音频基础 2
Posted _Rye_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了音频基础 2相关的知识,希望对你有一定的参考价值。
02|如何量化分析语音信号?
语音的基本特征
语音按照发音原理可以分为清音和浊音,语音的音调、能量分布等信息可以用基频、谐波、共振峰等特征来分析。为了更好地分析语音,先来看看语音是如何产生的?
浊音和清音
可以结合下图的人体发音器官结构示意图来看一下语音是如何产生的。
声道就是声音传播所通过的地方。发音的声道主要是指三个腔体,即咽腔、口腔和鼻腔。而语音是由声源和声道共同作用产生的。按照声源的不同把语音分成以下两类:
第一类是声带振动作为声源产生的声音,把它们叫做浊音。比如拼音中的 “a,o,e” 等。
第二类是由气体在经过唇齿等狭小区域由于空气与腔体摩擦而产生的声音,把它们叫做清音。比如拼音中的 “shi、chi、xi” 等。那么清音和浊音的声源不同在频谱上有什么样的差异呢?先来看看语音的频谱图。
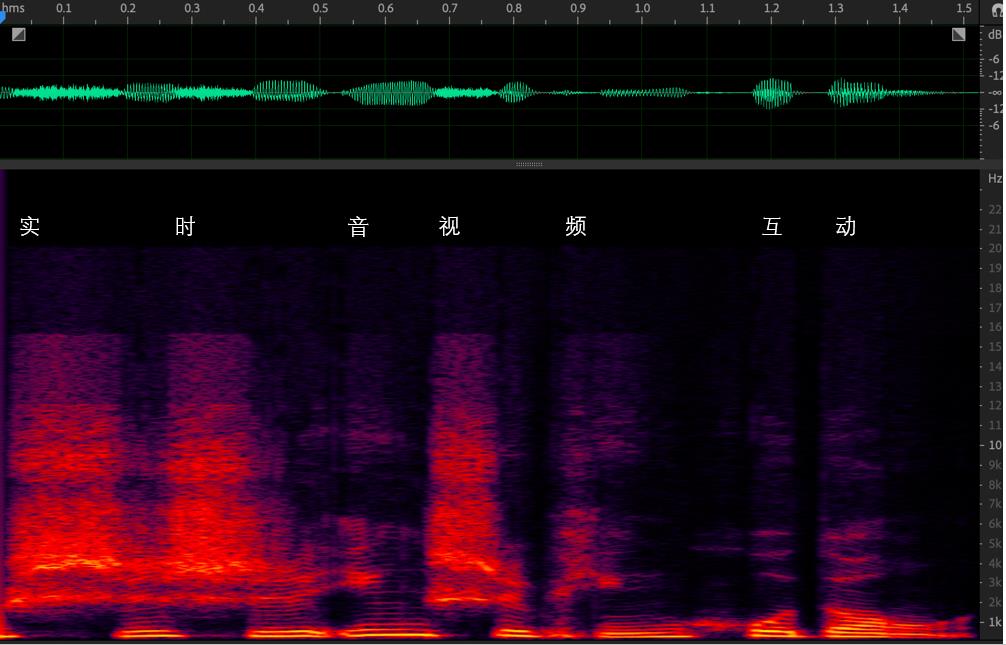
上图中显示的是“实时音视频互动”这几个字的音频信号的时域图和频域图(频谱图)。时域就是信号幅度和时间的关系,而频域指的是能量与时间和频率的关系。
频域更方便观察不同频率的能量分布。可以看到浊音,比如最后两个字“互动”是明显的有规律的能量分布,即低频能量大于高频且有明显的能量比较集中的地方,如频谱图中的亮线。而“实时”和“视”这几个字,都有 “sh” 这个由牙齿间高速气流产生的清音。清音在频谱上显示为比较均匀的分布。在 13kHz 的高频,清音也有不少的能量。
根据这个简单的分布规律已经可以从频谱上分辨清浊音了。接下来再来看看,还能从有明显能量分布的浊音的频谱中得到哪些信息。
基频
在发浊音的时候,声带会振动从而产生一个声波,把这个声波叫做基波,并且把基波的频率叫做基频(一般用 F0 来表示)。这个基频其实就可以对应到我们平时所说的音调。比如,唱歌音调比较高,其实就是声音基频比较高。一般来说,男生的正常说话基频在 100~200Hz 之间,而女生的则会高一些,在 140~240Hz 之间。这就是为什么女生的声音听起来比男生的尖锐一些。基频会随年龄变化而变化,比如小孩的基频比较高,可以达到 300Hz,而年龄越大则基频会越来越低。基频的能量对应的是浊音频谱中频率最低的亮线。
谐波
声带振动产生的基波,在传输过程中会在声道表面反复碰撞反射,从而产生许多频率倍数于基频的声波,通常把这些声波叫做谐波。按照谐波频率从低到高,依次叫 1 次谐波,2 次谐波等等。下图中可以看一下基频信号和谐波信号在时域上的样子。
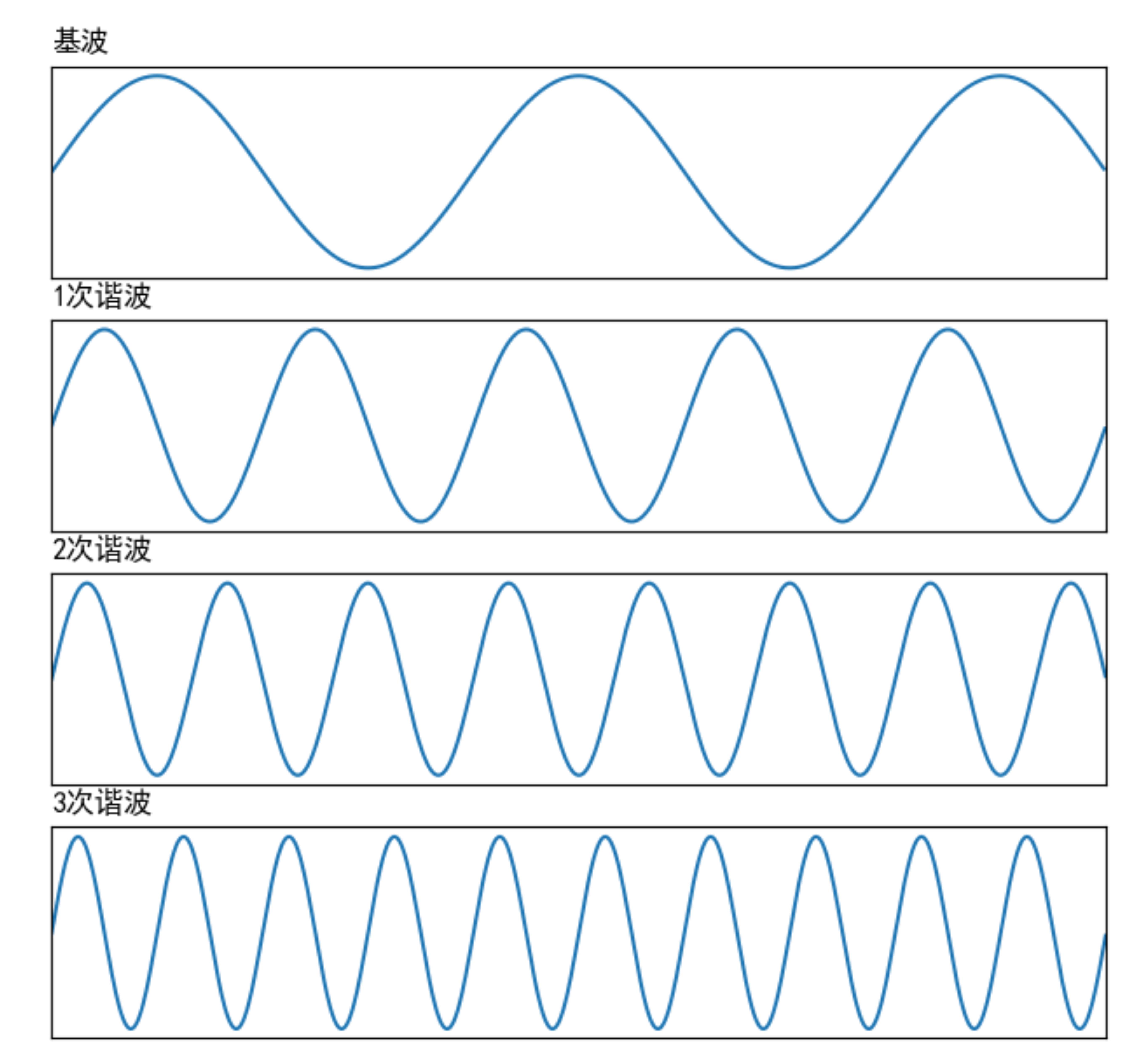
谐波频率和基频是浊音能量集中的地方,这也就是为什么我们能看见浊音的频谱是一个栅格的形状。
共振峰
一个 200Hz 基频的浊音,大部分的能量都分布在 200Hz 以及 200Hz 的整数倍的频率上。那么是什么决定了哪个谐波的能量高、哪个谐波的能量低呢?
由于高次谐波是由低次谐波在腔体表面碰撞反射得到的,并且碰撞反射会导致能量的衰减,但在看频谱图的时候发现谐波信号并不是从低到高依次衰减的。这是为什么呢?
这是因为在这个浊音的产生过程中,声源的振动信号通过声道时,声道本身也会发生共鸣,与声道共振频率相近的能量会被增强,远离声道共振频率的部分则会被衰减,从而谐波的能量就组成了一组高低起伏的形状包络,把这些包络中的巅峰位置叫做共振峰。比如下图中英文单词 father 中的 “a” 这个音可以看到明显的三个共振峰,频率分别为 750Hz、1100Hz、2600Hz。
频率从低到高分别用 F1、F2、F3 等来表示第一共振峰、第二共振峰、第三共振峰等。
从图中可以看到,发不同的音,比如 “a、i、u” 等,共振峰的位置和峰值都是不一样的。这是因为之前说的声道的三个腔体随发音的不同,开合、形状都会发生变化。从而形成了不同的腔体共振频率。所以,共振峰的位置和幅度就和发音可以一一对应起来了。这其实也是语音识别背后的原理之一,即通过共振峰的位置和能量分布来识别音频代表的语音。
语音信号的分析
现在对语音是怎么产生的已经能够理解了,那接下来分别从时域、频域这两个方面来介绍几个常用的语音分析的方法。因为窗函数常作为时域或频域实时分析的前处理步骤,所以在介绍这些语音分析方法之前,先介绍一下窗函数。
窗函数
分析音频时域或频域特征随时间的变化时,需要按照时间把音频截断成一个个小片段,每个小片段也就是我们说的音频帧。比如 10ms 的切片为 1 帧。
但如果直接截断信号则会导致频谱泄漏,即出现不该有的频谱分量。比如,对一个 50Hz 的单频信号直接截断,可能会出现 60Hz、200Hz 的能量分量。因此,一般采用加窗,即在原有信号中乘一个两端为 0 的窗信号,来减少截断信号时的频谱泄漏。常用的窗函数有 Haning(汉宁窗)、Hamming(汉明窗)、Blackman(布莱克曼窗)等。在时域上加窗(Haning)的过程如图所示:
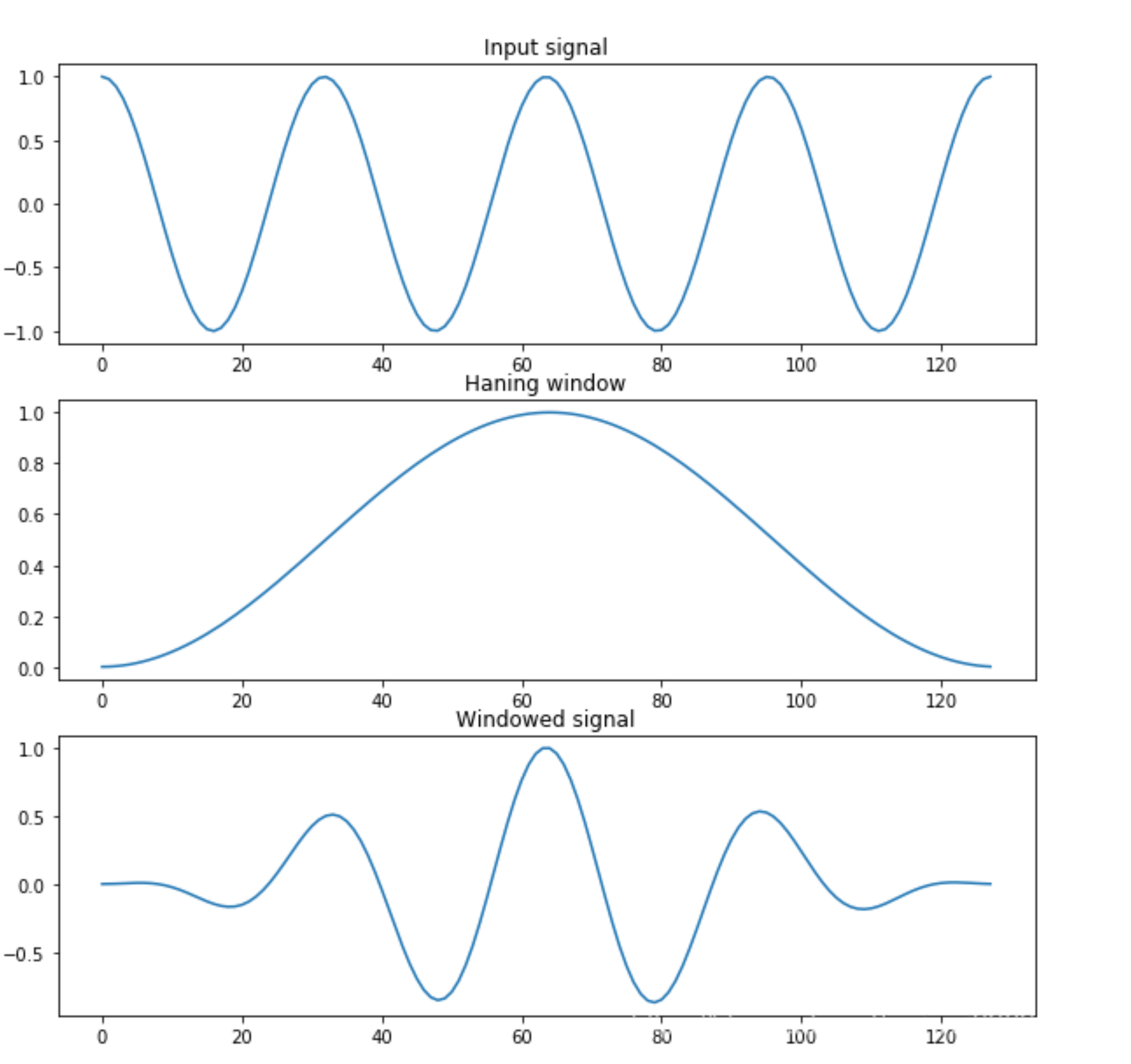
可以看到上图加窗的过程其实就是输入信号乘以窗函数,得到了一个两边小、中间高的新信号。
时域分析
了解了窗函数,现在来看看时域分析。在时域上主要介绍两个指标,短时能量和短时平均过零率。
短时能量
由于语音的能量随时间的变化较快,比如能量小的时候可能就是没有在说话,而能量大的地方可能是语音中重读的地方。因此,短时能量常被用来判断语音的起止位置或者韵律。短时能量分析的定义如公式所示:
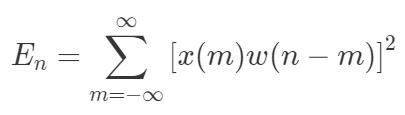
其中,x 代表采样点,w 代表窗函数。第 n 个点的短时能量 En 就是由加窗后的采样信号的平方和来表示的。由于不涉及频谱分析,因此这里的窗可以使用简单的矩形窗。短时能量主要有以下 3 个方面的应用:
1. 可以用来区分清浊音。一般来说,清音部分的能量比浊音部分的能量要小很多。
2. 可以用来区分有声段和无声段。比如,可以设置一个能量阈值作为判断该语音段是否为静音段的条件。
3. 能量的起伏在语音识别里也被用于判断韵律(比如重读音节)的特征。
短时平均过零率
短时平均过零率,顾名思义,就是每帧内信号通过零值的次数。连续的音频信号是围绕 0 值上下波动的,并且表现为音频信号正负号随时间不断切换。短时平均过零率可以通过下列公式来计算。
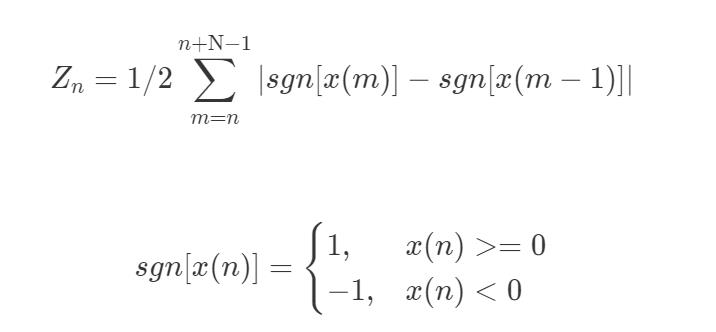
其中,N 为一帧中包含的信号点数,sgn 为符号函数,x 为音频采样点。
如果是正弦信号,例如基频和谐波信号,它们的短时平均过零率,就是信号的频率除以两倍的采样频率。
短时平均过零率在一定程度上可以表示语音信号的频率信息。由于清音的频率集中的范围要高于浊音,所以浊音的过零率要低于清音,从而可以初步用短时平均过零率来判断清浊音。
除了判断清浊音。还可以将短时能量和短时平均过零率结合起来判断语音起止点的位置。在背景噪声较小的情况下,短时能量比较准确;但当背景噪声比较大时,短时平均过零率有较好的效果。因此,一般的音频识别系统就是通过这两个参数相结合,来判断待检测语音是否真的开始。
频域分析
上面讲了基于时域的两种语音分析方法,接下来学习基于频域的两种语音分析方法:短时傅里叶变换和梅尔谱。
短时傅里叶变换
短时傅里叶变换(Short-time Fourier Transform)是音频频域分析最常用的方法之一,简称 STFT。那它有什么作用呢?在分析音频信号时经常会使用到频谱图,那你知道这个频谱图是怎么得到的吗?
结合短时傅里叶变换的步骤(如下图所示),也许你就明白了:
首先,对时域信号加滑动窗,在把音频切成若干个短帧的同时,防止频谱泄漏(窗可以使用汉宁窗)。
然后,对每一帧做快速傅里叶变换(Fast Fourier Transform,简称 FFT),把时域信号转换为复数频域信号。
上图 中的 Hop Length 代表滑动窗移动一次的距离,并且 Overlap Length 就是两个相邻滑动窗重叠的范围。
清楚了这些,就可以回答刚才的问题了。其实呢,是把短时傅里叶变换的结果对复数频域信号求模,并取对数转换成分贝(dB),然后用热力图的形式展示出来,这样就能得到频谱图。频谱图的横坐标为时间,纵坐标为频率,并且热力图中的颜色代表每个频点在当前时刻的能量大小。这样就可以通过频谱图来观察每个时刻的语音能量分布了。
梅尔谱(Mel spectrum)
上面通过短时傅里叶变换得到的频谱图通常也叫做声谱、线性谱或者语谱。
由于心理和听力系统的构造,其实人耳对以 Hz 为单位的频率并不是很敏感。比如,人类很难区分 500Hz 和 510Hz 的声音。我们平时能区分的音调都是以指数排列的。比如,我们说的高八度其实就是把原有频率乘以 2。因此,用对数的频率坐标来表示可以更好地反映人的实际听感。
除此之外,人耳对不同频率声音大小的感知也是不同的。如下图所示,红线代表人耳感知到的响度和实际声压的对应关系,人耳感知的响度一般用 phon(方)来表示。
由上图可以看到,人类在 4kHz 的频率对声音的响度比较敏感,而在两端的高频和低频则需要更强的声压,人类才能感知。这其实和人类的进化有关,4kHz 多为猛兽的叫声能量分布范围,所以人耳对这类危险的频率较为警觉。
因此,为了结合人耳对频率的感知。需要使用对数的频率坐标,且通过分配滤波器组对频谱图的能量按照听感重新分配,于是就有了梅尔谱等表示形式。
Mel 谱的计算步骤分为下面几步:
首先,对语音信号进行预加重(平衡高低频能量);
然后,语音信号通过 STFT 得到频率谱;
最后,通过三角滤波器组对频率谱逐帧进行滤波。
三角滤波器组如图 8 所示。可以看到三角滤波器组把频率划分成了若干个频段。敏感的频段滤波器分布比较密集,而不敏感的频段比较稀疏,这样就能更好地表征人耳的实际听感。
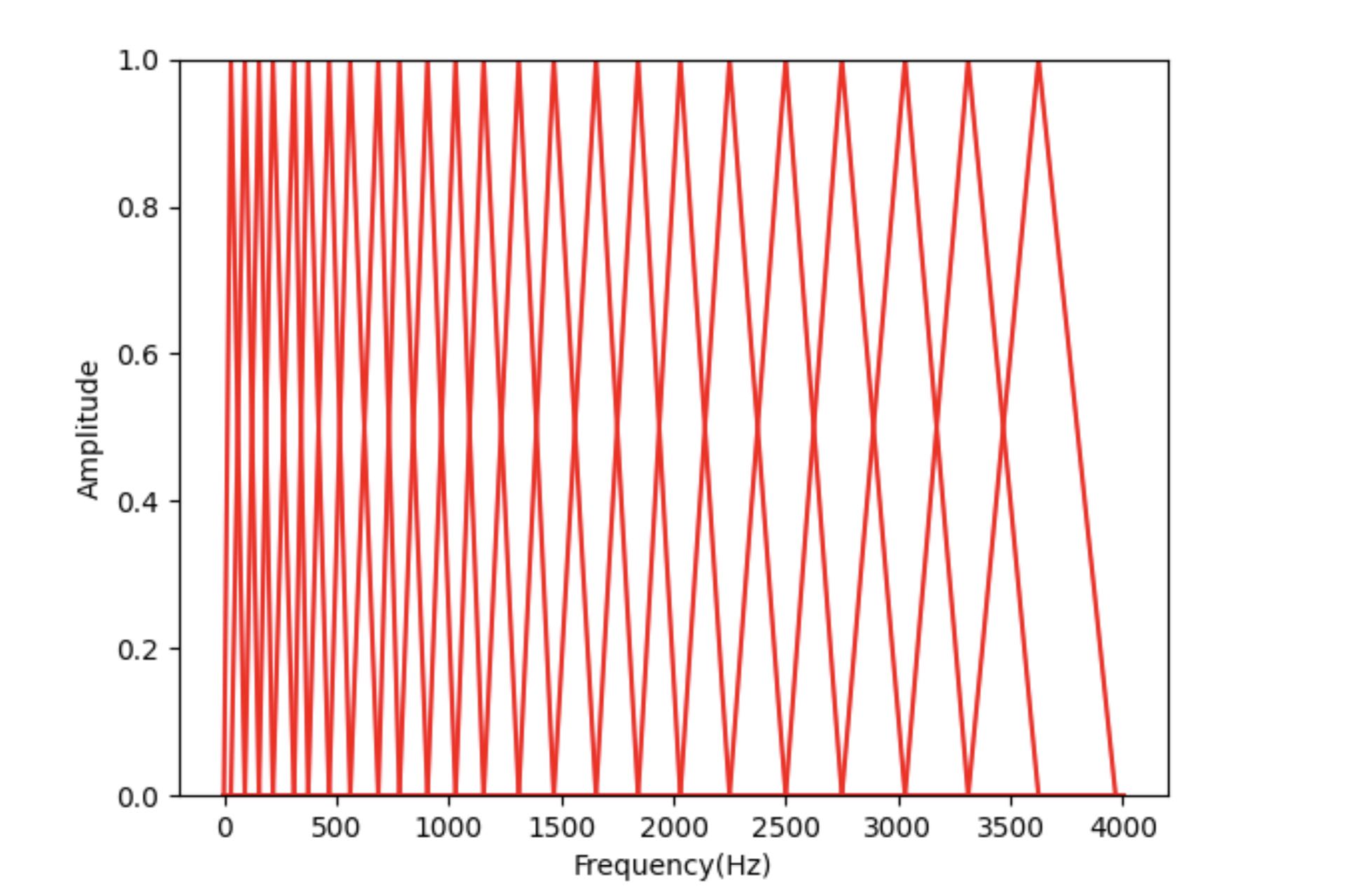
梅尔谱以及对梅尔谱再进一步求倒谱系数得到的 MFCC(梅尔倒谱系数),经常被用于语音识别、声音事件识别等领域。其实类似的基于人耳实际听感的表示还有Bark 谱、Gamma Tone Filter 等,这里就不一一赘述了。
小结
语音根据发音原理的不同可分为清音和浊音,并且根据它们在频谱图上的分布规律,可以从频谱上分辨清浊音。
只有浊音才有基频和谐波。将发浊音时声带振动产生的声音叫基波,并且将基波的频率叫做基频。基频对应我们平时所说的音调,而谐波是频率倍数于基频的声波。
共振峰表示发音受腔体形状影响。共振峰的位置和幅度可以和发音一一对应,从而可以通过共振峰的位置和能量分布来识别音频代表的语音。
在做音频分析的时候需要对音频信号进行截断,而这会导致频谱泄漏。加窗可防止频谱泄漏。
短时能量和短时平均过零率是时域分析的常见指标。它们可用于判断清、浊音以及语音的起止位置。
频域分析常使用短时傅里叶变换和梅尔谱等方法,并且梅尔谱更能反映人耳的实际听感。
Android音频开发:音频基础知识
一、Android音频开发(一):音频基础知识
二、Android音频开发(二):录制音频(WAV及MP3格式)
三、Android音频开发(三):使用ExoPlayer播放音频
四、Android音频开发(四):音频播放模式
五、Android音频开发(五):感应(息屏/亮屏)管理
附GitHub源码:MultimediaExplore
1、采样频率:
一秒钟内采样的点(次)数称为采样频率,采样频率越高越接近原始信号。常用的音频采样频率有:8kHz、16kHz、44.1kHz、96kHz、192kHz等。
2、采样位宽【采样精度 / 位深度】:
采样位数就是采样值用多少位0和1来表示,也叫采样精度,用的位数越多就越接近真实声音。 常见的位宽有:8bit 或者16bit。
3、声道:
语音一般只有一个声道,音乐有两个声道,环绕立体声可以有多个声道。
4、编解码:
音频采样过程也叫做脉冲编码调制编码,即PCM(Pulse Code Modulation)编码。
编码过程:模拟信号->抽样->量化->编码->数字信号.
5、压缩:
<1>无损编码:如能够达到最高保真水平的就是PCM编码、WAV格式。
<2>有损编码:如MP3格式.
MP3格式是按1:12压缩保存的,所以MP3格式大小等于WAV的1/12。
6、码率:
又称为比特率,是指一个音频流中每秒钟能通过的数据量。
码率 = 采样频率(44.1k)* 采样位数(16)* 声道个数(2)= 1411.2kbps。
知道音频码率后,可求得整个音频文件的大小=时长(300s)*码率(1411.2)/1024/8=51.67M。
7、常用音频格式:
<1>WAV格式:音质高 无损格式 体积较大。
<2>AAC格式:相对于 mp3,AAC 格式的音质更佳,文件更小,有损压缩。
<3>AMR格式:压缩比比较大,但相对其他的压缩格式质量比较差,多用于人声,通话录音。
<4>mp3格式:特点 使用广泛,有损压缩,牺牲了12KHz到16KHz高音频的音质。
以上是关于音频基础 2的主要内容,如果未能解决你的问题,请参考以下文章