NLP下的bert模型的一些学习
Posted CR1820
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP下的bert模型的一些学习相关的知识,希望对你有一定的参考价值。
自然语言处理NLP
最近在着手一个跨模态情绪识别项目中自然语言处理 在经过训练LSTM与Bert两款模型后 发现Bert是真的强 BERT是2018年10月由Google AI研究院提出的一种预训练模型。BERT在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩: 全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA表现,包括将GLUE基准推高至80.4% (绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就。
此文章基于 https://www.bilibili.com/video/BV1tG411x7yq?p=12&spm_id_from=pageDriver&vd_source=606928d0775e26f8833c726f83b3abd3
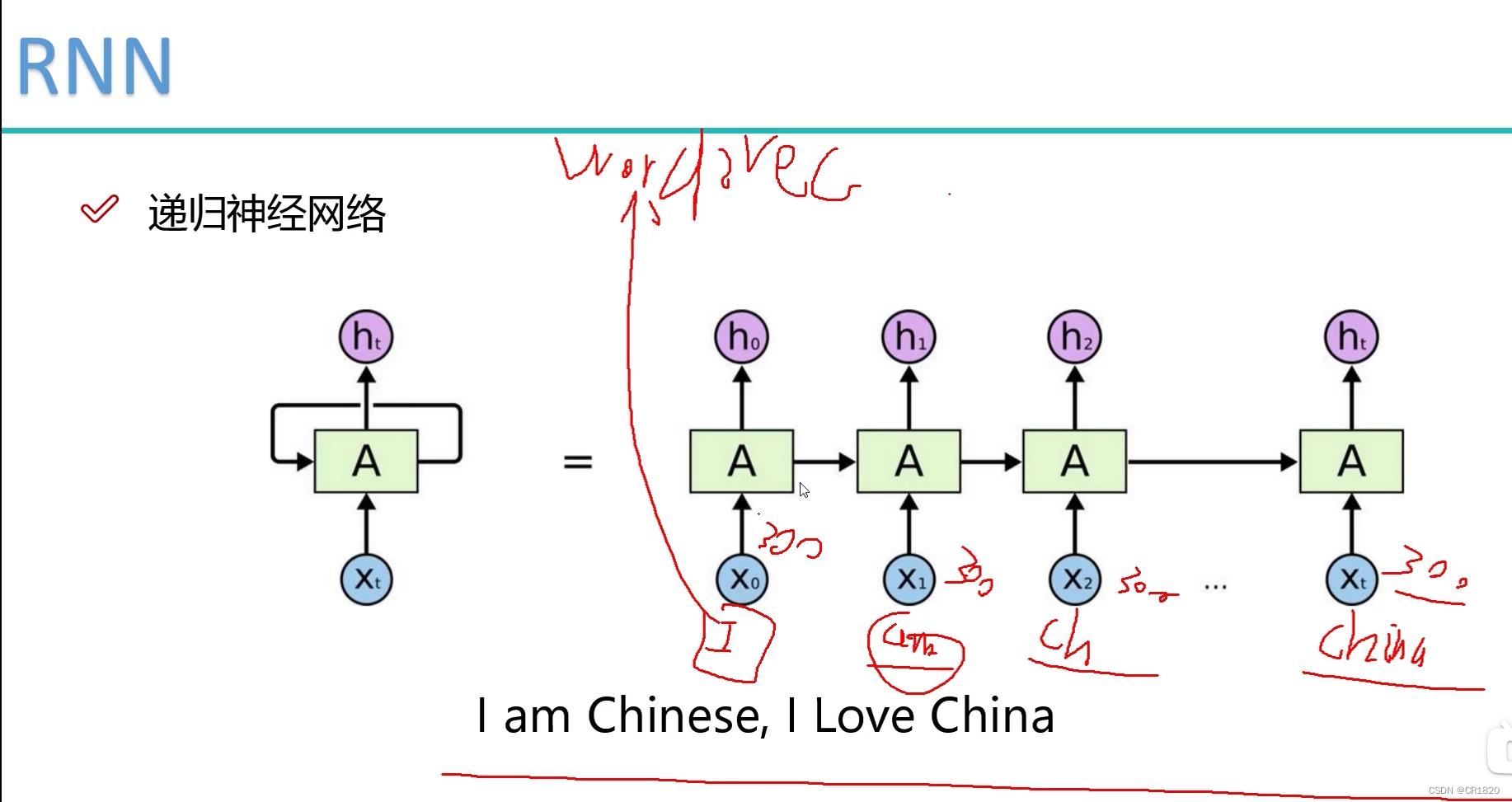
RNN适用于NLP CNN适用于CV
一句话中 前面的单词会对后面的单词产生影响 存在时间序列 同时记录前面的所有中间结果
串行工作 无法并行工作---->transformer可以并行
LSTM
存在过滤判断
词向量模型–Word2vec
-
词义相近的词在词向量空间中靠的越近
-
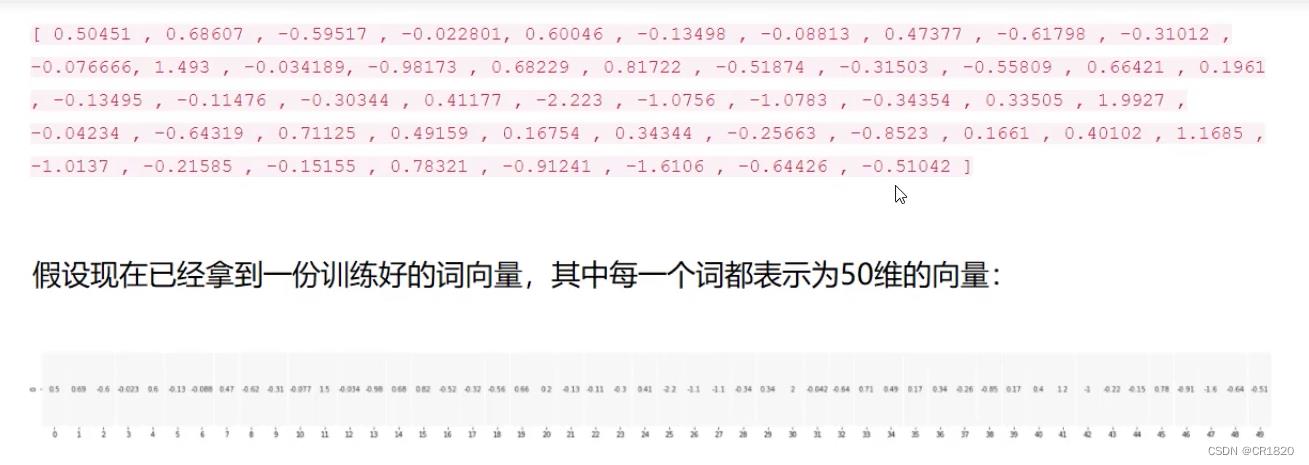
词向量的维度较高 (50-300)来描述词语 300最好 词向量可以用来求相似度
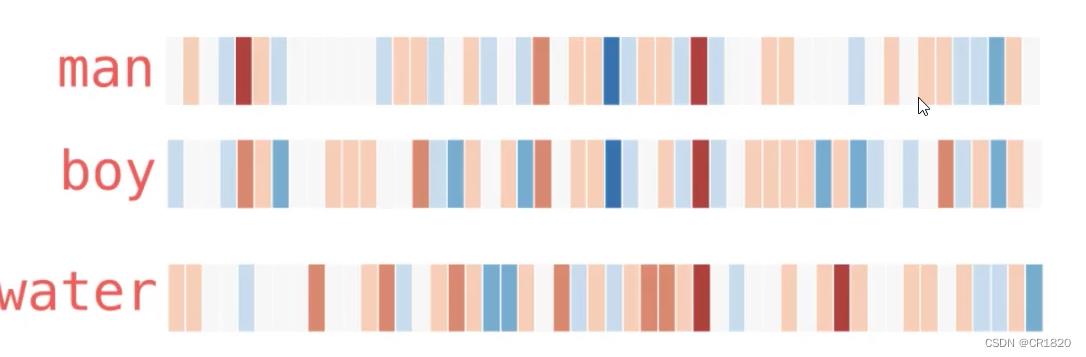
此处可以发现man和boy在些许地方是相似的
-
输入输出
- 我喜欢电影-----输入我+喜欢 训练神经网络输出电影
- 实际上是一个分类任务 输入我+喜欢 通过神经网络---->多个词语 输出概率最大的一个 torch.argmax(会存在问题 问题在后面会说到)
-
神经网络
- 每个词进来 去look up embeddedings(词语大表)找到对应的n维词向量
- look up embeddedings是随机初始化的 前向传播计算loss_fn 反向传播更新权重参数
- 在这个模型中 经过无数次训练后 每个词都进行了更新
-
构建训练数据 I think the film is great
-
存在滑动窗口 I think the 输入I think 输出the
-
think the film 输入think the 输出film
-
.训练模型有很多:输入上下文输出中间词 输入中间词输出上下文
-
-
问题
- 分类任务 输入我+喜欢 通过神经网络---->多个词语 输出概率最大的一个 torch.argmax运算量巨大
- 改进1:输入输出一起输入–>target 1 0
- 改进1问题:所有标签都是1 效果不好
- 改进2:缺少0 输入I think 输出the 让他输出happy---->0(负样本) 人为创造0 负样本
transformer神经网络
最重要的在于对每一个词 都需要考虑上下文的语境
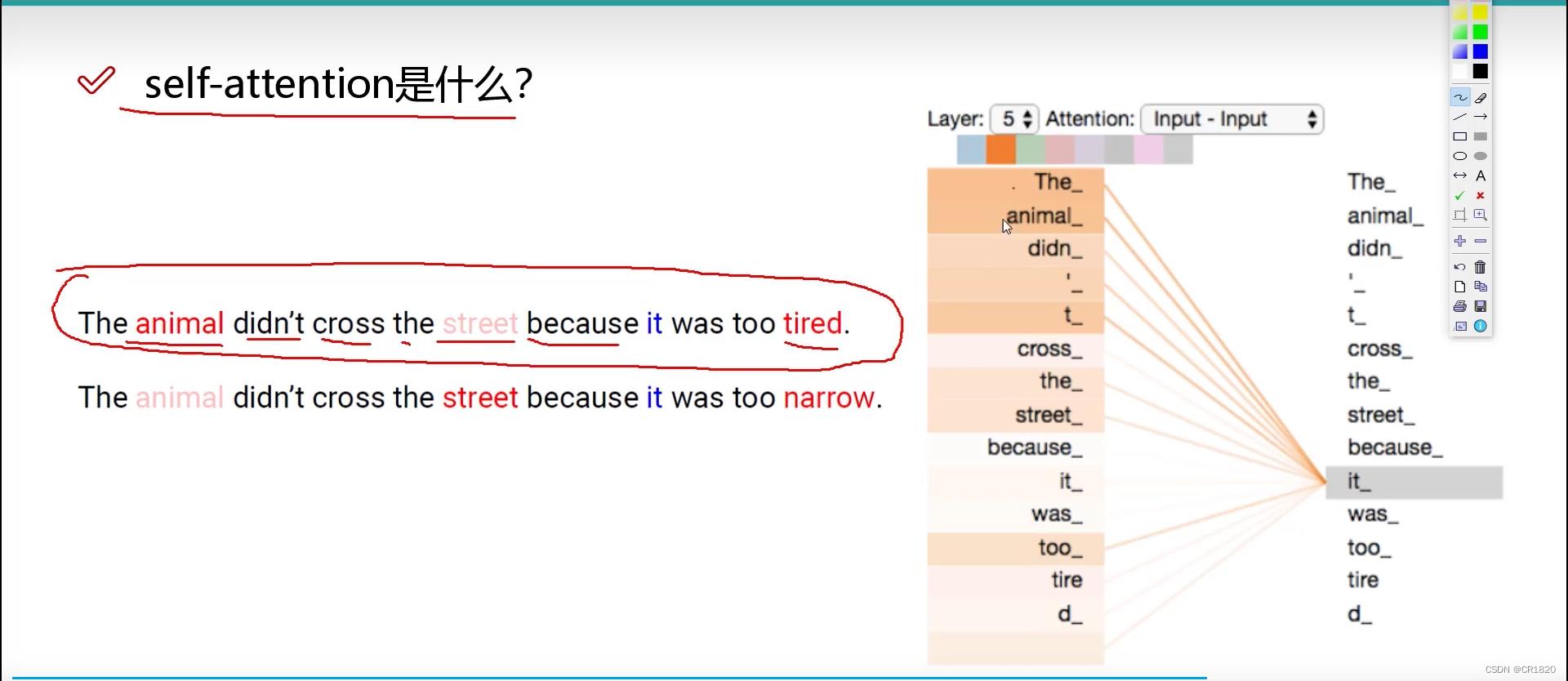
self-attention机制
给词作编码时 上下文的文本信息加到该词的词向量中 分配权重
计算
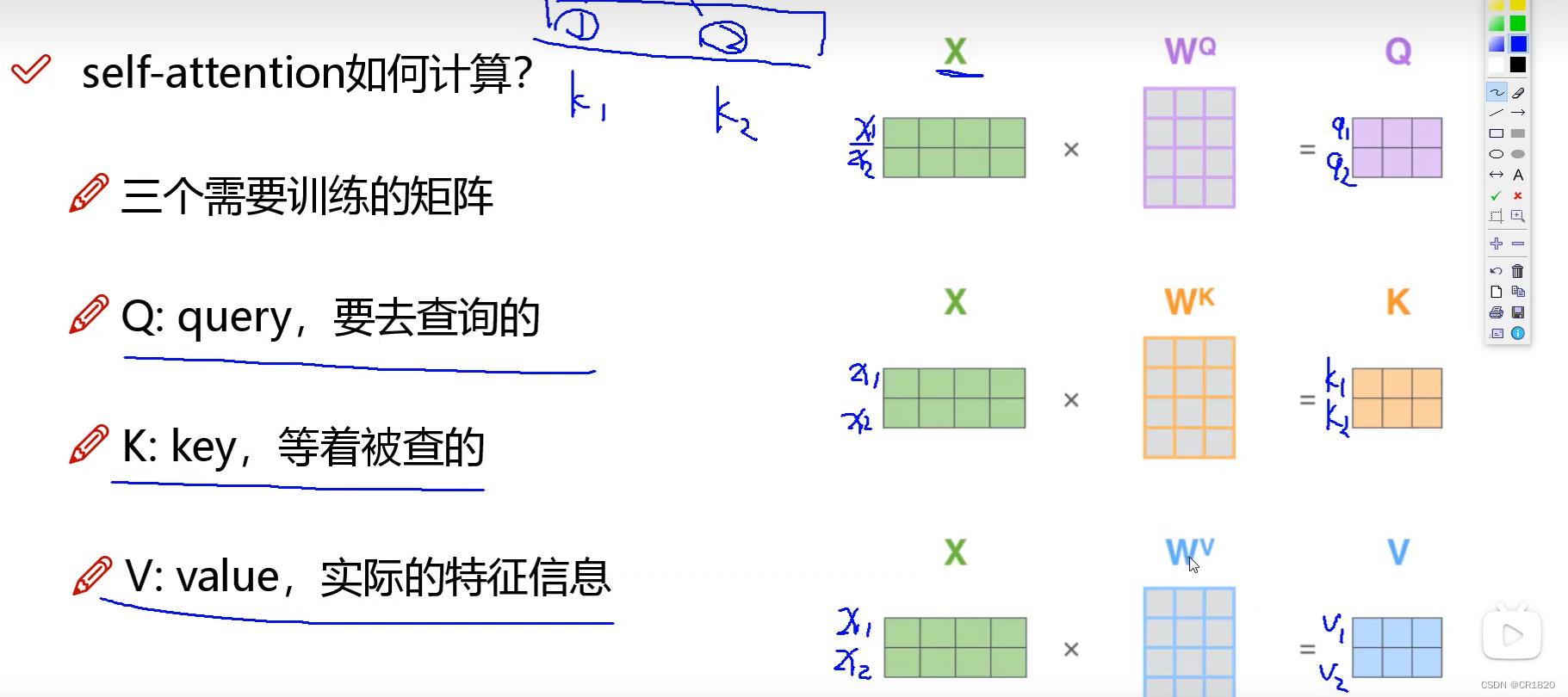

eg.计算 想要去查询第一个与其他的关系 查询第一个–>q1 其他的是被查询–>k1 k2…
然后去做内积 内积若为0 则垂直–>没有关系 内积越大 则相关程度越大 就需要分配更多的权重
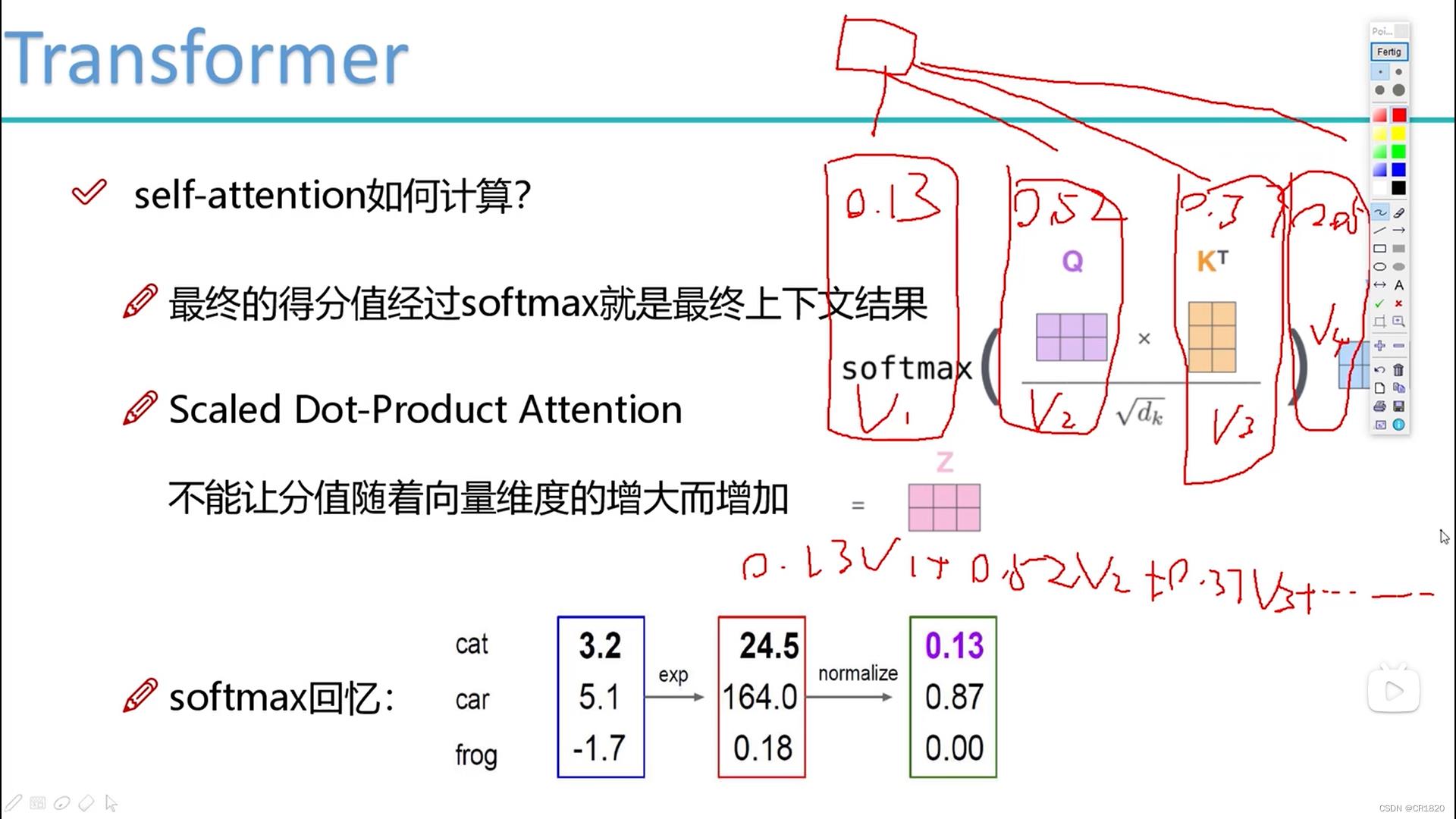
softmax归一化返回权重 然后去×对应的v向量
总体流程

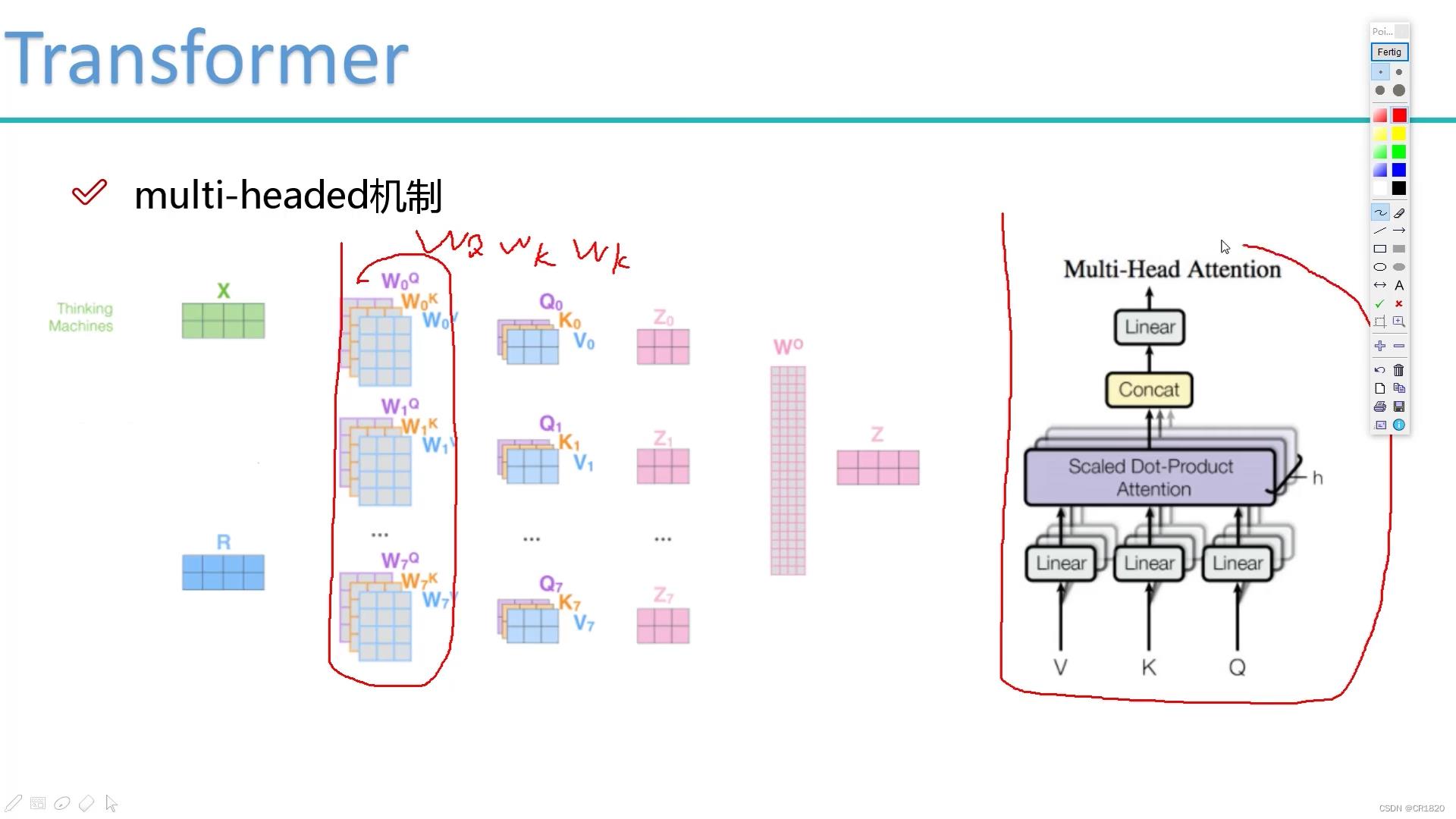
multi-headed多头机制
多个head 多组qkv得到多个特征z 所有特征拼接在一起 通过一层全连接层降维 可以有多层
位置信息表达
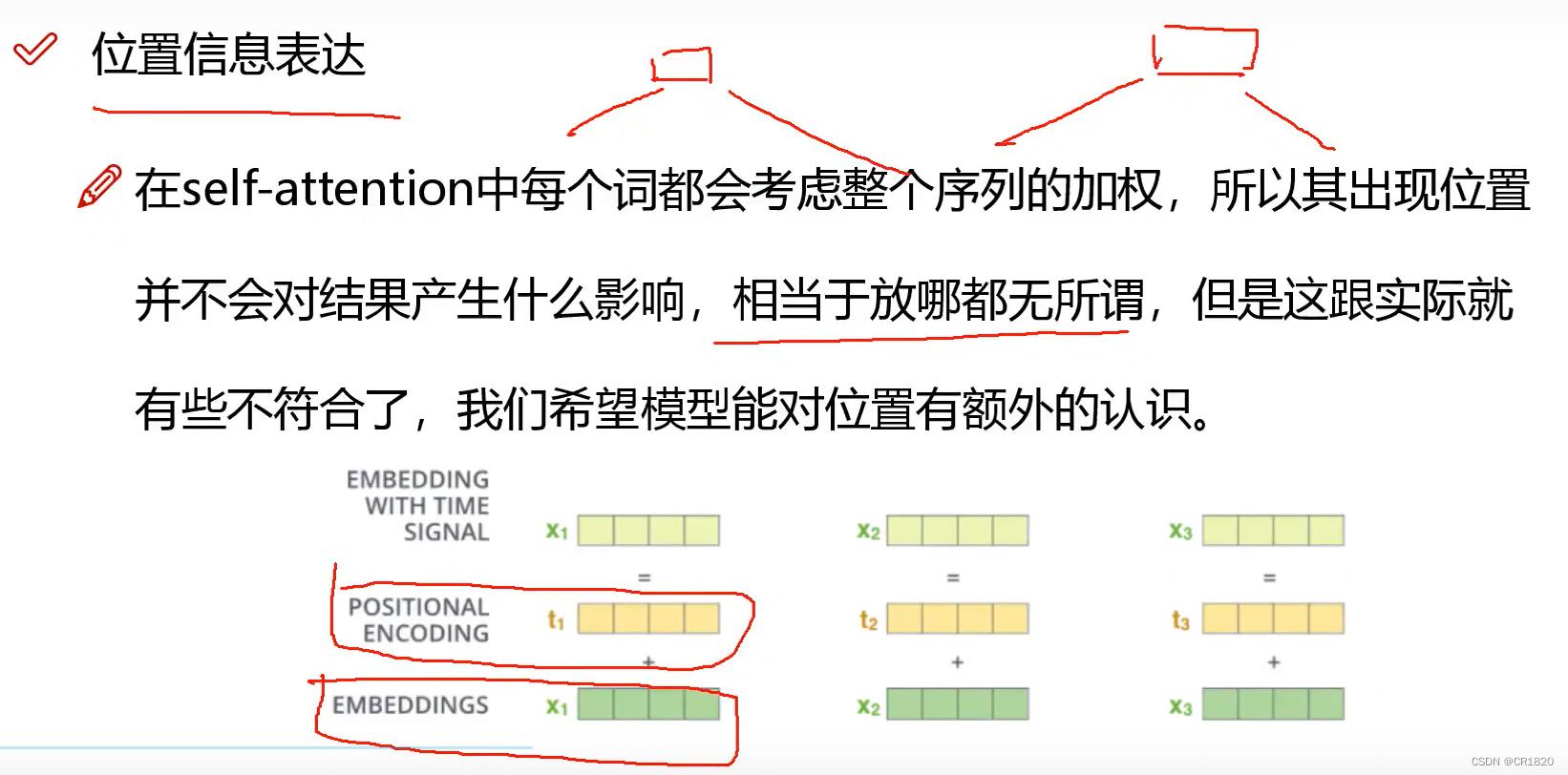
positional encoding在attention is all you need原文中 使用正余弦周期函数
transformer整体梳理
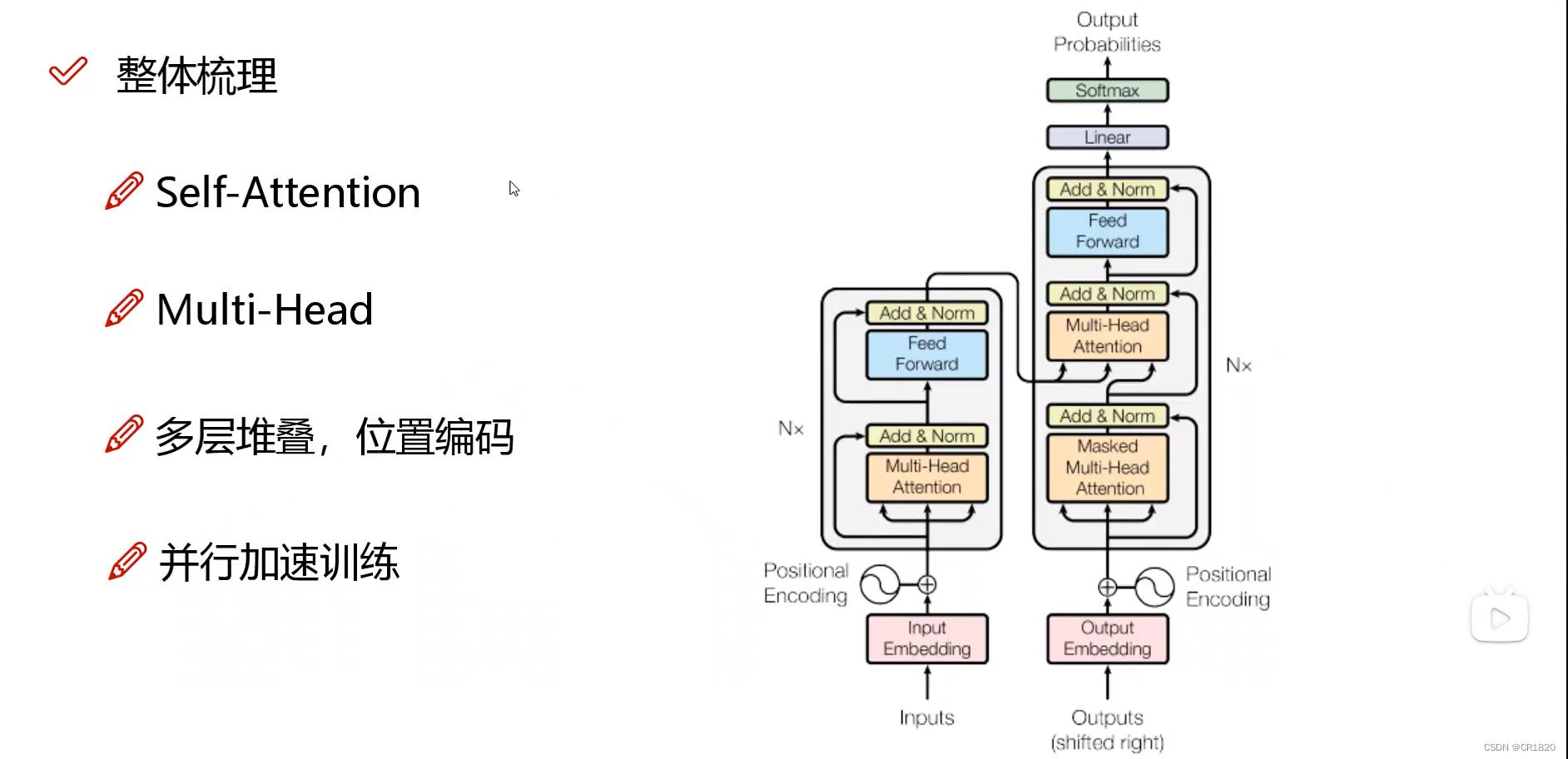
1.输入 输入一个句子inputs 把里面的词语拿出来(根据任务不同 语言不同视情况而定)直接使用bert的预训练模型 得到embedding 并加入周期信号编码
2.做n层的多头self-attention
3.在层数堆叠的过程中 可能效果变差 此处使用残差连接 确保两条路
4.右侧仅仅是多出mask机制
最重要的在于self-attention机制
bert模型 Bidirectional Encoder Representations from Transformer
bert模型基于transformer网络结构的训练
这主要解决得到特征
方法一 mask机制
句子中有15% 的词汇被随机mask掉 交给模型去预测被mask的是什么
方法二:预测两个句子是否应该连在一起
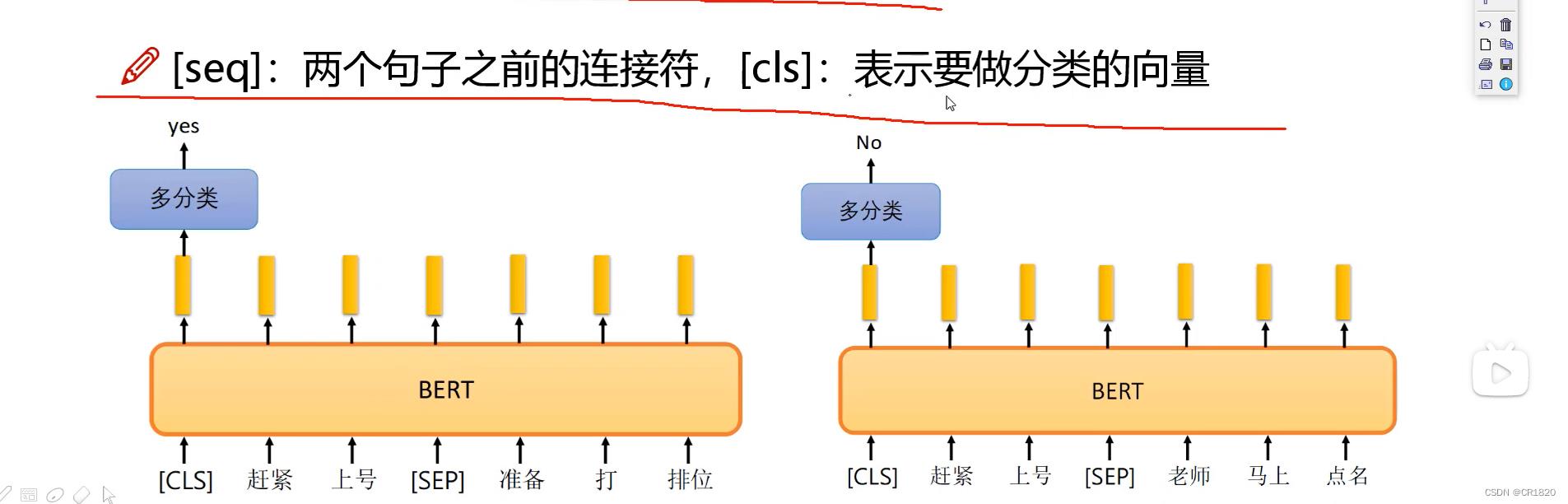
cls做编码时要考虑其他所有字符 最后cls做二分类(判断两句话是否应该连在一起)
以上是关于NLP下的bert模型的一些学习的主要内容,如果未能解决你的问题,请参考以下文章
ACL 2021|美团提出基于对比学习的文本表示模型,效果相比BERT-flow提升8%