Segmentation-Based Deep-Learning Approach for Surface-Defect Detection-论文阅读笔记
Posted wyypersist
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Segmentation-Based Deep-Learning Approach for Surface-Defect Detection-论文阅读笔记相关的知识,希望对你有一定的参考价值。
Segmentation-Based Deep-Learning Approach for Surface-Defect Detection
基于分割的表面缺陷深度学习检测方法
//2022.7.20下午12:49开始阅读笔记
论文速览
文中提出了一个基于分割的两阶段的表面缺陷检测方法。第一阶段包括在缺陷的像素级标签上训练的分割网络,而第二阶段包括在分割网络上构建的附加决策网络,以预测整个图像中是否存在异常。对所提出的方法进行了广泛的评估,评估对象是半成品工业产品,即电换向器,其中表面缺陷表现为材料断裂。该问题域已作为基准数据集公开,称为Kolektor表面缺陷数据集(KolektorSDD)。在该领域,将该方法与几种最先进的方法进行了比较,包括专用的商用软件和两种基于深度学习的标准分割方法。
同时,使用决策网络增加了提出网络的精度。
为了在图像中检测出来小目标缺陷,分割网络的设计需要有如下重要要求:
-
高分辨率图像中的较大感受野的尺寸;
-
网络架构可以捕获小目标特征;
为了实现上述两个要求,作者对分割网络的架构进行了如下修改:
-
使用额外的下采样层,且在较高层中使用较大的内核大小来显著增加感受野大小;
-
将每次下采样的层数更改为在架构的具有较少层的较低部分,这增加了具有较大感受野大小的特征容量;
-
最后,只用Maxpooling层而不是使用卷积层进行下采样,这将确保较小的特征在前向传播的过程中保存下来。
论文地址
[1903.08536] Segmentation-Based Deep-Learning Approach for Surface-Defect Detection (arxiv.org)
论文贡献
本文提出了一种基于分割的缺陷检测框架,该结构可以在少量样本的情况下进行训练,此外,文中作者将所提出的方法与最先进的深度学习架构和商业软件进行性能的比较,结果表明文中提出的方法达到了最好的性能,同时,作者指出,该方法仅在25-30个缺陷样本上进行训练
论文内容
1.介绍
对于使用特征工程的机器学习检测方法,针对不同场景,并不适合。
图1中显示了文中提出的深度学习方法。
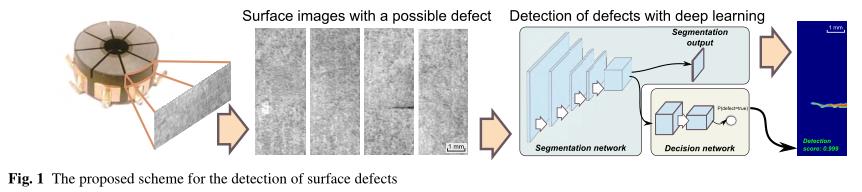
文中从工业4.0的角度出发,从以下角度探索网络结构:
-
注释要求;
-
所需训练样本的数量;
-
计算要求;
文章提出了两阶段的深度学习框架来实现检测任务,提出了一种新的分割和决策网络,该网络适合从小量样本中学习,但是仍然可以达到最先进的效果。
本文提出的方法在KolektorSDD数据集中进行了性能评估,
2.相关工作
和相关网络相比,本文提出的结构集合了分段网络和决策网络,修改了其中的部分结构以增加感受野的大小,并增加了网络对小目标的提取能力。
本文选择了DeepLabv3+,U-Net作为基础网络架构,同时,使用Deeplabv3+网络对使用预训练的性能影响做出了评估实验。该网络使用ImageNet和MS COCO数据集进行预训练。
3.提出的方法
文中设计了两阶段网络适应了小样本数据集的训练。
图2为提出的两阶段网络架构。

在图2中,第一阶段提出了一个分割网络,该网络对表面缺陷进行像素级定位。使用单个像素作为训练样本,从而增加了训练样本的数量,放置了网络在训练中出现过度拟合现象。
第二阶段使用第一个阶段的分割网络的输出的特征进行二值分类。
3.1 分割网络
该网络由11个卷积层和3个最大池层组成,每个层将分辨率降低两倍。每个卷积层后边跟着特征归一化和非线性ReLU层,这两者都有助于提高学习过程中的收敛速度。
特征归一化将每个通道归一化为具有单位方差的零均值分布。前九个卷积层使用5×5的内核大小,而后两个层分别使用15×15和1×1的内核大小。如图2中网络架构的详细描述所示,为不同层分配了不同数量的信道。在应用1×1卷积层后获得最终输出掩码,该卷积层减少了输出通道的数量。这导致单通道输出映射的输入图像分辨率降低了8倍。由于卷积层中的权重共享提供了足够的正则化,因此在该方法中不使用Dropout层。
为了在图像中检测出来小目标缺陷,分割网络的设计需要有如下重要要求:
-
高分辨率图像中的较大感受野的尺寸;
-
网络架构可以捕获小目标特征;
为了实现上述两个要求,作者对分割网络的架构进行了如下修改:
1.使用额外的下采样层,且在较高层中使用较大的内核大小来显著增加感受野大小;
2.将每次下采样的层数更改为在架构的具有较少层的较低部分,这增加了具有较大感受野大小的特征容量;
3.最后,只用Maxpooling层而不是使用卷积层进行下采样,这将确保较小的特征在前向传播的过程中保存下来。
3.2 决策网络
该网络采用分段网络的最后一个卷积层(1024个通道)的输出,并与单通道分段输出映射串联。这将产生1025个通道体积,代表具有最大池层和具有5×5内核大小的卷积层的其余层的输入。两个层的组合重复3次,第一、第二和第三卷积层中分别有8、16和32个通道。结构的详细描述如图2所示。通道的数量随着特征分辨率的降低而增加,因此对每一层的计算要求相同。该设计有效地使最后一个卷积层的分辨率比原始图像的分辨率低64倍。最后,网络执行全局最大和平均池,产生64个输出神经元。此外,分割输出图上的全局最大值和平均值池的结果被连接为两个输出神经元,为分割图已经确保完美检测的情况提供了捷径。这种设计产生了66个输出神经元,这些神经元与线性权重组合成最终的输出神经元。
其次,决策网络不仅使用1×1核信道约简之前来自分割网络的最后一次卷积运算的输出特征量,还使用1×1核信道约简之后获得的最终分割输出图。这引入了一个快捷方式,网络可以避免使用大量特征图。它还减少了对大量参数的过度拟合。快捷方式在两个层次上实现:一个在决策网络的开头,其中分割输出映射被前馈传播送到决策网络的几个卷积层,另一个在决策网络的结尾,其中分割输出映射的全局平均值和最大值被附加到最终全连接层的输入。
3.3 学习过程
文中评估了两种不同的训练方法:1.使用MSE均方误差损失的回归;2.使用具有交叉山海关损失的二元分类函数;
模型直接使用正态分布对其中的参数进行初始化。
网络训练细节:
利用交叉熵损失函数训练决策网络。学习与分割网络分开进行。首先,只独立训练分割网络,然后冻结分割网络的权重,只训练决策网络层。通过仅微调决策层,网络避免了分割网络中大量权重的过度拟合问题。这在学习决策层的阶段比在学习分割层的阶段更重要。在学习决策层时,GPU内存的限制将批大小限制为每批仅一个或两个样本,但在学习分割层时,图像的每个像素被视为一个单独的训练样本,因此将有效批大小增加了几倍。
作者解释了使用两阶段学习机制的原因:
同时考虑了分割网络和决策网络的同时学习。损失函数的类型在这种情况下发挥了重要作用。只有当两个网络都使用交叉熵时,才可能同时学习。由于损耗适用于不同的范围,即一个在每像素级别,另一个在每图像级别,因此两个层的精确归一化起着至关重要的作用。最后,事实证明,与使用单独的学习机制相比,正确归一化这两种损失不仅在实践中更难实现,而且也没有带来任何性能增益。因此,两阶段学习机制被证明是一个更好的选择,并随后在所有实验中使用。
3.4 推理
该网络的输入是灰度图像。网络架构与输入大小无关,类似于全卷积网络(Long等人2015),因为全连接层不用于特征图,但用于在通过全局平均和最大池消除空间维度后的特征图。因此,根据问题的不同,输入图像可以是高分辨率或低分辨率。本文探讨了两种图像分辨率:1408×512和704×256。
该网络模型返回两个输出。第一个输出是作为分割网络输出的分割掩码。分割掩码输出8×8组输入像素的缺陷概率;因此,输出分辨率相对于输入分辨率降低了8倍。由于高分辨率图像中8×8像素块的分类足以解决当前问题,因此输出地图不会插值回原始图像大小。第二个输出是[0,1]范围内的概率分数,表示决策网络返回的图像中存在异常的概率。
4.分割和决策网络评估
4.1 Kolektor表面缺陷数据集上的检测结果
图像像素为:1408x512。
该数据集由50个有缺陷的电气换向器组成,每个换向器最多有8个相关表面。这总共产生了399张图像。在两个项目中,缺陷在两个图像中可见,而对于其余项目,缺陷仅在单个图像中可见,这意味着有52个图像中缺陷可见(即缺陷或阳性样品)。对于每个图像,都提供了详细的逐像素注释掩码。剩余的347幅图像用作非缺陷表面的负面示例。具有可见缺陷和没有可见缺陷的图像的示例如图3所示。

数据集中注释标记对模型性能的至关重要。
数据集注释细节:
为此,通过使用不同核大小(即5、9、13和17像素)的形态学操作扩展原始注释,生成了另外四种注释类型。注意,这适用于原始分辨率的图像,在分辨率为一半的实验中,注释掩码在放大后会减小。所有注释,一个手动的(a)和四个生成的(b-e)如图4所示。

4.2 实验
作者在如下四个配置组下对模型的性能进行了评估:
1.5种注释类型;
2.分割网络的两种损失函数类型(均方误差和交叉熵);
3. 两种尺寸的输入图像(全尺寸和半尺寸);
4. 无90和有90◦ 的输入图像旋转;
每个配置组都可以从四个方面评估网络的性能。不同的注释类型允许评估注释精度的影响,而不同的图像分辨率允许以较低的计算成本评估对分类性能的影响。此外,还评估了不同损失函数的影响以及通过以0.5的概率旋转图像来增加训练数据的影响。
为了进行评估,将表面缺陷检测问题转化为二值图像分类问题。主要目标是将图像分为两类:(a)存在缺陷和(b)不存在缺陷。虽然可以从分割网络中获得缺陷的像素级分割,但评估并不测量像素级误差,因为它在工业环境中并不重要。相反,只测量每图像二值图像分类错误。分割输出仅用于可视化目的。
4.3 性能指标
评估指标选择相关的详细说明:
评估采用三重交叉验证进行,同时确保同一物理产品的所有图像处于同一折叠中,因此不会同时出现在训练集和测试集中。考虑到三种不同的分类指标:(a)平均精度(AP),(b)误报数(FN)和(c)误报数(FP),对所有评估的网络进行比较。注意,阳性样品被称为具有可见缺陷的图像,阴性样品被称为没有可见缺陷的图像。评估中使用的主要指标是平均精度。这比FP或FN更合适,因为平均精度计算为precisionrecall曲线下的面积,并在单个值中准确捕获不同阈值下模型的性能。另一方面,未命中分类(FP和FN)的数量取决于应用于分类分数的特定阈值。我们报告了在达到最佳F-测度的阈值下未命中分类的数量。此外,请注意,选择AP而不是ROC曲线下的面积(AUC),因为与AUC相比,AP更准确地反映=了具有大量负(即无缺陷)样本的数据集的性能。
4.4 实施和学习细节
作者为了保证训练过程中正负样本的平衡,采用了如下方法:在每个偶数次迭代中使用有缺陷的样本,再每个奇数次迭代中使用没有缺陷的样本。因为,数据集中存在较多的无缺陷样本,如果单纯使用平常的训练方法,会出现训练样本正/负类别不平衡的问题,且由于数据集中存在较多的无缺陷样本,模型训练过程中会更加缓慢。
上述的训练细节表明,epoches不能表示网络模型的训练迭代次数。因为数据集中的无缺陷样本数量是缺陷样本数量的8倍,并且文中提出的网络在接收所有非缺陷图像之前接收相同的缺陷图像。
上述的分割和决策两个网络都经过了多达6600个步骤的训练。每个训练集中有33个缺陷图像,在每个步骤中在缺陷图像和非缺陷图像之间交替,这转化为100个时代。仅当至少遍历过所有缺陷图像时,才认为一个epoch训练结束,但并不是所有的非缺陷图像都需要遍历过。
4.5 分割和决策网络
图5所示为提出的网络性能评估。
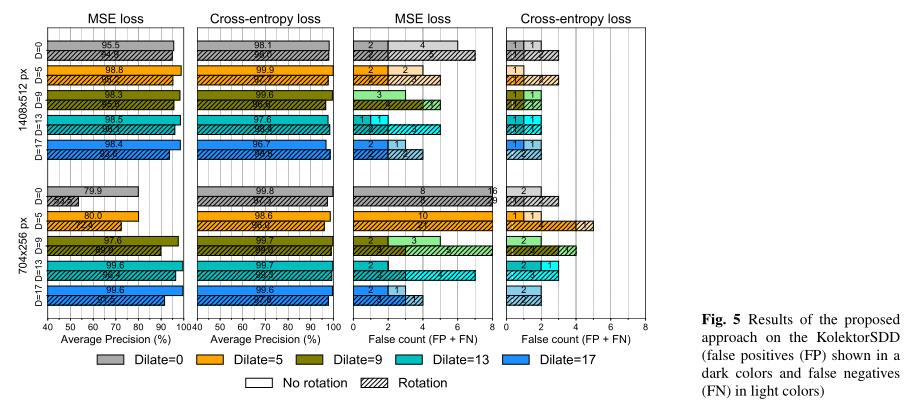
图5中显示:使用5×5核尺寸(扩张=5)扩展的注释、交叉熵损失函数、全图像分辨率和无任何图像旋转获得了最佳效果。
该配置中的网络平均精度(AP)为99.9%,无假阳性(FP)和一个假阴性(FN)。
可以观察到如下几个设置更改对性能的影响:
-
分割网络的交叉熵损失函数从均方误差损失更改;
-
从全图像分辨率更改为较小的图像分辨率;
-
输入数据旋转90◦ 或无旋转;
图6中报告了所有实验中平均AP的改善。通过首先计算所有设置(如图5所示)的所有可能配置的AP,然后计算仅更改所述设置的两个实验之间的AP差异,获得特定设置更改的结果,例如,从全图像分辨率更改为图像分辨率的一半,例如,在使用半图像分辨率的实验和使用全图像分辨率的实验之间,但所有其他设置都相同。性能的整体改善是通过平均AP与所有其他保持不变的设置之间的差异来实现的。还分别报告了正方向和负方向的标准偏差。

损失函数 当比较图5中的均方误差损失(MSE)和交叉熵损失函数时,很明显,使用交叉熵损失函数训练的网络获得了最佳性能。这反映在AP度量和FP/FN计数中,以及图6中所有其他设置的平均交叉熵的改进中。平均而言,交叉熵的AP提高了7个百分点(pp)。
图像分辨率 如图6所示,图像分辨率降低的网络平均在AP差5%的情况下执行。仔细检查图5表明,较小的图像主要对使用MSE损失函数训练的网络产生负面影响,而使用交叉熵训练的网络不受影响。交叉熵对降低的图像分辨率不太敏感,在某些情况下,分辨率降低的图像表现稍好(在AP中约为1%)。
图像旋转 另一方面,随机旋转图像并没有被证明是有用的,也没有带来任何显著的性能提升。在某些情况下,增益最多为1%;然而,在其他情况下,性能下降了更多。
注释类型 最后,比较图5中的不同注释类型,在使用较小注释(原始注释或小核膨胀)进行训练时,以及在考虑交叉熵损失时,只会对性能产生轻微的负面影响。这种差异在均方误差损失函数中更为明显。总的来说,最好的结果似乎是以中到大的扩张率扩张注释。
4.6 决策网络的贡献
本文还评估了决策网络对最终性能的贡献。通过将上一节的结果与不带决策网络的分割网络进行比较来衡量这一贡献。使用简单的二维描述符和逻辑回归代替决策网络。从分割输出图的全局最大值和平均池的值创建二维描述符,然后将其用作逻辑回归的特征,该特征在网络已经训练后从分割网络中单独学习。

结果如图7所示。当关注具有交叉熵损失的模型时,很明显,只有分段网络的网络已经取得了相当好的结果。通过Digrate=9注释获得的最佳配置的平均精度(AP)为98.2%,零误报(FP)和四误报(FN)。然而,决策网络在大多数实验中改善了这一结果。决策网络对均方误差损失的贡献较大。当仅使用分割网络时,MSE损失函数的平均精度达到小于90%的AP,而使用决策网络时,MSE损失的AP高于95%。对于使用交叉熵训练的网络,决策网络也有助于提高性能,但由于分割网络已经表现良好,改进幅度略小,将AP提高了3.6个百分点,使决策网络的平均AP提高到98%以上。在理想阈值下,未命中分类的数量也呈现相同的趋势,其中,当包含决策网络时,分割网络的平均4个未命中分类减少到平均2个未命中分类。
上述这些结果表明了决策网络的重要作用。简单的每像素输出分割似乎没有足够的信息来预测图像中是否存在缺陷,决策网络也同样如此。另一方面,该决策网络能够从最后一个分割层的丰富特征中捕获信息,并通过额外的决策层,将噪声与正确的特征分离。决策网络中的额外下采样也有助于提高性能,因为这增加了感受野的大小并启用了决策网络对捕捉缺陷的全局形态。全局形状对于分类很重要,但对于像素级分割并不重要。
4.7 所需的注释精度
本节通过评估更粗糙注释对分类性能的影响来进一步探讨这一点。为此,创建了另外两种类型的注释,称为:(a)带边界框的大注释和(b)带旋转边界框的粗注释。两个注释如图8所示。

实验表明,大型注释的性能几乎与更精细的注释一样好。
图9结果显示:表示为big的注释性能稍差,最佳AP为98.7%和3个未命中分类,而coarse注释的AP为99.7%和2个未命中分类。请注意,在较小的图像分辨率下,两种注释都可以实现类似的AP,并且未命中分类的数量相同。

5.与最先进技术的比较
5.1 与商业软件的性能比较
使用的是:Cognex ViDi Suite软件
在本文中,所有使用Cognex ViDi Suite v2.1的实验都是在监督模式下使用ViDi-Red工具进行的。
使用的配置:
-
五种注释类型;
-
三种特征尺寸;
-
两种尺寸的输入图像(全尺寸和半尺寸);
-
有/无90◦ 输入数据旋转;
和上述第4节中的设置一样,但是实验过程少了使用不同loss函数进行,此外,本次使用软件的实验中还增加了对不同像素特征的性能评估。根据文档,不建议使用小于15像素的功能,而大于60像素的功能会产生更糟糕的结果。
实现细节(略)
结果
结果如图10所示。在不同的学习设置中,使用使用扩张=5注释训练的模型,使用最小的特征大小(20像素),在不旋转图像和使用原始图像大小的情况下,获得了最佳性能。该模型实现了99.0%的AP和5个未分类,即5个FN和0个FP。注意,一个模型仅实现了4个误分类,尽管总体上AP较低。

注释大小的影响
在不同的注释类型中,扩展注释的性能优于非扩展注释。然而,在不同的扩张率中,性能增益最小,扩张=5和扩张=17之间只有0.1pp的差异。
特征矩阵大小
比较不同的特征尺寸,无论注释精度如何,具有小特征的模型始终优于具有较大特征的模型。这可以归因于具有高图像分辨率和许多小表面缺陷的数据集的细节。此外,对半分辨率图像的实验表明,在这种情况下,大特征的表现明显不如小特征。这导致了这样一个结论,即较大的特征尺寸无法捕捉较小的细节,这对于分类很重要。
图像大小和是否旋转对模型性能的影响
最后,实验还表明,无论是半分辨率图像还是将输入数据随机旋转90◦ 导致了性能的提高。在这两种情况下,性能都略有下降,但两者的性能下降都很小。
5.2 使用最先进的分割网络的对比实验
对DeepLabV3+和U-Net网络结构来说仅使用交叉熵损失函数,且只使用了没有旋转的全分辨率图像,因为上述实验设置在之前的实验中表现得最好。
实现细节
将上述两种经典的分割网络替换到了文中提出的两阶段的检测框架的分割部分。
对DeepLabV3+网络,在单尺度上进行训练。
对U-Net来说,在每个卷积层后添加了一个批量归一化层BN层,原始U网络还以全输入分辨率输出分割;然而,由于全分辨率的像素级精确分割不符合本实验的利益,因此输出map矩阵分辨率降低了8倍。这与拟议网络中的输出分辨率相同。
使用上述两种网络进行训练的结果如下:

结果分析
结果如图11所示。在标准网络中,性能最好的模型,即使用deplabv3=9注释训练的DeepLabv3+获得了98.0%的AP,并在理想F-标准下获得了两个FP和四个FN。总的来说,稍微放大的注释显示出最佳结果,而用较大内核放大的注释给出的结果更差。平均而言,DeepLabv3+的性能也比U-Net架构高出2− 无论注释类型如何,平均精度为3%。
5.3 和文中提出的方法的实验对比
本节中的实验设置都是根据前边实验过程中探索到的最佳模型性能的实验设置。
对于所有方法,包括使用原始图像大小(1408×512分辨率)、无输入图像旋转、使用商业软件的最小特征尺寸20像素,以及对所有剩余方法使用交叉熵损失函数。
对于注释类型,不同的方法在不同的注释中表现最好。商业软件和拟议的分割和决策网络方法在扩展=5注释上训练时都取得了最佳性能,而DeepLabv3+和U-Net在使用扩张=9注释进行训练时取得了最佳性能。
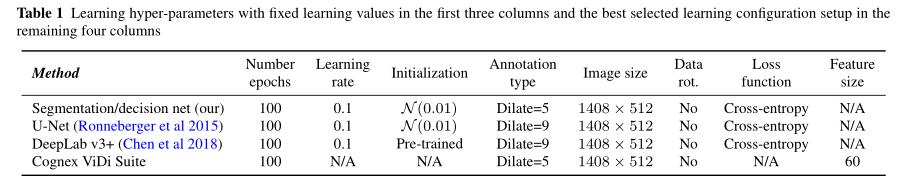
表1中显示了每个的选定配置设置。
实验结果
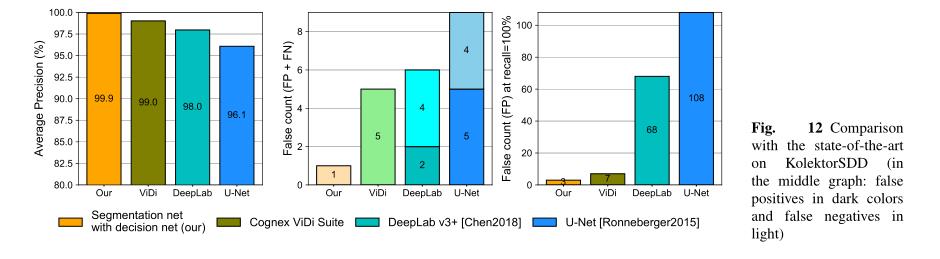
结果如图12所示。如最左侧栏所示,所提出的方法在所有指标上都优于所有最先进的方法。商业产品的表现第二好,而两种标准分割方法的表现最差,DeepLabv3+架构的表现略好于U-Net。在理想的Fmeasure下观察未命中分类的数量表明,所提出的分割和决策网络能够将未命中分类减少到只有一个假阴性,而所有其余方法都引入了5个或更多的未命中分类。
所有方法的几种未命中分类图像如图13和14所示。如图13所示,真阳性和假阴性检测揭示了第一列中拟议方法的单个缺失检测。该样本包含一个很难检测到的小缺陷,并且使用任何其他方法都无法检测到。对于其余示例,本文提出的方法能够正确预测缺陷的存在,包括最后一列中看到的一个小缺陷。该方法还能够以很高的精度定位缺陷。在相关方法中也可以观察到良好的定位;然而,对是否存在缺陷的预测较差。注意,在某些情况下,分数很大;然而,为了正确地将所有缺陷与非缺陷区分开来,阈值也需要设置得很高,指出在没有缺陷的图像上存在许多误报。
图14中展示了很多误报的图像。
除本文提出的方法和商业软件外,所有相关方法都可以观察到高分误报。特别是,U-Net返回的输出带有大量噪声,这阻止了真实缺陷与错误检测的清晰分离,即使使用额外的决策网络。另一方面,提出的方法没有任何假阳性问题,并且能够正确预测这些图像中是否存在缺陷。


工业环境中的结果
如图12中最右边的图所示,结果表明,本文提出的模型在所有399幅图像中仅引入了3个误报,漏检率为零。这占所有图像的0.75%。另一方面,相关方法取得的结果较差,商业产品需要手动验证7幅图像,而标准分割网络分别需要68和108次手动验证,用于DeepLabv3+和U-Net。注意,使用拟议的决策网络报告了两种标准分割的结果。使用logistic回归代替拟议的决策网络导致性能显著下降。
5.4 对训练样本数量的敏感性
在工业环境中,一个非常重要的因素也是所需的缺陷训练样本数,因此我们还评估了较小训练样本量的效果。使用与所有先前实验中使用的相同序列/测试分割的3倍交叉验证进行评估,因此在所有训练样本上训练时,有效地在每个折叠中使用33个阳性(缺陷)样本。然后减少阳性训练样本的数量,以有效地获得每个折叠的25、20、15、10和5个样本的训练大小N,而每个折叠的测试集保持不变。移除的训练样本是随机选择的,但所有方法都移除了相同的样本。遵循与之前所有实验相同的训练和测试程序。
将提出的分割和决策网络与商业软件Cognex ViDi Suite和两种最先进的分割网络进行了比较。所有方法都使用在前几节中介绍的实验中确定的性能最佳的训练设置进行评估,即使用Diplified=5注释(或Diplified=9用于分割网络)、全图像分辨率、交叉熵损失和无图像旋转。结果如图15所示。当仅使用25个有缺陷的训练样本时,所提出的分割和决策网络保留了99%以上的AP和单个未命中分类的相同结果。当使用更少的训练样本时,结果会下降,但当仅使用5个有缺陷的训练样本时,该方法仍达到约96%的AP。可以观察到Cognex ViDi套件的性能下降更为明显,然而,在这种情况下,结果在N=25时已经下降到97.4%的AP。当仅使用5个有缺陷的训练样本时,商业软件的AP略低于90%。在图15下半部分所示的错误分类数量中观察到了相同的趋势,深色表示误报,浅色表示误报。
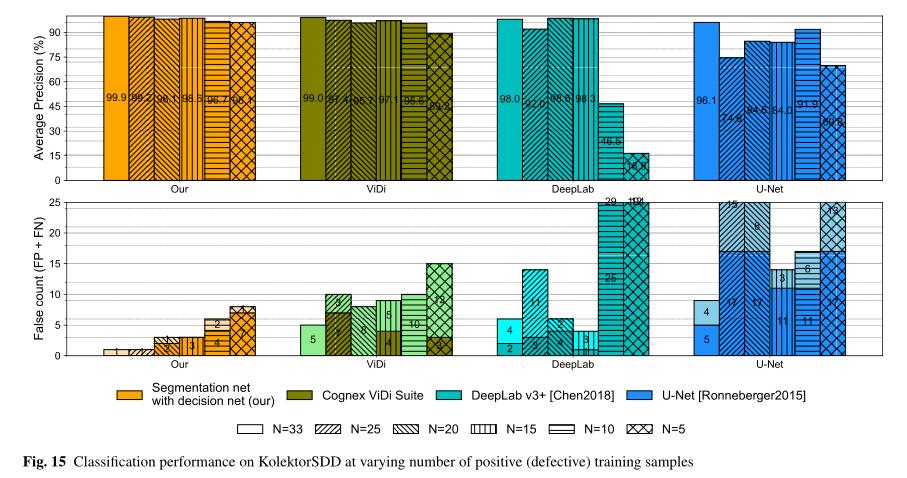
另一方面,当使用较少的训练样本时,DeepLab v3+和U-Net的性能比提出的方法差。U-Net的性能迅速下降,而DeepLab即使只有15个有缺陷的训练样本也保持了相当好的结果。注意,在20和15个缺陷训练样本下的性能略优于所有训练样本的结果,表明DeepLab对特定训练示例相当敏感,移除此类样本有助于提高性能。U-Net对训练样本数的减少更为敏感;结果的平均精度从75%到略高于90%不等。然而,对于10个和5个有缺陷的训练样本,DeepLab表现最差,AP分别为46%和16%。
总的来说,实验结果表明,当可用的训练样本数较少时,文中提出来的方法也保持了优越和稳定的性能。
5.5 计算成本
文中所提出的方法在正向传播过程中的平均精度如图16所示。

表2中展示了文中所提出方法和DeepLabV3+/UNet网络三个网络以及商业软件中使用模型参数的配置信息。

6.讨论与总结
本文从具体工业应用的角度出发,探索了一种利用分段网络进行表面缺陷检测的深度学习方法。提出了一种两阶段方法。第一阶段包括在缺陷的像素级标签上训练的分割网络,而第二阶段包括在分割网络上构建的附加决策网络,以预测整个图像中是否存在异常。对所提出的方法进行了广泛的评估,评估对象是半成品工业产品,即电换向器,其中表面缺陷表现为材料断裂。该问题域已作为基准数据集公开,称为Kolektor表面缺陷数据集(KolektorSDD)。在该领域,将该方法与几种最先进的方法进行了比较,包括专有软件和两种基于深度学习的标准分割方法。
文中提出的方法达到了最好的性能原因:这是因为文中提出的方法具有分割和决策网络的两阶段设计,以及改进的感受野大小和捕获缺陷精细细节的能力。
在使用低分辨率时,商业软件的精度明显低于文中提出的方法。即使在使用了和文中提出方法一致的分辨率,也无法达到文中提出方法的性能。
该方法是仅从33个缺陷样本的数据集中训练得到的,图17展示了文中提出的方法的正确分类示例。

作者又指出:仅使用包含25个缺陷样本的数据集进行训练,也可以达到良好的性能。
就实现100%检测率的性能而言,所提出的模型在所有399幅图像中仅需要三幅图像进行手动检查,从而使检查率达到0.75%。大而粗糙的注释也足以实现与具有更精细注释的注释类似的性能。在某些情况下,较大的注释甚至可以产生比使用精细的注释更好的性能。这个结论似乎违反直觉;然而,可以在用于分类每个像素的感受野大小中找到可能的解释。稍微远离缺陷区域的像素的感受野仍将覆盖部分缺陷区域,因此,如果对其进行正确注释,则有助于找到对其检测重要的特征。这一结论可以在使方法适应新领域时减少人工劳动,并将降低劳动力成本和提高生产线的灵活性。
作者指出了:提出的方法仅限于特定类型的检查,但是针对不同的应用场景,文中所提出的方法架构不需要进行更改就可以在其他领域进行训练和测试,该体系结构可以应用于包含多个复杂表面的图像,也可以应用于检测其他不同的缺陷,例如划痕、污迹或其他不规则现象,前提是有足够数量的缺陷训练样本可用,并且特定缺陷检测的任务可以作为表面分割问题。
文章最后说明了本文提出的方法在DAGM数据集上进行缺陷检测的结果也是比较好的,但是DAGM是人为地在结合真实世界图像之后生成的,因此,还需要在更多真实世界图像的数据集中训练文中提出的方法。
//本文仅作为日后复习之用,并无他用。
以上是关于Segmentation-Based Deep-Learning Approach for Surface-Defect Detection-论文阅读笔记的主要内容,如果未能解决你的问题,请参考以下文章