线程池饱和异常
Posted 码海拾贝2023
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线程池饱和异常相关的知识,希望对你有一定的参考价值。
1. 定义
线程池(ThreadPoolExecutor)使用率达到100%,新提交的任务被拒绝,这种情况我们称之为线程池饱和。
线程池使用率 = 活跃线程数(getActiveCount) / 最大线程数(getMaximumPoolSize),线程池饱和意味着:
-
队列使用率100%,任务已堆积,内存占用上升
-
所有线程已被占用,新提交的任务可能被拒绝处理,导致业务中断
通过本章节,你将了解到如何监控、查看、定位线程池饱和导致的生产问题。
2. 背景知识
JVM应用依赖多线程来提升并发吞吐量,但是线程是稀缺资源,线程越多,开销越大:
-
线程的创建、初始化、销毁,会消耗一定系统资源(底层为OS Native Thread),虽然比进程开销小
-
单个线程至少占用-Xss的内存(默认为1M),内存占用(RSS)过多,容易被操作系统OOM Killer强制Kill
-
线程上下文切换过多,进程CPU使用率上升,操作系统最多可同时执行NCPU个线程,频繁切换反而性能下降
在实际项目中,我们使用线程池(ThreadPoolExecutor)来复用线程。
2.1 线程池为何会饱和?
线程池是标准的生产者/消费者模型,生产者通过execute提交任务,消费者(Thread)会轮询队列处理任务(runWorker),最多有N个消费者(最大线程数)。
假设单个任务的平均处理耗时为T毫秒,则每秒最多可处理: (1000 / T) * N 个任务。
举个例子,某线程池最大线程数为10,队列大小为0,单个任务平均处理耗时 T = 20ms,那每秒最多可处理:(1000 / 20 ) * 10 = 500 个任务。
可以看到,影响线程池饱和的两个最大因素是:
- 单个任务平均处理耗时
- 每秒提交的任务数
线程是稀缺资源,数量有限,一般会适当调整,但不是关键因素。
当生产者提交过快,比如流量上升,若任务处理耗时不变,每秒提交的任务超过 500 ,线程池就可能饱和。
当消费者(Thread)或任务变慢,单个任务平均耗时增加到40ms,则每秒处理的任务下降至250,若每秒提交的任务数超过250,线程池就可能饱和。
2.2 如何收集/查看线程池的指标?
//注意只有自己手动创建的才需要主动收集,如果已托管为Spring @Bean / 单例,监控狗会自动收集。
//其中,name为线程池的名称,会展示在监控面板上,建议为有业务含义的
MetricsCollectorMeterRegistry.register(“yourThreadPoolName”,yourExecutor,ThreadPoolExecutorMetricsCollector.DEFAULT);
展开线程池 - ThreadPoolExecutor这一行,找到你关注的线程池,如下图所示:
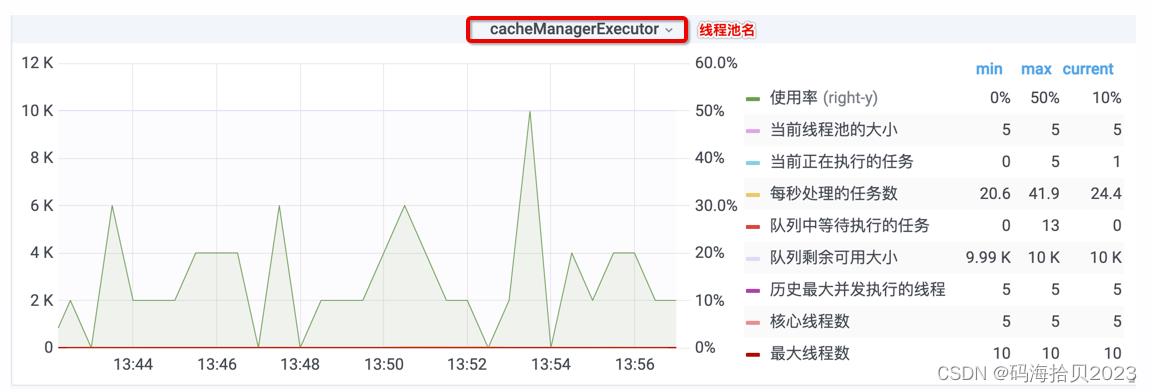
线程池的使用率达到100%,就表明线程池已饱和。
其他图例字段说明如下:
- 当前线程池的大小,对应方法getPoolSize,当前池里有多少个线程
- 当前正在执行的任务,对应方法getActiveCount,有多少个线程正在忙(处理任务)
- 每秒处理的任务数,对应方法getCompletedTaskCount,累计已完成的任务数,基于此计算出大概每秒处理的任务。
- 队里中等待执行的任务,对应方法getQueue().size(),当前队列里堆积的任务数
- 队里剩余可用大小,对应方法getQueue().remainingCapacity(),即 队列容量 - 当前队列里的任务,如果任务没积压,则可以看出这个线程池的队列大小。
- 历史最大并发执行的线程,对应方法getLargestPoolSize,线程池自创建以来最大同时存在的线程数。这个可侧面验证是否存在过使用率100%的情况(这个值等于最大线程数),但这个仅能说明某个时间点同时存在maximumPoolSize个线程而已。
- 核心线程数,对应方法getCorePoolSize
- 最大线程数,对应方法getMaximumPoolSize
指标30秒采样一次,在采样间隔内的突发变化可能捕捉不到。另外,各个指标读取的先后顺序不同,各字段数据也未必完合得上。
2.3 如何创建线程池?
我们推荐基于ThreadPoolExecutor来创建线程池,避免使用Executors等方法创建。
只有完整设置了线程池的6个核心参数,才能避免生产故障,即使出现了生产问题,也方便排查。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler);
线程池大小
线程数的多少影响了任务处理的并行度,但过多的线程数,除了增加内存开销,反而导致性能下降。
CPU密集型
基于内存数据计算、使用CPU时无需等待外部资源的场景(CPU Bound),通常核心线程等于最大线程数,核心线程数(corePoolSize)建议等于系统可用CPU+1。
系统可用CPU基于 Runtime.availableProcessors(),但启用了CGroup CPU限制的情况下,系统可用CPU 建议以CGroup CPU Quota为准。
私有云应用详情的基本信息里,有容量套餐,比如 8U6G ,表示应用最大可用8个CPU + 6G内存。接入了监控狗的应用,可参考应用大盘的 CPU Quota:8CPU !

注意,JDK 8u192及以上版本,支持container-aware,Runtime.availableProcessors()= CGroup CPU Quota,对开发是透明的,即高版本JDK的 Runtime.availableProcessors 会返回8。
IO密集型
涉及到网络调用或磁盘IO、等待IO完成时无需CPU的场景(IO Bound),线程池大小取决于流量和任务处理耗时。
吞吐量依赖线程数的同步调用场景,核心线程数可通过公式估算:每秒提交的任务 / 每秒能处理的任务数。
异步调用的场景,建议线程数等于2倍的进程可用CPU,比如 Netty EventLoop,异步IO。
举个例子,若任务平均处理耗时 20 ms,那么单个线程每秒能处理50个 (1000 / 20),每秒提交200个任务则同时需要4个线程来处理。
举个例子,若任务平均处理耗时 20 ms,那么单个线程每秒能处理50个 (1000 / 20),每秒提交200个任务则同时需要4个线程来处理。
考虑到流量突发或长尾处理耗时,一般会额外冗余几个线程。
除了增加线程数之外,也可选择合适的阻塞队列来缓冲流量或抖动。
IO密集型任务,最大线程数既可以和核心线程数一致,也可以基于突发流量来估算。另外,线程不建议过多,现有节点处理不过来,可适当扩容,也可尝试 Reactive Stream 或者异步IO。
线程闲置时长 - keepAliveTime
建议keepAliveTime 设置在 60 - 120 秒之间,线程闲置时长仅在以下两种情况有效:
-
最大线程数 核心线程数
-
线程池的 allowCoreThreadTimeOut 被手动设置为true
默认情况下, 若线程等待了keepAliveTime这么久,队列里还没有任务,则退出,最多有maximumPoolSize-corePoolSize个线程会终止(terminate)。
当线程池固定大小 ( 最大线程数 = 核心线程数 )时,keepAliveTime 就没有意义了,可设置为0。
在用户手动设置了allowCoreThreadTimeOut 为true 时,上述逻辑作用于所有的 worker,最终全部线程在等待了keepAliveTime之后终止,包括 core + non core 线程。一般周期性的任务、临时流量,处理完之后释放全部线程。
阻塞队列 - workQueue
用于暂存任务的阻塞队列,当已有的核心线程来不及处理新任务时,线程池优先将任务添加到workQueue,这暗示了两点:
-
任务在队列中等待,通常意味者较高的延迟,追求low latency的场景,尽可能避免任务入队
-
队列的大小至关重要,必须显式指定大小,否则,任务堆积时,会占用大量内存,导致OOM
Low Latency 场景
对追求 low latency 的场景,每个新任务尽可能立即执行,避免在队列里等待,与之对应的队列为:SynchronousQueue。
逻辑上,SynchronousQueue是一个队列大小为0的阻塞队列,新任务提交(offer)时,必须有一个 Worker 线程在等待执行它,才算提交成功。
使用SynchronousQueue之后,整个线程池的工作流程调整为:先创建N个核心线程,新任务来了,如果没有核心线程可以立即执行(任务提交失败),则直接新建一个线程,Worker总量不超过最大线程数,超过则交给RejectedExecutionHandler去处理。
比如 Hystrix Command TheadPool 和 Dubbo Provider FixedThreadPool,默认为这个队列。
High Throughput 场景
部分场景,对延迟不敏感,但可能流量波动大,比如异步日志、异步任务等,可引入有界队列缓冲突发流量,与之对应的队列为:LinkedBlockingQueue。
ArrayBlockingQueue 也是一个可选项,但在容量较大时,需提前分配一个capacity大小的Object数组,哪怕实际只存了几个Task。
使用LinkedBlockingQueue时必须指定合理的大小,控制内存开销,增加系统稳定性,尽可能Fail Fast。过多的任务堆积,被引用的方法参数长期得不到回收,轻则老年代不足频繁fullgc,重则 Out Of Memory 。
线程工厂 - threadFactory
在创建任何线程时,尽可能指定一个有业务含义的线程名,默认线程工厂创建的线程名类似:pool-1-thread-1,很难知道是那个业务组件的。
除此之外,也应自定义UncaughtExceptionHandler,增加一些日志输出,方便排查问题,以免有时候线程执行异常但找不到蛛丝马迹。
public class LoggingUncaughtExceptionHandler implements UncaughtExceptionHandler
public static final LoggingUncaughtExceptionHandler DEFAULT =
new LoggingUncaughtExceptionHandler();
private LoggingUncaughtExceptionHandler()
@Override
public void uncaughtException(Thread t, Throwable e)
LOGGER.error("线程:" + t.getName() + "执行任务时异常", e);
建议使用Guava的ThreadFactoryBuilder,代码示例如下:
new ThreadFactoryBuilder()
//线程名,尽可能有业务含义,%d会被替换为递增的数字,比如 cache-refresh-thread-1
.setNameFormat("cache-refresh-thread-%d")
//如果线程执行Run方法时抛出异常,会被这个Handler处理。
.setUncaughtExceptionHandler(LoggingUncaughtExceptionHandler.DEFAULT)
.setDaemon(true)
.build();
注意,通过Executor.summit提交的任务会返回Future,任务执行时的所有异常会通过 Future.get() 抛出,无需UncaughtExceptionHandler处理。
拒绝策略 - RejectedExecutionHandler
JDK提供了四种线程池饱和时的拒绝策略:AbortPolicy(拒绝执行,抛出异常)、CallerRunsPolicy(调用方的线程来执行)、DiscardPolicy(丢弃新任务)、DiscardOldestPolicy(丢弃最先入队的任务),默认策略为AbortPolicy。
尽管已有现成的策略,我们仍建议自定义Policy,增加一些日志输出,方便排查问题。
以AbortPolicy为例(其他Policy同理):
public class LoggingAbortPolicy implements RejectedExecutionHandler
public void rejectedExecution(Runnable r, ThreadPoolExecutor e)
String message="线程池已耗尽,Task " + r.toString() +
" rejected from " +
e.toString();
LOGGER.warn(message);
throw new RejectedExecutionException(message);
另外,在异步Reactive/Netty Eventloop等场景中自定义业务线程池时,应避免使用CallerRunsPolicy,以免阻塞EventLoop。
建议在任务内部try/catch异常,打印适当的业务日志,UncaughtExceptionHandler或RejectedExecutionHandler拿不到具体的业务Context,可能漏掉一些排错用到的参数。
2.4 线程池工作原理
线程池基于生产者/消费者模型,其工作原理如下:
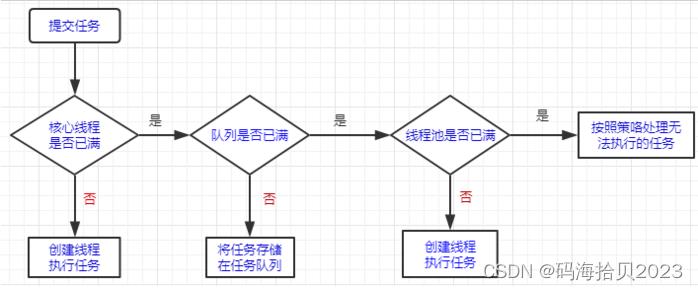
- 新任务提交(execute)了,先判断当前 Worker 是否小于核心线程数(corePoolSize),若是,则调用threadFactory创建一个新线程(Worker),直接执行任务。
- 若当前 Worker 数量等于corePoolSize,则尝试将任务添加到阻塞队列workQueue,若入队成功,则返回。
- 若入队失败,workQueue 满了,判断当前 Worker 数量是否小于最大线程数(maximumPoolSize),若是,则调用threadFactory创建一个新线程,包装为Worker,直接执行任务。
- 若当前 Worker 数量等于最大线程数(maximumPoolSize),线程池饱和了,则调用RejectedExecutionHandler处理新任务,默认策略为:AbortPolicy,即拒绝执行新任务,直接抛出异常。
- 每个 Worker 会轮询消费workQueue里的任务,若线程等待了keepAliveTime这么久,队列里还没有任务,且当前 Worker 数量大于核心线程数,则退出,最多有maximumPoolSize-corePoolSize个线程会终止(terminate)。
可以看到, JDK 在实现线程池时,先创建了几个核心线程;如果新提交的任务来不及处理,则会优先放到阻塞队列里;若队列满了,才会继续创建新线程,但总的线程不会超过最大线程数。
之所以这么设计,是为了优先复用线程,吞吐量优先。
我们知道线程是稀缺资源,线程多了性能反而下降。复用线程,一方面有更多的任务可分摊线程的开销,另一方面,可避免核心线程和最大线程数之间的扩缩容(创建和销毁),避免线程数的抖动。
最大线程数,通常是为了应对突发流量,而额外准备的线程。
3. 定位问题
线程池饱和通常是任务过多或者任务处理太慢导致的。
3.1 收到报警
目前线程池使用率超过80%且这种状态持续超过1分钟则主动报警,收到报警后,可参考常见原因定位问题。
3.2 常见原因
前面提到,影响线程池饱和的两个最大因素是:单个任务平均处理耗时 和 每秒提交的任务数。
在实际排查中,主要围绕这两点,相关数据可参考”如何收集/查看线程池的指标“。
3.2.1 线程池参数不合理
CPU密集型任务,建议线程数为 进程可用CPU + 1。
IO密集型任务,建议线程数为2倍的进程可用CPU,若是同步调用,依赖线程来提升吞吐量,可通过公式估算:每秒提交的任务 / 每秒能处理的任务数。在延迟允许的范围内,可考虑引入有界队列LinkedBlockingQueue,适当减少线程数。
通常情况下,进程可用CPU为Runtime.availableProcessors(),但在开启了资源限制的情况下,需以进程可用的CPU额度为准。
更多内容,参考[“如何创建线程池”]
3.2.2 流量过高
在线程数一定的情况下,假设任务平均耗时 T ms,每秒能处理的任务数 = ( 1000 / T ) * 线程数,监控面板也提供了指标每秒处理的任务数。
如果每秒提交的任务数超过每秒能处理的任务数,即流量过高,可能导致线程池饱和,常见的处理方案:
-
Kafka Consumer 消息过多的话,可尝试切换到支持更多分区的集群,增加消费者,提升并行度。
-
HTTP API 请求量过多的话,可尝试扩容节点,若是基于容器部署的话,可高峰期扩容,低峰期缩容。
-
定时任务的话,控制每批查询返回的数据量,数据该合并的合并、压缩的压缩。
-
资源有限的话,可尝试限流、控制并发量,限制每秒提交的任务数。
3.2.3 慢请求 / 性能抖动
在线程数一定的情况下,任务处理耗时越短,则每秒能处理的任务越多。
慢请求是最常见的导致线程池饱和的原因,包括间歇性抖动,涉及到的场景比较多:
- 慢SQL,能加索引的加索引,能批量的批量,可参考慢SQL章节
- RPC依赖的接口不可用或性能抖动,建议参考性能统计设置合理的IO连接/读取超时,尽可能Fail Fast,避免异常场景下任务阻塞过久。
- 跨机房调用,VPN专线抖动,重要的服务可按机房申请Redis、mysql等基础设施。
- 日志记录过于频繁,磁盘IO负载高,建议只记录必要的日志,除此之外,可尝试异步日志,按天、按大小滚动日志。注意,虽然业务日志异步化可以避免受磁盘IO影响,但是中间件日志,比如GC、AccessLog等,依旧可能受到IO竞争影响,因此建议控制日志量。
- 可创建多组线程池,将快慢请求隔离,防止部分任务阻塞线程。
3.2.4 CPU Throttled
生产环境,大多数服务启用了资源限制,具体可参考:私有云应用详情 - 基本信息 - 实例 - 容量套餐,监控狗应用大盘里也会显示具体的CPU、内存额度。
JDK 8u192及以上版本,支持container-aware,Runtime.availableProcessors()和进程可用的CPU Quota是相同的,对开发是透明的。
在JDK 8u192以下版本,Runtime.availableProcessors()返回的是物理机的CPU数,不会自动识别CGroup进程可用的CPU Quota,因此需要手动去指定、设置,否则可能线程过多、CPU Quota过快用尽从而触发CPU被限制(Throttled)。
生产环境主流的JAVA版本为 8u181,监控狗应用节点的部署环境部分可查看JAVA版本等。
CPU Quota 用完后,线程会被操作系统停止调度执行,造成性能抖动,尤其是GC阶段。
应用是否触发了CPU Throttled,通过访问 ,展开进程 / 线程 / CPU / 磁盘 / IO,找到监控面板”CGroup统计“,图例近一分钟CPU Throttled占比即最近一分钟进程CPU Throttled占总CPU Period的比例,占比越高,CPU被限制的越多,长尾请求可能越多。
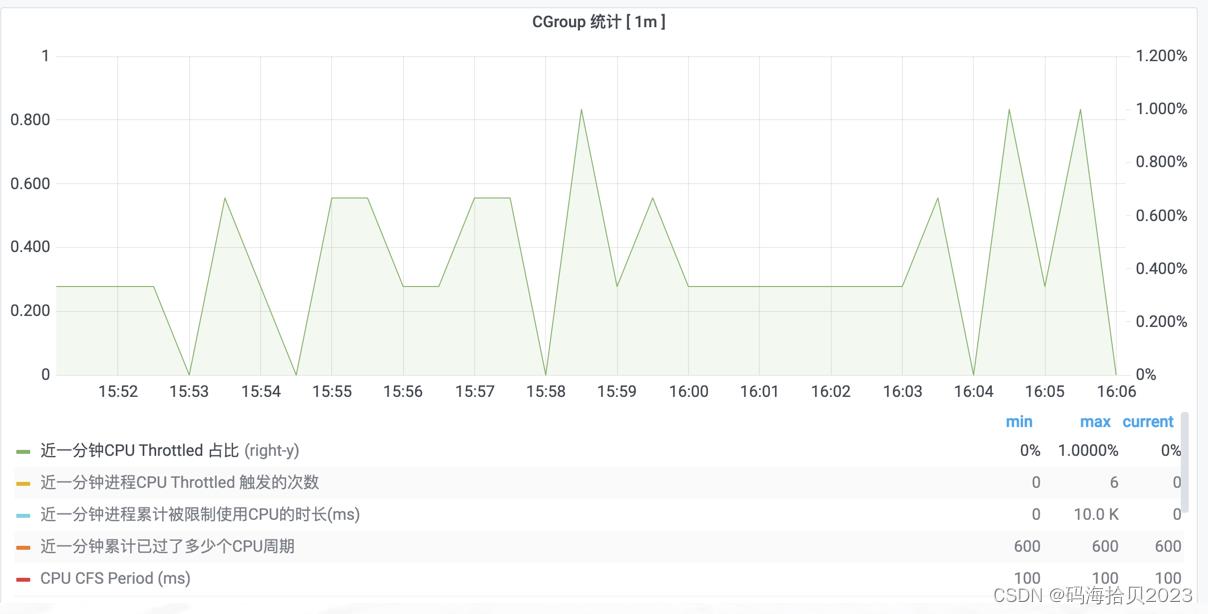
CPU被限制,除了CPU额度太小,就是CPU用的太多了(可通过进程CPU Usage来交叉验证),常见解决方案如下:
- CPU额度小的,可适当扩容CPU,建议普通应用4CPU,核心应用8CPU,基础服务12CPU。
- GC并行线程数(-XX:ParallelGCThreads=NCPU)、Netty Eventloop(-Dio.netty.availableProcessors=NCPU)、ForkJoin Pool(-Djava.util.concurrent.ForkJoinPool.common.parallelism=NCPU)等以进程可用CPU额度为准,减少Runnable状态的线程数。除了设置GC线程数之外,也应关注Young GC频率,越频繁,GC占用的CPU越多。
- 排查是否存在代码质量差、设计不合理的任务,可借助火焰图、JVisualVM CPU采样、日志等根据时间段来缩小范围。
3.2.5 Long GC Pause
GC停顿过长,可能造成线程池任务处理变慢。当线程池饱和时,可交叉比对那个时间点的GC停顿。
GC停顿统计 展开JVM / 内存 / GC / Classloader,找到监控面板”GC耗时“,查看图例最大停顿时长。
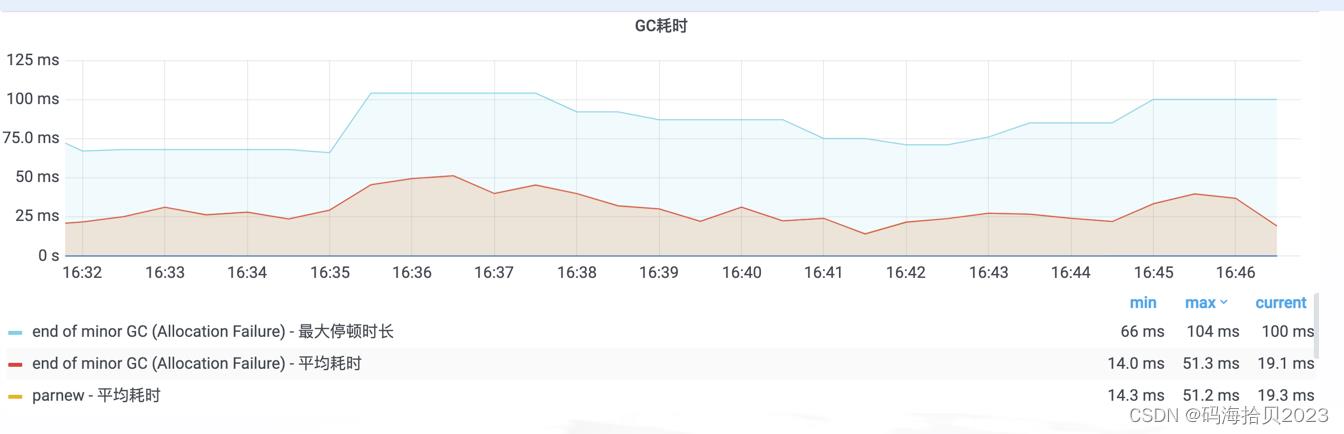
GC 停顿长的原因非常多,常见的解决方案如下:
- CPU Throttled,可参考上文部分,设置合理的GC线程、CPU额度。
- 内存不足,GC过于频繁,可参考监控面板”GC原因与频次“ 和 ”GC内存分配“,扩容内存Quota或者尝试G1
- 代码设计不合理,比如,一次加载过多数据,包括上传、下载、导出、SQL查询返回过多、Kafka 单次拉取的消息过多、Redis大Key。数据量大,处理不及时,对象存活过长,会晋升到老年代,导致GC扫描过多内存,甚至FullGC,因此建议控制批处理的数据量。
3.2.6 JVM冷启动(Slow Start)
部分项目在应用启动初期,会出现线程池饱和,比如 Dubbo Provider 线程池耗尽。
原因是JVM在启动时,是解释执行的,性能比较差。另外,JIT开始编译一些热点代码为Native代码,也会占用很多CPU,可能触发CPU Throttled。
此类问题,建议通过预热机制来解决。预热完成将应用状态修改为Ready后,再放流量进来。
基于发布平台部署的应用,可适当调整发布后等待时长为3至5分钟。在等待期间,会有/healthcheck或其他任务在执行,触发JIT优化,这个时候虽然慢,但没有正常流量进来。
基于服务发现的服务提供方,建议过了发布平台设置的等待期后,将当前节点状态为UP。
4. 处理问题
在排除了代码设计不合理导致的线程池处理过慢后,可从运行时角度来优化。
4.1 调整资源额度
- 设置合理的线程池大小
- 申请合理的应用的CPU Quota 和 Memory Quota
see 常见原因部分的”线程池参数不合理“ 、”CPU Throttled“、”Long GC Pause“
4.1 限流&分片
在资源有限的情况下,尝试令牌桶或Redis限流,控制并发量、批处理的数据量,定时任务可尝试数据分片。
see 常见原因部分的”流量过高“
4.2 节点扩容
单节点的吞吐量是有上限的,在CPU Quota一定的情况下,线程过多,反而导致延迟上升,性能下降。
若瓶颈不是数据库、Redis等基础设施,可尝试多扩容几个节点。
若瓶颈是同步IO,一个线程一个Request,可尝试异步HttpClient。
ThreadPoolExecutor 线程池理论饱和策略工作队列排队策略
本文链接:https://blog.csdn.net/wangmx1993328/article/details/80582803
目录
本文导读
线程池简述
Executor结构
使用线程池的好处
线程池工作原理
线程池饱和策略
AbortPolicy
DiscardPolicy
DiscardOldestPolicy
用户自定义拒绝策略(最常用)
线程池工作流程图
工作队列排队策略
SynchronousQueue
LinkedBlockingQueue
ArrayBlockingQueue
本文导读
本文主要描述Java线程池的理论知识
Java中有几种方法新建一个线程?
继承Thread或者实现Runnable
使用更高级的线程池
线程池简述
线程池是JDK1.5开始引入的,也叫Executor框架,或是Java并发框架
线程池相关的API在java.util.concurrent包中,常用到以下几个类和接口:
java.util.concurrent.Executor:一个只包含一个方法的接口,它的抽象含义是:用来执行一个Runnable任务的执行器
java.util.concurrent.ExecutorService:继承了Executor接口的接口,增加了很多对于任务和执行器的生命周期进行管理的方法
java.util.concurrent.ThreadFactory:一个生成新线程的接口。用户可以通过实现这个接口管理对线程池中生成线程的逻辑
java.util.concurrent.Executors:创建并返回其余各个实例的类,提供了很多不同的生成执行器的实用方法,比如基于线程池的执行器的实现。
java.util.concurrent.ThreadPoolExecutor:这个类维护了一个线程池,对于提交到此Executor中的任务,它不是创建新的线程而是使用池内的线程进行执行,对于数量巨大但执行时间很短的任务,可以显著地减少对于任务执行的开销。
Executor结构
executor结构主要包括任务、任务的执行和异步结果的计算。
任务:包括被执行任务需要实现的接口,如Runnable接口或Callable接口
任务的执行:包括任务执行机制的核心接口Executor,以及继承自Executor的ExecutorService接口。Executor框架有两个关键类实现了ExecutorService接口(ThreadPoolExecutor和ScheduledThreadPoolExecutor)
异步计算的结果:包括接口Future和实现Future接口的FutureTask类
使用线程池的好处
降低资源消耗:可以重复利用已创建的线程降低线程创建和销毁造成的消耗。
提高响应速度:当任务到达时,任务可以不需要等到线程创建就能立即执行。
提高线程的可管理性:线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控
线程池工作原理
当一个新的任务提交到线程池之后,线程池处理过程如下:
线程池判断核心线程池里的线程是否已满。未满时,则创建一个新的工作线程来执行任务。如果核心线程池里的线程已满,则执行第二步。
线程池判断工作队列是否已经满。如果工作队列没有满,则将新提交的任务存储在这个工作队列里等待执行。如果工作队列满了,则执行第三步。
线程池判断线程池(核心线程池外的线程池部分)的线程是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
线程池饱和策略
常用的饱和策略如下:
它们是ThreadPoolExecutor类中的内部类,可以直接调用
AbortPolicy
Java线程池默认的阻塞策略,即不执行此新任务,而且直接抛出一个运行时异常,切记ThreadPoolExecutor.execute需要try catch,否则程序会直接退出。
DiscardPolicy
直接抛弃,新任务不执行,空方法
DiscardOldestPolicy
从队列里面抛弃head的一个任务,并再次execute 此task。
用户自定义拒绝策略(最常用)
实现RejectedExecutionHandler,并自己定义策略模式
线程池工作流程图
以ThreadPoolExecutor为例展示线程池的工作流程
如果当前运行的线程少于corePoolSize(核心线程数),则创建新线程来执行任务(注意,执行这一步骤需要获取全局锁)。
如果运行的线程等于或多于corePoolSize,则将任务加入BlockingQueue(阻塞队列/任务队列)。
如果无法将任务加入BlockingQueue(队列已满),则在非corePool中创建新的线程来处理任务(注意,执行这一步骤需要获取全局锁)。
如果创建新线程将使当前运行的线程超出maximumPoolSize,任务将被拒绝,并执行线程饱和策略,如:RejectedExecutionHandler.rejectedExecution()方法。
ThreadPoolExecutor采取上述步骤的总体设计思路,是为了在执行execute()方法时,尽可能地避免获取全局锁(那将会是一个严重的可伸缩瓶颈)。在ThreadPoolExecutor完成预热之后(当前运行的线程数大于等于corePoolSize),几乎所有的execute()方法调用都是执行步骤2,而步骤2不需要获取全局锁。
工作队列排队策略
已经说过当线程池中工作线程的总数量超过核心线程数量后,新加的任务就会放入工作队列中进行等待被执行
使用线程池就得创建ThreadPoolExecutor对象,通过ThreadPoolExecutor(线程池)类的构造方法创建时,就得指定工作队列,它是BlockingQueue<Runnable>接口,而实际开发中是指定此接口的具体实现类,常用的如下所示。
SynchronousQueue
直接提交策略----意思是工作队列不保存任何任务被等待执行,而是直接提交给线程进行执行。
工作队列的默认选项是 SynchronousQueue,它将任务直接提交给线程而不保存它们。
如果不存在可用于立即运行任务的线程,则试图把任务加入队列将失败,因此会构造一个新的线程。
此策略可以避免在处理可能具有内部依赖性的请求集时出现锁。直接提交通常要求无界 maximumPoolSizes 以避免拒绝新提交的任务。
Executors的newCacheThreadPool()方法创建线程池,就是使用的此种排队策略
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
LinkedBlockingQueue
无界队列策略----无界指的是工作队列大小没有上限,可以添加无数个任务进行等待。
使用无界队列将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。于是创建的线程就不会超过 corePoolSize。因此,maximumPoolSize 的值也就无效了。所以一般让corePoolSize等于maximumPoolSize
当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列
Executors的newFixedThreadPool(int nThreads)方法创建线程池,就是使用的此种排队策略
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
ArrayBlockingQueue
有界队列策略----意思是工作队列的大小是有限制的
优点是可以防止资源耗尽的情况发生,因为如果工作队列被无休止的添加任务也是很危险的
当工作队列排满后,就会执行线程饱和策略
// 构造线程池
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(3, 4,
3, TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(2),
new ThreadPoolExecutor.DiscardOldestPolicy());
如上核心线程为3个,每个线程的工作队列大小为2(即队列中最多有两个任务在等待执行),线程池最大线程数为4个
所以当工作线程数小于等于3时,直接新建线程执行任务;超过3时,任务会被添加进工作队列进行等待,3*2=6,当工作队列等待的任务数超过6个以后,则又会新建一个线程,此时整个线程池线程总数已经达到了4个,当还有任务进行添加时,此时将采取饱和策略
————————————————
版权声明:本文为CSDN博主「蚩尤后裔」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangmx1993328/article/details/80582803
以上是关于线程池饱和异常的主要内容,如果未能解决你的问题,请参考以下文章