性能优化方法论系列三性能优化的核心思想
Posted 明明如月学长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能优化方法论系列三性能优化的核心思想相关的知识,希望对你有一定的参考价值。
3.1 增加资源
3.1.1 增加机器
比如由单个 WEB 服务器来响应用户请求,改为通过 nginx 等负载均衡工具将请求分发到多台服务器。

这就相当于原本店铺里只有一个服务员,一个服务员同时只能接待 5 位客人,现在又多招聘几个服务员,这样能够同时接待顾客数量会更多一些。

或者为集群添加更多机器。
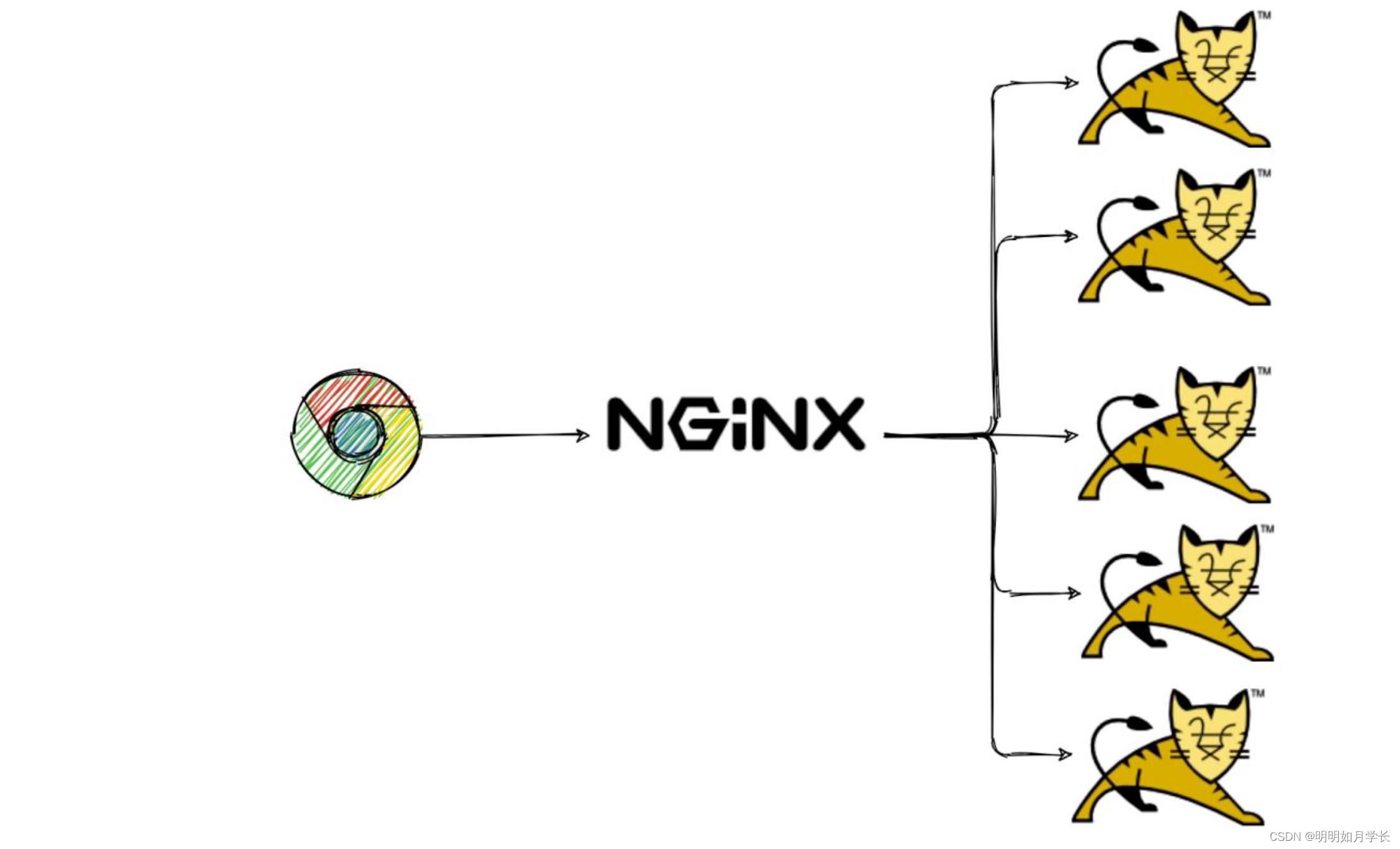
通常很多站点都会在某些大型活动(如限时秒杀、微博热帖、高考查成绩、热门直播等)前或过程中,通过手动或者自动“扩容” 增加更多机器的方式来支撑更多流量。
3.1.2 升级配置
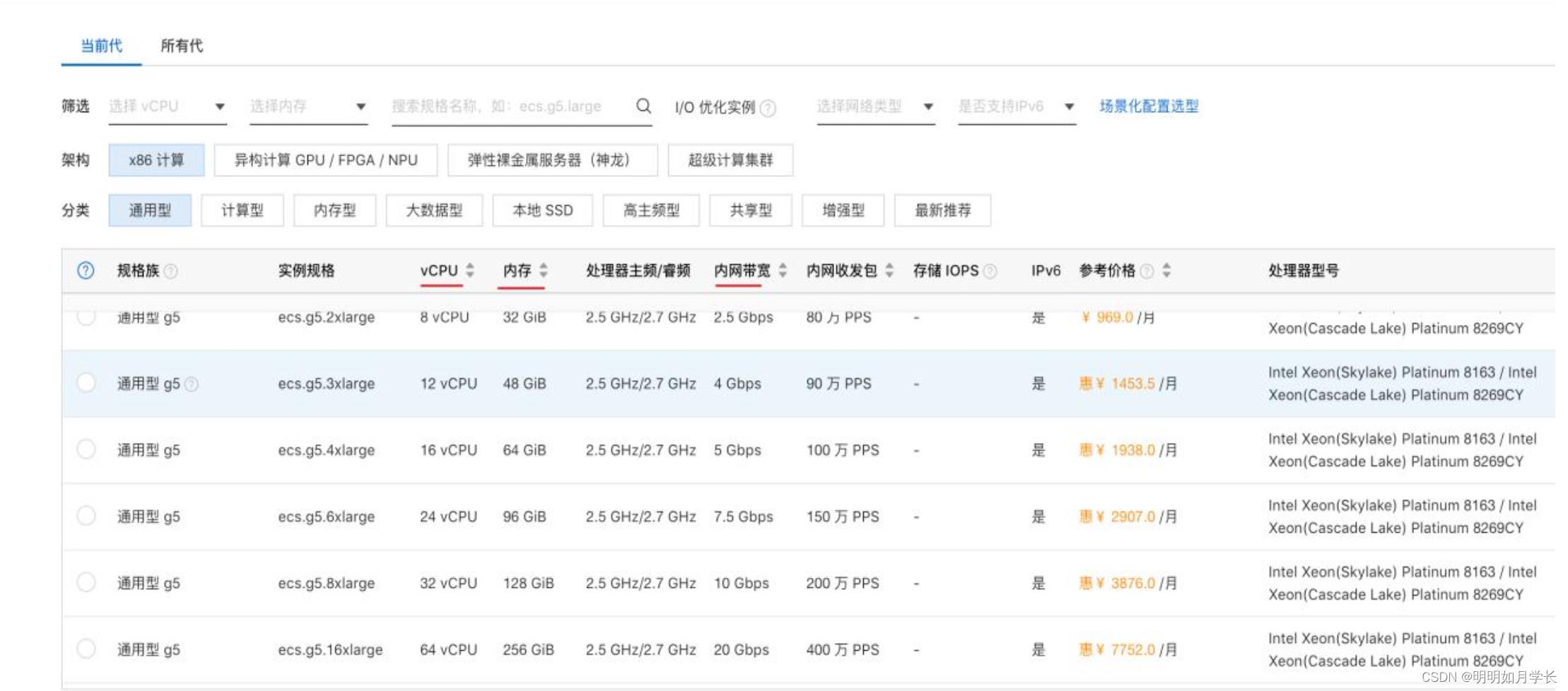
增加配置,通常是更换性能更好的 CPU、增加内存、增加宽带、使用固态硬盘、增加磁盘空间等。
下图为阿里云购买服务器页面的截图,其中的选项就是配置相关的关键指标。
3.2 减少耗时操作
要提高性能,通常需要减少操作的耗时。想要减少耗时,就要了解常见传输媒介的耗时情况。
下图为各种操作的时间量级参考表:
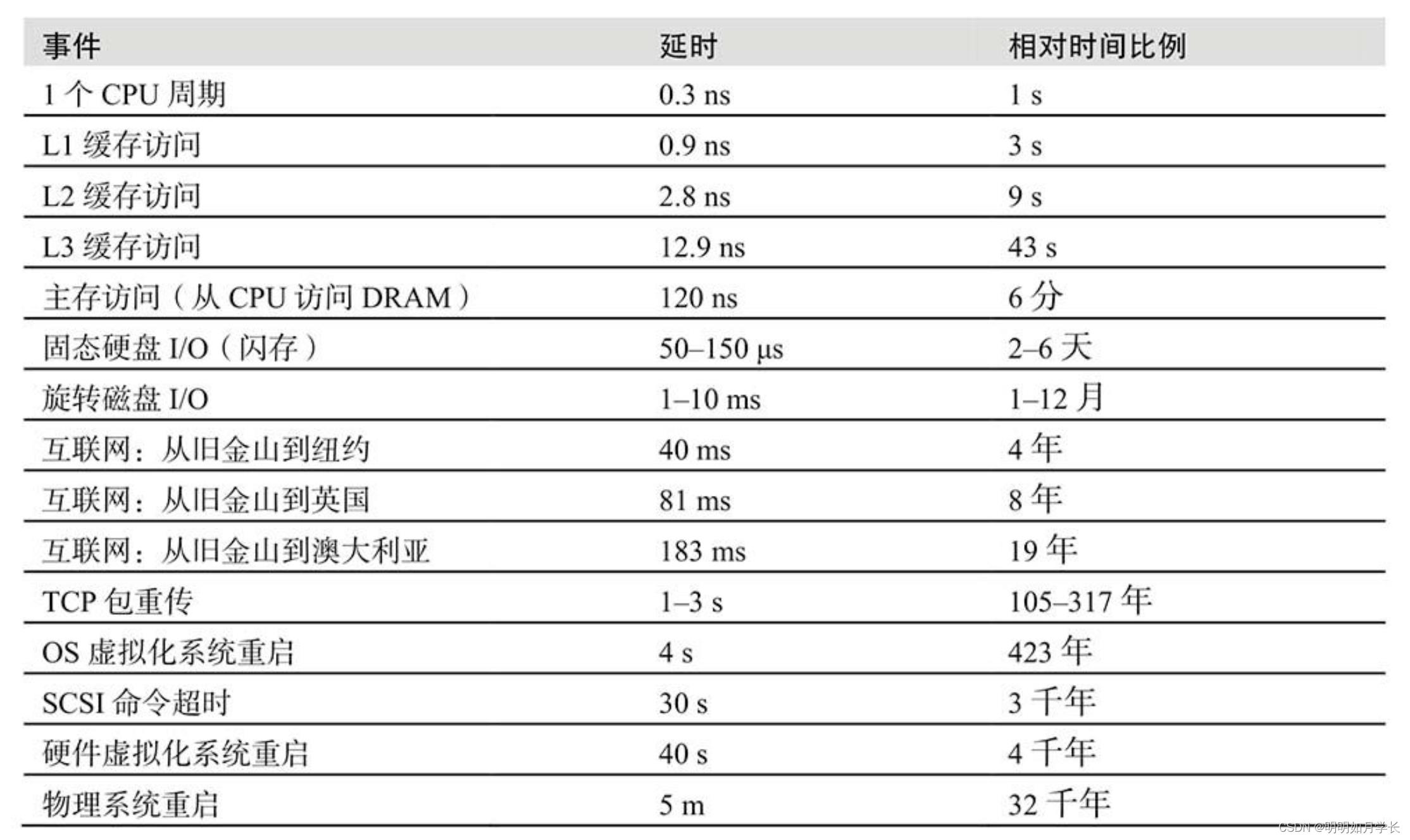
(图片来源:《性能之巅》[1])
这张图是我们后续很多性能优化方法的主要依据。
3.2.1 合并操作(化零为整)
合并操作是性能优化非常典型和重要的思想。
比如渲染某个前端页面,前端需要请求多个 js 文件,可以将多个 js 文件合并成一个,来减少向服务端发起请求的次数。
比如后端服务在某个请求中需要构造不同的请求,多次调用同一个二方接口,此时,可以使用批量查询接口,而不是 for 循环中执行单个请求再去处理。
如下图所示,某个功能,需要在循环中请求十几次甚至几十次二方或者三方接口 :

假设每次耗时100ms, 请求 20次,就是 2 秒钟。
如下图所示,可以通过调用批量接口,发起一次网络请求获取十几条数据或者几十条数据:

同样的功能,可能 100 ms 更多一点就搞定了。
很多中间件在设计时,也会提供一些批量接口。
如 hbase-client 中就提供了批量查询接口:
org.apache.hadoop.hbase.client.Table#get(java.util.List<org.apache.hadoop.hbase.client.Get>)

再如 Redis 中的 mget 命令,可以批量获取 key 的值。
ES 中也提供了 mget 批量查询 api。
大家都知道 IO 操作通常和读写内存、CPU缓存等相比非常耗时,如果想进行性能优化,就要考虑减少 IO 操作。

那么我们可以将多个写操作先写到内存缓冲区中,达到一定的条件再落盘。

Java 中也提供了如 java.nio.ByteBuffer 和 java.io.BufferedOutputStream 等。
下面是 BufferedOutputStream 的源码注释:

从注释中也可以看出,应用可以使用该类将字节写入到这里,而不是每个字节都调用底层写入方法,本质上就是合并请求。
mysql 、Elasticsearch 等很多存储相关的功能都用到了“缓冲区”的思想。
以 Elasticsearch 为例,索引是映射类型的容器,一个 ES 索引是独立的一个大量文档的集合。每个索引存储在磁盘上的同组文件中,索引存储了所有映射类型的字段和设置。如下图所示,数据先存储到内存缓存功能区中,当 refresh 发生时,数据被提交到 segment 然后可被搜索,每个索引可以设置 refresh 间隔,可以通过 refresh_interval 参数控制。

由于 refresh 的耗时相对较长,可以通过控制刷盘的间隔来提高性能。而这个时间间隔的设置需要进行权衡,如果设置间隔太久,会导致新的数据需要很久才可被搜索到,影响用户体验;设置的时间太短,造成性能损耗。
“当一条数据需要更新时, InnoDB 引擎就会先把记录写到 redo log里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面”[2]。也是通过合并的方式减少写盘次数进而优化性能。
HBase 中每次刷新 memstore 都会产生新的 HFile,由于 HFile 存储在磁盘上,就需要寻址操作。传统的硬盘寻址较慢, HFile 多了之后寻址操作就增多,效率就不高。为了防止 HFile 过多,同时为了减少碎片,HBase 会执行一些合并操作。
3.2.2 压缩
对要存储或传输的数据进行压缩,可以减少资源占用,提高传输速率。
比如前端可以对 js 或者 css 文件进行压缩,来减少传输的数据量,加快资源加载速度。
也可以在使用资源时,默认对资源自动压缩。
如通过微信发送图片或者视频时,默认会自动压缩,必要时可以选择原图进行发送。

查看时只加载预览图,在必要时可以选择查看原图或者选择清晰度更高的视频。如 QQ 空间相册、爱奇艺/ B 站等视频的清晰度切换等。

比如后端可以对将要存储到 redis 中的大段文本数据进行压缩,然后再存储,使用前再解压。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j7rc2D8O-1657205677931)(http://r5sutk2yq.bkt.clouddn.com/img-image-20220204231036182.png)]
3.2.3 复用
复用是减少资源使用的非常经典的方式。包括 各种连接池、线程池在内的对象池模式是复用典型应用。
它们的核心思想都是重用和共享创建代价比较昂贵的对象。
其结构如下:

基本思想:当客户端需要资源时,向资源池发起申请,资源池检查后获取第一个可用资源给客户端使用;客户端使用后归还资源到资源池重复使用。
比如 Http 长连接就是在同一个连接中发起多次请求来提高性能的; 数据库连接池,也是通过复用连接来提高性能的模式。
3.2.4 减少 IO 操作
下面只是给出几个实际中常见的具体案例,大家要根据实际情况进行举一反三。
减少不必要的调用
有时,前端由于架构设计不够合理等原因,会进行一些没有必要的同步调用,造成响应时间无辜被拖长。
此时,需要去掉不必要的调用(尤其是同步调用)。
做新的项目时,有时候需要协调多个下游,如果有些接口没有必要调用,就要减少调用。
如果有些接口应该是你的下游给封装起来的,下游的服务应该对其进行封装,避免造成上游进行不必要的接口调用。

调用额外的接口增加耗时,而且很多场景下不符合迪米特法则。
减少不必要的日志输出
大家在编写代码时,可能会(同步)打印一些没有必要的大文本日志,当请求量较多时也会影响性能,影响系统响应时间或者浪费存储空间。
因此建议大家只打印必要的日志,对于大对象只打必要的字段。
减少不必要的转换
比如有时候需要将内存对象持久化到一些 KV 存储中,由于有些序列化方式需要实现序列化接口,而有些对象没有实现序列化接口从而不支持某种二进制序列化方式,有些人会选择先进行 JSON 序列化成字符串然后再进行存储,这样做性能很差。
如果 KV 存储要求实现序列化接口,如果想要序列化没有实现序列化接口的二方或者三方 jar 包中的类,可以定义一个具有相同属性的类,转换后再进行序列化。

3.2.5 减少上下文切换
频繁地上下文切换也会造成性能损耗。
有些场景下使用多线程执行,由于频繁地上下文切换造成性能损耗反而比使用单线程耗时更长。
自旋锁是减少上下文切换的一个优化案例。
如果有一个以上处理器,能让两个或者以上的线程同时并行执行,可以让后面请求锁的线程“稍等一下”,不放弃处理器的执行时间,看看持有锁的线程是否很快就释放。如果自旋超过限定的次数仍然没有成功获取锁,就应当使用传统的方式挂起线程。
3.2.6 减少操作指令
大家在看一些框架源码时,可能会见到类似下面的写法:

可能有些朋友会好奇,为啥要定义一个局部变量 data 呢?
为什么不像下面这么写呢?
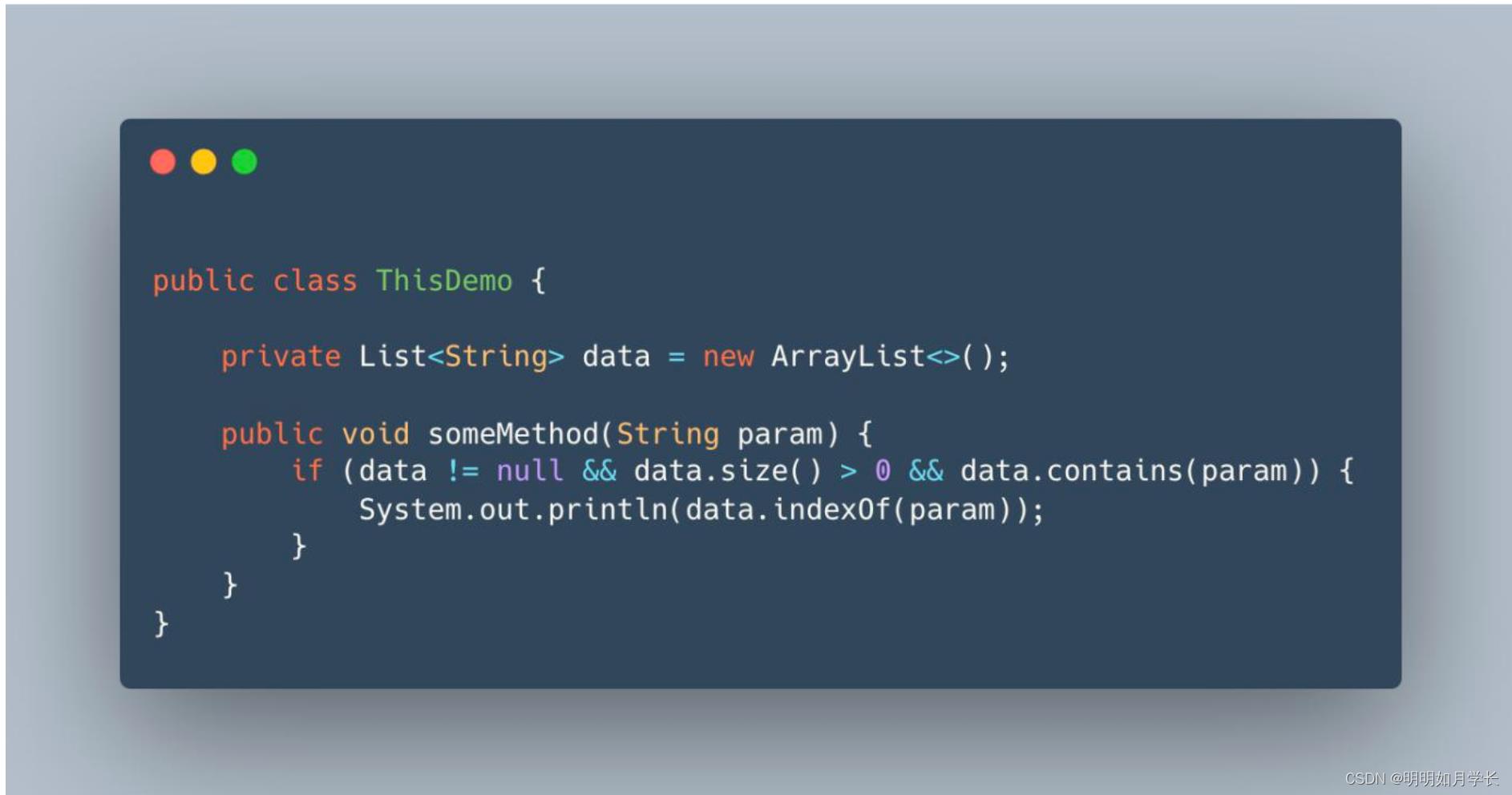
大家动手用 javap 进行反汇编之后你会发现,如果当前函数多次使用 data 时,第一种写法指令更少。
第一种写法,第一次将 data 对象存储到当前栈帧的局部变量表中,使用时直接从局部变量表中获取,而第二种写法需要先装载 this 然后通过 getfield 方法来获取属性。
想了解详细内容,可以参考我一篇专题文章:《为什么推荐大家学习 Java 字节码》
有些前置判断应该尽量放在靠前的位置,避免做了一些列不必要的操作。
伪代码如下:

3.2.7 合理设置等待时间
执行远程接口调用时,要设置合理的等待时间。
如果等待的时间过长,那么即使能够获得数据,也很影响用户体验。与其这样,比如设置用户能够接受的超时时间,超时时让用户重试。
创作不易,如果本文对你有帮助,欢迎点赞、收藏加关注,你的支持和鼓励,是我创作的最大动力。

以上是关于性能优化方法论系列三性能优化的核心思想的主要内容,如果未能解决你的问题,请参考以下文章