Service Mesh 浅析:从概念、产品到实践
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Service Mesh 浅析:从概念、产品到实践相关的知识,希望对你有一定的参考价值。
参考技术A 近几年,微服务架构逐渐发展成熟,从最初的星星之火到现在大规模的落地和实践,几乎已经成为分布式环境下的首选架构。然而软件开发没有银弹,基于微服务构建的应用系统在享受其优势的同时,痛点也越加明显。Service Mesh 技术也因此而生,受到越来越多的开发者关注,并拥有了大批拥趸。本文会从概念介绍开始,让大家理解 Service Mesh 技术出现的原因以及愿景;接着会对目前最主流的两个产品 Istio 和 AWS App Mesh 进行详细的比较;最后简要介绍一下我们目前在该领域的一些探索与实践。Service Mesh - 服务通信的济世良方
Service Mesh 是什么?
Service Mesh(中文译做服务网格)这一概念由 Buoyant 公司的 CEO,William Morg」n 首先提出。2017 年 4 月该公司发布了第一个 Service Mesh 产品 Linkerd,这篇同一时间发表的文章 What’s a service mesh? And why do I need one? 也被业界公认是 Service Mesh 的权威定义。
“A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.”
其定义翻译为:Service Mesh 是一个处理服务通讯的专门的基础设施层。它的职责是在由云原生应用组成服务的复杂拓扑结构下进行可靠的请求传送。在实践中,它是一组和应用服务部署在一起的轻量级的网络代理,对应用服务透明。这段话有点晦涩难懂,但只要抓住下面 4 个关键点就能轻松理解:
本质:基础设施层
功能:请求分发
部署形式:网络代理
特点:透明
如果用一句话来总结,我个人对它的定义是:Service Mesh 是一组用来处理服务间通讯的网络代理。
为什么需要 Service Mesh?
上面晦涩抽象的定义很难让你真正理解 Service Mesh 存在的意义。你可能会想,服务间通信(service-to-service communication)无非就是通过 RPC、HTTP 这些方式进行,有什么可处理的?没错,服务间只需要遵循这些标准协议进行交互就可以了,但是在微服务这样的分布式环境下,分散的服务势必带来交互的复杂性,而规模越大的系统其通信越加错综复杂。 分布式计算下的 8 个谬论 很好的归纳了分布式环境下存在的网络问题。而为了解决这些问题,提高系统的容错能力和可用性,出现了服务注册与发现、负载均衡、熔断、降级、限流等等和通信相关的功能,而这些才是 Service Mesh 要真正处理的问题。
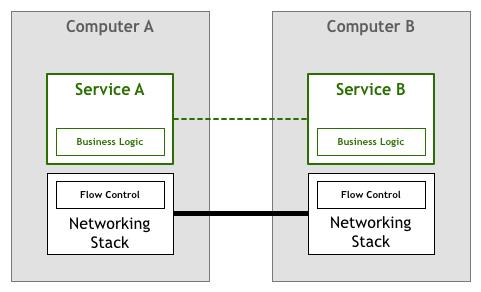
Pattern:Service Mesh 这篇文章详细的讲述了微服务架构下通讯处理的演进,由此引出 Service Mesh 出现的意义和核心价值。下图为服务通信演变的过程:
最初,流量管理和控制能力(比如图例中的熔断、服务发现)是和业务逻辑耦合在一起,即便以引用包的方式被调用,依然解决不了异构系统无法重用的问题。
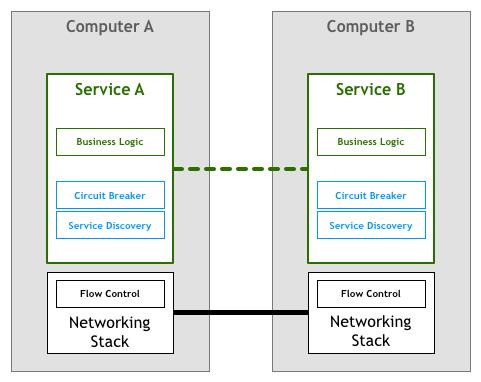
流控功能和业务耦合相当不美好,于是出现了提供这些功能的公共库和框架。但这些库通常比较复杂,无论是学习使用,与业务系统整合、维护都会带来很大的成本。
为避免花费太多时间开发和维护这些通用库,人们希望流量控制能力可以下沉到网络通讯栈的层面,但几乎无法实现。
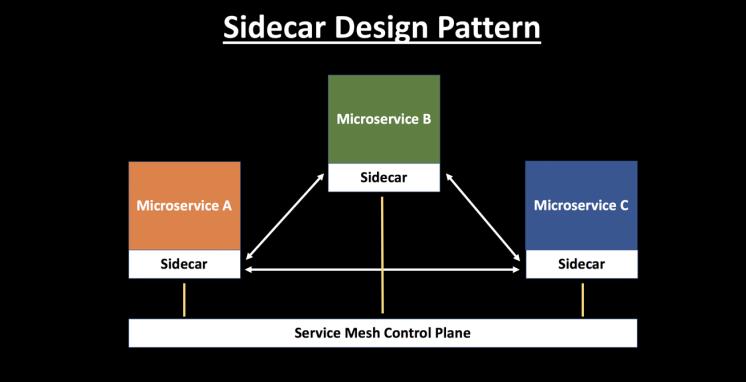
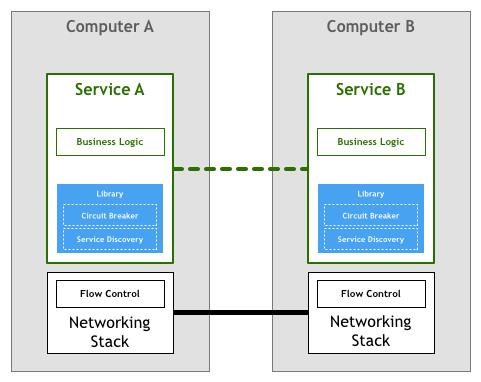
于是另一种思路出现,就是将这些功能独立成一个代理,由它先接管业务服务的流量,处理完成后再转发给业务服务本身,这就是 Sidecar 模式。
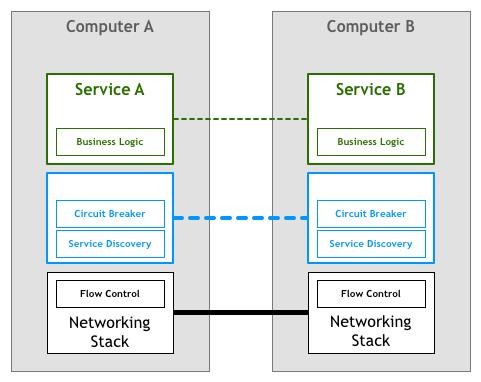
为统一管理 Sidecar,该模式进一步进化,形成网络拓扑,增加了控制平面,演变成 Service Mesh(最后的网格图中,绿色代表业务服务,蓝色代表 sidecar 服务)。
可以说,Service Mesh 就是 Sidecar 的网络拓扑形态,Mesh 这个词也由此而来。(关于 Sidecar 模式这里不做讨论,你可以自行 Google)。
业务系统的核心价值应该是业务本身,而不是服务,微服务只是一种实现手段,实现业务才是目标。现有的微服务架构下,为解决可能出现的网络通信问题,提升系统的弹性,开发人员不得不花费大量时间和精力去实现流量控制相关的非业务需求,不能聚焦在业务本身。而 Service Mesh 的出现解决了这一问题,带来了下面 2 个变革:
解决了微服务框架中的服务流量管理的痛点,使开发人员专注于业务本身;
将服务通信及相关管控功能从业务程序中分离并下层到基础设施层,使其和业务系统完全解耦。
在云原生应用中,面对数百个服务或数千个实例,单个业务链路的请求经由服务的拓扑路径可能会非常复杂,单独处理非常必要。这就是 Service Mesh 的意义所在。
Service Mesh 的主要功能
那么 Service Mesh 到底能带来哪些实用的功能呢?可以把它们归纳为下面 4 个部分:
流量控制:流控是最主要也是最重要的功能,通过 Service Mesh,我们可以为应用提供智能路由(蓝绿部署、金丝雀发布、A/B test)、超时重试、熔断、故障注入、流量镜像等各种控制能力;
-安全:在安全层面上,授权和身份认证也可以托管给 Service Mesh;
策略:可以为流量设置配额、黑白名单等策略;
可观察性:服务的可观察性一般是通过指标数据、日志、追踪三个方式展现的,目前的 Service Mesh 产品可以很容易和和主流的后端设施整合,提供给应用系统完整的监控能力。
通过上面的讲述,我相信 Service Mesh 的概念大家都已经有所了解。接下来我们来介绍两个重要的网格产品,让大家进一步了解 Service Mesh 的产品形态是什么样的。
Istio vs AWS App Mesh - 开源与闭环之争
目前市面上比较成熟的开源服务网格主要有下面几个:Linkerd,这是第一个出现在公众视野的服务网格产品,由 Twitter 的 finagle 库衍生而来,目前由 Buoyant 公司负责开发和维护;Envoy,Lyft 开发并且是第一个从 CNCF 孵化的服务网格产品,定位于通用的数据平面或者单独作为 Sidecar 代理使用;Istio,由 Google、IBM、Lyft 联合开发的所谓第二代服务网格产品,控制平面的加入使得服务网格产品的形态更加完整。
从今年的风向看,作为构建云原生应用的重要一环,Service Mesh 已经被各大云厂商认可,并看好它的发展前景。在 Istio 红透半边天的情况下,作为和 Google 在云服务市场竞争的 Amazon 来说,自然不愿错失这块巨大的蛋糕。他们在今年 4 月份发布了自己的服务网格产品:AWS App Mesh。这一部分内容我们会聚焦于 Istio 和 App Mesh 这两个产品,通过横向的对比分析让大家对 Service Mesh 的产品形态和两大云厂商的策略有一个更深入的认识。
产品定位
从官方的介绍来看,Istio 和 App Mesh 都明确的表示自己是一种服务网格产品。Istio 强调了自己在连接、安全、控制和可视化 4 个方面的能力;而 App Mesh 主要强调了一致的可见性和流量控制这两方面能力,当然也少不了强调作为云平台下的产品的好处:托管服务,无需自己维护。
从某种程度上讲,Istio 是一个相对重一点的解决方案,提供了不限于流量管理的各个方面的能力;而 App Mesh 是更加纯粹的服务于运行在 AWS 之上的应用并提供流控功能。笔者认为这和它目前的产品形态还不完善有关(后面会具体提到)。从与 AWS 技术支持团队的沟通中可以感觉到,App Mesh 应该是一盘很大的棋,目前只是初期阶段。
核心术语
和 AWS 里很多产品一样,App Mesh 也不是独创,而是基于 Envoy 开发的。AWS 这样的闭环生态必然要对其进行改进和整合。同时,也为了把它封装成一个对外的服务,提供适当的 API 接口,在 App Mesh 这个产品中提出了下面几个重要的技术术语,我们来一一介绍一下。
服务网格(Service mesh):服务间网络流量的逻辑边界。这个概念比较好理解,就是为使用 App mesh 的服务圈一个虚拟的边界。
虚拟服务(Virtual services):是真实服务的抽象。真实服务可以是部署于抽象节点的服务,也可以是间接的通过路由指向的服务。
虚拟节点(Virtual nodes):虚拟节点是指向特殊工作组(task group)的逻辑指针。例如 AWS 的 ECS 服务,或者 Kubernetes 的 Deployment。可以简单的把它理解为是物理节点或逻辑节点的抽象。
Envoy:AWS 改造后的 Envoy(未来会合并到 Envoy 的官方版本),作为 App Mesh 里的数据平面,Sidecar 代理。
虚拟路由器(Virtual routers):用来处理来自虚拟服务的流量。可以理解为它是一组路由规则的封装。
路由(Routes):就是路由规则,用来根据这个规则分发请求。
上面的图展示了这几个概念的关系:当用户请求一个虚拟服务时,服务配置的路由器根据路由策略将请求指向对应的虚拟节点,这些节点最终会与集群中某个对外提供服务的 DNS 或者服务名一一对应。
那么这些 App Mesh 自创的术语是否能在 Istio 中找到相似甚至相同的对象呢?我归纳了下面的表格来做一个对比:
App MeshIstio
服务网格(Service mesh)Istio并未显示的定义这一概念,我们可以认为在一个集群中,由Istio管理的服务集合,它们组成的网络拓扑即是服务网格。
虚拟服务(Virtual services)Istio中也存在虚拟服务的概念。它的主要功能是定义路由规则,使请求可以根据这些规则被分发到对应的服务。从这一点来说,它和App Mesh的虚拟服务的概念基本上是一致的。
虚拟节点(Virtual nodes)Istio没有虚拟节点的概念,可以认为类似Kubernetes里的Deployment。
虚拟路由器(Virtual routers)Istio也没有虚拟路由器的概念。
路由(Routes)Istio中的目标规则(DestinationRule)和路由的概念类似,为路由设置一些策略。从配置层面讲,其中的子集(subset)和App Mesh路由里选择的目标即虚拟节点对应。但Istio的目标规则更加灵活,也支持更多的路由策略。
从上面的对比看出,App Mesh 目前基本上实现了最主要的流量控制(路由)的功能,但像超时重试、熔断、流量复制等高级一些的功能还没有提供,有待进一步完善。
架构
AWS App Mesh 是一个商业产品,目前还没有找到架构上的技术细节,不过我们依然可以从现有的、公开的文档或介绍中发现一些有用的信息。
从这张官网的结构图中可以看出,每个服务的橙色部分就是 Sidecar 代理:Envoy。而中间的 AWS App Mesh 其实就是控制平面,用来控制服务间的交互。那么这个控制平面具体的功能是什么呢?我们可以从今年的 AWS Summit 的一篇 PPT 中看到这样的字样:
控制平面用来把逻辑意图转换成代理配置,并进行分发。
熟悉 Istio 架构的朋友有没有觉得似曾相识?没错,这个控制平面的职责和 Pilot 基本一致。由此可见,不管什么产品的控制平面,也必须具备这些核心的功能。
那么在平台的支持方面呢?下面这张图展示了 App Mesh 可以被运行在如下的基础设施中,包括 EKS、ECS、EC2 等等。当然,这些都必须存在于 AWS 这个闭环生态中。
而 Istio 这方面就相对弱一些。尽管 Istio 宣称是支持多平台的,但目前来看和 Kubernetes 还是强依赖。不过它并不受限于单一的云平台,这一点有较大的优势。
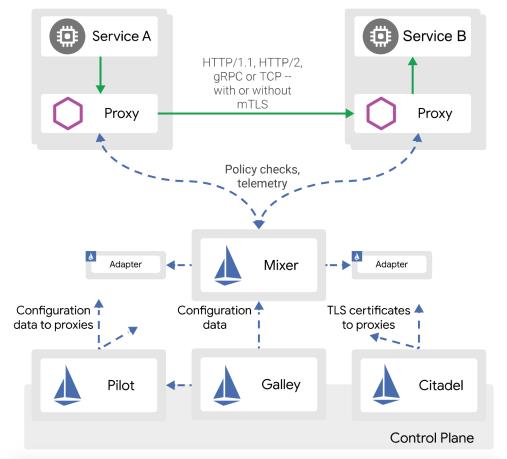
Istio 的架构大家都比较熟悉,数据平面由 Envoy sidecar 代理组成,控制平面包括了 Pilot、Mixer、Citadel、Galley 等控件。它们的具体功能这里就不再赘述了,感兴趣的同学可以直接去 官网 查看详细信息。
功能与实现方式
部署
无论是 Istio 还是 App Mesh 都使用了控制平面+数据平面的模式,且 Sidecar 都使用了 Envoy 代理。Istio 的控制平面组件较多,功能也更复杂,1.0.x 版本完整安装后的 CRD 有 50 个左右。架构修改后 Mixer 的一些 adapter 被独立出去,crd 有所降低。下面是最新的 1.4 版本,安装后仍然有 24 个 crd。
而 App Mesh 就简单得多,只针对核心概念添加了如下 3 个 crd,用一个 controller 进行管理。
尽管 Istio 更多的 crd 在一定程度上代表了更加丰富的功能,但同时也为维护和 troubleshooting 增加了困难。
流量控制
尽管两者的数据平面都基于 Envoy,但它们提供的流量控制能力目前还是有比较大的差距的。在路由的设置方面,App Mesh 提供了相对比较丰富的匹配策略,基本能满足大部分使用场景。下面是 App Mesh 控制台里的路由配置截图,可以看出,除了基本的 URI 前缀、HTTP Method 和 Scheme 外,也支持请求头的匹配。
Istio 的匹配策略更加完善,除了上面提到的,还包括 HTTP Authority,端口匹配,请求参数匹配等,具体信息可以从官方文档的虚拟服务设置查看。下面两段 yaml 分别展示了两个产品在虚拟服务配置上的差异。
App Mesh 配置:
Istio 配置:
另外一个比较大的不同是,App Mesh 需要你对不同版本的服务分开定义(即定义成不同的虚拟服务),而 Istio 是通过目标规则 DestinationRule 里的子集 subsets 和路由配置做的关联。本质上它们没有太大区别。
除了路由功能外,App Mesh 就显得捉襟见肘了。就在笔者撰写本文时,AWS 刚刚添加了重试功能。而 Istio 借助于强大的 Envoy,提供了全面的流量控制能力,如超时重试、故障注入、熔断、流量镜像等。
安全
在安全方面,两者的实现方式具有较大区别。默认情况下,一个用户不能直接访问 App Mesh 的资源,需要通过 AWS 的 IAM 策略给用户授权。比如下面的配置是容许用户用任意行为去操作网格内的任意资源:
因此,App Mesh 的授权和认证都是基于 AWS 自身的 IAM 策略。
Istio 提供了两种认证方式,基于 mTLS 的传输认证,和 基于 JWT 的身份认证。而 Istio 的授权是通过 RBAC 实现的,可以提供基于命名空间、服务和 HTTP 方法级别的访问控制。这里就不具体展示了,大家可以通过官网 文档 来查看。
可观察性
一般来说,可以通过三种方式来观察你的应用:指标数据、分布式追踪、日志。Istio 在这三个方面都有比较完整的支持。指标方面,可以通过 Envoy 获取请求相关的数据,同时还提供了服务级别的指标,以及控制平面的指标来检测各个组件的运行情况。通过内置的 Prometheus 来收集指标,并使用 Grafana 展示出来。分布式追踪也支持各种主流的 OpenTracing 工具,如 Jaeger、Zipkin 等。访问日志一般都通过 ELK 去完成收集、分析和展示。另外,Istio 还拥有 Kiali 这样的可视化工具,给你提供整个网格以及微服务应用的拓扑视图。总体来说,Istio 在可观察方面的能力是非常强大的,这主要是因为 Mixer 组件的插件特性带来了巨大的灵活性。
App Mesh 在这方面做的也不错。从最新发布的 官方 repo 中,App Mesh 已经提供了集成主流监控工具的 helm chart,包括 Prometheus、Grafana、Jaeger 等。同时,AWS 又一次发挥了自己闭环生态的优势,提供了与自家的监控工具 CloudWatch、X-Ray 的整合。总的来说,App Mesh 在对服务的可观察性上也不落下风。
Amazon 与 Google 的棋局
AWS App Mesh 作为一个 2019 年 4 月份才发布的产品(GA),在功能的完整性上和 Istio 有差距也是情有可原的。从 App Mesh 的 Roadmap 可以看出,很多重要的功能,比如熔断已经在开发计划中。从笔者与 AWS 的支持团队了解的信息来看,他们相当重视这个产品,优先级很高,进度也比较快,之前还在预览阶段的重试功能在上个月也正式发布了。另外,App Mesh 是可以免费使用的,用户只需要对其中的实例资源付费即可,没有额外费用。对 AWS 来说,该产品的开发重点是和现有产品的整合,比如 Roadmap 列出的使用 AWS Gateway 作为 App Mesh 的 Ingress。借助着自己的生态优势,这种整合即方便快捷的完善了 App Mesh,同时又让生态内的产品结合的更紧密,使得闭环更加的牢固,不得不说是一步好棋。
和 App Mesh 目前只强调流控能力不同,Istio 更多的是把自己打造成一个更加完善的、全面的服务网格系统。架构优雅,功能强大,但性能上受到质疑。在产品的更迭上貌似也做的不尽如人意(不过近期接连发布了 1.3 到 1.4 版本,让我们对它的未来发展又有了期待)。Istio 的优势在于 3 大顶级技术公司加持的强大资源,加上开源社区的反哺,利用好的话容易形成可持续发展的局面,并成为下一个明星级产品。然而 Google 目前对 Istio 的态度有一些若即若离,一方面很早就在自家的云服务 gcloud 里提供了 Istio 的默认安装选项,但同时又发布了和 Istio 有竞争关系的 Traffic director 这个托管的控制平面。笔者的猜测是 Google 也意识到 Istio 的成熟不可能一蹴而就,鉴于网格技术托管需求的越发强烈,先提供一个轻量化的产品以占领市场。
目前各大厂商都意识到了网格技术的重要性并陆续推出了自己的产品(包括 AWS App Mesh,Kong 的 Kuma,国内的蚂蚁金服、腾讯云等),竞争也会逐渐激烈。未来是三分天下还是一统山河,让我们拭目以待。
我们的实践 - 从 Service Mesh 迈向云原生
最后这部分给大家简要介绍一下我们(FreeWheel)在 Service Mesh 领域的实践。希望通过一些前瞻性的探索,总结出最佳实践,为我们将来的微服务应用全面拥抱云原生提供一定的经验和指导。目前我们已经开发完成的 Data service 项目就整合了 AWS App Mesh,即将上线,并使用网格的能力进行智能路由和发布。
Data service 项目只包含两个服务:Forecast service 和 Query service,前者作为业务服务通过 Query service 查询来自持久层(ClickHouse)的数据;后者作为数据访问代理,从持久层获取数据并进行对象化的封装。这个 mini 的微服务系统非常适合作为一个先行者为我们探索网格的功能、性能、易用性等方面的能力,且范围足够小,不会影响到其他业务系统。
选择 AWS App Mesh 作为该项目的网格产品主要原因如下:
FreeWheel 是一个重度使用 AWS 各项服务的公司,未来所有的服务也都会全部托管的 AWS 上。作为一个闭环生态,App Mesh 可以和现有服务无缝整合,提高易用性;
相比 Istio 这样还不太成熟的开源产品,我们可以得到 AWS 技术团队的全力支持;
数据平面基于成熟高效的 Envoy,控制平面不存在 Istio 中的性能问题;
完全免费
下图是该项目的部署视图。前端请求从我们的业务系统 UIF 发送到 Forecast service,它作为 App Mesh 的一个虚拟节点,调用 Data service 进行数据查询。Data service 作为数据平面,会注入 App Mesh 的 sidecar 代理。这两个服务组成了一个 Mesh 网格,并无缝整合在 AWS 的 EKS 中。
下图是网格内部的逻辑视图,展示了如何利用 App Mesh 进行智能路由。Forecast service 作为调用者被定义为虚拟节点,Data service 作为虚拟服务,挂载着虚拟路由,内部根据需要可以设定若干路由规则。用 App Mesh 实现一个金丝雀发布的过程非常简单:假设在 Data service 的新版本(V2)发布前,流量都被指向 V1 版本;此时我们在 App Mesh 里配置好一个新的路由规则,将 10%的流量指向新的 V2 版本;只需要将新的规则通过 kubectl apply -f new-rule.yaml 应用到集群中,金丝雀发布就可以完成,且无缝切换,对用户透明。
在后续的工作中,我们会先验证 App Mesh 的性能和可靠性,然后逐渐的将更多的流量控制(如超时重试、熔断等)功能添加进来,并总结出一整套可行的实施方案,供大家参考。也欢迎对 Service Mesh 感兴趣的同学加入到我们的团队中,一起学习,共同进步。
总结
解耦是软件开发中永恒的主题,开发人员对消除重复的偏执是推动软件、以及架构模式演进的主要动力。而 Service Mesh 的核心价值就是将服务通信功能从业务逻辑中解耦,并下沉为基础设施,由控制平面统一管理。有人将 Service Mesh、Kubernetes 和 Serverless 技术称为云原生应用开发的三驾马车。Kubernetes 是云应用实际意义上的操作系统;Service Mesh 将服务通信功能剥离,实现了与业务的解耦;Serverless 让你不用关心应用的服务器。这三项技术让我们有能力实现应用开发的终极目标,那就是:只关注业务本身。而它们,也会引领我们通向未来云原生应用的诗和远方。
万字长文:Service Mesh · Istio · 以实践入门
Photo @ Jez Timms
文 | 三辰
本文不是 Istio 的全部,但是希望入门仅此一篇就够。
概念
围绕云原生(CN)的概念,给人一种知识大爆炸的感觉,但假如你深入了解每一个概念的细节,你会发现它和你很近,甚至就是你手里每天做的事情。

图片来源:https://landscape.cncf.io/
服务网格
历史
原始的应用程序--图片来源于网络
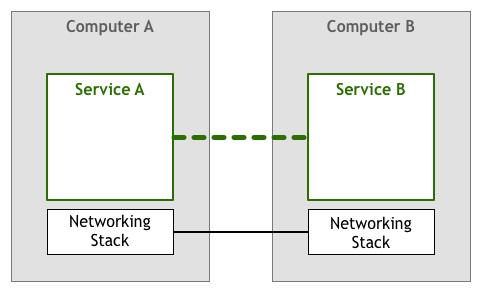
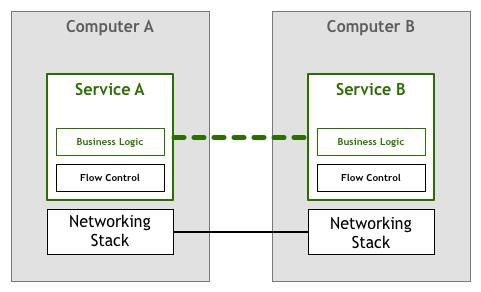
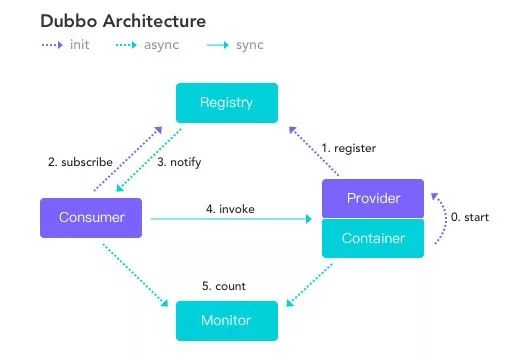
图片来源于网络
Consumer 与 Provider 就是微服务互相调用的一种解决方案。
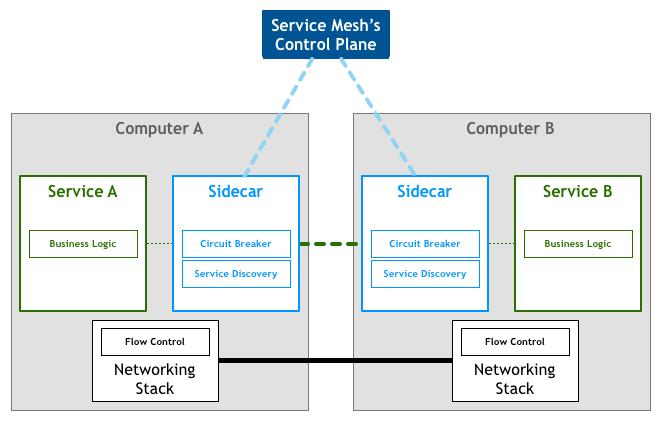
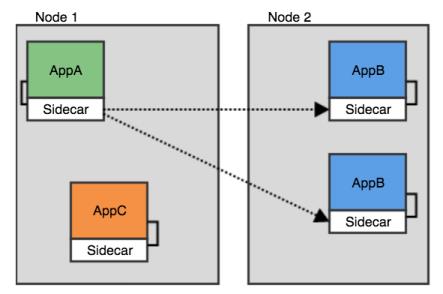
以下是微服务集群基于Sidecar互相通讯的简化场景:
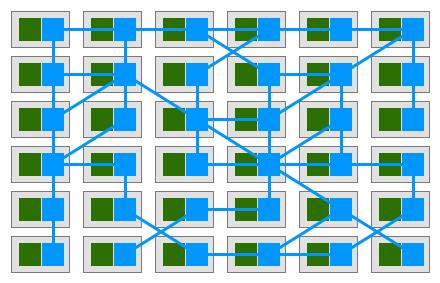
图片来源于网络
Service Mesh 是 Kubernetes 支撑微服务能力拼图的最后一块
Istio 和 Envoy
Istio,第一个字母是(ai)。
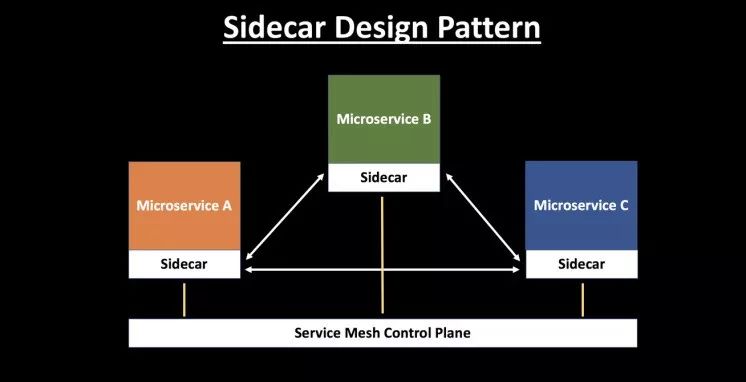
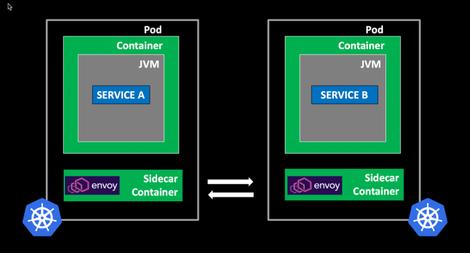
Istio基于Envoy实现Service Mesh数据平面--图片来源于网络

Sidecar注入
小结

所以我们打算卖什么?
实践
准备工作
如果是本地测试,Docker-Desktop也可以启动一个单机的k8s集群
curl -sL "https://github.com/istio/istio/releases/download/1.4.2/istio-1.4.2-osx.tar.gz" | tar xz从 1.4.0 版本开始,不再使用 helm 来安装 Istio
# helm工具$ brew install kubernetes-helm
安装Istio
首先确认 kubectl 连接的正确的 k8s 集群。
istioctl
安装
cd istio-1.4.2# 安装istioctlcp bin/istioctl /usr/local/bin/ # 也可以加一下PATH# (可选)先查看配置文件istioctl manifest generate --set profile=demo > istio.demo.yaml# 安装istioistioctl manifest apply --set profile=demo## 以下是旧版本istio的helm安装方式 ### 创建istio专属的namespacekubectl create namespace istio-system# 通过helm初始化istiohelm template install/kubernetes/helm/istio-init --name istio-init --namespace istio-system | kubectl apply -f -# 通过helm安装istio的所有组件helm template install/kubernetes/helm/istio --name istio --namespace istio-system | kubectl apply -f -
## 以下是旧版本istio的helm安装方式 ### 创建istio专属的namespacekubectl create namespace istio-system# 通过helm初始化istiohelm template install/kubernetes/helm/istio-init --name istio-init --namespace istio-system | kubectl apply -f -# 通过helm安装istio的所有组件helm template install/kubernetes/helm/istio --name istio --namespace istio-system | kubectl apply -f -
$ kubectl get crds | grep 'istio.io' | wc -l23
如果是阿里云ACS集群,安装完Istio后,会有对应的一个SLB被创建出来,转发到Istio提供的虚拟服务器组
示例:Hello World
cd samples/hello-world
注入
istioctl kube-inject -f helloworld.yaml -o helloworld-istio.yaml实际上就是通过脚本修改了原文件,增加了:
分析
apiVersion: v1kind: Servicemetadata:name: helloworldlabels:app: helloworldspec:ports:- port: 5000name: httpselector:app: helloworld---apiVersion: apps/v1kind: Deploymentmetadata:creationTimestamp: nulllabels:version: v1name: helloworld-v1spec:replicas: 1selector:matchLabels:app: helloworldversion: v1strategy: {}template:metadata:labels:app: helloworldversion: v1spec:containers:- image: docker.io/istio/examples-helloworld-v1imagePullPolicy: IfNotPresentname: helloworldports:- containerPort: 5000resources:requests:cpu: 100m---apiVersion: apps/v1kind: Deploymentmetadata:creationTimestamp: nulllabels:version: v2name: helloworld-v2spec:replicas: 1selector:matchLabels:app: helloworldversion: v2strategy: {}template:metadata:labels:app: helloworldversion: v2spec:containers:- image: docker.io/istio/examples-helloworld-v2imagePullPolicy: IfNotPresentname: helloworldports:- containerPort: 5000resources:requests:cpu: 100m
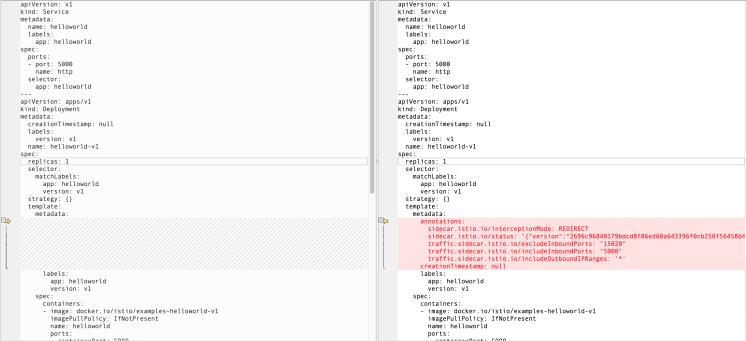
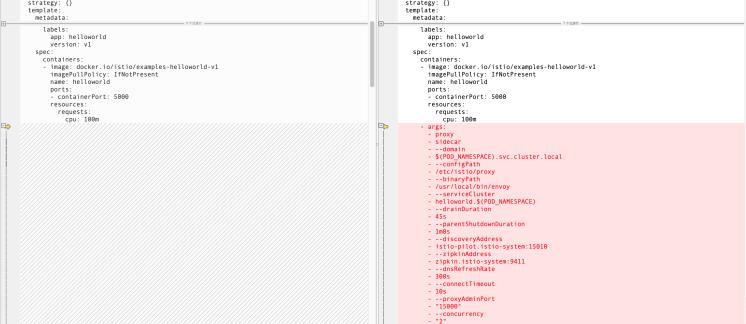
- args:- proxy- sidecar- ...env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- ...image: docker.io/istio/proxyv2:1.3.2imagePullPolicy: IfNotPresentname: istio-proxyports:- containerPort: 15090name: http-envoy-promprotocol: TCPreadinessProbe:failureThreshold: 30httpGet:path: /healthz/readyport: 15020initialDelaySeconds: 1periodSeconds: 2resources:limits:cpu: "2"memory: 1Girequests:cpu: 100mmemory: 128MisecurityContext:readOnlyRootFilesystem: truerunAsUser: 1337volumeMounts:- mountPath: /etc/istio/proxyname: istio-envoy- mountPath: /etc/certs/name: istio-certsreadOnly: true
镜像名 docker.io/istio/proxyv2:1.3.2 。
initContainers:- args:- -p- "15001"- -z- "15006"- -u- "1337"- -m- REDIRECT- -i- '*'- -x- ""- -b- '*'- -d- "15020"image: docker.io/istio/proxy_init:1.3.2imagePullPolicy: IfNotPresentname: istio-initresources:limits:cpu: 100mmemory: 50Mirequests:cpu: 10mmemory: 10MisecurityContext:capabilities:add:- NET_ADMINrunAsNonRoot: falserunAsUser: 0volumes:- emptyDir:medium: Memoryname: istio-envoy- name: istio-certssecret:optional: truesecretName: istio.default
$ kubectl apply -f helloworld-istio.yamlservice/helloworld createddeployment.apps/helloworld-v1 createddeployment.apps/helloworld-v2 created$ kubectl get deployments.apps -o wideNAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTORhelloworld-v1 1/1 1 1 20m helloworld,istio-proxy docker.io/istio/examples-helloworld-v1,docker.io/istio/proxyv2:1.3.2 app=helloworld,version=v1helloworld-v2 1/1 1 1 20m helloworld,istio-proxy docker.io/istio/examples-helloworld-v2,docker.io/istio/proxyv2:1.3.2 app=helloworld,version=v2并启用一个简单的gateway来监听,便于我们访问测试页面$ kubectl apply -f helloworld-gateway.yamlgateway.networking.istio.io/helloworld-gateway createdvirtualservice.networking.istio.io/helloworld created部署完成之后,我们就可以通过gateway访问hello服务了:$ curl "localhost/hello"Hello version: v2, instance: helloworld-v2-7768c66796-hlsl5$ curl "localhost/hello"Hello version: v2, instance: helloworld-v2-7768c66796-hlsl5$ curl "localhost/hello"Hello version: v1, instance: helloworld-v1-57bdc65497-js7cm
深入探索
流量控制 - 切流
$ kubectl get gw helloworld-gateway -o yamlapiVersion: networking.istio.io/v1alpha3kind: Gatewaymetadata:name: helloworld-gatewayspec:selector:istio: ingressgateway # use istio default controllerservers:- port:number: 80name: httpprotocol: HTTPhosts:- "*"$ kubectl get vs helloworld -o yamlapiVersion: networking.istio.io/v1alpha3kind: VirtualServicemetadata:name: helloworldspec:hosts:- "*"gateways:- helloworld-gatewayhttp:- match:- uri:exact: /helloroute:- destination:host: helloworld # short for helloworld.${namespace}.svc.cluster.localport:number: 5000
apiVersion: networking.istio.io/v1alpha3kind: VirtualServicemetadata:name: helloworldspec:hosts:- "*"gateways:- helloworld-gatewayhttp:- match:- uri:exact: /helloroute:- destination:host: helloworld.default.svc.cluster.localsubset: v1weight: 0- destination:host: helloworld.default.svc.cluster.localsubset: v2weight: 100
apiVersion: networking.istio.io/v1alpha3kind: DestinationRulemetadata:name: helloworld-destinationspec:host: helloworld.default.svc.cluster.localsubsets:- name: v1labels:version: v1- name: v2labels:version: v2
$ kubectl apply -f helloworld-gateway.yamlgateway.networking.istio.io/helloworld-gateway unchangedvirtualservice.networking.istio.io/helloworld configureddestinationrule.networking.istio.io/helloworld-destination created
$ while true;do sleep 0.05 ;curl localhost/hello;doneHello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6Hello version: v2, instance: helloworld-v2-76d6cbd4d-tgsq6
Gateway
VirtualService
DestinationRule
示例:Bookinfo
$ cd samples/bookinfo注入
$ kubectl label namespace default istio-injection=enabled部署
$ kubectl apply -f platform/kube/bookinfo.yamlservice/details createdserviceaccount/bookinfo-details createddeployment.apps/details-v1 createdservice/ratings createdserviceaccount/bookinfo-ratings createddeployment.apps/ratings-v1 createdservice/reviews createdserviceaccount/bookinfo-reviews createddeployment.apps/reviews-v1 createddeployment.apps/reviews-v2 createddeployment.apps/reviews-v3 createdservice/productpage createdserviceaccount/bookinfo-productpage createddeployment.apps/productpage-v1 created
$ kubectl apply -f networking/bookinfo-gateway.yamlgateway.networking.istio.io/bookinfo-gateway createdvirtualservice.networking.istio.io/bookinfo created



流量控制 - 网络可见性
$ kubectl run --image centos:7 -it probe# 请求productpage服务上的接口[root@probe-5577ddd7b9-rbmh7 /]# curl -sL http://productpage:9080 | grep -o "<title>.*</title>"<title>Simple Bookstore App</title>$ kubectl exec -it $(kubectl get pod -l run=probe -o jsonpath='{..metadata.name}') -c probe -- curl www.baidu.com | grep -o "<title>.*</title>"<title>百度一下,你就知道</title>
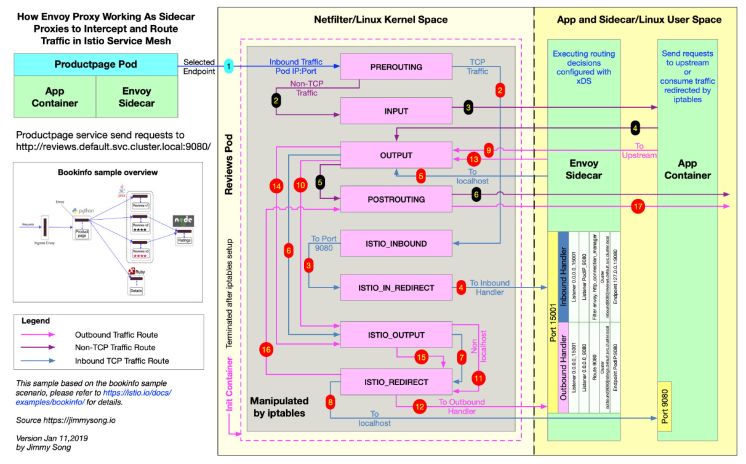
Sidecar
$ kubectl get configmap istio -n istio-system -o yaml | sed 's/mode: ALLOW_ANY/mode: REGISTRY_ONLY/g' | kubectl replace -n istio-system -f -configmap "istio" replaced$ kubectl get configmap istio -n istio-system -o yaml | grep -n1 -m1 "mode: REGISTRY_ONLY"67- outboundTrafficPolicy:68: mode: REGISTRY_ONLY
$ kubectl apply -f - <<EOFapiVersion: networking.istio.io/v1alpha3kind: Sidecarmetadata:name: defaultnamespace: istio-systemspec:egress:- hosts:- "./*"- "istio-system/*"EOFsidecar.networking.istio.io/default configured
每个namespace只允许一个无 workloadSelector 的配置 rootNamespace中无 workloadSelector 的配置是全局的,影响所有namespace,默认的rootNamespace=istio-system
egress
这里需要等待一会生效,或者直接销毁重新部署一个测试容器
$ kubectl exec -it $(kubectl get pod -l run=probe -o jsonpath='{..metadata.name}') -c probe -- curl -v www.baidu.com* About to connect() to www.baidu.com port 80 (#0)* Trying 220.181.38.150...* Connected to www.baidu.com (220.181.38.150) port 80 (#0)> GET / HTTP/1.1> User-Agent: curl/7.29.0> Host: www.baidu.com> Accept: */*>* Recv failure: Connection reset by peer* Closing connection 0curl: (56) Recv failure: Connection reset by peercommand terminated with exit code 56
效果是:外网已经访问不通。
apiVersion: networking.istio.io/v1alpha3kind: ServiceEntrymetadata:name: baiduspec:hosts:- www.baidu.comports:- number: 80name: httpprotocol: HTTPresolution: DNSlocation: MESH_EXTERNAL---apiVersion: networking.istio.io/v1alpha3kind: Sidecarmetadata:name: defaultspec:egress:- hosts:- "./www.baidu.com"port:number: 80protocol: HTTPname: http
$ kubectl exec -it $(kubectl get pod -l run=probe -o jsonpath='{..metadata.name}') -c probe -- curl -v www.baidu.com* About to connect() to www.baidu.com port 80 (#0)* Trying 220.181.38.150...* Connected to www.baidu.com (220.181.38.150) port 80 (#0)> GET / HTTP/1.1> User-Agent: curl/7.29.0> Host: www.baidu.com> Accept: */*>< HTTP/1.1 200 OK< accept-ranges: bytes< cache-control: private, no-cache, no-store, proxy-revalidate, no-transform< content-length: 2381< content-type: text/html< date: Tue, 15 Oct 2019 07:45:33 GMT< etag: "588604c8-94d"< last-modified: Mon, 23 Jan 2017 13:27:36 GMT< pragma: no-cache< server: envoy< set-cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/< x-envoy-upstream-service-time: 21
$ kubectl exec -it $(kubectl get pod -l run=probe -o jsonpath='{..metadata.name}') -c probe -- curl productpage:9080curl: (56) Recv failure: Connection reset by peercommand terminated with exit code 56配置上ServiceEntryapiVersion: networking.istio.io/v1alpha3kind: Sidecarmetadata:name: defaultspec:egress:- hosts:- "./www.baidu.com"- "./productpage.default.svc.cluster.local" # 这里必须用长名称---apiVersion: networking.istio.io/v1alpha3kind: ServiceEntrymetadata:name: baiduspec:hosts:- www.baidu.comresolution: DNSlocation: MESH_EXTERNAL---apiVersion: networking.istio.io/v1alpha3kind: ServiceEntrymetadata:name: productpagespec:hosts:- productpageresolution: DNSlocation: MESH_EXTERNAL
$ kubectl exec -it $(kubectl get pod -l run=probe -o jsonpath='{..metadata.name}') -c probe -- curl productpage:9080 | grep -o "<title>.*</title>"<title>Simple Bookstore App</title>
需要留意的是,不带workloadSelector的(不指定特定容器的)Sidecar配置只能有一个,所以规则都需要写在一起。
ingress
apiVersion: networking.istio.io/v1alpha3kind: Sidecarmetadata:name: productpage-sidecarspec:workloadSelector:labels:app: productpageingress:- port:number: 9080protocol: HTTPdefaultEndpoint: 127.0.0.1:10080egress:- hosts:- "*/*"
这个配置的效果是让 productpage 应用的容器收到 9080 端口的 HTTP 请求时,转发到容器内的10080端口。
$ kubectl exec -it $(kubectl get pod -l run=probe -o jsonpath='{..metadata.name}') -c probe -- curl -s productpage:9080upstream connect error or disconnect/reset before headers. reset reason: connection failure
小结
概述
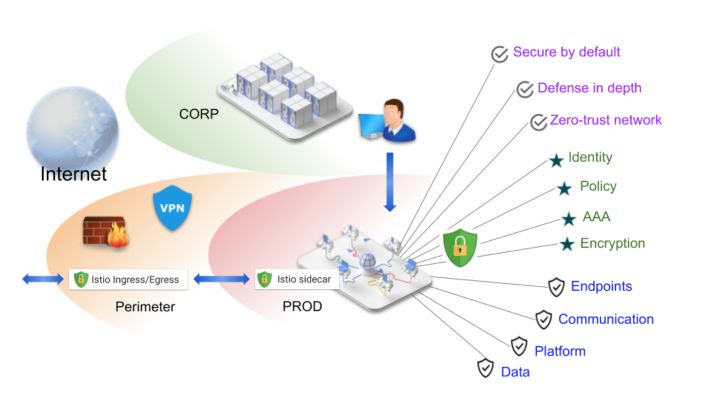
策略(Policy)
TLS
认证(Authentication)与鉴权(Authorization)
认证(Authentication)
示例:配置Policy
准备环境:
#!/bin/bashkubectl create ns fookubectl apply -f <(istioctl kube-inject -f samples/httpbin/httpbin.yaml) -n fookubectl apply -f <(istioctl kube-inject -f samples/sleep/sleep.yaml) -n fookubectl create ns barkubectl apply -f <(istioctl kube-inject -f samples/httpbin/httpbin.yaml) -n barkubectl apply -f <(istioctl kube-inject -f samples/sleep/sleep.yaml) -n barkubectl create ns legacykubectl apply -f samples/httpbin/httpbin.yaml -n legacykubectl apply -f samples/sleep/sleep.yaml -n legacy
#!/bin/bashfor from in "foo" "bar" "legacy"; do for to in "foo" "bar" "legacy"; do kubectl exec $(kubectl get pod -l app=sleep -n ${from} -o jsonpath={.items..metadata.name}) -c sleep -n ${from} -- curl "http://httpbin.${to}:8000/ip" -s -o /dev/null -w "sleep.${from} to httpbin.${to}: %{http_code} "; done; done$ ./check.shsleep.foo to httpbin.foo: 200sleep.foo to httpbin.bar: 200sleep.foo to httpbin.legacy: 200sleep.bar to httpbin.foo: 200sleep.bar to httpbin.bar: 200sleep.bar to httpbin.legacy: 200sleep.legacy to httpbin.foo: 200sleep.legacy to httpbin.bar: 200sleep.legacy to httpbin.legacy: 200
打开TLS:
$ kubectl apply -f - <<EOFapiVersion: "authentication.istio.io/v1alpha1"kind: "MeshPolicy"metadata:name: "default"spec:peers:- mtls: {}EOF
$ ./check.shsleep.foo to httpbin.foo: 503sleep.foo to httpbin.bar: 503sleep.foo to httpbin.legacy: 200sleep.bar to httpbin.foo: 503sleep.bar to httpbin.bar: 503sleep.bar to httpbin.legacy: 200sleep.legacy to httpbin.foo: 000command terminated with exit code 56sleep.legacy to httpbin.bar: 000command terminated with exit code 56sleep.legacy to httpbin.legacy: 200
配置托管的 mTLS 能力
kubectl apply -f - <<EOFapiVersion: "networking.istio.io/v1alpha3"kind: "DestinationRule"metadata:name: "default"namespace: "istio-system"spec:host: "*.local"trafficPolicy:tls:mode: ISTIO_MUTUALEOF
$ ./check.shsleep.foo to httpbin.foo: 200sleep.foo to httpbin.bar: 200sleep.foo to httpbin.legacy: 503sleep.bar to httpbin.foo: 200sleep.bar to httpbin.bar: 200sleep.bar to httpbin.legacy: 503sleep.legacy to httpbin.foo: 000command terminated with exit code 56sleep.legacy to httpbin.bar: 000command terminated with exit code 56sleep.legacy to httpbin.legacy: 200
sleep.foo to httpbin.bar: 503apiVersion: networking.istio.io/v1alpha3kind: Sidecarmetadata:name: defaultnamespace: istio-systemspec:egress:- hosts:- ./* # <--- istio-system/*
分析
ns=legacy中的行为仍然不变
鉴权(Authorization)
不是必要前提 有一部分鉴权规则是不依赖mTLS的,但是很少。
apiVersion: security.istio.io/v1beta1kind: AuthorizationPolicymetadata:name: deny-allnamespace: foospec:
apiVersion: security.istio.io/v1beta1kind: AuthorizationPolicymetadata:name: deny-allnamespace: foospec:rules:- from:- source:namespaces:- "istio-system"
其它
参考文档
-
Istio官方文档 https://istio.io/docs/ -
Istio Handbook https://www.servicemesher.com/istio-handbook/concepts-and-principle/what-is-service-mesh.html -
Pattern Service Mesh https://philcalcado.com/2017/08/03/pattern_service_mesh.html
作者信息:
↓↓ 点击"阅读原文" 【加入云技术社区】
相关阅读:
更多文章请关注
文章好看点这里[在看] 以上是关于Service Mesh 浅析:从概念、产品到实践的主要内容,如果未能解决你的问题,请参考以下文章