五深度学习优化算法
Posted Dragon Fly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了五深度学习优化算法相关的知识,希望对你有一定的参考价值。
文章目录
- 1、mini-batch梯度下降
- 2、指数加权平均-Exponential Weighted averages
- 3、 动量梯度下降- gradient with momentum
- 4、RMSprop
- 5、Adam optimization algorithm
- 6、Learning rate decay
- 7、Local optima in neural networks
- THE END
1、mini-batch梯度下降
\\qquad
mini-batch指的是将原本整个batch的数据集进行划分,e.g., 将整个数据集以1000条数据为标准划分成小的batch。

\\qquad
mini-batch梯度下降的流程如下所示:
 \\qquad
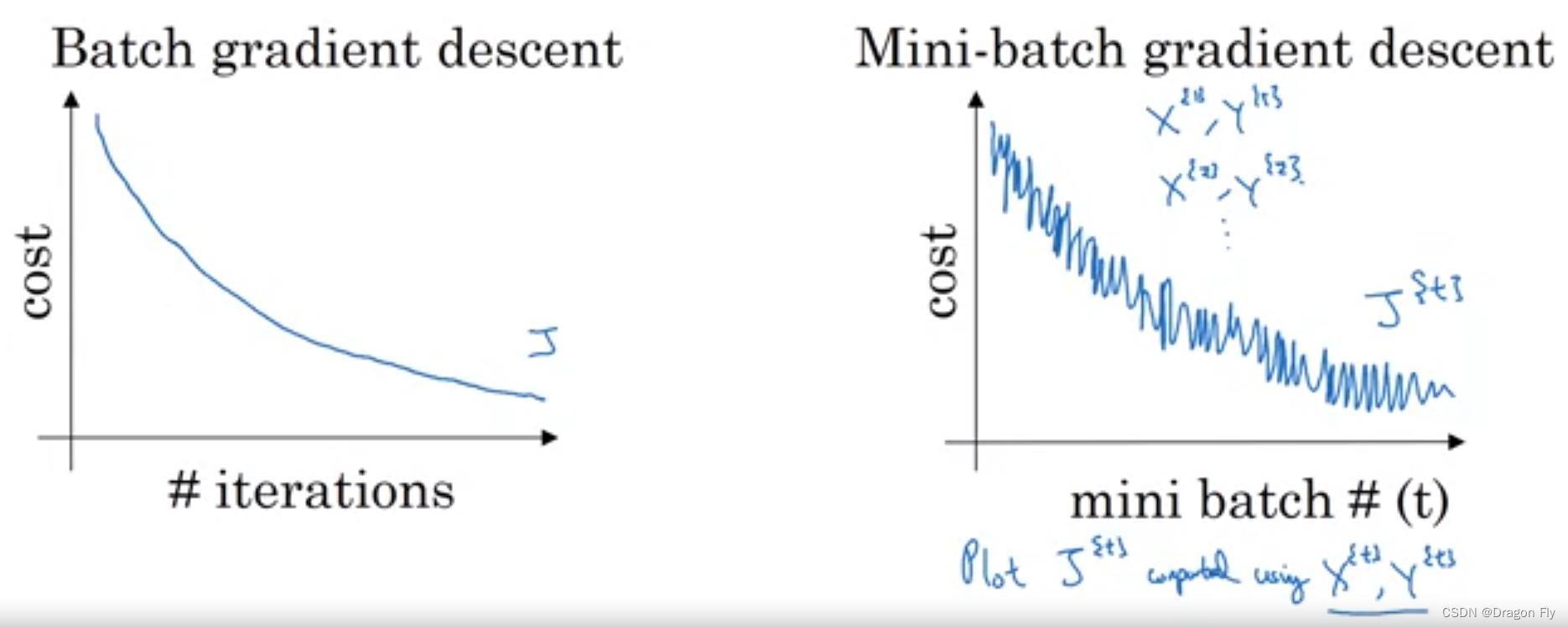
在进行mini-batch训练时,训练的成本可能不是随着训练次数增加而一直减小,而是呈现出波动下降的趋势,因为不同的mini-batch的数据之间的难易程度不一样。
\\qquad
在进行mini-batch训练时,训练的成本可能不是随着训练次数增加而一直减小,而是呈现出波动下降的趋势,因为不同的mini-batch的数据之间的难易程度不一样。
\\qquad
如下图所示,mini-batch size的选择不能过大也不能过小,若size过大会减慢训练的速度,若size过小会使得训练波动性变大,训练效果变差。
\\qquad
若训练集的数量比较小(
m
≤
1000
m \\leq 1000
m≤1000),可以不使用mini-batch训练,可以直接使用batch gradient descent进行训练。典型的mini-batch size包括64,128,256和512,一般不会使用1024以及更大的mini-batch进行模型训练。同时需要保证mini-batch size符合CPU/GPU的内存格式,否则会影响训练效果。
2、指数加权平均-Exponential Weighted averages
\\qquad
指数移动平均的计算式如下所示:
v
t
=
β
v
t
−
1
+
(
1
−
β
)
θ
t
v_t = \\beta v_t-1 + (1-\\beta) \\theta_t
vt=βvt−1+(1−β)θt
\\qquad
其中,
β
∈
[
0
,
1
]
\\beta \\in [0,1]
β∈[0,1]的值可以用来衡量移动平均的时间窗跨度,
β
\\beta
β的值越接近于1,移动平均的时间窗跨度越大,从而移动平均之后的数据相对于原始数据的来说越平滑;反之,移动平均值后的数据和原始数据的分布越接近。
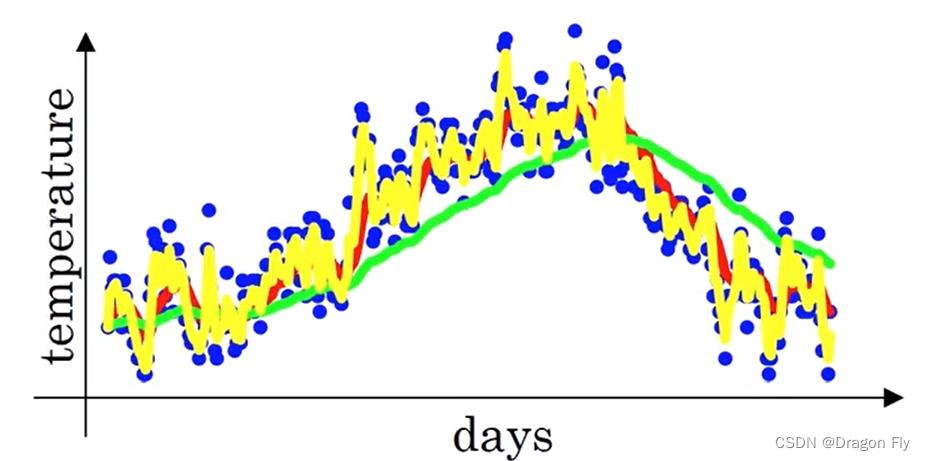
2.1 指数加权平均的偏差修正
\\qquad
在移动平均的前期,通常经过移动平均的数据相对原始数据的偏差较大,所有可以给指数移动平均添加一个修正项,修正之后的指数移动平均计算方法为:
v
t
=
β
v
t
−
1
+
(
1
−
β
)
θ
t
1
−
β
t
v_t = \\frac\\beta v_t-1 + (1-\\beta) \\theta_t1-\\beta^t
vt=1−βtβvt−1+(1−β)θt
3、 动量梯度下降- gradient with momentum
\\qquad
动量梯度下降的执行过程如下所示,相对于普通的梯度下降算法,动量梯度下降将学习率之后的项由
d
w
,
d
b
dw, db
dw,db替换成了
v
d
w
,
v
d
b
v_dw, v_db
vdw,vdb。

4、RMSprop
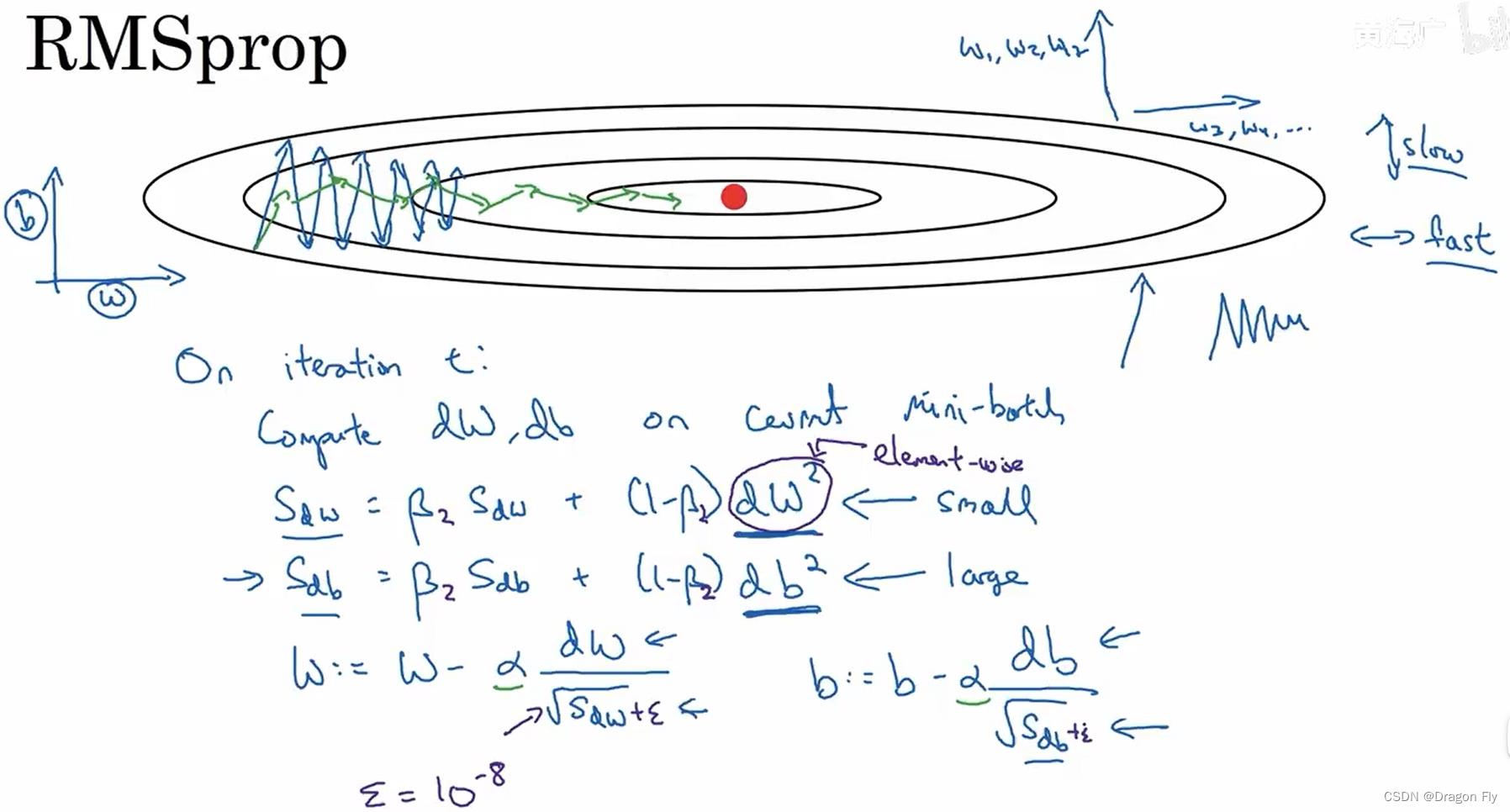
\\qquad
RMSProp的思想也是想要减小梯度下降过程中梯度在
b
b
b方向上的震荡幅度,同时不减小在
w
w
w方向上的收敛幅度,RMSProp的计算过程如下所示:
5、Adam optimization algorithm
\\qquad
将上述gradient descent with momentum 和 RMSProp相互结合,同时使用偏差修正之后,就得到了Adam optimization algorithm,其计算流程如下所示:

\\qquad
Adam 指的是Adaptive Moment Estimation,其中的hyper parameters取值:学习率
α
\\alpha
α需要通过parameter tunning 来选择调整;
β
1
\\beta_1
β1通常取值为0.9,
β
2
\\beta_2
β2通常取值为0.999,
ϵ
\\epsilon
ϵ通常取值为
1
0
−
8
10^-8
10−8。
6、Learning rate decay
\\qquad
使用learning rate decay的intuition是:当使用mini-batch进行训练时,当batch size选的比较小时,通常会造成学习不收敛,使得最终目标在最优值附近较大幅度地震荡,所以可以在训练初始阶段使用较大的学习率,使得训练速度加快;在之后使用比较小的学习率,使得震荡幅度减小。

7、Local optima in neural networks
\\qquad
由于神经网络在训练时通常会有很多维度的参数空间,所以通常神经网络不容易陷入一个很坏的局部最优解。
\\qquad
plateaus型函数会极大减慢训练的效率,所以可以使用Adam来提高运算效率。
THE END
以上是关于五深度学习优化算法的主要内容,如果未能解决你的问题,请参考以下文章