SysOM 案例解析:消失的内存都去哪了 !
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SysOM 案例解析:消失的内存都去哪了 !相关的知识,希望对你有一定的参考价值。

在《AK47 所向披靡,内存泄漏一网打尽》一文中,我们分享了slab 内存泄漏的排查方式和工具,这次我们分享一种更加隐秘且更难排查的"内存泄漏"案例。
一、 问题现象
客户收到系统告警,K8S 集群某些节点 used 内存持续升高,top 查看进程使用的内存并不多,剩余内存不足却找不到内存的使用者,内存神秘消失,需要排查内存去哪儿了。

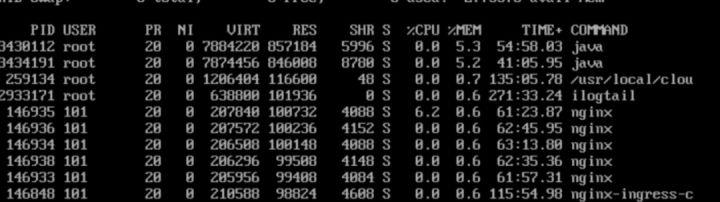
执行 top 指令并按内存排序输出,内存使用最多的进程才 800M 左右,加起来远达不到 used 9G 的使用量。
二、问题分析
2.1 内存去哪儿了?
在分析具体问题前,我们先把系统内存分类,便于找到内存使用异常的地方,从内存使用性质上,可以简单把内存分为应用内存和内核内存,两种内存使用量加上空闲内存,应该接近于 memory total,这样区分能够快速定位问题的边界。
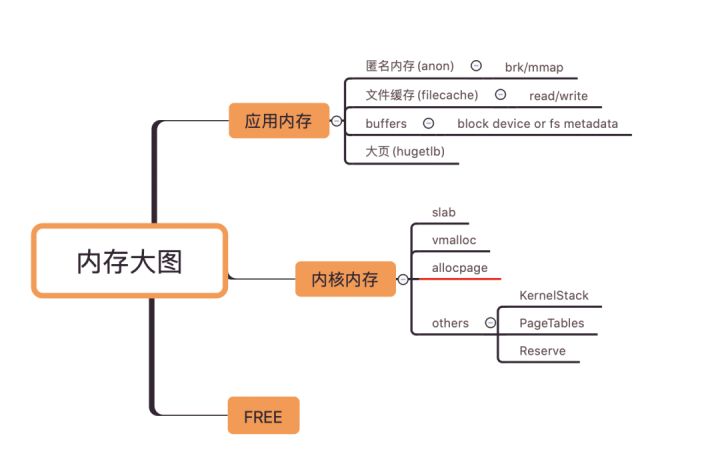
其中 allocpage 指通过 __get_free_pages/alloc_pages 等 API 接口直接从伙伴系统申请的内存量(不包含 slab 和 vmalloc)。
2.1.1 内存分析
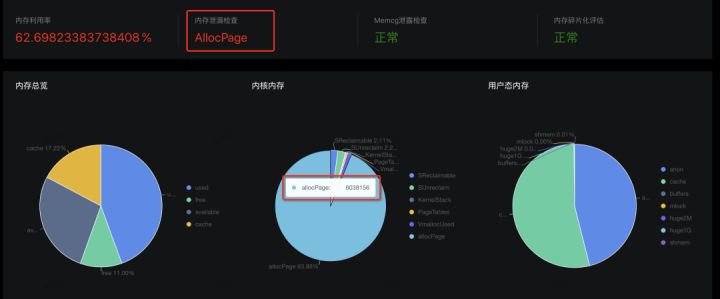
根据内存大图分别计算应用内存和内核内存,就可以知道是哪部分存在异常,但这些指标计算比较繁琐,很多内存值还存在重叠。针对这个痛点,SysOM 运维平台的内存大盘功能以可视化的方式展示内存的使用情况,并直接给出内存是否存在泄漏,本案例中,使用 SysOM 检测,直接显示 allocpage 存在泄漏,使用量接近 6G。
2.1.2 allocpage 内存
那既然是 alloc page 类型的内存占用多,是否可以直接从 sysfs、procfs 文件节点查看其内存使用了?很遗憾,这部分内存是内核/驱动直接调用 __get_free_page/alloc_pages 等函数从伙伴系统申请单个或多个连续的页面,系统层面没有接口查询这部分内存使用详情。如果这类内存存在泄漏,就会出现"内存凭空消失"的现象,比较难发现,问题原因也难排查。针对这个难点,我们的SysOM 系统运维能够覆盖这类内存统计和原因诊断。
所以需要进一步通过 SysOM 的诊断利器 SysAK 动态抓取这类内存的使用情况。
2.2 allocPage 类型内存排查
2.2.1 动态诊断
对于内核内存泄漏,我们直接可以使用 SysAK 工具来动态追踪,启动命令并等待 10 分钟。
sysak memleak -t page -i 600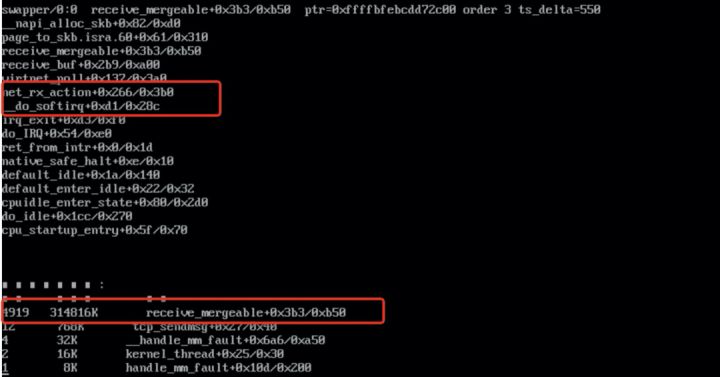
诊断结果显示 10 分钟内 receive_mergeable 函数分配的内存有 4919 次没有释放,内存大小在 300M 左右,分析到这里,我们就需要结合代码来确认 receive_mergeable 函数的内存分配和释放逻辑是否正确。
2.2.2 分配和释放总结
1)page_to_skb 每次会分配一个线性数据区为 128 Byte 的 skb。
2)数据区调用 alloc_pages_node 函数,一次性从伙伴系统申请 32k 内存(order=3)。
3)每个 skb 会对 32k 的 head page 产生一次引用计数,也就是只有当所有 skb 都释放时,这 32k 内存才释放回伙伴系统。
4)receive_mergeable 函数负责申请内存,但不负责释放这部分内存,只有当应用从 socket recvQ 中把数据读走才会对 head page 引用计数减一,当 page refs 为 0 时,释放回伙伴系统。
当应用消费数据比较慢,可能会导致 receive_mergeable 函数申请的内存释放不及时,而且最坏情况一个 skb 会占用 32k 内存,使用 sysak skcheck 检查 socket 接收队列和发送队列残留情况。

从输出可以知道,系统中只有 nginx 进程的接收队列有残留数据,socket fd=11 的 Recv-Q 有接近 3M 的数据没有接收,通过直接 kill 146935,系统内存恢复正常了,所以问题根本原因就是 nginx 没有及时收走数据了。
三、问题结论
经过与业务方沟通,最终确认是业务配置问题,导致 nginx 有一个线程没有处理数据,从而导致网卡驱动申请的内存没有及时释放,而 allocpage 内存又是无法统计的,从而出现内存凭空消失的现象。
3.1 结论验证
接收队列真的有数据残留吗,这里结合 crash 工具的 files 指令通过 fd 找到对应的sock:
socket = file->private_data sock = socket->sk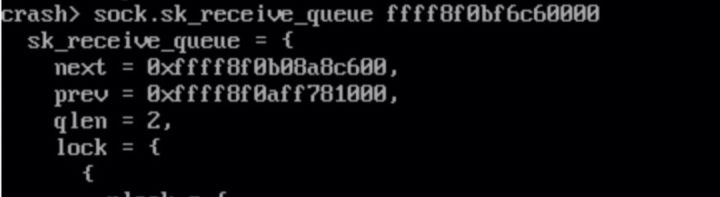
通过多次观察,发现 sk_receive_queue 上的 skb 长时间没有变化,这也证明了 nginx 没有及时处理接收队列上的 skb,导致在网卡驱动中分配的内存没有释放。
四、内存泄漏疑点
在排查过程还遇到一个非常较困惑的地方,sockstat 和 slabtop 看检查 tcp mem 和 skbuff_head_cache 使用都很正常,导致进一步掩盖了网络占用的内存。
tcp mem = 32204*4K=125M
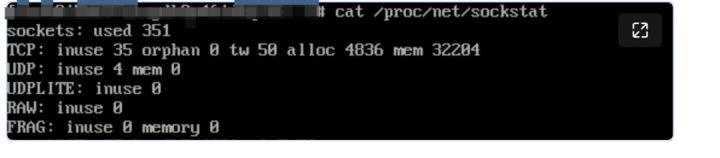
skb 数量在 1.5万~3 万之间。
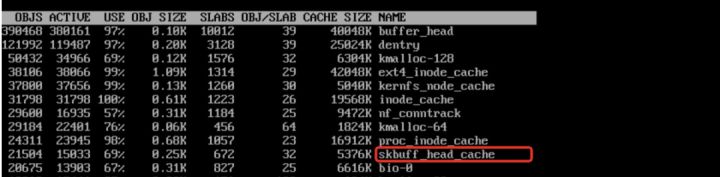
按照前面分析,一个skb最坏情况占用 32k 内存,那么 2 万个 skb 最大也就占 600M 左右,怎么会占用几个 G 了,难道分析有问题?如下图所示,skb 的非线性区可能还存在若干个 frag page,而每个 frag page 又可能由 compund page 组成。
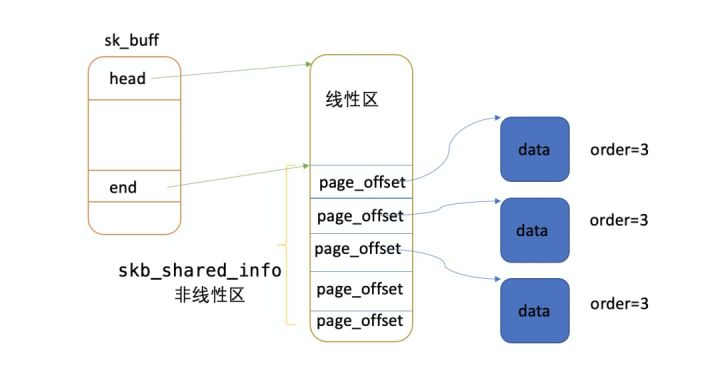
用 crash 实际读取 skb 内存发现,有些 skb 存在 17 个 frag page,并且数据大小只有 10 Byte。
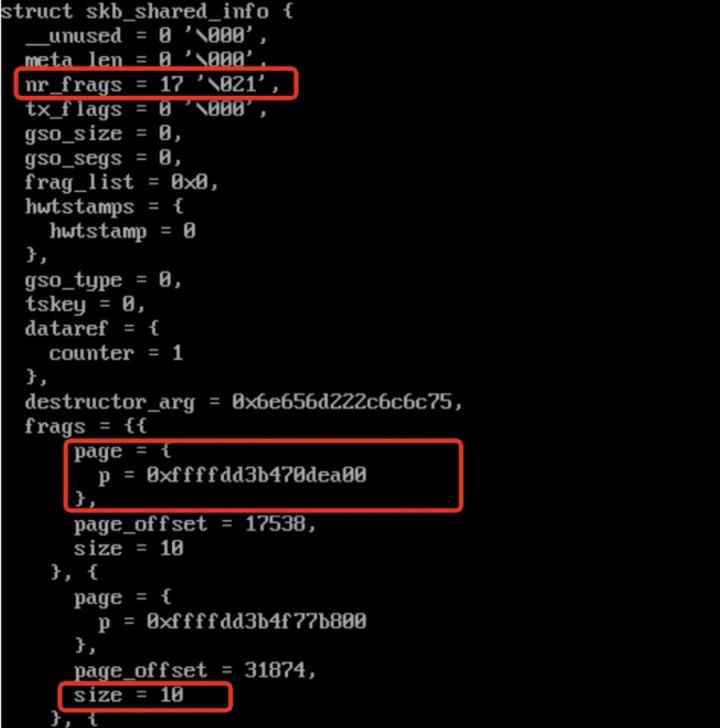
解析 frag page 的 order 为 3,意味着一个 frag page 占用 32k 内存。

极端情况下,一个 skb 可能占用(1+17)*8=144 页,上图 slabinfo 中skbuff_head_cache 活跃 object 数量为 15033 个,所以理论最大总内存 =144*15033*4K = 8.2G,而我们现在遇到的场景消耗 6G 的内存是完全有可能的。
本文为阿里云原创内容,未经允许不得转载。
以上是关于SysOM 案例解析:消失的内存都去哪了 !的主要内容,如果未能解决你的问题,请参考以下文章