为什么神经网络模型在测试集上的准确率高于训练集上的准确率?
Posted 静待花开s0
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么神经网络模型在测试集上的准确率高于训练集上的准确率?相关的知识,希望对你有一定的参考价值。
类似下图:
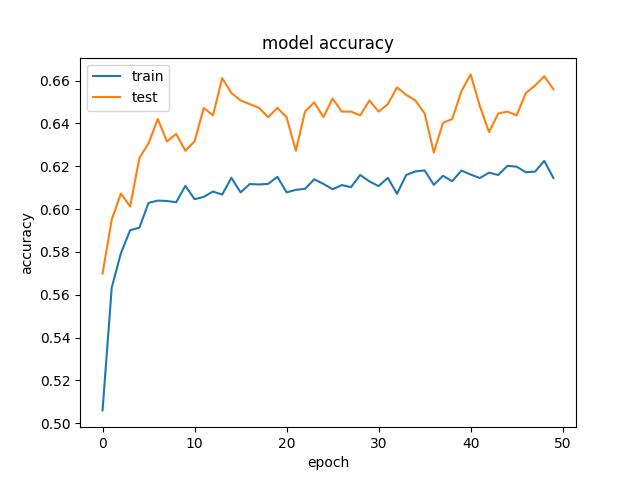
或者下图:
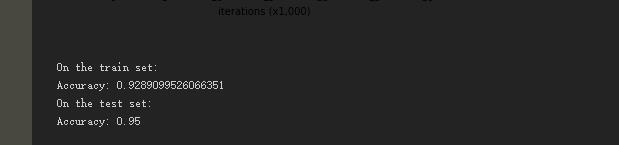
来自:吴恩达机器学习Regularization部分。
如上图所示,有时候我们做训练的时候,会得到测试集的准确率或者验证集的准确率高于训练集的准确率,这是什么原因造成的呢?经过查阅资料,有以下几点原因,仅作参考,不对的地方,请大家指正。
(1)数据集太小的话,如果数据集切分的不均匀,或者说训练集和测试集的分布不均匀,如果模型能够正确捕捉到数据内部的分布模式话,这可能造成训练集的内部方差大于验证集,会造成训练集的误差更大。这时你要重新切分数据集或者扩充数据集,使其分布一样
(2)由Dropout造成,它能基本上确保您的测试准确性最好,优于您的训练准确性。Dropout迫使你的神经网络成为一个非常大的弱分类器集合,这就意味着,一个单独的分类器没有太高的分类准确性,只有当你把他们串在一起的时候他们才会变得更强大。
因为在训练期间,Dropout将这些分类器的随机集合切掉,因此,训练准确率将受到影响
在测试期间,Dropout将自动关闭,并允许使用神经网络中的所有弱分类器,因此,测试精度提高。
References:
https://www.cnblogs.com/carlber/p/10892042.html
以上是关于为什么神经网络模型在测试集上的准确率高于训练集上的准确率?的主要内容,如果未能解决你的问题,请参考以下文章