爱奇艺内容中台数据中心的设计与实现
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爱奇艺内容中台数据中心的设计与实现相关的知识,希望对你有一定的参考价值。
互联网技术发展至今,当业务复杂度比较高的时候,采用微服务化是一个有效的手段,但是随着服务的拆分,数据管理工作变得极具挑战。数据中心(OLTP)通过对数据的统一收集和管理,一方面可以建立数据之间的联系,从而带来更大的价值;另一方面还可以提供强大的数据阅览、数据分析、挖掘数据等能力,进而为企业创造价值收益。数据中心(OLTP)不仅可以为不同业务线屏蔽技术难点,还可以降低业务逻辑开发的复杂度,使得开发同学能够专注于业务逻辑的开发。
利用数据中心(OLTP)整合不同业务线的数据,解决数据孤岛问题已经是各个互联网企业的必用手段。
本文将分享爱奇艺内容中台数据中心(OLTP)的设计与实现。
01
方案设计与实现
之前各个业务线自己维护自己的数据和接口,这样既不利于第三方的接入,也浪费了人力进行重复建设,为了解决诸多类似问题,我们进行了如下设计。
2.1 方案设计目标
首先我们梳理了目前系统存在的各种亟待解决的问题:
1.数据孤岛:无法全面的看到内容运营的所有数据
2.重复建设:各业务团队均需具备同样能力的服务建设
3.对接复杂:各业务团队接口规范不统一,增加对接难度
4.耦合严重:各业务团队因需要共享数据,导致服务严重互相依赖
5.开发繁琐:各业务团队需要考虑自研数据中心(OLTP)的技术痛点和难点,无法做到专人做专事,即业务开发只关注自身
为了满足业务长远的发展,我们还制定了一些需要达到的目标:
1.支持百亿级数据的存储
2.支持高QPS的读、写请求
3.统一的字段变化消息通知
4.极少的运维成本,页面操作添加字段
5.通用的查询与保存能力,避免个性化需求带来的额外开发成本
2.2 业务架构图
基于以上的目标我们设计了内容中台数据中心的业务架构,如下图:
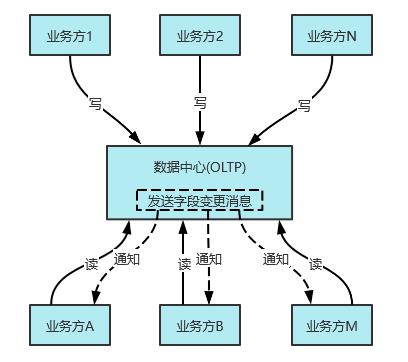
图1数据中心(OLTP)业务架构图
数据写入方统一将数据写到数据中心(OLTP),然后数据中心(OLTP)统一对外广播字段的变化,其它业务方监听自身关心的字段变化。同一个业务方既可以是写入方也可以是读取方。
2.3 数据一致性方案
由于数据中心(OLTP)将数据分别存储到了MongoDB和ES,这样就引入了数据一致性的问题。为了解决这个问题我们调研了业内的一些方案最终选定了最终一致性的方案。具体设计如下图:

图2数据一致性方案设计图
为了避免脏数据的产生,我们设计字段权限控制,字段有归属的业务方,非归属的业务方没有权限写入该字段。由于实际使用场景中,我们大量使用ES查询数据,所以我们设计了MongoDB字段与ES字段的映射,业务方只需要分别创建MongoDB和ES的字段元数据,并建立好两者之间的映射关系。在投递数据的时候只需要投递一份原始数据,我们即可保存到MongoDB和ES中。为了避免ES中字段的相互覆盖问题,我们采取的方案是查询MongoDB中的最新数据并根据映射关系转化为ES结构,然后将ES中对应的文档进行整体覆盖。
2.4 数据高可用方案
数据中心(OLTP)存储着业务的关键数据,其重要性不言而喻,所以一定要保证服务的高可用,所以我们设计了高可用的方案,具体如下图:

图3数据高可用方案设计图
方案中为了支持海量数据存储采用了分布式文件的存储能力。分片MongoDB集群采用同城多地部署,达到同城多活的效果,以提升集群的容灾能力。
为了避免单点问题,我们设计了实时数据备份,利用服务配置化双写能力,将数据写入备份集群。代码层面设计数据库切换开关,以支持主集群不可用后,可以方便的切换至备份集群,从而达到数据高可用。
为了满足数据报表等大数据处理需求我们规划了离线数仓,充分利用MongoDB的备用集群能力。在日常使用中,备用集群可以为大数据平台和离线数仓提供数据支撑。离线数仓可以通过指定时间读取备用集群数据,如将9时、12时、18时共3份快照(可根据业务自身的特征自定义快照时间)进行备份。可依据离线数仓数据来恢复指定时间点的数据。
2.5 海量数据存储方案
随着互联网的高速发展,很多业务场景的数据量都达到了上亿的级别甚至更多,这就涉及到了海量数据的存储问题。由于我们的业务场景也达到了上亿的级别,所以我们设计了海量数据存储方案。
DB层面:DB层面使用分布式文件存储的DB,详见2.4中MongoDB的分片集群,支持横向扩展,可以支撑大数据量存储,且性能仅受限于单分片collection的数据量级。
ES层面:ES在创建index时需要指定索引的分片个数,一旦创建后不可修改,所以我们在创建索引时需要评估好该索引的数据量级与增长趋势。当索引单分片的数据量级过大,会导致性能急剧下降,此时我们可以使用ES的reIndex API进行索引重建,但该操作会最大程度占用ESserver端的服务资源,导致影响正常业务。为了解决此类问题我们可以利用ES的别名Alias + 分库分表的思路,设计出支持不受数据量级限制的ES索引。ES的别名下可挂载多个真实的索引名,而我们按照一定的规则对索引数据进行拆分,将数据写入到拆分后的真实索引中,而真实索引挂在在同一个别名下,这样可以做到读业务方无感知的效果。但是ES的别名并不具备写入能力(别名下多个索引时),所以我们需要自己执行路由规则,进行索引拆分和写入。具体设计方案如下图:

图4ES索引拆分写入与查询流程图
02
最佳实践
3.1 标准化、通用化消息通知
为了解决各业务团队因需要共享数据,导致服务严重互相依赖的问题,我们设计了标准化、通用化的消息通知机制。用户只需要引入数据中心(OLTP) SDK ,并做简单的配置,便可监听到指定字段发生变化时的消息,以触发自身的业务逻辑。数据中心(OLTP)消息通知 SDK 设计图如下:
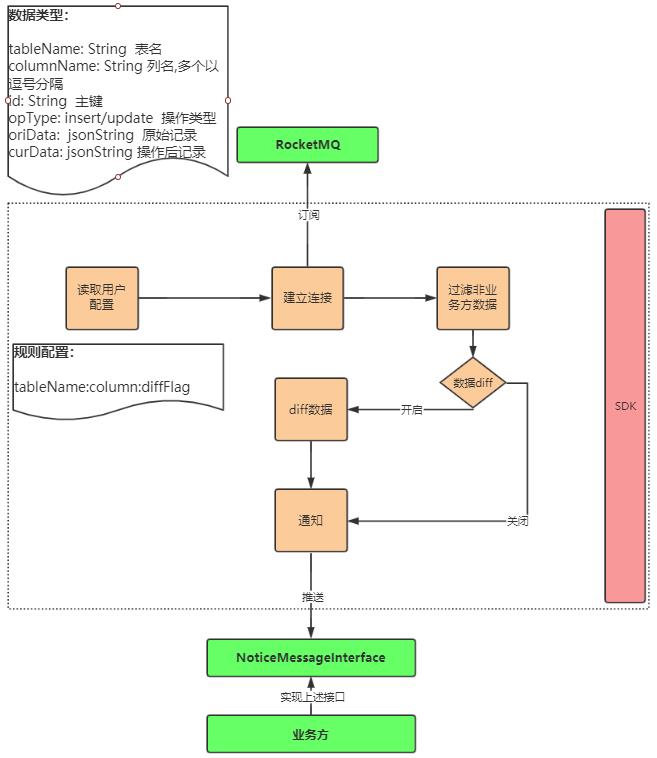
图5 消息通知SDK设计图
当数据中心(OLTP)的字段发生变化时,会向RMQ 消息队列投放相关信息;SDK根据业务方配置信息会订阅 RMQ 消息队列,并根据用户的订阅配置,过滤掉用户不关心的消息。
SDK设计的关键点:
一、将RMQ封装起来,降低业务方的复杂度;
二、轻服务端重客户端,将消息的过滤与去重放到SDK,降低服务端的压力;
三、消息的过滤可以支持到二级字段维度,更精确的过滤掉业务方不需要的消息,减少客户端的压力。
3.2 技术难点
在数据中心(OLTP)的应用实践当中我们遇到了一些技术挑战,经过研究我们进行了很好的解决:
数据库乐观锁锁粒度控制
数据中心(OLTP)一张表中的字段都有归属的业务方,如果我们用一个version作为乐观锁控制,那A业务方在保存a字段时,B业务方就无法保存b字段,会导致服务性能的急剧下降,这不是我们期望的结果。
我们期望A业务方保存归属字段时,B业务方不受影响,做到业务隔离。而A业务方乐观锁只控制A业务方并发保存时的数据一致性。所以我们的乐观锁version可以以业务方维度设计,可以做到锁隔离和锁粒度的控制,进而提升保存性能。
ES批量写入
作为数据中心(OLTP),避免不了业务方批量写入数据的场景。而此时我们可以利用ES的Bulk API,来提升ES的写入性能。经验证ES的Bulk API比单条数据写入index API性能高几十倍(针对大数据量写入)。
Bulk API官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.6/docs-bulk.html#docs-bulk
ES之深度分页查询
ES在分页查询时,为避免深度翻页对server端带来的压力,故默认控制检索深度不能超过1万条。如果我们需要实时查询深度分页数据时,可以使用Search After API进行查询;如果我们需要快速查询深度分页数据,可以使用Scroll API进行查询。经验证性能远大于深度翻页,且无深度限制。
业务方维度控制
由于数据中心(OLTP)需要跟多个业务方交互,为了避免某个业务方流量异常影响其它业务方,我们设计了业务方维度的分布式限速,从而达到业务方之间的隔离。
03
效果与展望
数据中心(OLTP)上线后,可以看到内容运营的所有数据,解决了数据孤岛问题;
各写入方只需要按规范将数据投递给数据中心(OLTP)即可对外提供数据,解决了重复建设的问题;
查询业务方只需要对接数据中心(OLTP)即可获取所需的所有内容运营数据,解决了对接复杂的问题;
各业务团队统一从数据中心(OLTP)获取需要的数据,不再需要跟数据写入方交互,解决了业务系统耦合严重的问题。
目前数据中心(OLTP)已对接26个业务方,部署物理隔离的独立集群4套,流量较大的集群,读QPS超过2K,写入QPS超过500,最大的表数据量已达2.5亿。
当然数据中心(OLTP)还需要持续建设,为了数据的高可用我们设计了主备集群,但这样也带来了主备集群间的数据一致性问题——数据中心的数据量会越来越大。为了看到整个数据的全貌,传统的技术已经无法解决,我们目前正在打通此系统与离线数据平台(OLAP)平台的通路,借助实时数仓与离线数仓的技术,全面赋能业务需要。
以上是关于爱奇艺内容中台数据中心的设计与实现的主要内容,如果未能解决你的问题,请参考以下文章