Spring实战Spring注解配置工作原理源码解析
Posted Herman-Hong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring实战Spring注解配置工作原理源码解析相关的知识,希望对你有一定的参考价值。
一、背景知识
在 【Spring实战】Spring容器初始化完成后执行初始化数据方法一文中说要分析其实现原理,于是就从源码中寻找答案,看源码容易跑偏,因此应当有个主线,或者带着问题、目标去看,这样才能最大限度的提升自身代码水平。由于上文中大部分都基于注解进行设置的( Spring实战系列篇demo大部分也都是基于注解实现的),因此就想弄明白Spring中注解是怎么工作的,这个也是分析上文中实现原理的一个基础。于是索性解析下Spring中注解的工作原理。二、从context:component-scan标签或@ComponentScan注解说起
如果想要使用Spring注解,那么首先要在配置文件中配置context:component-scan标签或者在配置类中添加@ComponentScan注解。题外话:现在Spring已经完全可以实现无xml(当然有些还是需要xml配置来实现的)的配置,甚至都不需要web.xml,当然这需要Servlet3.0服务器的支持(如Tomcat7或者更高版本)。Spirng In Action Fourth是针对三种bean的装配机制(xml进行显示配置、java中进行显示配置、隐式的bean发现机制和自动装配)的使用是这样建议的:
如果要使用自动配置机制,就要在配置文件中配置context:component-scan标签或者在配置类中添加@ComponentScan注解。基于 【Spring实战】----Spring配置文件的解析 篇文章,本文还是基于xml中的自定义标签进行解析,当然也可以直接看@ComponentScan注解的解析(ComponentScanAnnotationParser.java,这其中还牵扯到@Configuration以及另外的知识点)。
三、context:component-scan标签解析
以实战篇系列demo为例进行分析 <context:component-scan base-package="com.mango.jtt"></context:component-scan>从 【Spring实战】----Spring配置文件的解析中可知,标签的处理器为spring.handlers
http\\://www.springframework.org/schema/context=org.springframework.context.config.ContextNamespaceHandlerregisterBeanDefinitionParser("component-scan", new ComponentScanBeanDefinitionParser());在ComponentScanBeanDefinitionParser.java中进行处理
@Override
public BeanDefinition parse(Element element, ParserContext parserContext)
String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
// Actually scan for bean definitions and register them.
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element); //得到扫描器
Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages); //扫描文件,并转化为spring bean,并注册
registerComponents(parserContext.getReaderContext(), beanDefinitions, element); //注册其他相关组件
return null;
从上述代码中可知,其作用就是扫描basePackages下的文件,转化为spring中的bean结构,并将其注册到容器中;最后是注册相关组件(主要是注解处理器)。注解需要注解处理器来处理。
要知道ComponentScanBeanDefinitionParser扫描文件并转化成spring bean的原则的,就需要看下其定义的属性值:
private static final String BASE_PACKAGE_ATTRIBUTE = "base-package";
private static final String RESOURCE_PATTERN_ATTRIBUTE = "resource-pattern";
private static final String USE_DEFAULT_FILTERS_ATTRIBUTE = "use-default-filters";
private static final String ANNOTATION_CONFIG_ATTRIBUTE = "annotation-config";
private static final String NAME_GENERATOR_ATTRIBUTE = "name-generator";
private static final String SCOPE_RESOLVER_ATTRIBUTE = "scope-resolver";
private static final String SCOPED_PROXY_ATTRIBUTE = "scoped-proxy";
private static final String EXCLUDE_FILTER_ELEMENT = "exclude-filter";
private static final String INCLUDE_FILTER_ELEMENT = "include-filter";
private static final String FILTER_TYPE_ATTRIBUTE = "type";
private static final String FILTER_EXPRESSION_ATTRIBUTE = "expression";先简单解析下上述属性的作用
- base-package:为必须配置属性,指定了spring需要扫描的跟目录名称,可以使用”,” “;” “\\t\\n(回车符)”来分割多个包名
- resource-pattern:配置扫描资源格式.默认”
**/*.class” - use-default-filters:是否使用默认扫描策略,默认为”true”,会自动扫描指定包下的添加了如下注解的类,@Component, @Repository, @Service,or @Controller

- annotation-config:是否启用默认配置,默认为”true”,该配置会在BeanDefinition注册到容器后自动注册一些BeanPostProcessors对象到容器中.这些处理器用来处理类中Spring’s @Required and
@Autowired, JSR 250’s @PostConstruct, @PreDestroy and @Resource (如果可用),
JAX-WS’s @WebServiceRef (如果可用), EJB 3’s @EJB (如果可用), and JPA’s
@PersistenceContext and @PersistenceUnit (如果可用),但是该属性不会处理Spring’s @Transactional 和 EJB 3中的@TransactionAttribute注解对象,这两个注解是通过<tx:annotation-driven>元素处理过程中对应的BeanPostProcessor来处理的. - include-filter:如果有自定义元素可以在该处配置
- exclude-filter:配置哪些类型的类不需要扫描
- 注意:
</context:component-scan>元素中默认配置了annotation-config,所以不需要再单独配置</annotation-config>元素.
protected ClassPathBeanDefinitionScanner configureScanner(ParserContext parserContext, Element element)
boolean useDefaultFilters = true;
if (element.hasAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE))
useDefaultFilters = Boolean.valueOf(element.getAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE));
// Delegate bean definition registration to scanner class.
ClassPathBeanDefinitionScanner scanner = createScanner(parserContext.getReaderContext(), useDefaultFilters); //包含了扫描策略配置
scanner.setResourceLoader(parserContext.getReaderContext().getResourceLoader());
scanner.setEnvironment(parserContext.getReaderContext().getEnvironment());
scanner.setBeanDefinitionDefaults(parserContext.getDelegate().getBeanDefinitionDefaults());
scanner.setAutowireCandidatePatterns(parserContext.getDelegate().getAutowireCandidatePatterns());
if (element.hasAttribute(RESOURCE_PATTERN_ATTRIBUTE))
scanner.setResourcePattern(element.getAttribute(RESOURCE_PATTERN_ATTRIBUTE)); //配置扫描资源格式
try
parseBeanNameGenerator(element, scanner); //配置名称生成器
catch (Exception ex)
parserContext.getReaderContext().error(ex.getMessage(), parserContext.extractSource(element), ex.getCause());
try
parseScope(element, scanner); //配置元数据解析器
catch (Exception ex)
parserContext.getReaderContext().error(ex.getMessage(), parserContext.extractSource(element), ex.getCause());
parseTypeFilters(element, scanner, parserContext); //配置包含和不包含过滤
return scanner;
看一下默认扫描策略的配置
/**
* Register the default filter for @link Component @Component.
* <p>This will implicitly register all annotations that have the
* @link Component @Component meta-annotation including the
* @link Repository @Repository, @link Service @Service, and
* @link Controller @Controller stereotype annotations.
* <p>Also supports Java EE 6's @link javax.annotation.ManagedBean and
* JSR-330's @link javax.inject.Named annotations, if available.
*
*/
@SuppressWarnings("unchecked")
protected void registerDefaultFilters()
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
logger.debug("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");
catch (ClassNotFoundException ex)
// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
try
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
logger.debug("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");
catch (ClassNotFoundException ex)
// JSR-330 API not available - simply skip.
- 默认过滤器主要扫描@Component @Repository @Service @Controller注解的类,同样可以通过配置类扫描过滤器来扫描自定义注解的类。
- 当类路径下有javax.annotation.ManagedBean和javax.inject.Named类库时支持这2个注解扫描。
其扫描过程如下: - 首先构造一个ClassPathBeanDefinitionScanner对象,需要传递一个BeanDefinitionRegistry对象。
- 根据配置文件配置属性设置scanner的扫描属性,比如”resource-pattern”, “name-generator”, “scope-resolver”等。
- 调用scanner.doScan(String… basePackages)方法完成候选类的自动扫描。
下面看一下doScan
/**
* Perform a scan within the specified base packages,
* returning the registered bean definitions.
* <p>This method does <i>not</i> register an annotation config processor
* but rather leaves this up to the caller.
* @param basePackages the packages to check for annotated classes
* @return set of beans registered if any for tooling registration purposes (never @code null)
*/
protected Set<BeanDefinitionHolder> doScan(String... basePackages)
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<BeanDefinitionHolder>();
for (String basePackage : basePackages)
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates)
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition)
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName); //配置bena属性
if (candidate instanceof AnnotatedBeanDefinition)
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate); //配置通过注解设置的便属性
if (checkCandidate(beanName, candidate))
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
return beanDefinitions;
实际上扫描文件并包装成BeanDefinition是由findCandidateComponents来做的
/**
* Scan the class path for candidate components.
* @param basePackage the package to check for annotated classes
* @return a corresponding Set of autodetected bean definitions
*/
public Set<BeanDefinition> findCandidateComponents(String basePackage)
Set<BeanDefinition> candidates = new LinkedHashSet<BeanDefinition>();
try
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + "/" + this.resourcePattern;
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources)
if (traceEnabled)
logger.trace("Scanning " + resource);
if (resource.isReadable())
try
MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
if (isCandidateComponent(metadataReader))
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd))
if (debugEnabled)
logger.debug("Identified candidate component class: " + resource);
candidates.add(sbd);
else
if (debugEnabled)
logger.debug("Ignored because not a concrete top-level class: " + resource);
else
if (traceEnabled)
logger.trace("Ignored because not matching any filter: " + resource);
catch (Throwable ex)
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
else
if (traceEnabled)
logger.trace("Ignored because not readable: " + resource);
catch (IOException ex)
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
return candidates;
大致的流程如下:
(1)先根据context:component-scan 中属性的base-package="com.mango.jtt"配置转换为classpath*:com/mango/jtt/**/*.class(默认格式),并扫描对应下的class和jar文件并获取类对应的路径,返回Resources
(2)根据 指定的不扫描包, 指定的扫描包配置进行过滤不包含的包对应下的class和jar。
(3)封装成BeanDefinition放到队列里。
实际上,是把所有包下的class文件都扫描了的,并且利用asm技术读取java字节码并转化为MetadataReader中的AnnotationMetadataReadingVisitor结构MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);SimpleMetadataReader(Resource resource, ClassLoader classLoader) throws IOException
InputStream is = new BufferedInputStream(resource.getInputStream());
ClassReader classReader;
try
classReader = new ClassReader(is);
catch (IllegalArgumentException ex)
throw new NestedIOException("ASM ClassReader failed to parse class file - " +
"probably due to a new Java class file version that isn't supported yet: " + resource, ex);
finally
is.close();
AnnotationMetadataReadingVisitor visitor = new AnnotationMetadataReadingVisitor(classLoader);
classReader.accept(visitor, ClassReader.SKIP_DEBUG);
this.annotationMetadata = visitor;
// (since AnnotationMetadataReadingVisitor extends ClassMetadataReadingVisitor)
this.classMetadata = visitor;
this.resource = resource;
此处不深究牛X的asm技术,继续看其两个if判断,只有符合这两个if的才add到candidates,也就是候选者BeanDefinition,函数名字起得名副其实。
if (isCandidateComponent(metadataReader))
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd))
if (debugEnabled)
logger.debug("Identified candidate component class: " + resource);
candidates.add(sbd);
else
if (debugEnabled)
logger.debug("Ignored because not a concrete top-level class: " + resource);
先看第一个判断
/**
* Determine whether the given class does not match any exclude filter
* and does match at least one include filter.
* @param metadataReader the ASM ClassReader for the class
* @return whether the class qualifies as a candidate component
*/
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException
for (TypeFilter tf : this.excludeFilters)
if (tf.match(metadataReader, this.metadataReaderFactory))
return false;
for (TypeFilter tf : this.includeFilters)
if (tf.match(metadataReader, this.metadataReaderFactory))
return isConditionMatch(metadataReader);
return false;
第二个if就是判断类是否是实现类,抽象类好接口类都不不可以
/**
* Determine whether the given bean definition qualifies as candidate.
* <p>The default implementation checks whether the class is concrete
* (i.e. not abstract and not an interface). Can be overridden in subclasses.
* @param beanDefinition the bean definition to check
* @return whether the bean definition qualifies as a candidate component
*/
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition)
return (beanDefinition.getMetadata().isConcrete() && beanDefinition.getMetadata().isIndependent());
至此,注解扫描分析完了,看一下bean注册,回到doScan中
if (checkCandidate(beanName, candidate))
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
再看下其他组件注册,回到最初的parse
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);protected void registerComponents(
XmlReaderContext readerContext, Set<BeanDefinitionHolder> beanDefinitions, Element element)
Object source = readerContext.extractSource(element);
CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), source);
for (BeanDefinitionHolder beanDefHolder : beanDefinitions)
compositeDef.addNestedComponent(new BeanComponentDefinition(beanDefHolder));
// Register annotation config processors, if necessary.
boolean annotationConfig = true;
if (element.hasAttribute(ANNOTATION_CONFIG_ATTRIBUTE)) //本例中没有配置annotation-config,默认为true
annotationConfig = Boolean.valueOf(element.getAttribute(ANNOTATION_CONFIG_ATTRIBUTE));
if (annotationConfig)
Set<BeanDefinitionHolder> processorDefinitions =
AnnotationConfigUtils.registerAnnotationConfigProcessors(readerContext.getRegistry(), source); //注册注解处理器
for (BeanDefinitionHolder processorDefinition : processorDefinitions)
compositeDef.addNestedComponent(new BeanComponentDefinition(processorDefinition));
readerContext.fireComponentRegistered(compositeDef); //目前没啥卵用,EmptyReaderEventListener.java中都是空操作,扩展用
上述代码的作用主要是注册注解处理器,本例中没有配置annotation-config,默认值为true,这里也就说明了为什么配置了<context:component-scan>标签就不需要再配置<context:annotation-config>标签的原因。看下注册注解处理器: org.springframework.context.annotation.AnnotationConfigUtils.java
/**
* Register all relevant annotation post processors in the given registry.
* @param registry the registry to operate on
* @param source the configuration source element (already extracted)
* that this registration was triggered from. May be @code null.
* @return a Set of BeanDefinitionHolders, containing all bean definitions
* that have actually been registered by this call
*/
public static Set<BeanDefinitionHolder> registerAnnotationConfigProcessors(
BeanDefinitionRegistry registry, Object source)
DefaultListableBeanFactory beanFactory = unwrapDefaultListableBeanFactory(registry);
if (beanFactory != null)
if (!(beanFactory.getDependencyComparator() instanceof AnnotationAwareOrderComparator))
beanFactory.setDependencyComparator(AnnotationAwareOrderComparator.INSTANCE); //设置注解比较器,为Spring中的Order提供支持
if (!(beanFactory.getAutowireCandidateResolver() instanceof ContextAnnotationAutowireCandidateResolver))
beanFactory.setAutowireCandidateResolver(new ContextAnnotationAutowireCandidateResolver()); //设置AutowireCandidateResolver,为qualifier注解和lazy注解提供支持
Set<BeanDefinitionHolder> beanDefs = new LinkedHashSet<BeanDefinitionHolder>(4);
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME))
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)); //注册@Configuration处理器
if (!registry.containsBeanDefinition(AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME))
RootBeanDefinition def = new RootBeanDefinition(AutowiredAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME));//注册@Autowired、@Value、@Inject处理器
if (!registry.containsBeanDefinition(REQUIRED_ANNOTATION_PROCESSOR_BEAN_NAME))
RootBeanDefinition def = new RootBeanDefinition(RequiredAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, REQUIRED_ANNOTATION_PROCESSOR_BEAN_NAME));//注册@Required处理器
// Check for JSR-250 support, and if present add the CommonAnnotationBeanPostProcessor.
if (jsr250Present && !registry.containsBeanDefinition(COMMON_ANNOTATION_PROCESSOR_BEAN_NAME))
RootBeanDefinition def = new RootBeanDefinition(CommonAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, COMMON_ANNOTATION_PROCESSOR_BEAN_NAME));//在支持JSR-250条件下注册javax.annotation包下注解处理器,包括@PostConstruct、@PreDestroy、@Resource注解等
// Check for JPA support, and if present add the PersistenceAnnotationBeanPostProcessor.
if (jpaPresent && !registry.containsBeanDefinition(PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME))
RootBeanDefinition def = new RootBeanDefinition();
try
def.setBeanClass(ClassUtils.forName(PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME,
AnnotationConfigUtils.class.getClassLoader()));
catch (ClassNotFoundException ex)
throw new IllegalStateException(
"Cannot load optional framework class: " + PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME, ex);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME));//支持jpa的条件下,注册org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor处理器,处理jpa相关注解
if (!registry.containsBeanDefinition(EVENT_LISTENER_PROCESSOR_BEAN_NAME))
RootBeanDefinition def = new RootBeanDefinition(EventListenerMethodProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_PROCESSOR_BEAN_NAME));//注册@EventListener处理器
if (!registry.containsBeanDefinition(EVENT_LISTENER_FACTORY_BEAN_NAME))
RootBeanDefinition def = new RootBeanDefinition(DefaultEventListenerFactory.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_FACTORY_BEAN_NAME));//注册支持@EventListener注解的处理器
return beanDefs;
真正的注册是如下函数:
private static BeanDefinitionHolder registerPostProcessor(
BeanDefinitionRegistry registry, RootBeanDefinition definition, String beanName)
definition.setRole(BeanDefinition.ROLE_INFRASTRUCTURE); //角色属于后台角色,框架内部使用,和最终用户无关
registry.registerBeanDefinition(beanName, definition); //也是注册到beanFactory中的beanDefinitionMap中,其实和注册bean一样,并且beanName是定义好了的
return new BeanDefinitionHolder(definition, beanName);
注册注解处理器的过程也是讲处理包装成RootBeanDefinition,放到beanFactory(这里是DefaultListableBeanFactory)中的beanDefinitionMap中。
至此,标签<context:component-scan>的解析已经分析完了,总结如下: 1)根据配置利用asm技术扫描.class文件,并将包含@Component及元注解为@Component的注解@Controller、@Service、@Repository或者还支持Java EE 6的@link javax.annotation.ManagedBean和jsr - 330的 @link javax.inject.Named,如果可用。的bean注册到beanFactory中 2)注册注解后置处理器,主要是处理属性或方法中的注解,包含: 注册@Configuration处理器ConfigurationClassPostProcessor, 注册@Autowired、@Value、@Inject处理器AutowiredAnnotationBeanPostProcessor, 注册@Required处理器RequiredAnnotationBeanPostProcessor、 在支持JSR-250条件下注册javax.annotation包下注解处理器CommonAnnotationBeanPostProcessor,包括@PostConstruct、@PreDestroy、@Resource注解等、 支持jpa的条件下,注册org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor处理器,处理jpa相关注解 注册@EventListener处理器EventListenerMethodProcessor
使用注解的.class文件也扫描完了,注解处理器也注册完了,那么注解是什么时候处理的呢?下一节会继续分析。
四、注解处理器实例化
要想使用注解处理器,必须要实例化注解处理器,那么其实例化是在哪里进行的呢,这里还需要回到org.springframework.context.support.AbstractApplicationContext.java中的refresh()函数
@Override
public void refresh() throws BeansException, IllegalStateException
synchronized (this.startupShutdownMonitor)
// Prepare this context for refreshing.
prepareRefresh(); //初始化前的准备,例如对系统属性或者环境变量进行准备及验证
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory(); //初始化BeanFactory,解析xml配置文件,其中标签<context:component-scan>就是在这里解析的
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory); //配置工厂的标准上下文特征,例如上下文的类加载器和后处理器。
try
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory); //子类覆盖方法,做特殊处理,主要是后处理器相关
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory); //激活各种beanFactory处理器,实例化并调用所有注册的BeanFactoryPostProcessor bean,
如果给定的话,尊重显式的顺序。注意这里和扫描时的bean处理器的区别。
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory); //实例化并调用所有已注册的BeanPostProcessor bean,如果给定的话,尊重显式的顺序。
必须在应用程序bean的任何实例化之前调用它。这是本节的分析重点。这里就是实例化上面注册的bean处理器
// Initialize message source for this context.
initMessageSource(); //初始化消息资源,国际化等用
// Initialize event multicaster for this context.
initApplicationEventMulticaster(); //初始化应用事件广播
// Initialize other special beans in specific context subclasses.
onRefresh(); //子类扩展
// Check for listener beans and register them.
registerListeners(); //注册监听器
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory); //实例化非延迟加载单例,包括所有注册非延迟加载bean的实例化
// Last step: publish corresponding event.
finishRefresh(); //完成刷新过程,通知生命周期处理器lifecycleProcessor刷新过程,同时发出ContextRefreshEvent通知别人
catch (BeansException ex)
if (logger.isWarnEnabled())
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
finally
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
从上述代码看,注解处理器也是在registerBeanPostProcessors(beanFactory);中进行实例化的:
public static void registerBeanPostProcessors(
ConfigurableListableBeanFactory beanFactory, AbstractApplicationContext applicationContext)
//获取所有beanFactory注册的BeanPostProcessor类型的bean处理器,三中注册的bean处理器在这里都会获取到
String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanPostProcessor.class, true, false);
// Register BeanPostProcessorChecker that logs an info message when
// a bean is created during BeanPostProcessor instantiation, i.e. when
// a bean is not eligible for getting processed by all BeanPostProcessors.
int beanProcessorTargetCount = beanFactory.getBeanPostProcessorCount() + 1 + postProcessorNames.length;
beanFactory.addBeanPostProcessor(new BeanPostProcessorChecker(beanFactory, beanProcessorTargetCount));
//以下是实例化bean处理器,并按照次序或无序添加到BeanFactory的beanPostProcessors列表中
// Separate between BeanPostProcessors that implement PriorityOrdered,
// Ordered, and the rest.
List<BeanPostProcessor> priorityOrderedPostProcessors = new ArrayList<BeanPostProcessor>();
List<BeanPostProcessor> internalPostProcessors = new ArrayList<BeanPostProcessor>();
List<String> orderedPostProcessorNames = new ArrayList<String>();
List<String> nonOrderedPostProcessorNames = new ArrayList<String>();
for (String ppName : postProcessorNames)
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class))
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
priorityOrderedPostProcessors.add(pp);
if (pp instanceof MergedBeanDefinitionPostProcessor)
internalPostProcessors.add(pp);
else if (beanFactory.isTypeMatch(ppName, Ordered.class))
orderedPostProcessorNames.add(ppName);
else
nonOrderedPostProcessorNames.add(ppName);
// First, register the BeanPostProcessors that implement PriorityOrdered.
sortPostProcessors(beanFactory, priorityOrderedPostProcessors);
registerBeanPostProcessors(beanFactory, priorityOrderedPostProcessors);
// Next, register the BeanPostProcessors that implement Ordered.
List<BeanPostProcessor> orderedPostProcessors = new ArrayList<BeanPostProcessor>();
for (String ppName : orderedPostProcessorNames)
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
orderedPostProcessors.add(pp);
if (pp instanceof MergedBeanDefinitionPostProcessor)
internalPostProcessors.add(pp);
sortPostProcessors(beanFactory, orderedPostProcessors);
registerBeanPostProcessors(beanFactory, orderedPostProcessors);
// Now, register all regular BeanPostProcessors.
List<BeanPostProcessor> nonOrderedPostProcessors = new ArrayList<BeanPostProcessor>();
for (String ppName : nonOrderedPostProcessorNames)
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
nonOrderedPostProcessors.add(pp);
if (pp instanceof MergedBeanDefinitionPostProcessor)
internalPostProcessors.add(pp);
registerBeanPostProcessors(beanFactory, nonOrderedPostProcessors);
// Finally, re-register all internal BeanPostProcessors.
sortPostProcessors(beanFactory, internalPostProcessors);
registerBeanPostProcessors(beanFactory, internalPostProcessors);
beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(applicationContext));
/**
* Register the given BeanPostProcessor beans.
*/
private static void registerBeanPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanPostProcessor> postProcessors)
for (BeanPostProcessor postProcessor : postProcessors)
beanFactory.addBeanPostProcessor(postProcessor);
@Override
public void addBeanPostProcessor(BeanPostProcessor beanPostProcessor)
Assert.notNull(beanPostProcessor, "BeanPostProcessor must not be null");
this.beanPostProcessors.remove(beanPostProcessor);
this.beanPostProcessors.add(beanPostProcessor);
if (beanPostProcessor instanceof InstantiationAwareBeanPostProcessor)
this.hasInstantiationAwareBeanPostProcessors = true;
if (beanPostProcessor instanceof DestructionAwareBeanPostProcessor)
this.hasDestructionAwareBeanPostProcessors = true;
五、注解处理器的调用
以
【Spring实战】Spring容器初始化完成后执行初始化数据方法中的注解@PostConstruct为例分析其注解处理器的调用。四种分析了处理器的实例化,看一下@postConstruct处理器CommonAnnotationBeanPostProcessor.java,其构造函数如下:
/**
* Create a new CommonAnnotationBeanPostProcessor,
* with the init and destroy annotation types set to
* @link javax.annotation.PostConstruct and @link javax.annotation.PreDestroy,
* respectively.
*/
public CommonAnnotationBeanPostProcessor()
setOrder(Ordered.LOWEST_PRECEDENCE - 3);
setInitAnnotationType(PostConstruct.class);
setDestroyAnnotationType(PreDestroy.class);
ignoreResourceType("javax.xml.ws.WebServiceContext");
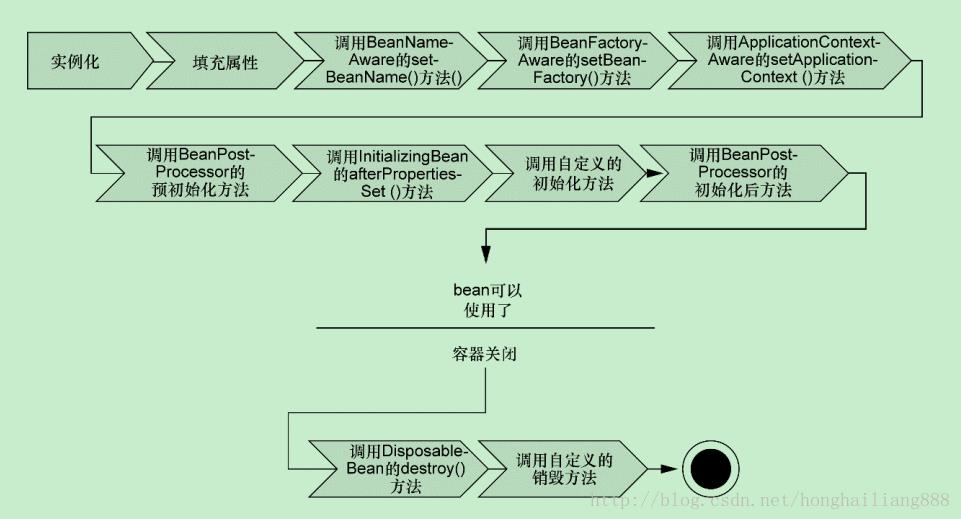
其中@PostConstruct处理器的调用就是在初始化bean时调用的,而属性的注解,如@Autowired处理器是在属性注入的时候调用的。先看下调用栈
@PostConstuct的
at com.mango.jtt.init.InitMango.init(InitMango.java:29)
at sun.reflect.NativeMethodAccessorImpl.invoke0(NativeMethodAccessorImpl.java:-1)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleElement.invoke(InitDestroyAnnotationBeanPostProcessor.java:365)
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleMetadata.invokeInitMethods(InitDestroyAnnotationBeanPostProcessor.java:310)
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:133)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsBeforeInitialization(AbstractAutowireCapableBeanFactory.java:408)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1570)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:545)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:482)
at org.springframework.beans.factory.support.AbstractBeanFactory$1.getObject(AbstractBeanFactory.java:306)
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:230)
- locked <0xe68> (a java.util.concurrent.ConcurrentHashMap)
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:302)
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:197)
at org.springframework.beans.factory.support.DefaultListableBeanFactory.preInstantiateSingletons(DefaultListableBeanFactory.java:776)
at org.springframework.context.support.AbstractApplicationContext.finishBeanFactoryInitialization(AbstractApplicationContext.java:861)
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:541)
- locked <0x19af> (a java.lang.Object)
at org.springframework.web.context.ContextLoader.configureAndRefreshWebApplicationContext(ContextLoader.java:444)
at org.springframework.web.context.ContextLoader.initWebApplicationContext(ContextLoader.java:326)
at org.springframework.web.context.ContextLoaderListener.contextInitialized(ContextLoaderListener.java:107)@Autowired处理器的调用栈
at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.postProcessPropertyValues(AutowiredAnnotationBeanPostProcessor.java:347)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.populateBean(AbstractAutowireCapableBeanFactory.java:1214)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:543)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:482)
at org.springframework.beans.factory.support.AbstractBeanFactory$1.getObject(AbstractBeanFactory.java:306)
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:230)
- locked <0xe4f> (a java.util.concurrent.ConcurrentHashMap)
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:302)
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:202)
at org.springframework.context.support.PostProcessorRegistrationDelegate.registerBeanPostProcessors(PostProcessorRegistrationDelegate.java:228)
at org.springframework.context.support.AbstractApplicationContext.registerBeanPostProcessors(AbstractApplicationContext.java:697)
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:526)
- locked <0xe50> (a java.lang.Object)
at org.springframework.web.context.ContextLoader.configureAndRefreshWebApplicationContext(ContextLoader.java:444)
at org.springframework.web.context.ContextLoader.initWebApplicationContext(ContextLoader.java:326)
at org.springframework.web.context.ContextLoaderListener.contextInitialized(ContextLoaderListener.java:107)具体分析下@PostConstruct的注解处理器调用
/**
* Actually create the specified bean. Pre-creation processing has already happened
* at this point, e.g. checking @code postProcessBeforeInstantiation callbacks.
* <p>Differentiates between default bean instantiation, use of a
* factory method, and autowiring a constructor.
* @param beanName the name of the bean
* @param mbd the merged bean definition for the bean
* @param args explicit arguments to use for constructor or factory method invocation
* @return a new instance of the bean
* @throws BeanCreationException if the bean could not be created
* @see #instantiateBean
* @see #instantiateUsingFactoryMethod
* @see #autowireConstructor
*/
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton())
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
if (instanceWrapper == null)
instanceWrapper = createBeanInstance(beanName, mbd, args);
final Object bean = (instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null);
Class<?> beanType = (instanceWrapper != null ? instanceWrapper.getWrappedClass() : null);
// Allow post-processors to modify the merged bean definition.
synchronized (mbd.postProcessingLock)
if (!mbd.postProcessed)
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
mbd.postProcessed = true;
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure)
if (logger.isDebugEnabled())
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
addSingletonFactory(beanName, new ObjectFactory<Object>()
@Override
public Object getObject() throws BeansException
return getEarlyBeanReference(beanName, mbd, bean);
);
// Initialize the bean instance.
Object exposedObject = bean;
try
populateBean(beanName, mbd, instanceWrapper);
if (exposedObject != null)
exposedObject = initializeBean(beanName, exposedObject, mbd);
catch (Throwable ex)
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName()))
throw (BeanCreationException) ex;
else
throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
if (earlySingletonExposure)
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null)
if (exposedObject == bean)
exposedObject = earlySingletonReference;
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName))
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<String>(dependentBeans.length);
for (String dependentBean : dependentBeans)
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean))
actualDependentBeans.add(dependentBean);
if (!actualDependentBeans.isEmpty())
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example.");
// Register bean as disposable.
try
registerDisposableBeanIfNecessary(beanName, bean, mbd);
catch (BeanDefinitionValidationException ex)
throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
return exposedObject;
/**
* Initialize the given bean instance, applying factory callbacks
* as well as init methods and bean post processors.
* <p>Called from @link #createBean for traditionally defined beans,
* and from @link #initializeBean for existing bean instances.
* @param beanName the bean name in the factory (for debugging purposes)
* @param bean the new bean instance we may need to initialize
* @param mbd the bean definition that the bean was created with
* (can also be @code null, if given an existing bean instance)
* @return the initialized bean instance (potentially wrapped)
* @see BeanNameAware
* @see BeanClassLoaderAware
* @see BeanFactoryAware
* @see #applyBeanPostProcessorsBeforeInitialization
* @see #invokeInitMethods
* @see #applyBeanPostProcessorsAfterInitialization
*/
protected Object initializeBean(final String beanName, final Object bean, RootBeanDefinition mbd)
if (System.getSecurityManager() != null)
AccessController.doPrivileged(new PrivilegedAction<Object>()
@Override
public Object run()
invokeAwareMethods(beanName, bean);
return null;
, getAccessControlContext());
else
invokeAwareMethods(beanName, bean);
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic())
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
try
invokeInitMethods(beanName, wrappedBean, mbd);
catch (Throwable ex)
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null),
beanName, "Invocation of init method failed", ex);
if (mbd == null || !mbd.isSynthetic())
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
return wrappedBean;
初始化给定的bean实例,应用工厂回调以及init方法和bean post处理器。顺便说一句,实现了InitializingBean接口的bean的afterPropertiseSet()方法是在
invokeInitMethods(beanName, wrappedBean, mbd);中进行调用的。接着看
@Override
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)
throws BeansException
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors())
result = beanProcessor.postProcessBeforeInitialization(result, beanName);
if (result == null)
return result;
return result;
这里就用到了前面注册的beanPostProcessors列表,于是就调用到了CommonAnnotationBeanPostProcessor中的postProcessBeforeInitialization()方法(继承自InitDestroyAnnotationBeanPostProcessor.java)
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException
LifecycleMetadata metadata = findLifecycleMetadata(bean.getClass());
try
metadata.invokeInitMethods(bean, beanName);
catch (InvocationTargetException ex)
throw new BeanCreationException(beanName, "Invocation of init method failed", ex.getTargetException());
catch (Throwable ex)
throw new BeanCreationException(beanName, "Failed to invoke init method", ex);
return bean;
上述代码也很简单,就是获取用@PostConstruct注解标注的method,然后调用,看下findLifecycleMetadata实现
private LifecycleMetadata buildLifecycleMetadata(final Class<?> clazz)
final boolean debug = logger.isDebugEnabled();
LinkedList<LifecycleElement> initMethods = new LinkedList<LifecycleElement>();
LinkedList<LifecycleElement> destroyMethods = new LinkedList<LifecycleElement>();
Class<?> targetClass = clazz;
do
final LinkedList<LifecycleElement> currInitMethods = new LinkedList<LifecycleElement>();
final LinkedList<LifecycleElement> currDestroyMethods = new LinkedList<LifecycleElement>();
ReflectionUtils.doWithLocalMethods(targetClass, new ReflectionUtils.MethodCallback()
@Override
public void doWith(Method method) throws IllegalArgumentException, IllegalAccessException
if (initAnnotationType != null)
if (method.getAnnotation(initAnnotationType) != null)
LifecycleElement element = new LifecycleElement(method);
currInitMethods.add(element);
if (debug)
logger.debug("Found init method on class [" + clazz.getName() + "]: " + method);
if (destroyAnnotationType != null)
if (method.getAnnotation(destroyAnnotationType) != null)
currDestroyMethods.add(new LifecycleElement(method));
if (debug)
logger.debug("Found destroy method on class [" + clazz.getName() + "]: " + method);
);
initMethods.addAll(0, currInitMethods);
destroyMethods.addAll(currDestroyMethods);
targetClass = targetClass.getSuperclass();
while (targetClass != null && targetClass != Object.class);
return new LifecycleMetadata(clazz, initMethods, destroyMethods);
是不是有种豁然开朗的感觉。
public void invokeInitMethods(Object target, String beanName) throws Throwable
Collection<LifecycleElement> initMethodsToIterate =
(this.checkedInitMethods != null ? this.checkedInitMethods : this.initMethods);
if (!initMethodsToIterate.isEmpty())
boolean debug = logger.isDebugEnabled();
for (LifecycleElement element : initMethodsToIterate)
if (debug)
logger.debug("Invoking init method on bean '" + beanName + "': " + element.getMethod());
element.invoke(target);
public void invoke(Object target) throws Throwable
ReflectionUtils.makeAccessible(this.method);
this.method.invoke(target, (Object[]) null);
熟悉的java反射。至此整个Spring注解的工作原理就分析完了,总结如下:
1)利用asm技术扫描class文件,转化成Spring bean结构,把符合扫描规则的(主要是是否有相关的注解标注,例如@Component)bean注册到Spring 容器中beanFactory 2)注册处理器,包括注解处理器 4)实例化处理器(包括注解处理器),并将其注册到容器的beanPostProcessors列表中 5)创建bean的过程中个,属性注入或者初始化bean时会调用对应的注解处理器进行处理。
以上是关于Spring实战Spring注解配置工作原理源码解析的主要内容,如果未能解决你的问题,请参考以下文章
Spring Boot 揭秘与实战 源码分析 - 工作原理剖析
spring5 源码深度解析----- 被面试官给虐懵了,竟然是因为我不懂@Configuration配置类及@Bean的原理