Faster RCNN学习笔记
Posted 摆烂无敌王者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Faster RCNN学习笔记相关的知识,希望对你有一定的参考价值。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
最近在学习Faster RCNN,所以做一个笔记来记录一下,这样也方便日后的复习, 有错误欢迎指出
一、Faster RCNN概览
Faster RCNN算法发表于NIPS2015,是一种两阶段算法。相较于Fast RCNN,Faster RCNN最大的创新点在于提出了RPN(Region Proposal Network),利用Anchor机制将区域生成与卷积网络联系到一起,极大的提升了检测速度。
1.1.什么是Anchor
Anchor可以看做是图像上很多固定大小与宽高的方框。假设一个256256大小的图片,经过64、128、256的下采样后,产生44、22、11的特征图,我们在这三个特征图上每个点上都设置三个不同大小的Anchor。
在Faster RCNN中,Anchor被当做强先验的知识,接下来就只需要将Anchor与真实物体进行匹配,进行分类与位置的微调即可,这样可以极大的降低网络收敛的难度,因此其速度也就得到了巨大的提升。
1.2.Faster RCNN算法基本流程
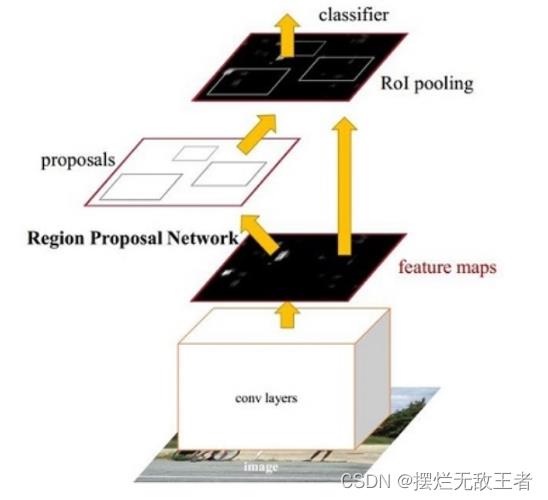
上图是Faster RCNN常用的一个图片,它简要说明了Faster RCNN的主要内容。从功能模块来讲,Faster RCNN主要包括了特征提取网络(conv layers)、RPN模块(Region Proposal Network)、ROI Pooling模块和RCNN模块。下面是它们的具体功能:
**1.特征提取网络Backbone:**即特征提取网络,用于提取特征。以VGGNet为例,假设输入图像大小是3600800,由于VGGNet包含了4个Pooling层,下采样率为16,则输出的feature map的大小为5123750(具体计算可以参考VGGNet)
**2.RPN模块:**区域生成模块,作用是生成较好的建议框,在这里要用到Anchor。RPN又分为5个子模块:
- Anchor生成:RPN对feature map上的每个点都对应了9个Anchor(以上图为例,每个图片生成37509个Anchor)这9个Anchor大小不同,对应到原图基本可以覆盖全部出现的物体,接下来,RPN的工作就是从中筛选,调整出更好的位置,得到Propos
- RPN卷积网络:利用1*1的卷积在feature map上得到每一个Anchor的预测得分与预测偏移值
- 计算RPN loss:这一步只在训练中,将所有的Anchor与标签进行匹配,匹配程度较好的Anchor赋予正样本,较差的赋予负样本,得到分类与偏移的真值,与第二步中的预测得分与预测偏置进行loss计算
- 得到Proposal利用第二步中每一个Anchor预测得分与偏移量可以进一步得到一组较好的Proposal,送到后续网络中
- 筛选Proposal得到ROI:进一步筛选Proposal得到ROI(默认256个)
3.ROI Pooling模块:这部分主要是用来接收RPN提取的feature map和RPN的 ROI,输送到RCNN网络中。由于RCNN模块使用了全连接网络,要求特征的维度固定,但每一个ROI对应的特征大小各不相同,无法送到全连接网络中,因此ROI Pooling将ROI特征池化到固定大小,方便送入网络。
4.RCNN模块:将ROI Pooling得到的特征送入全连接网络,预测每一个ROI的分类,并预测偏移量以精修边框的位置,并计算损失,完成整个Faster RCNN的过程。该部分分为三个模块: - RCNN全连接网络:将得到的固定维度的ROI特征接到全连接网络中,输出为RCNN部分的预测得分与预测回归偏移量
- 计算RCNN的真值:对于筛选出的ROI,需要确定是正样本还是负样本,同时计算与对应真实物体的偏移量。在实际实现时为了方便,这一步往往与RPN最后筛选ROI那一步放在一起
- RCNN loss:通过RCNN的预测值与ROI部分的真值,计算分类与回归loss
二、两大网络——RPN和RCNN
1.RPN
RPN的输入:feature map、物体标签
输出:Proposal、分类Loss、回归Loss。其中Proposal用于后续模块的分类与回归,两部分损失用于优化网络。
RPN具体原理如下图:
这里的sliding Window实际上就是对特征图做了3*3的卷积操作。
对于物体检测任务,模型需要预测每一个物体的类别及其出现的位置,由于有了Anchor这个先验框,RPN可以预测Anchor的类别作为预测边框的类别,并且可以预测真实的边框相对于Anchor的偏移量,而不是直接预测边框的中心点坐标。而RPN每次输出有两个分数,分别是物体的分数和背景的分数,4个坐标,也就是针对原图像的偏移。
对于分数的判断,RPN通过计算Anchor和标签的IOU来判断一个Anchor是属于前景还是背景。关于IOU的介绍可以看之前的文章
https://blog.csdn.net/qq_46738367/article/details/125059765?spm=1001.2014.3001.5501
当IOU大于一定值时,该Anchor的真值为前景,低于一定值时,该Anchor为背景。
在通过RPN分类与回归网络得到模型的预测值后,为了计算预测的损失,需要得到分类与偏移预测的真值。具体步骤为:生成全部Anchor→Anchor与Gt匹配打标→Anchor筛选→求解偏移真值
生成Anchor前面已做介绍,下面主要说明后面三步
1.标签匹配:为了计算Anchor的损失,在生成Anchor后还需要得到每个Anchor的类别,由于RPN的作用是生成建议框,因此只需要区分正样本和负样本就可以了。具体的区分标准为:
- 对于任何一个Anchor,与所有标签的IOU小于0.3则视为负样本
- 对于任何一个标签,与其有最大IOU的Anchor视为正样本
- 对于任何一个Anchor,与所有标签的IOU大于0.7则视为正样本
2.Anchor的筛选:由于Anchor的数量接近两万(37509=16650),并且大部分Anchor的标签都是背景,如果都计算损失的话会使正负样本失去均衡,不利于网络的收敛。因此RPN默认选用256个Anchor进行损失的计算,其中最多不超过128个正样本,如果数量超过限定值,就进行随机选取。
3.求解回归偏移真值:前面第二步在真实边框与锚框匹配时,已经将每个Anchor赋予正样本或者负样本代表了预测类别的真
值,当然锚框的标签属于负样本的话。是不参与计算回归损失的。现在我们需要知道那些标签为正样本的锚框与真实边框的偏移值,以便后面计算回归损失,具体公式见偏移量的真值。
得到偏移量的真值后,将其保存在bbox_targets中。与此同时, 还需要求解两个权值矩阵bbox_inside_weights和bbox_outside_weights,前者是用来设置正样本回归的权重,正样本设置为1,负样本设置为0,因为负样本对应的是背景, 不需要进行回归; 后者的作用则是平衡RPN分类损失与回归损失的权重。
2.RCNN全连接网络
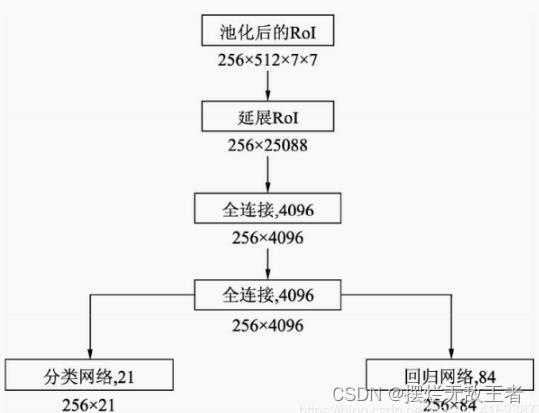
接下来利用VGGNet的两个全连接层,得到长度为4096的256个RoI特征。为了输出类别与回归的预测,将上述特征分别接入分类与回归的全连接网络。在此默认为21类物体,因此分类网络输出维度为21,回归网络则输出每一个类别下的4个位置偏移量,因此输出维度为84。
值得注意的是,虽然是256个RoI放到了一起计算,但相互之间是独立的,并没有使用到共享特征。什么意思呢?这是指送入最后的分类网络和回归网络的特征大小是(batch,256, 4096),是三个维度的数据,而不是我们通常认为两个维度的数据,这相当于训练了256个全连接层,输入大小是4096,输出是21(或者是84),而按我们直觉上只需要训练一个就够了,因此说其造成了重复计算。这也是FasterRCNN的一个缺点。
三、ROI Pooling
ROI Pooling作用是将各种大小宽高不同的Anchor生成的ROI变换成维度相同的特征,便于输入上面的RCNN全连接网络中进行分类与回归预测量的计算。
例如输入的feature map为: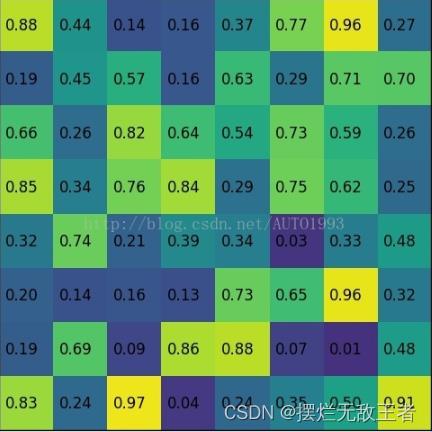
region proposal投影为:

将其划分为(22)个sections(因为输出大小为22),我们可以得到:
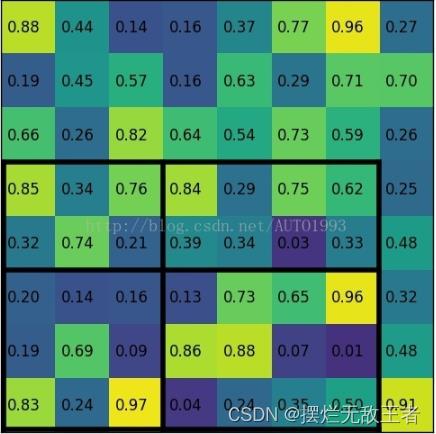
对每个section进行最大池化可以得到:

以上是关于Faster RCNN学习笔记的主要内容,如果未能解决你的问题,请参考以下文章
深度学习Caffe实战笔记(19)Windows平台 Faster-RCNN 制作自己的数据集
Py-faster-rcnn/lib/nms/nms_kernel.cu的学习笔记