超详细入门精讲数据仓库原理&实战 一步一步搭建数据仓库 内附相应实验代码和镜像数据和脚本
Posted Oraer_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超详细入门精讲数据仓库原理&实战 一步一步搭建数据仓库 内附相应实验代码和镜像数据和脚本相关的知识,希望对你有一定的参考价值。
超详细【入门精讲】数据仓库原理&实战 一步一步搭建数据仓库 内附相应实验代码和镜像数据和脚本
感谢B站UP主 哈喽鹏程!!!
文章目录
- 0. B站课程链接 和 搭建数据仓库资源下载
- 1. 项目介绍及
- 2. 环境准备01-02(虚拟机和Xshell)
- 3. 环境搭建03 (脚本准备)
- 4. 环境搭建04 (集群安装)
- 5. 项目流程&数据生成
- 6. ETL数据导入
- 7. ODS层创建&数据接入
- 8. DWD层创建&数据接入
- 9. DWS层创建&数据接入
- 10. ADS层复购率统计
- 11. ADS层数据导出
- 12. Azkaban自动化调度
- 13. 结果展示
- 14. 课后作业
- 15. 更换IP后所需要做的操作
- 16. 如何设置静态IP地址
- 17. 常见问题(未完持续更新中,欢迎补充!)
0. B站课程链接 和 搭建数据仓库资源下载
下载UP主 哈喽鹏程 给的资源镜像及脚本包
课程链接:https://www.bilibili.com/video/BV1qv411y7Wv/
下载连接:
数据仓库的课件:
链接:https://pan.baidu.com/s/1_B2FPJYbHR-qq-5Q-Xfamw/?pwd=d3a9
提取码:d3a9
数据仓库的实验数据,资源镜像及脚本包:
链接:https://pan.baidu.com/s/1zSkL1YWa6wGkKrUW-Zl8Yw/?pwd=fwpq
提取码:fwpq
数据仓库的automaticDeploy项目代码:
链接:https://pan.baidu.com/s/1qspiJ8LbrSr58pg84ICRUA/?pwd=7nff
提取码:7nff
备用链接:
数据仓库的实验数据,资源镜像及脚本包:
链接:https://pan.baidu.com/s/1WZsfADEGUlD1U7LcEf2dww/?pwd=ik61
提取码:ik61
数据仓库的资源镜像及脚本包和automaticDeploy项目代码(全):
1. 项目介绍及
1.1项目介绍
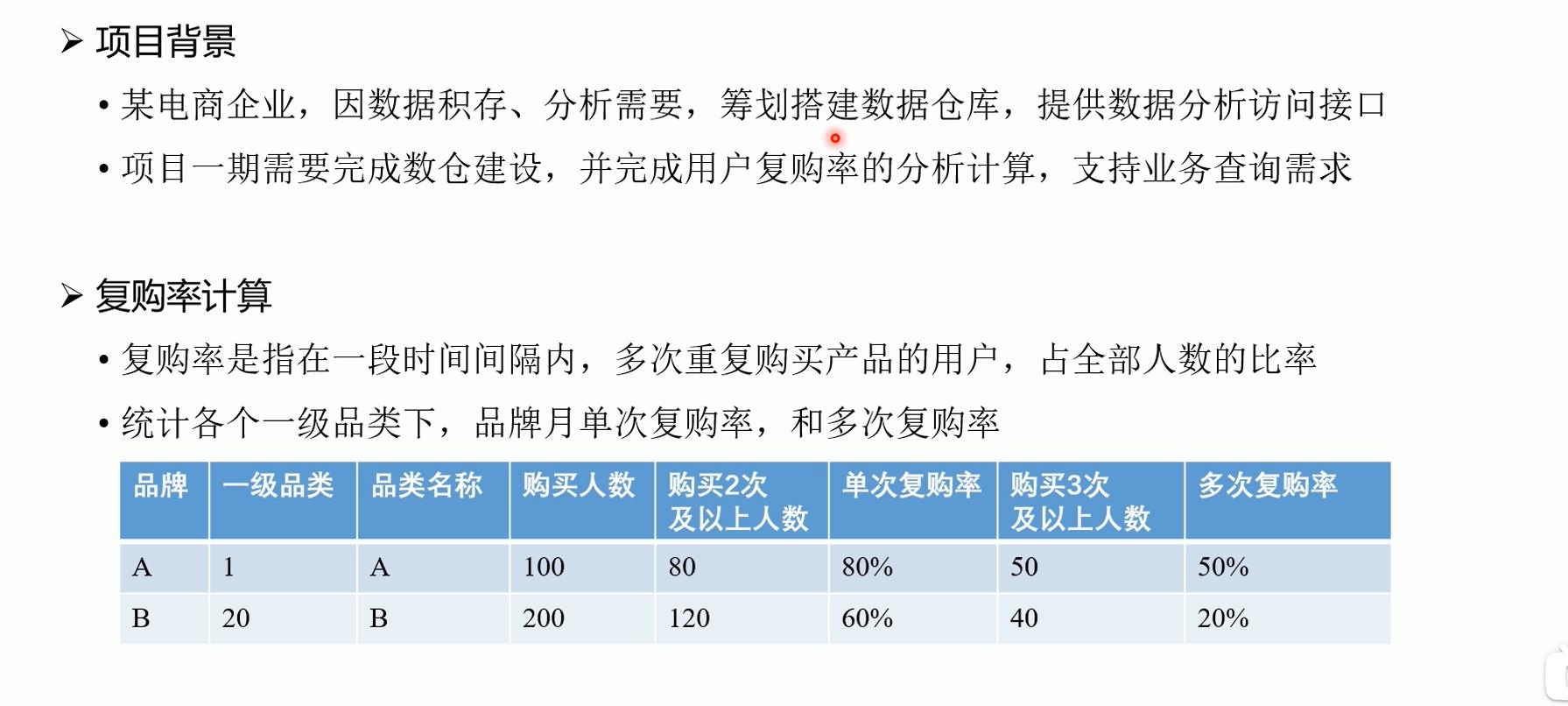
1.2 数据仓库架构
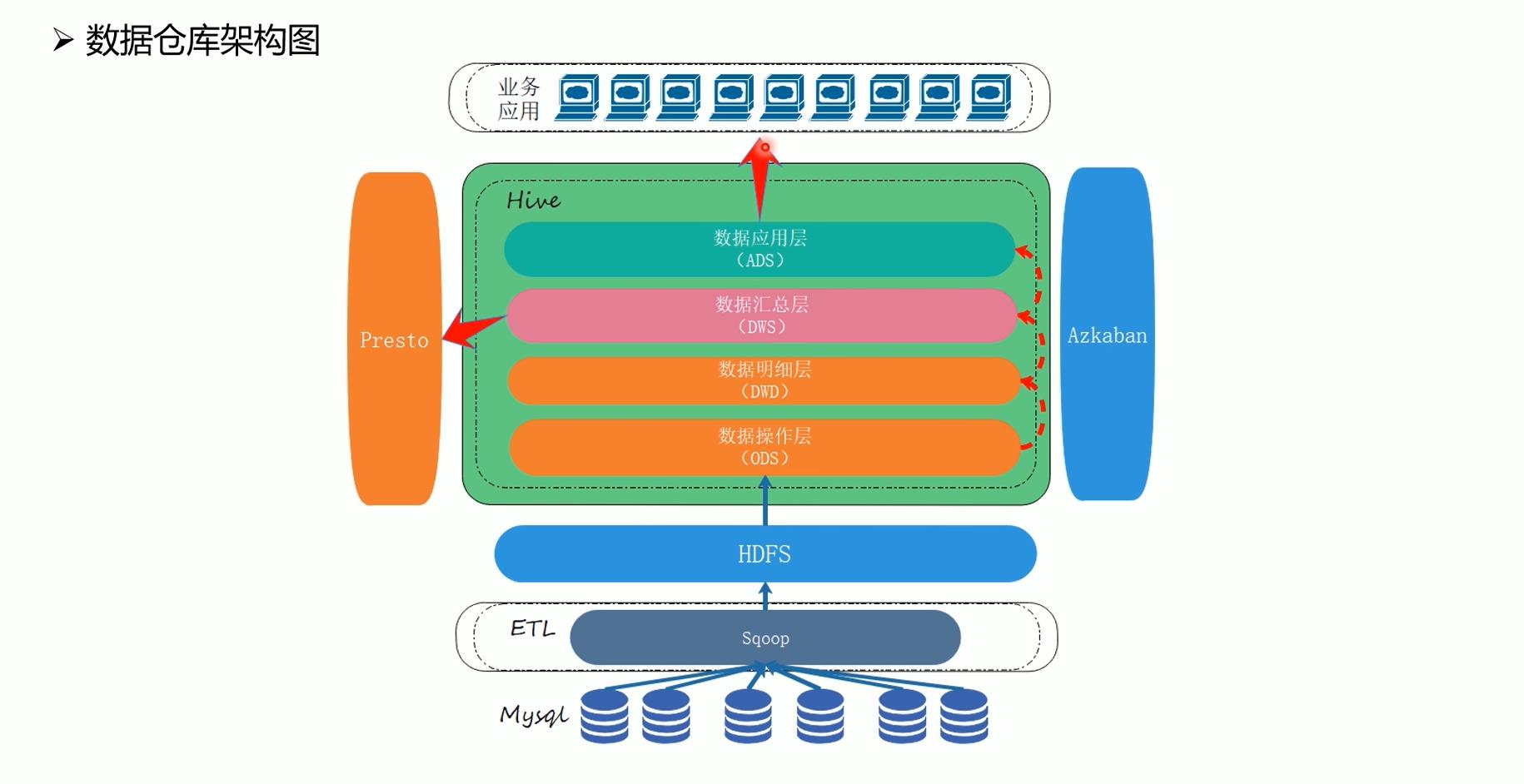
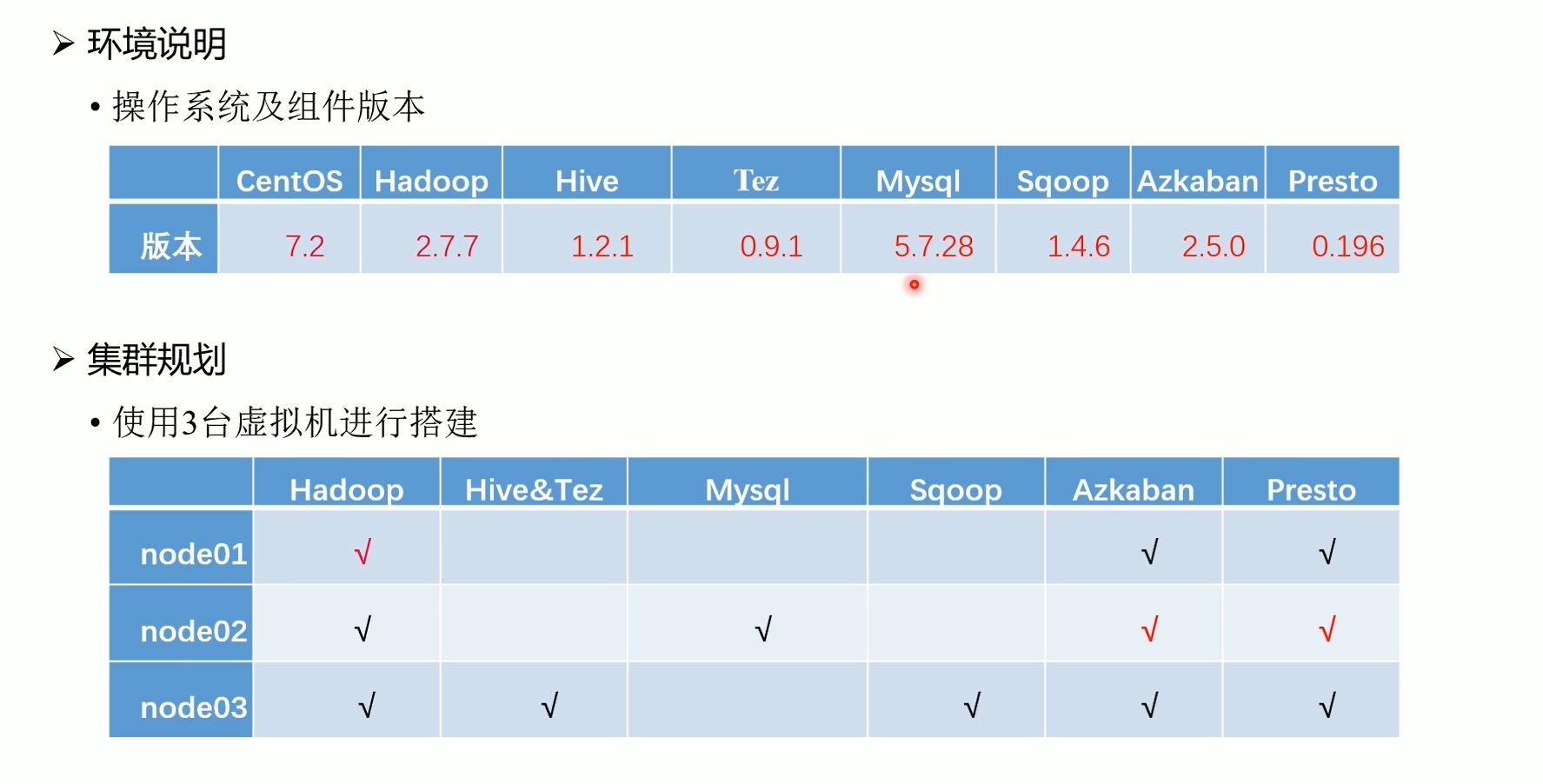
1.3 环境规划
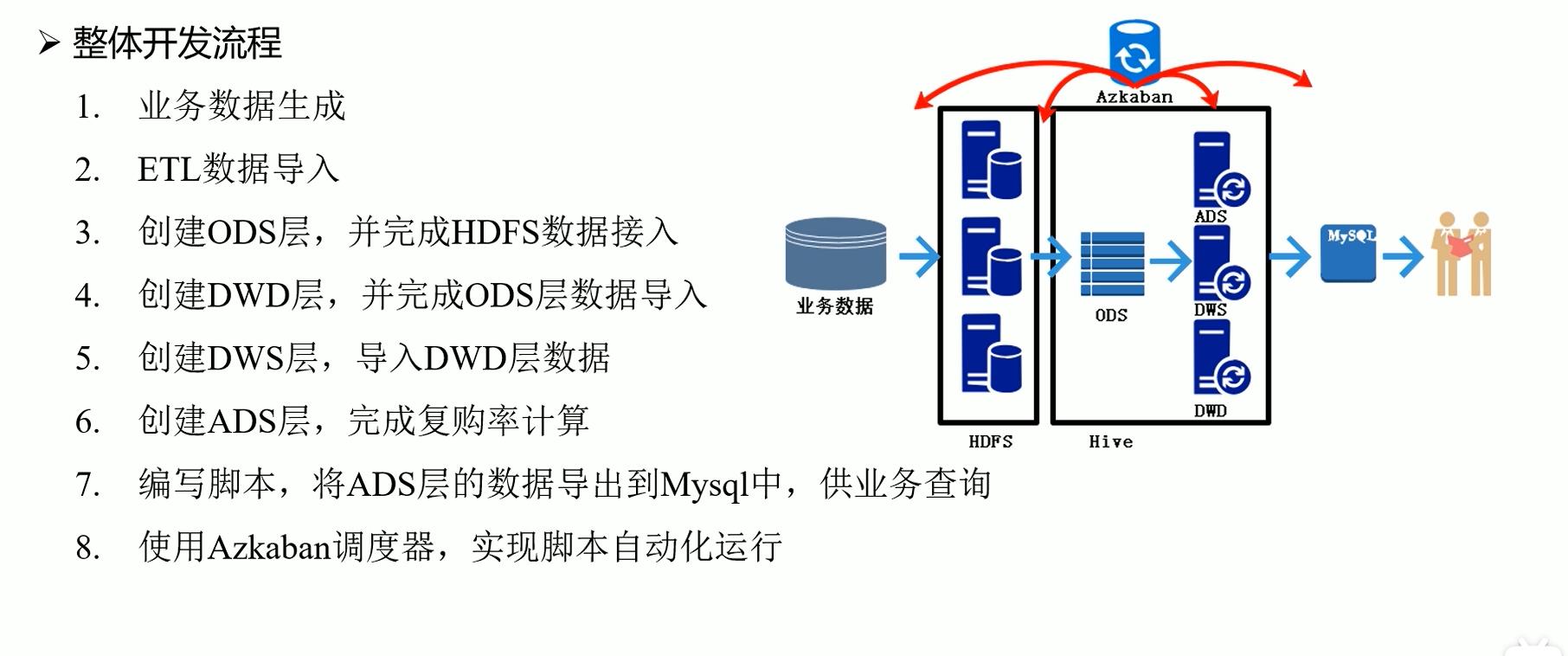
1.4 整体开发流程
2. 环境准备01-02(虚拟机和Xshell)
2.1 软件下载
安装以下软件:
-
虚拟机软件: Virtual Box, 下载链接: https://www.virtualbox.org/
-
远程联机软件: Xshell (也可以使用其他软件, 推荐使用FinalShell,我是用的是FinalShell)
Virtual Box**, **下载链接: https://www.virtualbox.org/
XShell,下载链接:https://www.xshell.com/zh/xshell/
FinalShell, 下载链接:http://www.hostbuf.com/t/988.html
下载UP主 哈喽鹏程 给的资源镜像及脚本包
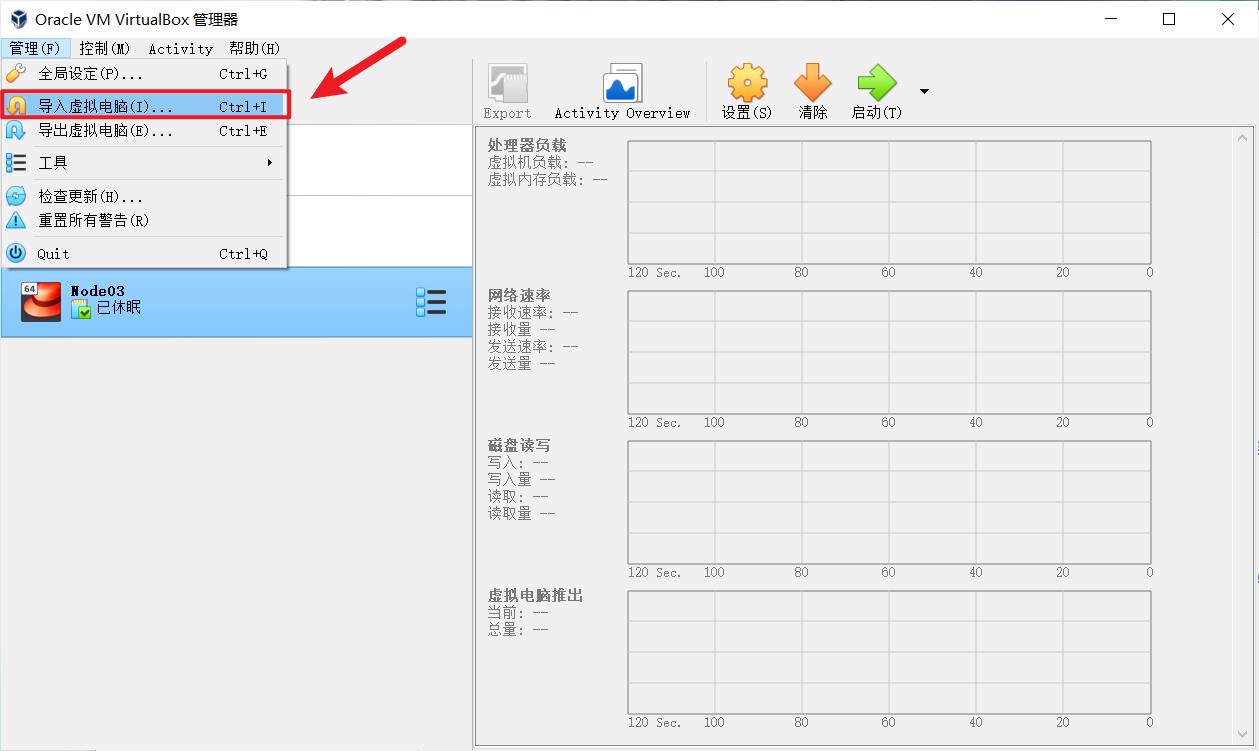
2.2 安装Virtual Box及导入OVA镜像
官网下载安装包,一路next就行,可以更改安装路径
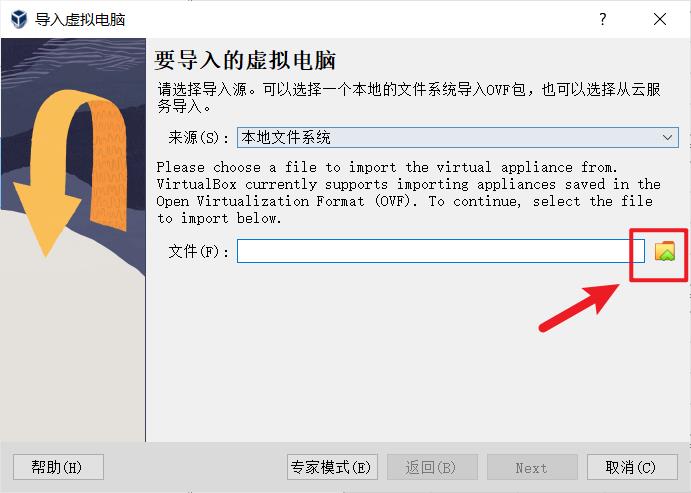
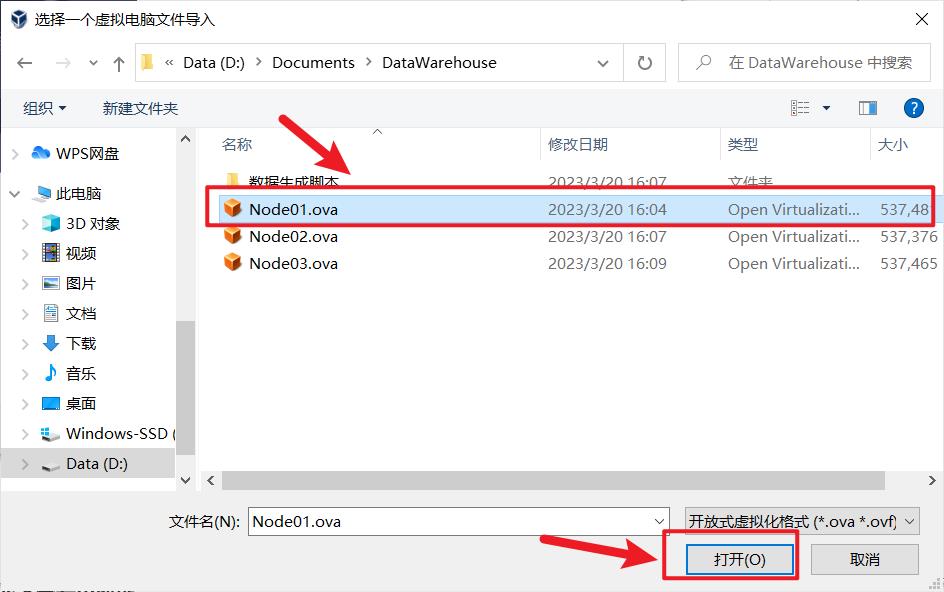
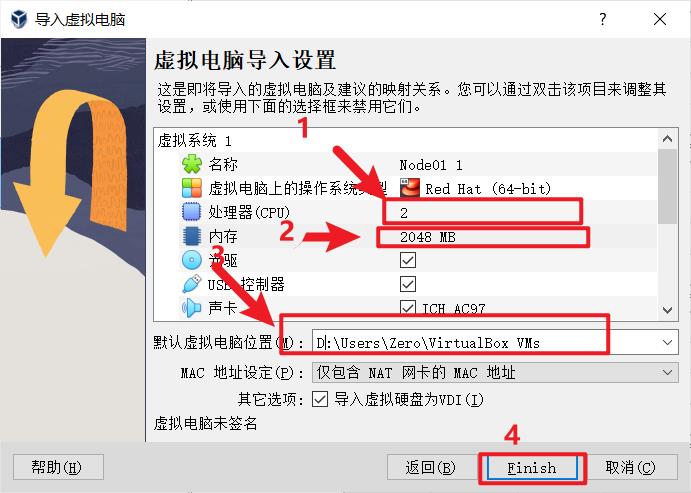
node02,node03同样的操作
虚拟机第一次打开的时候可能会有网络报错,这个时候需要操作一下
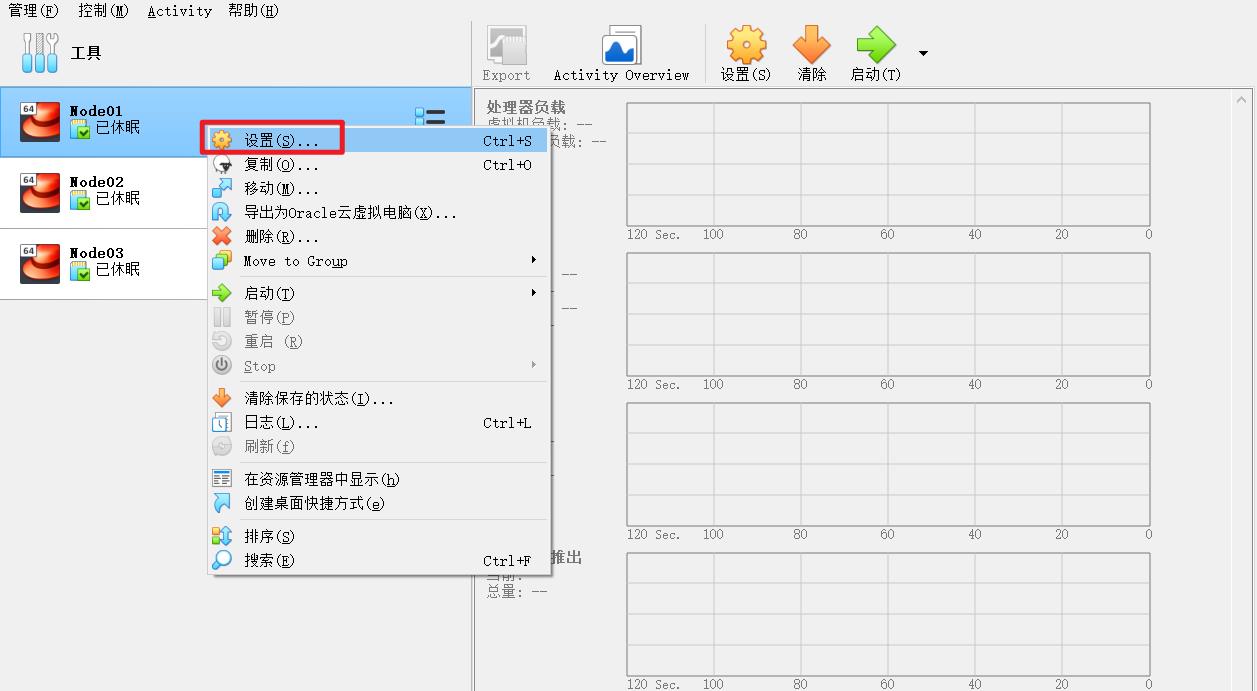
这里需要手动选择一次网卡,注意是一定要再选择一次
然后可以开启虚拟机了
三台虚拟机用户名及密码, 进入虚拟机
node01 root 123456
node02 root 123456
node03 root 123456
2.3 修改虚拟机静态IP地址
windows下查看IP地址
win+r 然后输入cmd 回车,打开命令行窗口,输入ifconfig查看主机ip地址
例如:
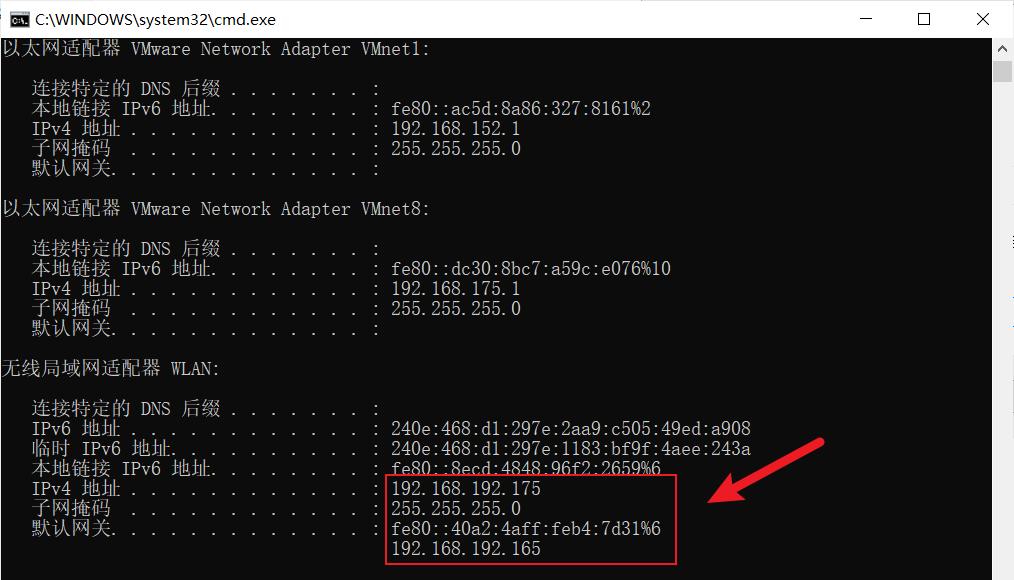
192.168.192.175
本地链接 IPv6 地址. . . . . . . . : fe80::8ecd:4848:96f2:2659%6
IPv4 地址 . . . . . . . . . . . . : 192.168.192.175
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . : fe80::40a2:4aff:feb4:7d31%6
192.168.192.165
在得到主机的IP地址后,分别对三台虚拟机node01、node02、node03进行修改
例如我的IP为192.168.192.175,则修改以下内容:
node01中的ifcfg-enp0s3文件中IPADDR=192.168.192.176
node02中的ifcfg-enp0s3文件中IPADDR=192.168.192.177
node03中的ifcfg-enp0s3文件中IPADDR=192.168.192.178
node02和node03中的GATEWAY=192.168.192.1
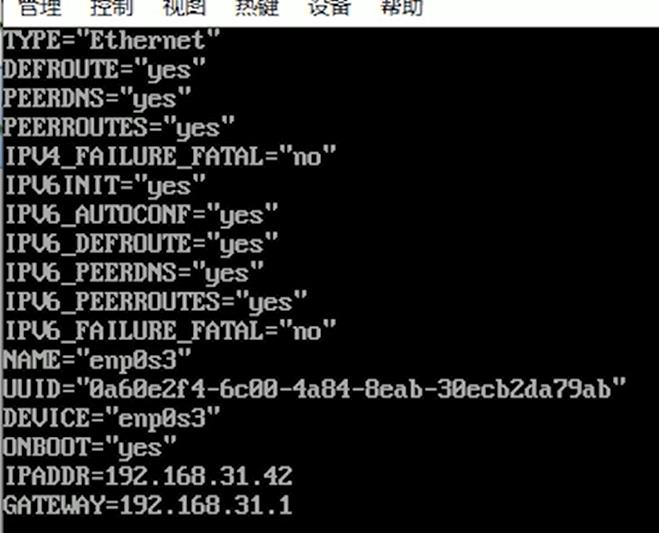
修改配置文件 ifcfg-enp0s3
[root@node01 ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
[root@node01 ~]# systemctl restart network
[root@node02 ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
[root@node02 ~]# systemctl restart network
[root@node03 ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
[root@node03 ~]# systemctl restart network
更新配置 systemctl restart network
注意node01没有GATEWAY,node02,node03有GATEWAY
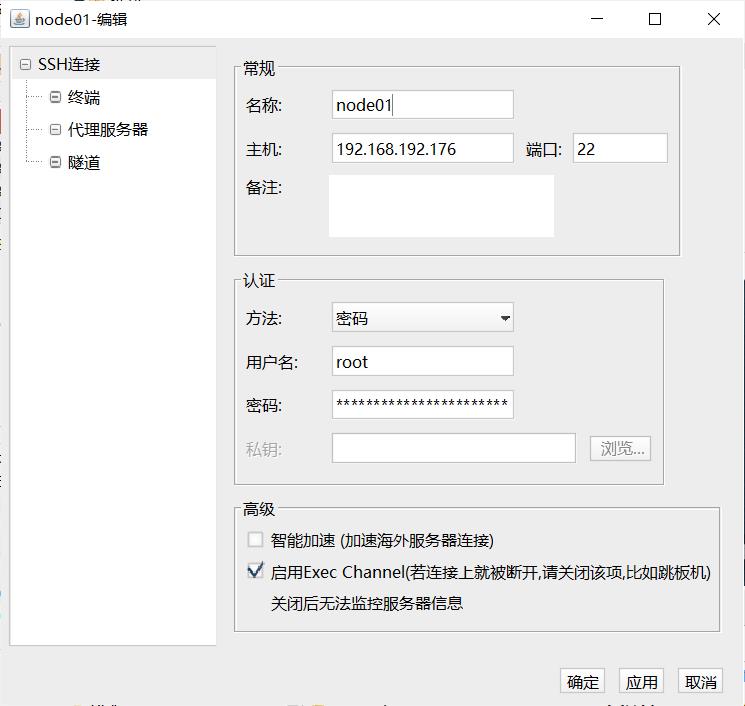
2.4 SSH链接虚拟机
这里使用 FinalShell SSH连接虚拟机
node01配置如下, node02和node03同理
3. 环境搭建03 (脚本准备)
wget https://github.com/Mtlpc/automaticDeploy/archive/master.zip
或者直接去github下载 https://github.com/Mtlpc/automaticDeploy (建议直接去下载然后上传到虚拟机, 如果你使用的是 FinalShell 可以直接上传, 如果使用的是Xshell, 则需安装上传组件, 安装方法在文章后面)
将下载好的文件解压到 /home/hadoop 下,并将该文件的文件名改成 automaticDeploy,否则运行会报错
以下是 automaticDeploy 中的文件
[root@node01 ~]# cd /home/hadoop/
[root@node01 hadoop]# unzip automaticDeploy.zip
# 给予可执行权限
[root@node01 hadoop]# chmod +x /home/hadoop/automaticDeploy/hadoop/* [root@node01 hadoop]# /home/hadoop/automaticDeploy/systems/*
# 文件内容
[root@node01 hadoop]# ls automaticDeploy/
configs.txt frames.txt hadoop host_ip.txt logs.sh README.md systems
configs.txt 文件内容如下:
# mysql相关配置
mysql-root-password DBa2020* END
mysql-hive-password DBa2020* END
mysql-drive mysql-connector-java-5.1.26-bin.jar END
# azkaban相关配置
azkaban-mysql-user root END
azkaban-mysql-password DBa2020* END
azkaban-keystore-password 123456 END
host_ip.txt 文件内容如下:
这个需要配置成自己的3个node的ip
192.168.31.41 node01 root 123456
192.168.31.42 node02 root 123456
192.168.31.43 node03 root 123456
farames.txt 文件内容如下:
# 通用环境
jdk-8u144-linux-x64.tar.gz true
azkaban-sql-script-2.5.0.tar.gz true
# Node01
hadoop-2.7.7.tar.gz true node01
# Node02
mysql-rpm-pack-5.7.28 true node02
azkaban-executor-server-2.5.0.tar.gz true node02
azkaban-web-server-2.5.0.tar.gz true node02
presto-server-0.196.tar.gz true node02
# Node03
apache-hive-1.2.1-bin.tar.gz true node03
apache-tez-0.9.1-bin.tar.gz true node03
sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz true node03
yanagishima-18.0.zip true node03
# Muti
apache-flume-1.7.0-bin.tar.gz true node01,node02,node03
zookeeper-3.4.10.tar.gz true node01,node02,node03
kafka_2.11-0.11.0.2.tgz true node01,node02,node03
3.1 安装xshell上传组件 lrzsz
当然如果不使用Xshell的话, 使用FinalShell就可以不用安装, FinalShell自带文件上传组件
[root@node01 automaticDeploy]# yum install lrzsz -y
上传 frames.zip 压缩包
[root@node01 ~]# cd ~
[root@node01 ~]# unzip frames.zip -d /home/hadoop/automaticDeploy/
[root@node01 ~]# ssh root@192.168.133.177 "mkdir /home/hadoop"
[root@node01 ~]# ssh root@192.168.133.178 "mkdir /home/hadoop"
修改 automaticDeploy 文件夹下的 host_ip.txt 文件, 修改结果如下
这个需要配置成自己的3个node的ip
192.168.192.176 node01 root 123456
192.168.192.177 node02 root 123456
192.168.192.178 node03 root 123456
将 automaticDeploy 通过scp命令拷贝到 node02 ,node03
# 将修改后的automaticDeploy复制到node02,node03
[root@node01 hadoop]# scp -r /home/hadoop/automaticDeploy/ root@192.168.192.177:/home/hadoop/
[root@node01 hadoop]# scp -r /home/hadoop/automaticDeploy/ root@192.168.192.178:/home/hadoop/
拷贝完成后, 可以去 node02 , node03 上的 /home/hadoop/ 路径下进行确认
4. 环境搭建04 (集群安装)
恭喜你完成了以上操作, 到这一步正式开始环境搭建
# 分别在node01,node02,node03运行批处理脚本 batchOperate.sh 进行初始化
# 更新yum源, 免密钥登入,安装JDK,配置HOST
# node01
[root@node01 ~]# cd automaticDeploy
[root@node01 automaticDeploy]# cd systems/
[root@node01 systems]# ./batchOperate.sh
# node02
[root@node02 ~]# cd automaticDeploy/systems/
[root@node02 systems]# ./batchOperate.sh
# node03
[root@node03 ~]# cd automaticDeploy/systems/
[root@node03 systems]# ./batchOperate.sh
验证三台虚拟机是否能够互相连接,
注意: 每连完一台虚拟机后都要退出, 然后再连接另一台
# 分别SSH另外两台虚拟机, exit 退出SSH
# 示例: [root@node02 ~]# exit
# node01
[root@node01 systems]# ssh node02
[root@node01 systems]# ssh node03
# node02
[root@node02 systems]# ssh node01
[root@node02 systems]# ssh node03
# node03
[root@node03 systems]# ssh node01
[root@node03 systems]# ssh node02
脚本免密登录失败的话,可以手动进行免密登录操作
# 脚本免密登录失败的话,可以手动进行免密登录操作
# 以下为示例
[root@node01 ~]# ssh-copy-id node02
4.1 安装Hadoop
分别在三台虚拟机上依次执行
[root@node01 hadoop]# ./installHadoop.sh
[root@node02 hadoop]# ./installHadoop.sh
[root@node03 hadoop]# ./installHadoop.sh
安装完成后, 更新环境变量
[root@node01 hadoop]# source /etc/profile
[root@node02 hadoop]# source /etc/profile
[root@node03 hadoop]# source /etc/profile
在 node01 上初始化 hadoop
[root@node01 hadoop]# hadoop namenode -format
在 node01 上启动 hadoop 集群
[root@node01 ~]# start-all.sh
jps查看是否运行成功, node01有6个进程
[root@node01 ~]# jps
6193 NameNode
6628 SecondaryNameNode
7412 Jps
6373 DataNode
6901 ResourceManager
7066 NodeManager
node02
[root@node02 ~]# jps
5952 NodeManager
6565 Jps
5644 DataNode
node03
[root@node03 ~]# jps
6596 Jps
5594 DataNode
5902 NodeManager
进行到这一步, hadoop已经安装成功
可以打开浏览器,访问 node01 的 50070 端口, 进入hadoop的web界面
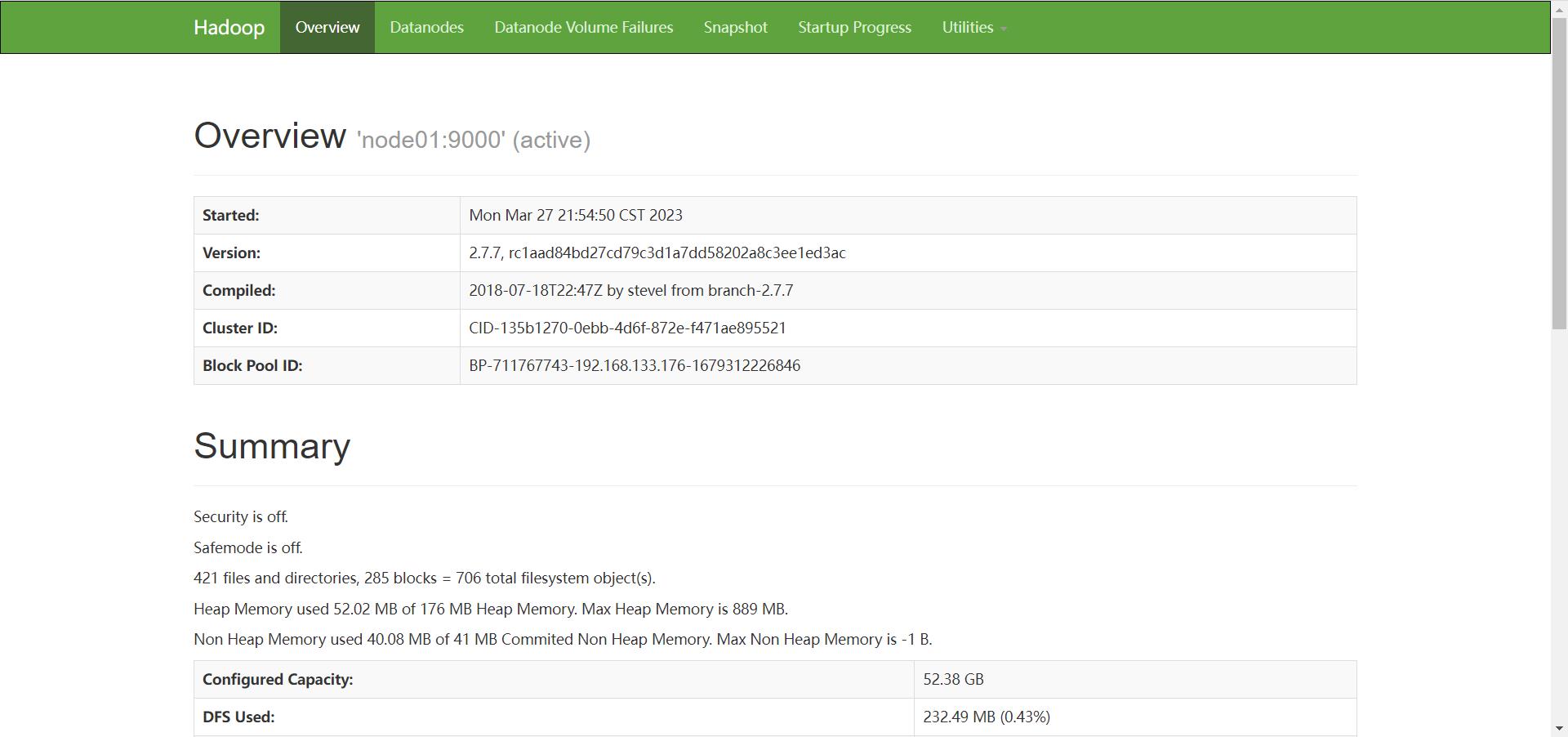
4.2 安装MYSQL
在 node02 上安装 MYSQL
[root@node02 hadoop]# ./installMysql.sh
MYSQL安装成功后, 运行MYSQL
[root@node02 hadoop]# mysql -uroot -pDBa2020*
mysql> show databases;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| azkaban |
| hive |
| mysql |
| performance_schema |
| sys |
+--------------------+
6 rows in set (0.01 sec)
4.3 安装Hive
在 node03 上安装 Hive, 安装过程会自动安装 Tez
[root@node03 hadoop]# ./installHive.sh
如果是INFO信息报错, 可以不用管
4.4 安装Sqoop
接着在 node03 上安装 Sqoop
[root@node03 hadoop]# ./installSqoop.sh
[root@node03 hadoop]# source /etc/profile
4.5 安装 Presto
分别在node01,node02, node03 上安装 Presto
Presto服务端口为8080
# Presto服务端口为8080
[root@node01 hadoop]# ./installPresto.sh
[root@node02 hadoop]# ./installPresto.sh
[root@node03 hadoop]# ./installPresto.sh
,接着分别在node01,node02, node03上安装Azkaban
[root@node01 hadoop]# ./installAzkaban.sh
[root@node02 hadoop]# ./installAzkaban.sh
[root@node03 hadoop]# ./installAzkaban.sh
为Presto安装一个插件,带来可视化的效果
Yanagishima服务端口为7080
# Yanagishima服务端口为7080
[root@node03 hadoop]# ./installYanagishima.sh
分别在node01,node02,node03上更新环境变量
# 分别在node01,node02,node03运行更新环境变量
[root@node01 hadoop]# source /etc/profile
[root@node02 hadoop]# source /etc/profile
[root@node03 hadoop]# source /etc/profile
5. 项目流程&数据生成

创建数据库mall
# 导入临时环境变量
[root@node01 hadoop]# export MYSQL_PWD=DBa2020*
[root@node01 hadoop]# mysql -uroot -e "create database mall;"
进入到 /home 目录下
[root@node02 hadoop]# cd /home/
上传生成数据脚本

将数据生成脚本上传到数据库中
[root@node02 home]# mysql -uroot mall < /root/1建表脚本.sql
[root@node02 home]# mysql -uroot mall < /root/2商品分类数据插入脚本.sql
[root@node02 home]# mysql -uroot mall < /root/3函数脚本.sql
[root@node02 home]# mysql -uroot mall < /root/3函数脚本.sql
[root@node02 home]# mysql
mysql>use mall;
mysql>CALL init_data('2020-08-29',300,200,300,False);
mysql>select count(1) from user_info;
mysql>show tables;
生成了300个订单, 200个用户, 300个商品,False不删除数据
6. ETL数据导入
[root@node03 ~]# mkdir -p /home/warehouse/shell
[root@node03 shell]# cd /home/warehouse/shell/
[root@node03 shell]# vim sqoop_import.sh
[root@node03 shell]# chmod +x sqoop_import.sh
[root@node03 shell]# ./sqoop_import.sh all 2020-08-29
网页可视化查看数据是否导入 http://192.168.192.176:50070/
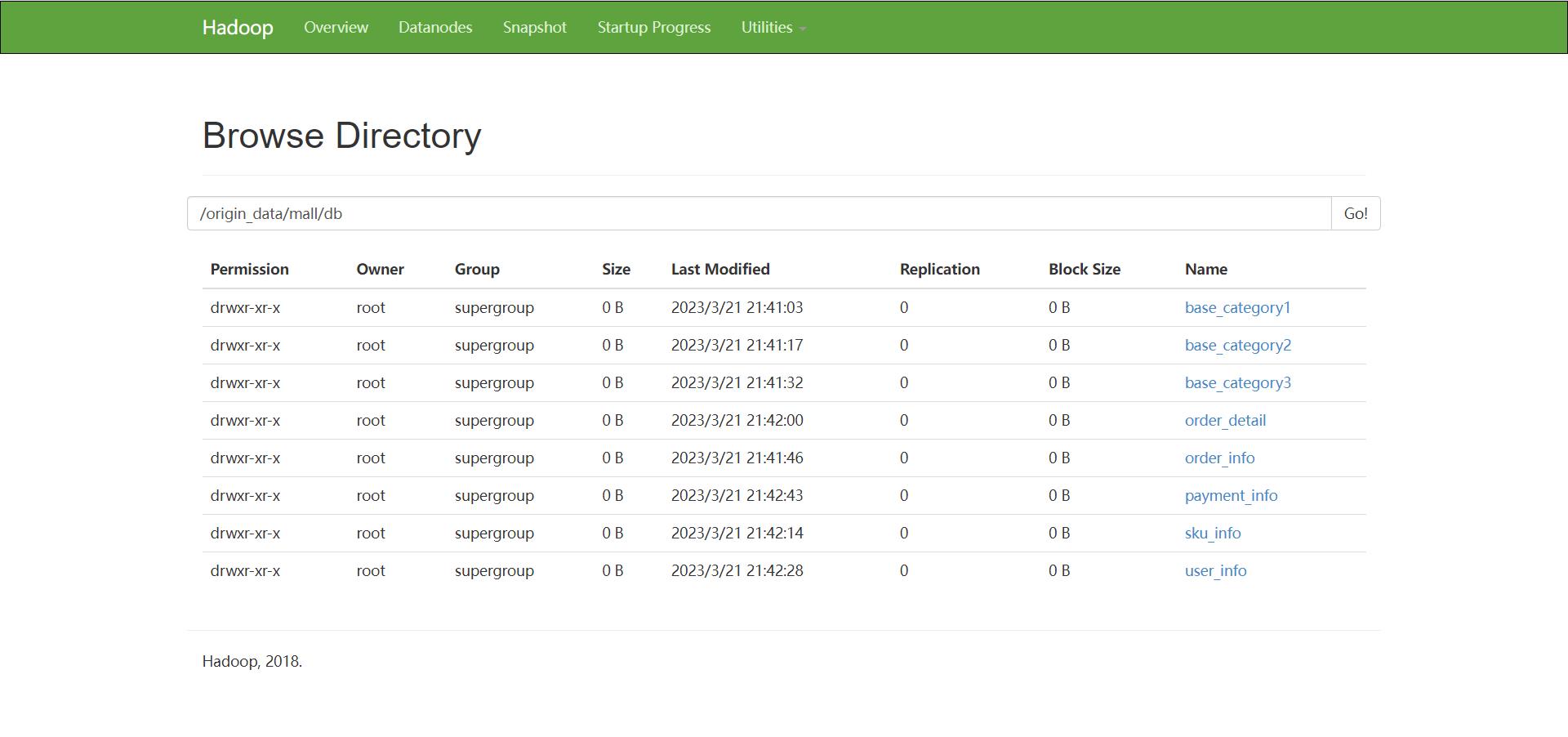
一共是8张表, 如果没有8张表的话, 建议多运行 ./sqoop_import.sh all 2020-08-29 命令几次
到这里,表示我们ETL任务已经成功了
7. ODS层创建&数据接入
启动Hive
# 启动Hive
[root@node03 shell]# hive --service hiveserver2 &
启动Hive的metastore服务
# 启动Hive的metastore
[root@node03 shell]# hive --service metastore &
如果这里报错 拒绝连接 , MSQL拒绝连接, 可能由于网络不通畅的问题引起, 在node03上试一下能不能连接到node02 , 连接不了的话可以重启 node02 的网络服务, systemctl restart network
[root@node02 ~]# systemctl restart network
ODS层创建&数据导入
# ODS层创建&数据导入
[root@node03 ~]# cd /home/warehouse
[root@node03 warehouse]# mkdir sql/
[root@node03 warehouse]# cd sql/
[root@node03 sql]# vim ods_ddl.sql
[root@node03 sql]# hive -f /home/warehouse/sql/ods_ddl.sql
如果很长时间都没有出结果, 可以 Ctrl + c 终止
查看刚刚Hive进行的两个服务
[root@node03 sql]# jps
2378 NodeManager
2133 DataNode
7288 RunJar
7210 RunJar
7646 Jps
[root@node03 sql]# jps -m
.
.
.
7288 RunJar .... /... /... / ....... / hadoop.hive.metastore.HiveMetaStore
.
.
.
# kill metastore服务
[root@node03 sql]# kill -9 7288
# 然后再重启 metastore, metasore服务需要连接mysql服务, 所以需要与node02网络通畅
[root@node03 sql]# hive --service metastore &
# 没有报错,重新执行 hive -f /home/warehouse/sql/ods_ddl.sql
[root@node03 sql]# hive -f /home/warehouse/sql/ods_ddl.sql
执行完后,进入Hive查看, 一共8张表
## 进入hive
[root@node03 shell]# hive
hive>use mall;
OK
Time taken: 0.55 seconds
hive>show tables;
hive>exit;
数据有了,然后完成数据的导入
[root@node03 shell]# cd ..
[root@node03 shell]# cd shell/
# 创建或上传 obs_db.sh
[root@node03 shell]# vim obs_db.sh
[root@node03 shell]# chmod +x obs_db.sh
[root@node03 shell]# ./ods_db.sh 2020-08-29
执行完成后,进入Hive查看数据是否导入
## 进入hive
[root@node03 shell]# hive
hive> use mall;
OK
Time taken: 0.55 seconds
hive> show tables;
hive> select count(1) from ods_user_info;
Query ID = root_20230327220623_2ce7b554-c007-4d37-b282-87a3227c2f16
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1679925264749_0002)
--------------------------------------------------------------------------------
VERTICES STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
--------------------------------------------------------------------------------
Map 1 .......... SUCCEEDED 2 2 0 0 0 0
Reducer 2 ...... SUCCEEDED 1 1 0 0 0 0
--------------------------------------------------------------------------------
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 7.56 s
--------------------------------------------------------------------------------
OK
200
Time taken: 9.383 seconds, Fetched: 1 row(s)
# 200条数据
hive> exit;
8. DWD层创建&数据接入
创建并执行dws_ddl.sql
[root@node03 shell]# cd /home/warehouse/sql/
[root@node03 sql]# vim dws_ddl.sql
创建或上传 dwd_ddl.sql
[root@node03 warehouse]# hive -f /home/warehouse/sql/dwd_ddl.sql
创建并执行dwd_db.sh
[root@node03 shell]# cd /home/warehouse/shell/
# 创建或上传 dwd_db.sh
[root@node03 shell]# vim dwd_db.sh
[root@node03 shell]# chmod +x dwd_db.sh
[root@node03 shell]# ./dwd_db.sh 2020-08-29
执行完成后,进入Hive查看数据是否接入
## 进入hive
[root@node03 shell]# hive
hive>use mall;
hive>show tables;
hive>select * from dwd_sku_info where df='2020-08-29' limit 2;
hive> exit;
9. DWS层创建&数据接入
创建并执行dws_ddl.sql
# DWS层创建&数据接入 node03
[root@node03 shell]# cd /home/warehouse/sql/
[root@node03 shell]# vim dws_ddl.sql
[root@node03 sql]# hive -f /home/warehouse/sql/dws_ddl.sql
创建并执行dws_db.sh
[root@node03 sql]# cd ../shell/
[root@node03 shell]# vim dws_db.sh
[root@node03 shell]# chmod +x dws_db.sh
[root@node03 shell]# ./dws_db.sh 2020-08-29
执行完成后,进入Hive查看数据是否接入
[root@node03 shell]# hive
hive> use mall;
hive> show databases;
hive> select * from dws_user_action where dt="2020-08-29" limit 2;
OK
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
1 3 1593 2 665 2020-08-29
10 1 434 1 434 2020-08-29
Time taken: 0.35 seconds, Fetched: 2 row(s)
# !!! 注意这里的SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder不用管
hive> exit;
10. ADS层复购率统计
创建并执行ads_sale_ddl.sql
# ADS层复购率统计 node03
[root@node03 shell]# cd /home/warehouse/sql/
[root@node03 shell]# vim ads_sale_ddl.sql
[root@node03 sql]# hive -f /home/warehouse/sql/ads_sale_ddl.sql
创建并执行ads_sale.sh
[root@node03 sql]# cd /home/warehouse/shell/
[root@node03 shell]# vim ads_db.sh
[root@node03 shell]# chmod +x ads_sale.sh
[root@node03 shell]# ./ads_sale.sh 2020-08-29
[root@node03 shell]# hive
hive> use mall;
hive> exit;
11. ADS层数据导出
创建并执行mysql_sale.sql
# ADS层数据导入
# node02
[root@node02 ~]# mkdir -p /home/warehouse/sql
[root@node02 sql]# vim mysql_sale.sql
[root@node02 sql]# export MYSQL_PWD=DBa2020*
[root@node02 sql]# mysql -uroot mall < /home/warehouse/sql/mysql_sale.sql
[root@node02 sql]# mysql
mysql> use mall;
mysql> show tables;
+-------------------------------+
| Tables_in_mall |
+-------------------------------+
| ads_sale_tm_category1_stat_mn |
| base_category1 |
| base_category2 |
| base_category3 |
| order_detail |
| order_info |
| payment_info |
| sku_info |
| user_info |
+-------------------------------+
9 rows in set (0.00 sec)
mysql> exit;
创建并执行sqoop_export.sh
# node03
[root@node03 ~]# cd /home/warehouse/shell/
[root@node03 shell]# vim sqoop_export.sh
[root@node03 shell]# chmod +x sqoop_export.sh
[root@node03 shell]# ./sqoop_export.sh all
如果这里报错 拒绝连接 MYSQLIO的问题, 一般这个拒绝连接错误都是MYSQL的问题, 可能由于网络不通畅的问题引起, 重启 node02 的网络服务, systemctl restart network
# node02
[root@node02 sql]# systemctl restart network
[root@node02 sql]# mysql -uroot -pDBa2020*
mysql> use mall;
mysql> select * from ads_sale_tm_category1_stat_mn;
+-------+--------------+----------------+----------+----------------+----------------------+-----------------+-----------------------+---------+------------+
| tm_id | category1_id | category1_name | buycount | buy_twice_last | buy_twice_last_ratio | buy_3times_last | buy_3times_last_ratio | stat_mn | stat_date |
+-------+--------------+----------------+----------+----------------+----------------------+-----------------+-----------------------+---------+------------+
| NULL | NULL | NULL | 158 | 141 | 0.89 | 107 | 0.79 | 2020-08 | 2020-08-29 |
| NULL | NULL | NULL | 158 | 141 | 0.89 | 107 | 0.79 | 2020-08 | 2020-08-29 |
| NULL | NULL | NULL | 284 | 256 | 0.9 | 207 | 0.81 | 2020-08 | 2020-08-30 |
+-------+--------------+----------------+----------+----------------+----------------------+-----------------+-----------------------+---------+------------+
3 rows in set (0.00 sec)
mysql> exit;
12. Azkaban自动化调度
Azkaban自动化调度, 生成数据
# Azkaban自动化调度
# 生成数据
[root@node02 sql]# mysql -uroot -pDBa2020*
mysql> use mall;
mysql> CALL init_data('2020-08-30',300,200,300,FALSE);
Query OK, 0 rows affected (0.70 sec)
**准备mall_job.zip **
三个节点启动Azkaban
# 准备mall_job.zip
# 三个节点启动Azkaban
[root@node01 ~]# azkaban-executor-start.sh
[root@node02 ~]# azkaban-executor-start.sh
[root@node03 ~]# azkaban-executor-start.sh
[AzkabanExecutorServer] [Azkaban] Azkaban Executor Server started on port 12321
# azkaban出问题时,可以重启, 关闭命令如下
# 重启命令 azkaban-executor-shutdown.sh
**启动Azkaban的web网页, 然后打开 https://192.168.192.178:8443/ **
#node03 启动Azkaban的web网页
[root@node03 shell]# cd /opt/app/azkaban/server/
[root@node03 server]# azkaban-web-start.sh
注意:
# https://192.168.192.178:8443/ # node03 注意这里是https
# Azkaban:
# 账号:admin
# 密码:admin
# 创建project mall
# 设置参数 dt 2020-08-30
# 设置参数 useExecutor node03
# 等自动化调度任务执行完后
# 到node02查看执行情况,新建一个node02连接终端
[root@node02 ~]# mysql -uroot -pDBa2020*
mysql> use mall;
mysql> select * from ads_sale_tm_category1_stat_mn;
13. 结果展示


14. 课后作业

15. 更换IP后所需要做的操作
# http://192.168.192.176:50070/ # node01
# https://192.168.192.178:8443/ # node03 注意这里是https
# Azkaban:
# 账号:admin
# 密码:admin
# 更改虚拟机静态IP地址
# 更改host_ip.txt
cd /home/hadoop/automaticDeploy/
vim host_ip.txt
systemctl restart network
source /etc/profile
16. 如何设置静态IP地址
- 右键左下角windows
- 点击网络连接 --> 网络和共享中心
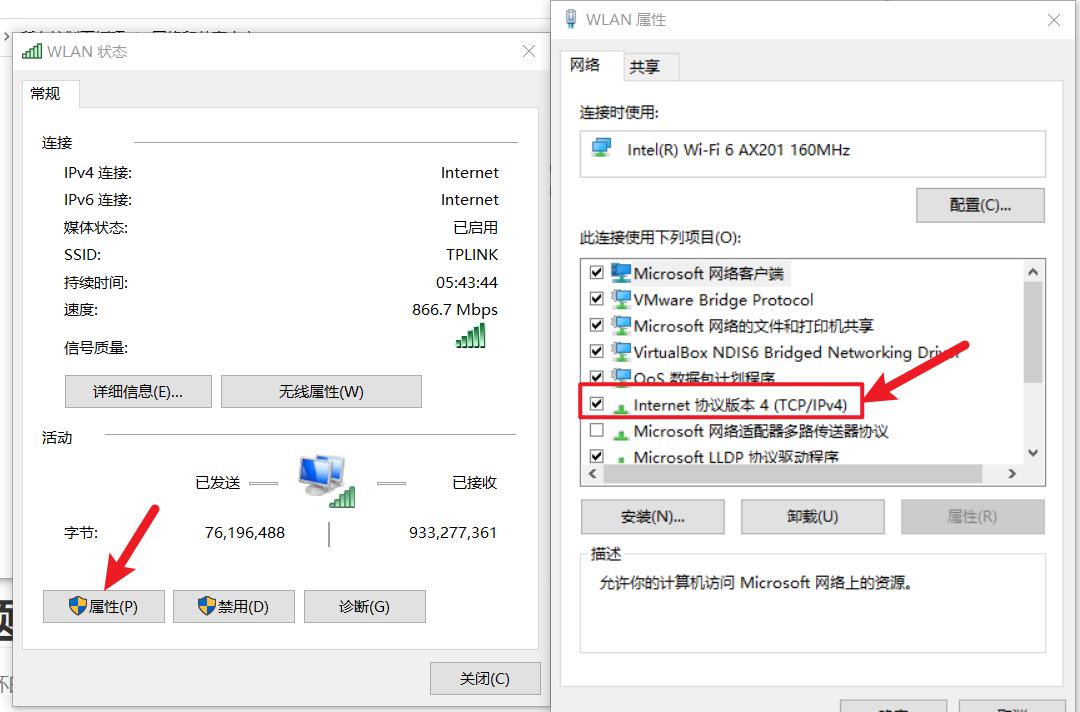
- 接下来按照自己电脑的ip改,我这里这是参考,具体得看每个人自己得电脑

查看自己电脑的ip信息
win+r打开运行cmd,然后输入ipconfig查看
17. 常见问题(未完持续更新中,欢迎补充!)
欢迎大家在搭建数据仓库的遇到的问题在评论区下方提出,也可以补充在下面
相应问题及解决方法:
/bin/bash^M: 坏的解释器: 没有那个文件或目录 : https://blog.csdn.net/qq_56870570/article/details/120182874
拒接连接:重启网络
systemctl restart networkVMware 运行 systemctl restart network失败:软件问题,请使用virtual box
作者:Oraer
都看到最后了,不点个赞+收藏吗?
超详细!教你一步一步搭建 Apache HBase 完全分布式集群
#扫描上方二维码进入报名#
文章链接:https://my.oschina.net/u/876354/blog/1163018
Apache HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存储集群,利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase海量数据,使用Zookeeper协调服务器集群。Apache HBase官网有详细的介绍文档。
Apache HBase的完全分布式集群安装部署并不复杂,下面是部署的详细过程:
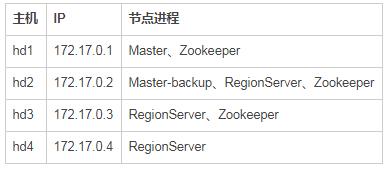
1、规划HBase集群节点
本实验有4个节点,要配置HBase Master、Master-backup、RegionServer,节点主机操作系统为Centos 6.9,各节点的进程规划如下:
2、安装 JDK、Zookeeper、Hadoop
各服务器节点关闭防火墙、设置selinux为disabled
安装 JDK、Zookeeper、Apache Hadoop 分布式集群(具体过程详见我另一篇博文:Apache Hadoop 2.8分布式集群搭建超详细过程)
安装后设置环境变量,这些变量在安装配置HBase时需要用到
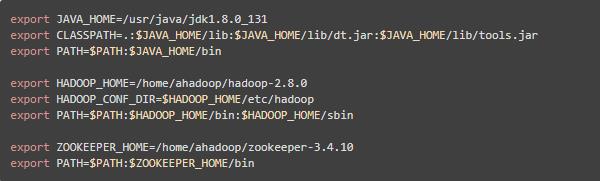
3、安装NTP,实现服务器节点间的时间一致
如果服务器节点之间时间不一致,可能会引发HBase的异常,这一点在HBase官网上有特别强调。在这里,设置第1个节点hd1为NTP的服务端节点,也即该节点(hd1)从国家授时中心同步时间,然后其它节点(hd2、hd3、hd4)作为客户端从hd1同步时间
(1)安装 NTP

启动 NTP 服务

(2)配置NTP服务端
在节点hd1,编辑 /etc/ntp.conf 文件,配置NTP服务,具体的配置改动项见以下中文注释
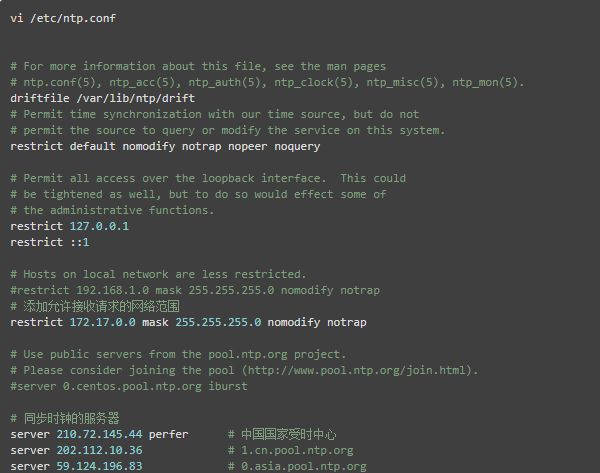
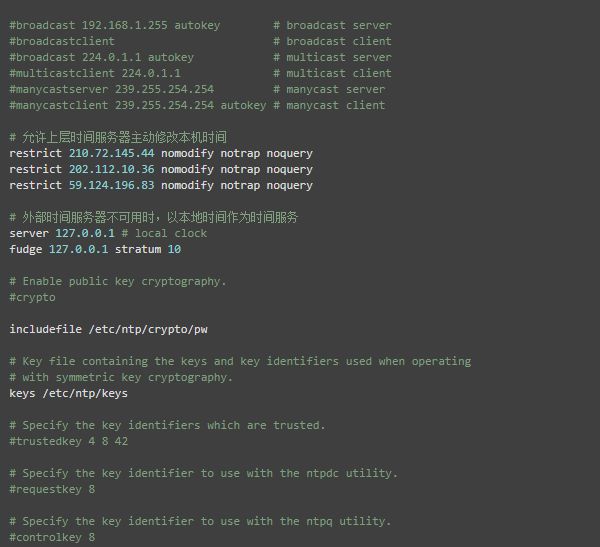
重启 NTP 服务

然后查看ntp状态

这时发现有报错,原来ntpd服务有一个限制,ntpd仅同步更改与ntp server时差在1000s内的时间,而查了服务器节点的时间与实际时间差已超过了1000s,因此,必须先手动修改下操作系统时间与ntp server相差时间在1000s以内,然后再去同步服务
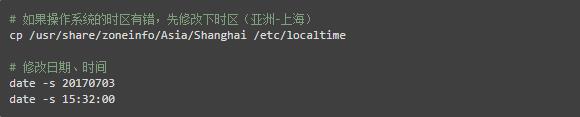
其实还有另外一个小技巧,就是在安装好NTP服务后,先通过授时服务器获得准确的时间,这样也不用手工修改了,命令如下:

【注意】如果是在docker里面执行同步时间操作,系统会报错

如果出现这个错误,说明系统不允许自行设置时间。在docker里面,由于docker容器共享的是宿主机的内核,而修改系统时间是内核层面的功能,因此,在 docker 里面是无法修改时间
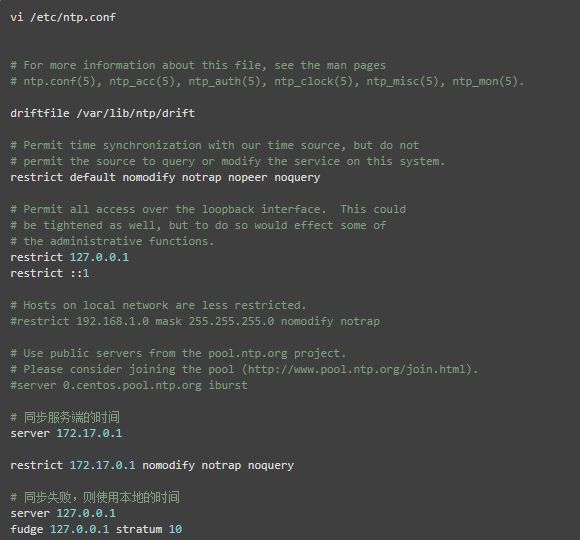
(3)配置NTP客户端
在节点hd2、hd3、hd4编辑 /etc/ntp.conf 文件,配置 NPT 客户端,具体的配置改动项,见以下的中文注释
重启NTP服务

启动后,查看时间的同步情况

4、修改ulimit
在Apache HBase官网的介绍中有提到,使用 HBase 推荐修改ulimit,以增加同时打开文件的数量,推荐 nofile 至少 10,000 但最好 10,240 (It is recommended to raise the ulimit to at least 10,000, but more likely 10,240, because the value is usually expressed in multiples of 1024.)
修改 /etc/security/limits.conf 文件,在最后加上nofile(文件数量)、nproc(进程数量)属性,如下:

修改后,重启服务器生效

5、安装配置Apache HBase
Apache HBase 官网提供了默认配置说明、参考的配置例子,建议在配置之前先阅读一下。
在本实验中,采用了独立的zookeeper配置,也hadoop共用,zookeeper具体配置方法可参考我的另一篇博客。其实在HBase中,还支持使用内置的zookeeper服务,但如果是在生产环境中,建议单独部署,方便日常的管理。
(1)下载Apache HBase
从官网上面下载最新的二进制版本:hbase-1.2.6-bin.tar.gz
然后解压

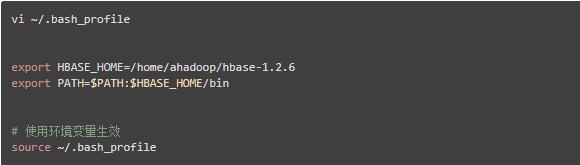
配置环境变量
(2)复制hdfs-site.xml配置文件
复制$HADOOP_HOME/etc/hadoop/hdfs-site.xml到$HBASE_HOME/conf目录下,这样以保证hdfs与hbase两边一致,这也是官网所推荐的方式。在官网中提到一个例子,例如hdfs中配置的副本数量为5,而默认为3,如果没有将最新的hdfs-site.xml复制到$HBASE_HOME/conf目录下,则hbase将会按3份备份,从而两边不一致,导致会出现异常。

(3)配置hbase-site.xml
编辑 $HBASE_HOME/conf/hbase-site.xml
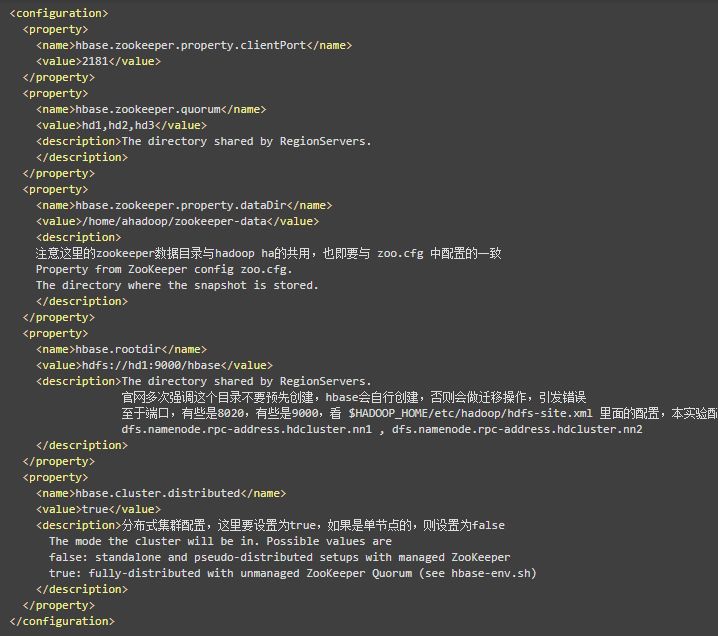
(4)配置regionserver文件
编辑 $HBASE_HOME/conf/regionservers 文件,输入要运行 regionserver 的主机名

(5)配置 backup-masters 文件(master备用节点)
HBase 支持运行多个 master 节点,因此不会出现单点故障的问题,但只能有一个活动的管理节点(active master),其余为备用节点(backup master),编辑 $HBASE_HOME/conf/backup-masters 文件进行配置备用管理节点的主机名

(6)配置 hbase-env.sh 文件
编辑 $HBASE_HOME/conf/hbase-env.sh 配置环境变量,由于本实验是使用单独配置的zookeeper,因此,将其中的 HBASE_MANAGES_ZK 设置为 false

到此,HBase 配置完毕
6、启动 Apache HBase
可使用 $HBASE_HOME/bin/start-hbase.sh 指令启动整个集群,如果要使用该命令,则集群的节点必须实现ssh的免密码登录,这样才能到不同的节点启动服务
为了更加深入了解HBase启动过程,本实验将对各个节点依次启动进程,经查看 start-hbase.sh 脚本,里面的启动顺序如下
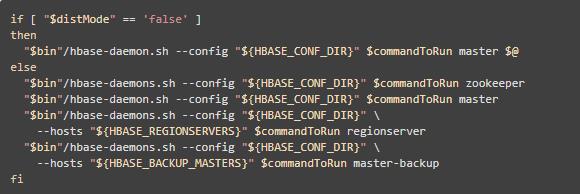
也就是使用 hbase-daemon.sh 命令依次启动 zookeeper、master、regionserver、master-backup
因此,我们也按照这个顺序,在各个节点进行启动
在启动HBase之前,必须先启动Hadoop,以便于HBase初始化、读取存储在hdfs上的数据
(1)启动zookeeper(hd1、hd2、hd3节点)

(2)启动hadoop分布式集群(集群的具体配置和节点规划,见我的另一篇博客)
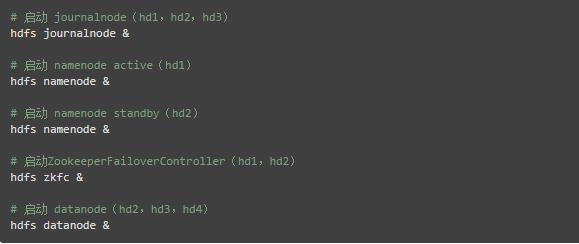
(3)启动hbase master(hd1)

(4)启动hbase regionserver(hd2、hd3、hd4)

(5)启动hbase backup-master(hd2)

这里很奇怪,在 $HBASE_HOME/bin/start-hbase.sh 写着启动 backup-master 的命令为

但实际按这个指令执行时,却报错提示无法加载类 master-backup
[ahadoop@1620d6ed305d ~]$ hbase-daemon.sh start master-backup &
[5] 1113
[ahadoop@1620d6ed305d ~]$ starting master-backup, logging to /home/ahadoop/hbase-1.2.6/logs/hbase-ahadoop-master-backup-1620d6ed305d.out
Error: Could not find or load main class master-backup
最后经查资料,才改用了以下命令为启动 backup-master

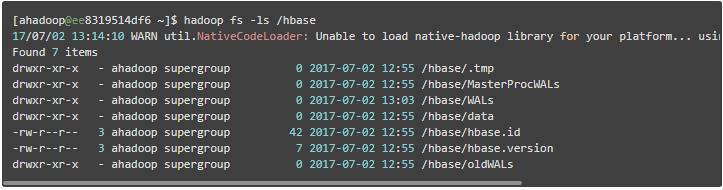
经过以上步骤,就已成功地启动了hbase集群,可到每个节点里面使用 jps 指令查看 hbase 的启动进程情况。
启动后,再查看 hdfs 、zookeeper 的 /hbase 目录,发现均已初始化,并且已写入了相应的文件,如下
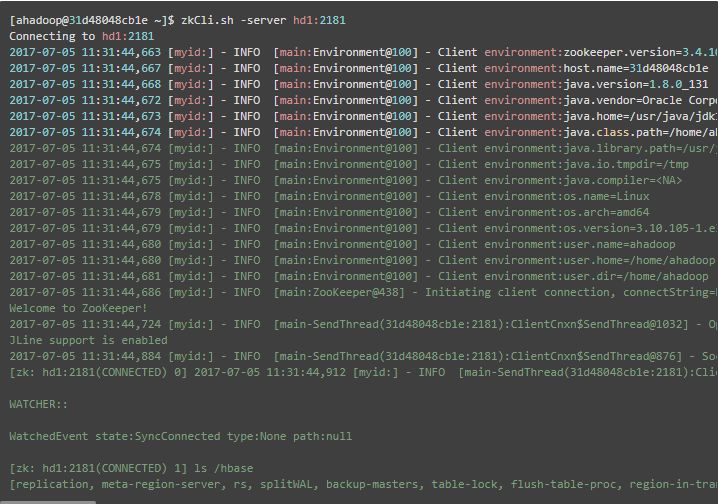
7、HBase 测试使用
使用hbase shell进入到 hbase 的交互命令行界面,这时可进行测试使用

(1)查看集群状态和节点数量

(2)创建表

hbase创建表create命令语法为:表名、列名1、列名2、列名3……
(3)查看表

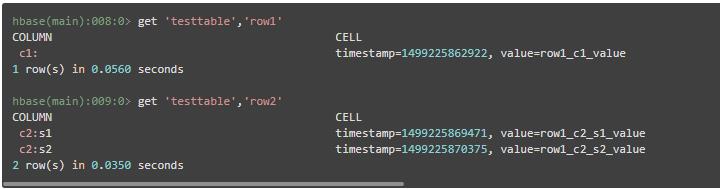
(4)导入数据

导入数据的命令put的语法为表名、行值、列名(列名可加冒号,表示这个列簇下面还有子列)、列数据
(5)全表扫描数据

(6)根据条件查询数据
(7)表失效
使用 disable 命令可将某张表失效,失效后该表将不能使用,例如执行全表扫描操作,会报错,如下

(8)表重新生效
使用 enable 可使表重新生效,表生效后,即可对表进行操作,例如进行全表扫描操作
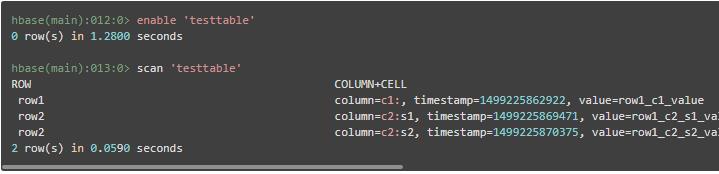
(9)删除数据表
使用drop命令对表进行删除,但只有表在失效的情况下,才能进行删除,否则会报错,如下
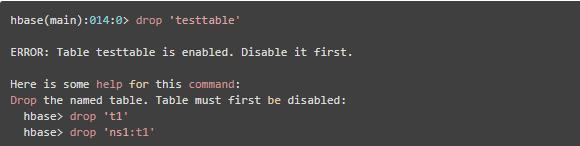
先对表失效,然后再删除,则可顺序删除表

(10)退出 hbase shell

以上就是使用hbase shell进行简单的测试和使用
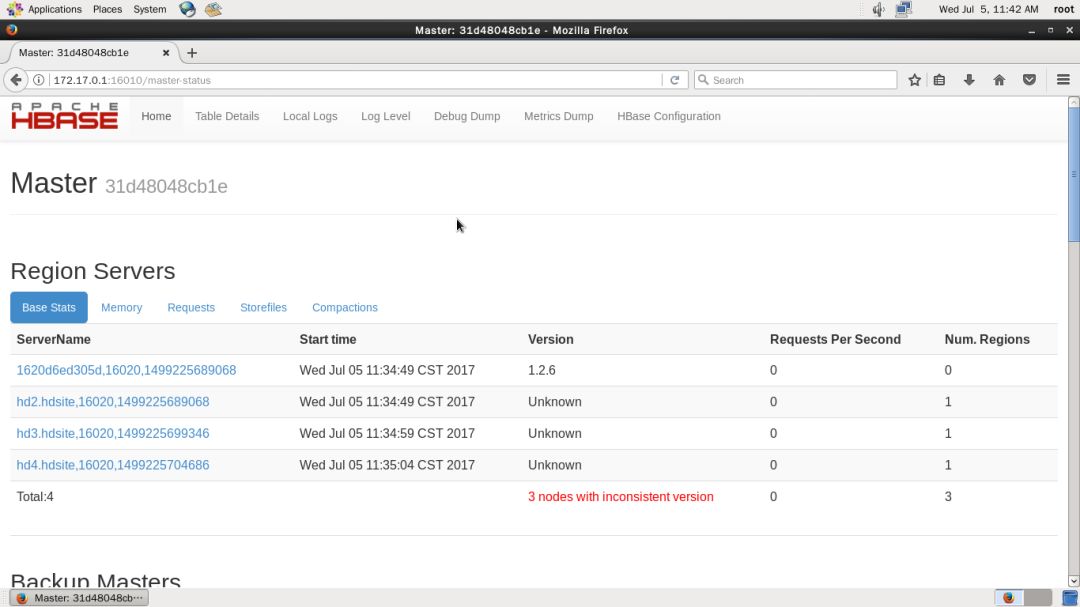
8、HBase 管理页面
HBase 还提供了管理页面,供用户查看,可更加方便地查看集群状态
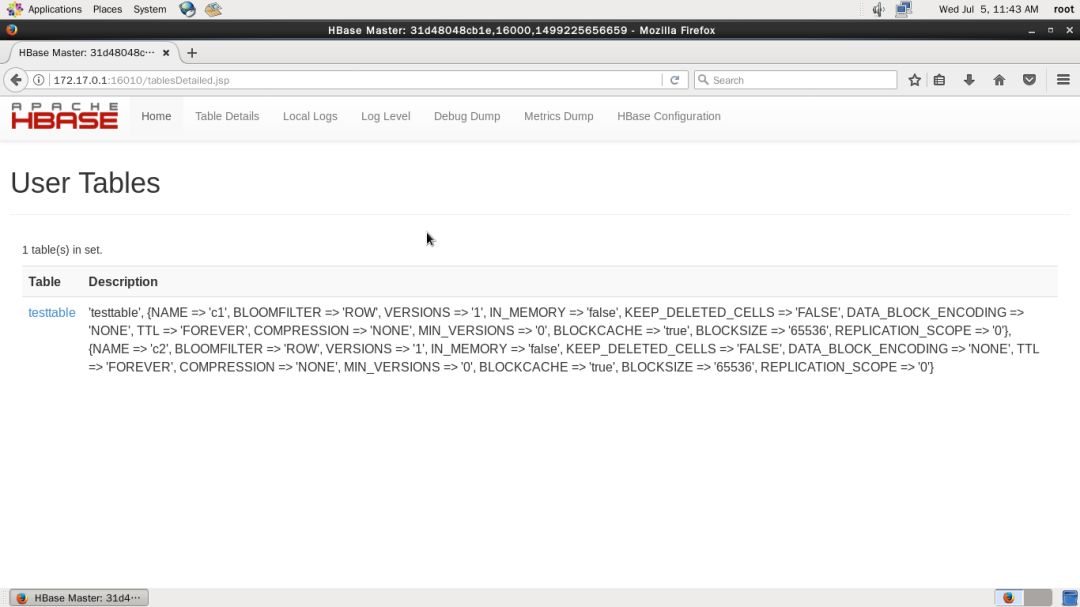
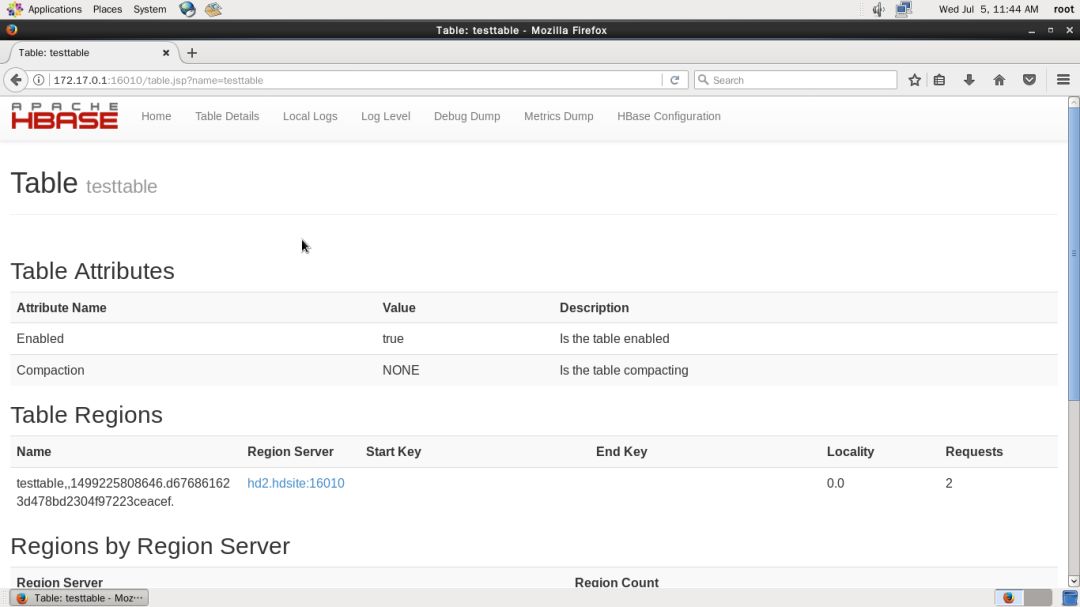
在主页的 Tables 下面也会列出表名出来,点击可查看某张表的信息,如下图
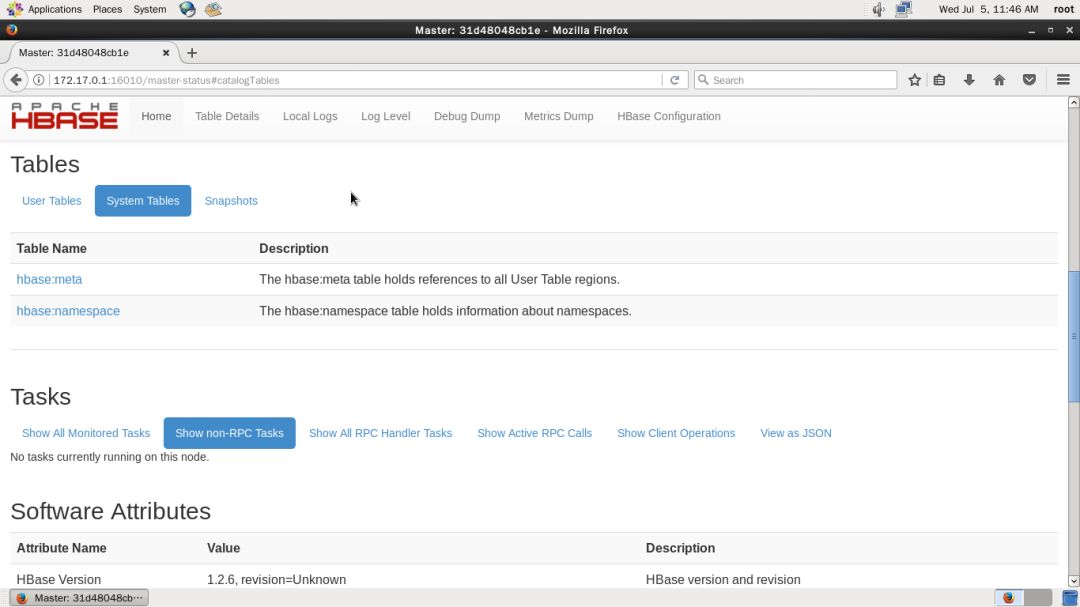
在 Tables 中点击 System Tables 查看系统表,主要是元数据、命名空间,如下图
以上就是Apache HBase集群配置,以及测试使用的详细过程,欢迎大家批评指正,共同交流进。

以上是关于超详细入门精讲数据仓库原理&实战 一步一步搭建数据仓库 内附相应实验代码和镜像数据和脚本的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop集群搭建准备环境,手把手教你一步一步搭建,超详细