ViT 微调时关于position embedding如何插值(interpolate)的详解
Posted SinHao22
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ViT 微调时关于position embedding如何插值(interpolate)的详解相关的知识,希望对你有一定的参考价值。
目录
本文适合对Vision Transformer有一定了解(知道内部结构和一些实现细节,最好是精读过ViT这篇论文)的读者阅读,这篇博客不会详细说明ViT的结构和前向推断过程。
1. 问题描述
| 符号 | 含义 |
|---|---|
| b b b | batch size |
| N N N | patch size |
| H H H W W W | 低分辨率图像的高和宽 |
| H ′ H' H′ W ′ W' W′ | 高分辨率图像的高和宽 |
| s o s_o so | 低分辨率图像的sequence length的长度( o o o是original的意思) |
| s n s_n sn | 高分辨率图像的sequence length的长度( n n n是new的意思) |
| h h h | hidden dimension,即每个patch经过linear layer后得到的vector的长度,原文是16x16x3=768 |
最近在读ViT相关的论文(ViT、DeiT、Swin Transformer),感觉看得比较细致,但ViT中有个细节我一直不太理解:就是在用高分辨率(high resolution)图像做微调时,作者在论文里说:保持patch size不变,直接把position embedding向量进行插值处理(interpolate),原文如下:

作者的意思是:当使用高分辨率(high resolution)图像对预训练好的ViT进行微调(fine-tuning)时,保持patch size( N ∗ N N*N N∗N)不变(即每个patch中的像素数量不变),但由于image size( H ′ ∗ W ′ H'*W' H′∗W′,且 H ′ = W ′ H'=W' H′=W′)变大了,则sequence length s n = H ′ / N s_n=H'/N sn=H′/N 也相应变大了。而预训练好的position embedding是对原先低分辨率(low resolution)图像的位置编码(即原来的sequence length s o = H / N s_o=H/N so=H/N),自然无法适应现在的新的sequence length s n s_n sn。作者对此提出的解决方案是对原先的postion embedding进行2D的插值处理。
这我就很困惑了:position embedding是个1-D的向量,怎么做2D的插值呢?查了好久也没找到满意的解释,最后还是去看了torchvision中ViT的实现才明白怎么回事儿,其实很简单。
2. positional embedding如何interpolate
我们用图来表示想做的事情:

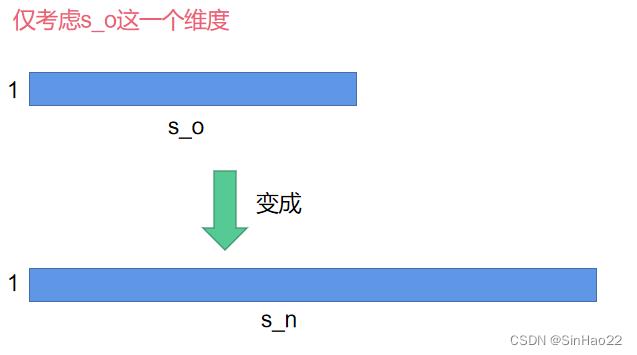
如何把 s o s_o so变成 s n s_n sn呢?具体做法如下:
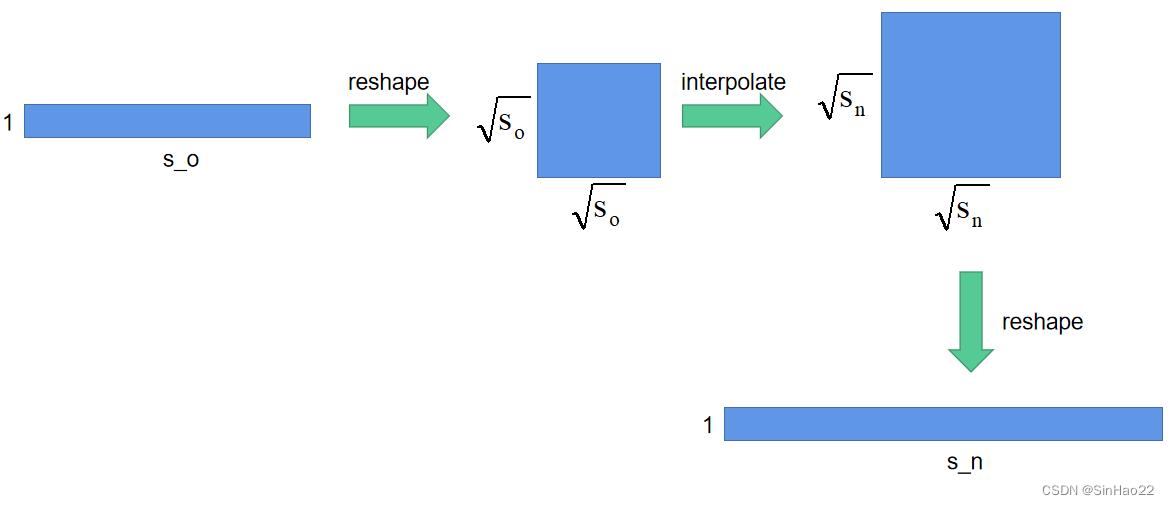
假设position_embedding_img的shape为 ( b , h , s o ) (b, h, s_o) (b,h,so),其中 b b b为batch size,设置 b = 1 b=1 b=1。 h h h和 s o s_o so的含义见上面的表格。
- 首先将position_embedding_img的shape由 ( b , h , s o ) (b, h, s_o) (b,h,so)reshape成( b b b, h h h, s o \\sqrts_o so, s o \\sqrts_o so)
- 然后将后两维 ( s o (\\sqrts_o (so, s o ) \\sqrts_o) so) 使用torch.nn.functinoal.interpolate,插值成: ( s n (\\sqrts_n (sn, s n ) \\sqrts_n) sn),此时position_embedding_img_new的shape为:( b b b, h h h, s n \\sqrts_n sn, s n \\sqrts_n sn)
- 最后再把position_embedding_img_new reshape成( b b b, h h h, s n s_n sn)
经过上述步骤,我们就将position_embedding_img的 ( b , h , s o ) (b, h, s_o) (b,h,so)变成了position_embedding_img_new的 ( b , h , s n ) (b, h, s_n) (b,h,sn)。示意图如下(这里设 b = 1 , h = 1 b=1,h=1 b=1,h=1):
3. 输入的sequence length改变了ViT还能正常前向推断?
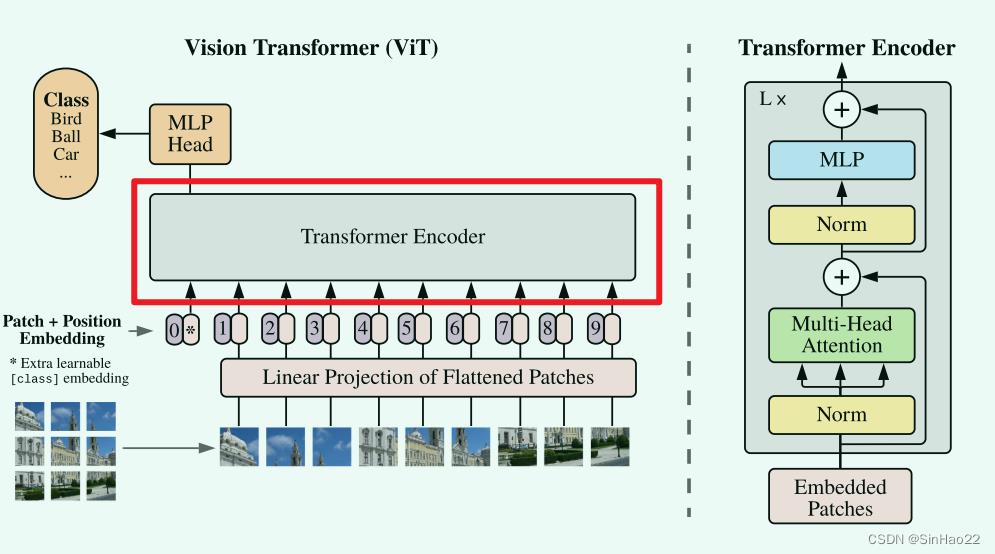
其实到了第二步就已经结束了,但可能有些人(包括我之前)还会有个疑问:之前我们预训练时输入给Transformer Encoder(即上图中红色圈出的部分)的tensor的shape为: ( b , s o , h ) (b, s_o, h) (b,so,h),而如果使用高分辨率的img进行微调,那输入到Transformer Encoder的shape变成了: ( b , s n , h ) (b, s_n, h) (b,sn,h),还可以前向推断吗?Transformer Encoder不需要改内部结构吗?
答案是不需要。原因在于微调时hidden dimension h h h的值没有变,为什么这么说呢?我们考虑下Transformer Encoder的内部结构,主要是多头自注意力(multi-head self-attention)和MLP。multi-head self-attention其实就是把输入切分成n个头,分别进行self-attention,然后再把结果concat起来,所以我们以单头自注意力、batch size=1为例,self-attention的大致流程为:

可以看出,Transformer Encoder中训练的参数:
W
q
、
W
k
、
W
v
W_q、W_k、W_v
Wq、Wk、Wv的形状都为
(
h
,
h
)
(h, h)
(h,h),并不会随着sequence length由
s
o
s_o
so变为
s
n
s_n
sn而发生改变。
同理,Transformer Encoder中的MLP的input layer的神经元个数也是 h h h,和 s n s_n sn无关。
即Transformer Encoder中参数只和hidden embedding的长度 h h h有关,和sequence length s o 、 s n s_o、s_n so、sn无关。
因此,即使我们输入Transformer Encoder的维度由
(
b
,
s
o
,
h
)
(b, s_o, h)
(b,s< 以上是关于ViT 微调时关于position embedding如何插值(interpolate)的详解的主要内容,如果未能解决你的问题,请参考以下文章