brpc介绍编译与使用
Posted breaksoftware
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了brpc介绍编译与使用相关的知识,希望对你有一定的参考价值。
brpc又称为baidu-rpc,是百度开发一款“远程过程调用”网络框架。目前该项目已在github上开源——https://github.com/brpc/brpc。(转载请指明出于breaksoftware的csdn博客)
据目前公开的资料,我们发现百度内部从2010年开始,开发过若干rpc框架:ub系列rpc(ubrpc,nova_pbrpc、public_pbrpc),hulu-pbrpc、sofa-pbrpc和本文介绍的baidu-rpc。从命名来看,我们并不太清楚ub、hulu和sofa是啥,但是可以确认的是我们知道baidu是什么意思。如果一款产品敢用公司名字来命名,可以见得该产品在公司内部的认可度——可以代表公司水平的产品。
然后从应用方面看,brpc目前被应用于百度公司内部各种核心业务上,据github上的overview.md资料,包括:高性能计算和模型训练和各种索引和排序服务,且有超过100万以上个实例是基于brpc工作的。
有大公司核心业务背书,我觉得这个项目还是可以玩玩的。
目前github上有原汁原味的技术文档,似乎是直接把公司内部文件放了出来。但是我们在外网接触不到他们的核心业务,更接触不到什么UB、hulu或者sofa(似乎sofa-pbrpc也是开源的)等技术。所以部分文档我们可以无视。这样我们就可以将关注重心放在它的设计思想、性能、易用性以及和主流开源rpc的对比上。
RPC
当然在谈这些前,需要知道什么是rpc。rpc全称是Remote Procedure Call,即远程过程调用。我们先了解下“过程调用”这个概念。比如我们有如下代码
void a()
printf("a excute\\n");
void b()
printf("b excute\\n");
a();
a、b函数我们可以认为它们各是一个“过程”。其中b函数调用了a函数,我们可以认为b过程调用了a过程,这个步骤我们可以称为一次“过程调用”。这也是我们最普遍见到的“过程调用”形式。
从宏观层面来看,a、b业务逻辑都在一台机器的一个进程的一个线程中被执行的;从微观层面,调用过程使用的全是本地资源——发生的变化仅限于本机的内存、CPU和显示设备。于是这个过程我们可以称为本地过程调用——Local Procedure Call。
然而随着业务发展,a函数所要执行的业务越来越复杂,我们可能会让其独立成为一个进程而存在。这样a、b函数将在同一台机器不同进程中执行。此时b函数想调用a函数,就需要使用管道等技术进行跨进程通信。这种调用我们还是称为本地过程调用。
再进一步,我们需要把a函数对应的逻辑作为一个独立的服务。这样承载a、b的服务可能部署于不同的机器上。此时b函数调用a函数的过程,需要跨越网络,我们称这种调用为“远过程调用”。
那么b函数是如何“远过程调用”a函数的呢?一般a函数对应的进程会开放一个网络端口,它接受某种协议(比如HTTP)的请求,然后把结果打包成对应的协议格式返回。b函数所在的进程则发起该请求,然后接收返回结果。
但是这种设计无意增加了代码开发者的工作量。因为本来就一个本地函数调用就能解决问题,现在却需要:编写a函数对应的服务、编写b访问网络的逻辑。这其中掺杂了网络、数据序列化等方面知识,开发难度直线上升。
大家开始想办法,如果我们能降低上述开发难度,让开发者不需要懂网络编程、不需要懂协议解析,就像写本地调用代码一样做开发就好了。于是rpc框架就被研发出来了,市面上的google出品的grpc、facebook出品的thrift以及本文介绍的百度出品的brpc就是这类产品。
易用性
以brpc为例,我们看一个远过程调用是如何被调用的
#include <brpc/channel.h>
#include "echo.pb.h"
……
brpc::Channel channel;
brpc::ChannelOptions options;
// 设置超时、协议等信息
……
example::EchoRequest request;
example::EchoResponse response;
// 设置参数
request.set_message("hello world");
// 设置调用桩
example::EchoService_Stub stub(&channel);
brpc::Controller cntl;
// 发起调用
stub.Echo(&cntl, &request, &response, NULL);
// 检测并分析结果
……可以见得,这段代码内容比较好的隐藏了网络知识——本地调用也存在超时和协议的概念。我们就像调用本地过程一样调用了Echo方法。
相应的远过程调用的远端——服务端代码如下
#include <brpc/server.h>
#include "echo.pb.h"
……
namespace example
class EchoServiceImpl : public EchoService
public:
EchoServiceImpl() ;
virtual ~EchoServiceImpl() ;
virtual void Echo(google::protobuf::RpcController* cntl_base,
const EchoRequest* request,
EchoResponse* response,
google::protobuf::Closure* done)
brpc::ClosureGuard done_guard(done);
brpc::Controller* cntl =
static_cast<brpc::Controller*>(cntl_base);
// Fill response.
response->set_message(request->message());
;
// namespace example
int main(int argc, char* argv[])
// Parse gflags. We recommend you to use gflags as well.
GFLAGS_NS::ParseCommandLineFlags(&argc, &argv, true);
// Generally you only need one Server.
brpc::Server server;
// Instance of your service.
example::EchoServiceImpl echo_service_impl;
if (server.AddService(&echo_service_impl,
brpc::SERVER_DOESNT_OWN_SERVICE) != 0)
LOG(ERROR) << "Fail to add service";
return -1;
// Start the server.
brpc::ServerOptions options;
options.idle_timeout_sec = FLAGS_idle_timeout_s;
if (server.Start(FLAGS_port, &options) != 0)
LOG(ERROR) << "Fail to start EchoServer";
return -1;
// Wait until Ctrl-C is pressed, then Stop() and Join() the server.
server.RunUntilAskedToQuit();
return 0;
我们关注于EchoServiceImpl的实现。它主要暴露了Echo方法,我们只要填充它的业务就行了,而main函数中的套路是固定的。
可以见得使用rpc框架大大降低了我们开发的难度。
性能
在易用性相似的情况下,我们再对比一下brpc和grpc、thrift的差别。以下数据和图片都来源于brpc在github上公布的调研结果
同机单client→单server在不同请求包大小下的QPS(越高越好)
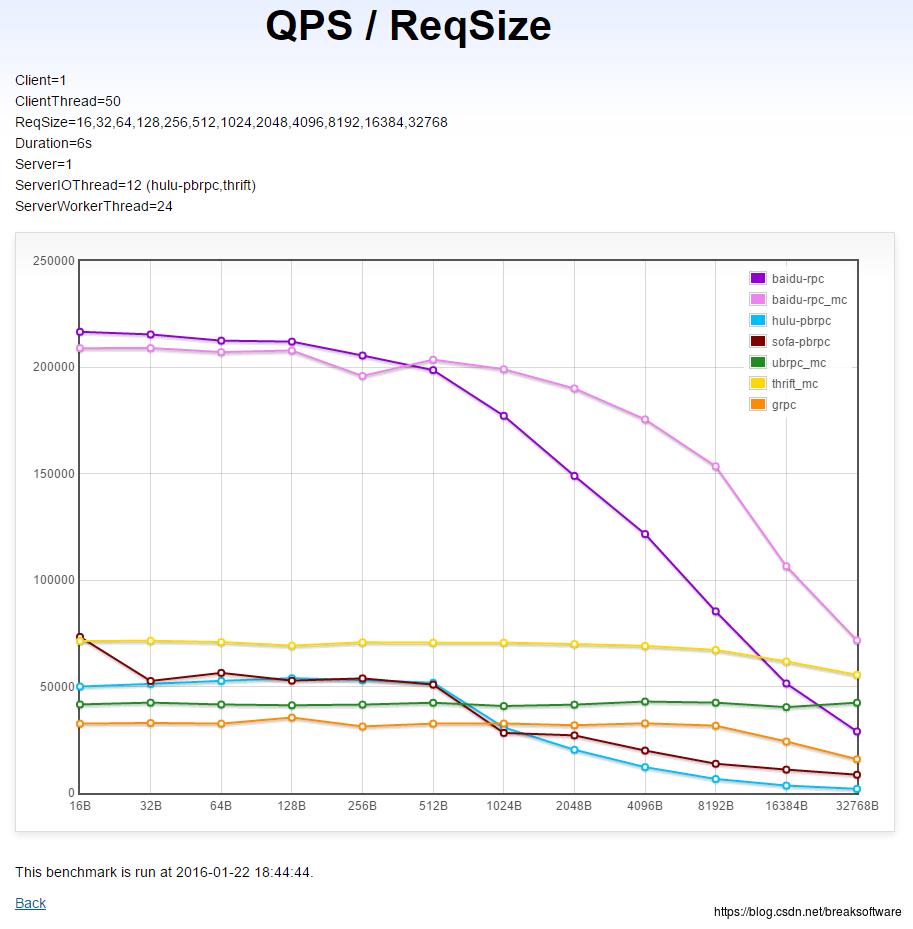
上图是一个Client端向一个Server端发送的数据随着数据包大小变化而导致QPS变化的关系图。我们看到:
- brpc随着请求包大小变大,QPS会下降得很明显。
- thrift随着请求包大小变大,QPS下降不明显。
- grpc随着请求包大小变大,在小于8KB的场景下变化不明显。但是8KB以上时,QPS明显下降。
- 在数据包大小<512B时,brpc的QPS接近grpc的5倍,接近thrift的3倍多。
- 在数据包大小<8KB时,brpc的QPS还是比grpc和thrift高。
- 在数据包大小>8KB时,brpc的QPS比thrift低,但是比grpc高。
跨机多client→单server的QPS(越高越好)
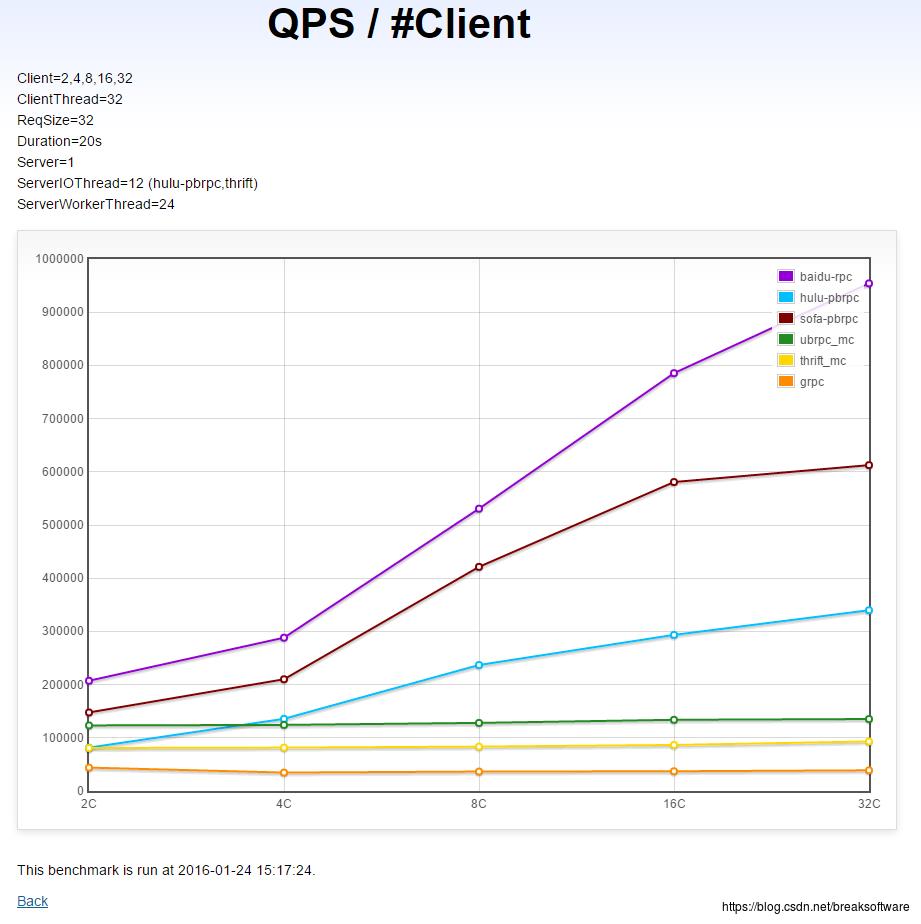
上图是多个Client向一个Server发请求时,Client端数量和Server的QPS数量之间的关系图。我们可以看到:
- 随着Client数量增加,grpc和thrif的QPS没有明显增加。这意味着请求增多,grpc和thrift就需要更多的Server端来消化。
- 随着Client数量增多,brpc的QPS迅速增加。这意味着请求增多,brpc的Server端不需要像grpc或者thrift方案那样增加太多。
同机单client→单server在不同线程数下的QPS(越高越好)
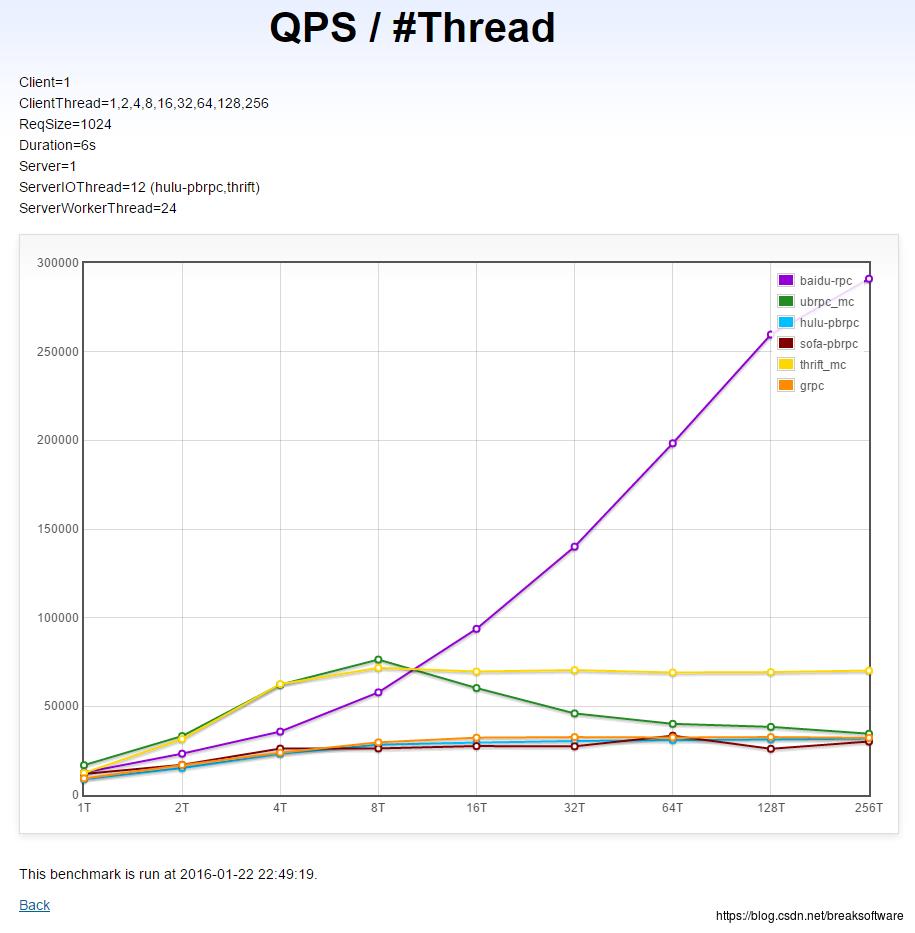
上图反映出Server开启的线程数和QPS之间的关系。随着服务器性能越来越好,CPU核心数也越来越多,我们可以开启更多的线程数来增加服务的处理能力,所以这个关系图很有意义。
- grpc随着线程数增加,QPS变化不明显。这意味着给grpc开启更多的线程数对QPS没有明显贡献。
- thrift在线程数<=8时,QPS比grpc和brpc都高。但是在达到8个线程之后,QPS基本没有变化,这就意味着thrift开启超过8个线程就对QPS没有明显贡献了。
- brpc随着线程数增加,QPS变化明显。虽然在8个线程及以下时,QPS不如thrift,但是之后随着线程数增加,QPS增加也快速增加。这说明brpc对线程的利用率是非常高的。这也意味着让brpc的服务部署在更多核心的机器上时,QPS会有更大的收益。
brpc为什么会有此特性。这儿就需要介绍一下其使用的bthread库。据公开的资料介绍,其特点是:
- 用户可以延续同步的编程模式,能在数百纳秒内建立bthread,可以用多种原语同步。
- bthread所有接口可在pthread中被调用并有合理的行为,使用bthread的代码可以在pthread中正常执行。
- 能充分利用多核。
- better cache locality, supporting NUMA is a plus.
除了看QPS,我们还要看处理延时。如果一个服务虽然QPS很高,但是每个请求都延迟很久处理,就会导致服务的平均响应时间变大。
跨机多client→单server在固定QPS下的延时CDF(越左越好,越直越好)
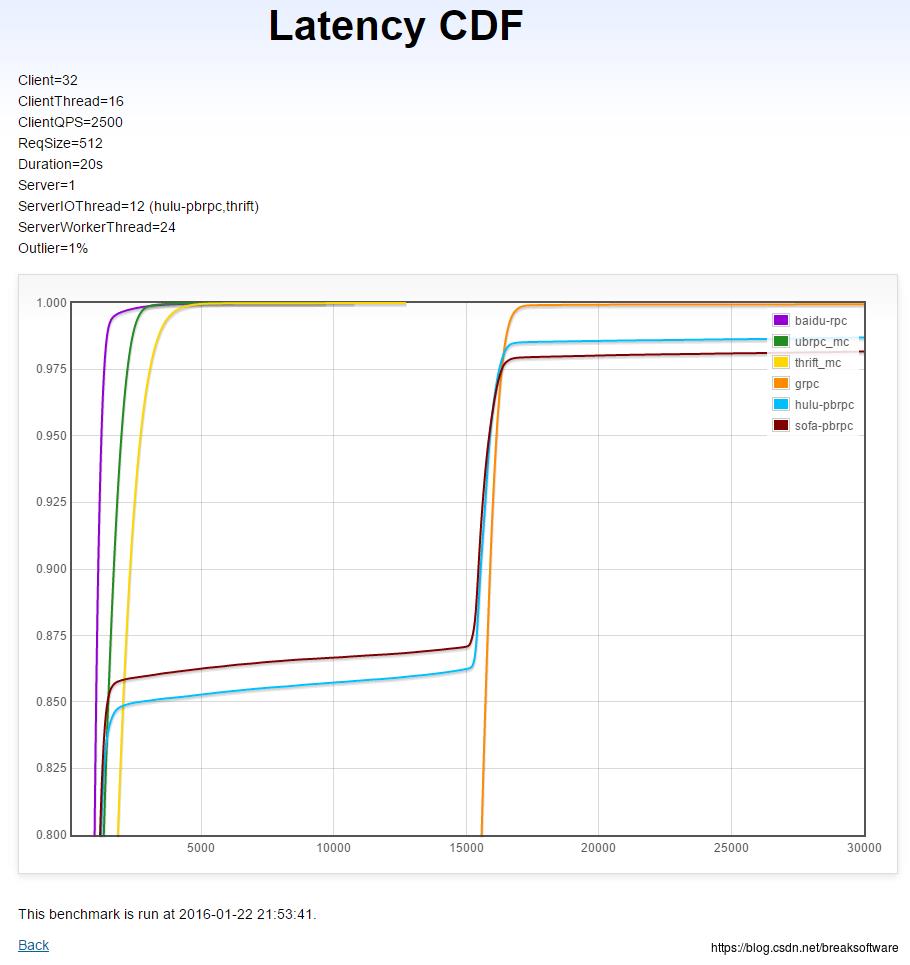
X轴是延时(微秒),Y轴是小于X轴延时的请求比例。这意味着变化曲线越靠近左边(延时短),越直(请求比例变化小)越好。
- brpc的延时要优于thrift和grpc。
- thrift同样优秀,但是grpc表现最差。
编译
关于编译brpc,可以参见https://github.com/brpc/brpc/blob/master/docs/cn/getting_started.md。但是一些环境问题,导致有些软件不能安装,就需要自己编译了。
我把在Ubuntu Server 18版本上的编译的过程贴出来,供大家参考。
sudo apt install make
sudo apt install gcc
sudo apt install g++
sudo apt install libleveldb-dev
sudo apt install libgflags-dev
sudo apt install openssl
sudo apt install libssl-devzlib是源码编译的
wget http://www.zlib.net/zlib-1.2.11.tar.gz .
tar -xzvf zlib-1.2.11.tar.gz
cd zlib-1.2.11
./configure -prefix=/usr
sudo make
sudo make install
protobuf是源码编译的
sudo apt-get install autoconf automake libtool
git clone https://github.com/google/protobuf.git
cd protobuf
./autogen.sh
./configure --prefix=/usr -with-PACKAGE=yes
cd protobuf
sudo make
sudo make install
最后还要修改下Makefile文件——增加"-std=c++11"
protoc-gen-mcpack: src/idl_options.pb.cc src/mcpack2pb/generator.o libbrpc.a
@echo "Linking $@"
ifeq ($(SYSTEM),Linux)
@$(CXX) -o $@ $(HDRPATHS) -std=c++11 $(LIBPATHS) -Xlinker "-(" $^ -Wl,-Bstatic $(STATIC_LINKINGS) -Wl,-Bdynamic -Xlinker "-)" $(DYNAMIC_LINKINGS)
else ifeq ($(SYSTEM),Darwin)
@$(CXX) -o $@ $(HDRPATHS) -std=c++11 $(LIBPATHS) $^ $(STATIC_LINKINGS) $(DYNAMIC_LINKINGS)
endif一切准备就绪,到brpc的目录下执行
sh config_brpc.sh --headers=/usr/include --libs=/usr/lib
make
最后切换到example/echo_c++目录下,make出server和client,执行查看效果


以上是关于brpc介绍编译与使用的主要内容,如果未能解决你的问题,请参考以下文章