbcTemplate jdbcTemplate = Test02QueryImportedTask.getPostgresJdbcTemplate();
DataSource dataSource = jdbcTemplate.getDataSource();
// 38 * 10_0000
String sql = "SELECT * FROM big_record t WHERE t.ENABLED = true AND t.DELETED = false limit 500000 ";
Connection con = dataSource.getConnection();
con.setAutoCommit(false);
PreparedStatement ps = con.prepareStatement(sql, ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
ps.setFetchSize(1_0000);
// PreparedStatement ps = con.prepareStatement(sql);
long start = System.currentTimeMillis();
// Tools.sleep(10_000);
ResultSet rs = ps.executeQuery();
long spent = Tools.spent(start);
System.out.println(formatLogInfoWithIdx(" spent : 0 ms ", spent));
// Tools.sleep(10_000);
if (rs.next())
System.out.println(JSON.toJSONString(new ResultSet2MapAdapter(rs).toMap()));
附上截图
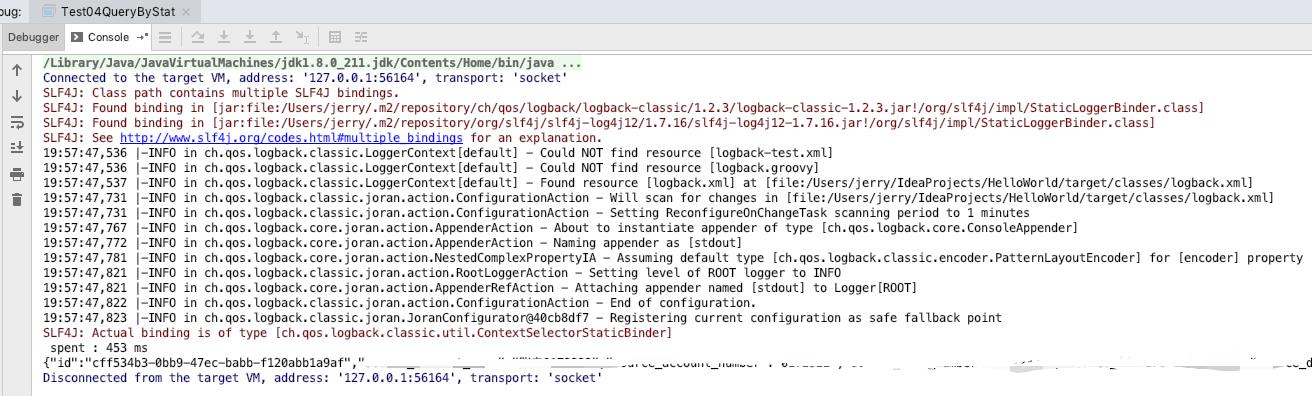
我们俩看看服务器返回的数据
呵呵 这里似乎是以 fetchSize 来分批次获取的数据, 这个就优秀了, 所以我们现在 limit 500000 也不怕了

PortalSuspended
参见 44.4. 消息格式
spark 中怎么处理?
同样的配置, 配置的方式有所不同

接着来看看 应用于项目的情况, 项目是配置了 -Xmx512M -Xms512M, 另外需要处理的目标表尾 200w 的数据

master:~ jerry$ jstat -gcutil 5549 3000
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
5.65 0.00 60.00 58.65 91.60 91.50 106 1.414 6 1.393 2.807
// 省略 n 行日志输出
77.70 0.00 82.00 82.55 90.91 91.39 210 3.518 10 5.199 8.717
// 省略 n 行日志输出
0.00 70.61 93.95 52.14 90.81 91.03 425 7.916 20 10.062 17.978
// 省略 n 行日志输出
78.36 0.00 36.00 93.44 89.21 88.74 750 13.359 39 16.804 30.163
// 省略 n 行日志输出
46.23 0.00 59.99 57.30 89.24 88.99 1000 16.730 47 20.160 36.890
0.00 81.67 1.52 88.51 89.35 89.18 1113 18.297 48 20.696 38.994参考
Tried to send an out-of-range integer as a 2-byte value: 40003
以上是关于17 记一次 spark 读取大数据表 OOM OutOfMemoryError: GC overhead limit exceeded的主要内容,如果未能解决你的问题,请参考以下文章