龙蜥社区开源 coolbpf,BPF 程序开发效率提升百倍
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了龙蜥社区开源 coolbpf,BPF 程序开发效率提升百倍相关的知识,希望对你有一定的参考价值。

引言
BPF 是一个新的动态跟踪技术,目前这项技术正在深刻的影响着我们的生产和生活。BPF 在四大应用场景发挥着巨大作用:
- 系统故障诊断:它可以动态插桩透视内核。
- 网络性能优化:它可以对接收和发送的网络包做修改和转发。
- 系统安全:它可以监控文件打开和关闭从而做出安全决策等。
- 性能监控:它可以查看函数耗费时间从而知道性能瓶颈点。
BPF 技术也是随着 Linux 内核的发展而发展的,Linux 内核版本经历了 3.x 向 4.x 到 5.x 演进,eBPF 技术的支持也是从 4.x 开始更加完善起来,特别是 5.x 内核也增加了非常多的高级特性。但是云上服务器有大量的 3.10 内核版本是不支持 eBPF 的,为了让我们现有的 eBPF 工具在这些存量机器得以运行,我们移植了 BPF 到低版本内核,同时基于 libbpf 的 CO-RE 能力,保证一个工具可运行在 3.x/4.x/5.x 的低、中、高内核版本。
BPF 的开发方式有很多,当前比较热门的有:
1)纯 libbpf 应用开发:借助 libbpf 库加载 BPF 程序到内核的方式:这种开发方式不仅效率低,没有基础库封装,所有必备步骤和基础函数都需要自己摸索。
2)借助 BCC等开源项目:开发效率高、可移植性好,并且支持动态修改内核部分代码,非常灵活。但存在部署依赖 Clang/LLVM 等库; 每次运行都要执行 Clang/LLVM 编译,严重消耗 CPU、内存等资源,容易与其它服务争抢。
coolbpf 项目,以 CO-RE(Compile Once-Run Everywhere)为基础实现,保留了资源占用低、可移植性强等优点,还融合了 BCC 动态编译的特性,适合在生产环境批量部署所开发的应用。coolbpf 开创了一个新的思路,利用远程编译的思想,把用户的BPF程序推送到远端的服务器并返回给用户.o或.so,提供高级语言如 Python/Rust/Go/C 等进行加载,然后在全量内核版本安全运行。用户只需专注自己的功能开发,不用关心底层库(如 LLVM、python 等)安装、环境搭建,给广大 BPF 爱好者提供一种新的探索和实践。
一、BPF 开发方式对比
BPF 经历了传统的 setsockopt 方式的 sock filter 报文过滤,到如今使用 libbpf CO-RE 方式进行监控和诊断功能的开发,是和 eBPF 与硬件紧密结合的优秀的指令集能力及 libbpf 通用库的开源开放分不开的,让我们一同回顾一下 BPF 的开发方式,并在此基础上推出基于远程编译思想为核心的 coolbpf,它站在了巨人的肩膀上,进行了资源优化、简洁编程和效率提升。
1、原始阶段
在 BPF 还叫伯克利报文过滤(cBPF)的时候,它通过 sock filter 将原始的 BPF 指令码,利用 setsockopt 加载到内核,通过 setsockopt 加载到内核,通过在 packet_rcv 调用 runfilter 运行这段程序来进行报文过滤。这种方式,BPF 字节码的生成非常原始,类似于手工编写汇编程序,过程是非常痛苦的。
static struct sock_filter filter[6] =
OP_LDH, 0, 0, 12 , // ldh [12]
OP_JEQ, 0, 2, ETH_P_IP , // jeq #0x800, L2, L5
OP_LDB, 0, 0, 23 , // ldb [23]
OP_JEQ, 0, 1, IPPROTO_TCP , // jeq #0x6, L4, L5
OP_RET, 0, 0, 0 , // ret #0x0
OP_RET, 0, 0, -1, , // ret #0xffffffff
;
int main(int argc, char **argv)
…
struct sock_fprog prog = 6, filter ;
…
sock = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL));
…
if (setsockopt(sock, SOL_SOCKET, SO_ATTACH_FILTER, &prog, sizeof(prog)))
return 1;
…
2、保守阶段
例子为 samples/bpf 下面的 sockex1_kern.c 和 sockex1_user.c,代码分为两部分,通常命名为 xxx_kern.c 和 xxx_user.c,前者加载到内核空间中执行,后者在用户空间执行。BPF 程序编写完成后就通过 Clang/LLVM 进行编译,xxx_user.c 里显式的去加载生成的 xxx_kernel.o 文件。这种方式虽然使用了编译器支持自动生成了 BPF 字节码,但代码组织和 BPF 加载方式比较保守,用户需要写非常多的重复代码。
struct
__uint(type, BPF_MAP_TYPE_ARRAY);
__type(key, u32);
__type(value, long);
__uint(max_entries, 256);
my_map SEC(".maps");
SEC("socket1")
int bpf_prog1(struct __sk_buff *skb)
int index = load_byte(skb, ETH_HLEN + offsetof(struct iphdr, protocol));
long *value;
if (skb->pkt_type != PACKET_OUTGOING)
return 0;
value = bpf_map_lookup_elem(&my_map, &index);
if (value)
__sync_fetch_and_add(value, skb->len);
return 0;
char _license[] SEC("license") = "GPL";
int main(int ac, char **argv)
struct bpf_object *obj;
struct bpf_program *prog;
int map_fd, prog_fd;
char filename[256];
int i, sock, err;
FILE *f;
snprintf(filename, sizeof(filename), "%s_kern.o", argv[0]);
obj = bpf_object__open_file(filename, NULL);
if (libbpf_get_error(obj))
return 1;
prog = bpf_object__next_program(obj, NULL);
bpf_program__set_type(prog, BPF_PROG_TYPE_SOCKET_FILTER);
err = bpf_object__load(obj);
if (err)
return 1;
prog_fd = bpf_program__fd(prog);
map_fd = bpf_object__find_map_fd_by_name(obj, "my_map");
...
3、BCC 初始阶段
BCC 的出现打破了保守的开发方式,出色的运行时编译和基础库封装能力,极大的降低了开发难度,有了不少迷妹,然后开始攻城略地,类似资本的快速扩张。用户只需要在 Python 程序里 attach 一段 prog ,然后进行数据分析和处理,缺点是必须在生产环境上安装 Clang 和 python 库,运行时有 CPU 资源瞬时冲高,导致出现加载 BPF 程序后问题不复现的可能。
int trace_connect_v4_entry(struct pt_regs *ctx, struct sock *sk)
if (container_should_be_filtered())
return 0;
u64 pid = bpf_get_current_pid_tgid();
##FILTER_PID##
u16 family = sk->__sk_common.skc_family;
##FILTER_FAMILY##
// stash the sock ptr for lookup on return
connectsock.update(&pid, &sk);
return 0;
# initialize BPF
b = BPF(text=bpf_text)
if args.ipv4:
b.attach_kprobe(event="tcp_v4_connect", fn_name="trace_connect_v4_entry")
b.attach_kretprobe(event="tcp_v4_connect", fn_name="trace_connect_v4_return")
b.attach_kprobe(event="tcp_close", fn_name="trace_close_entry")
b.attach_kretprobe(event="inet_csk_accept", fn_name="trace_accept_return")4、BCC 高级阶段
BCC 风靡一时,俘获了不少开发者。由于时代在进步,需求也在变。libbpf 横空出世及 CO-RE 思想盛行,BCC 自己也在变革,开始借助 BTF 的方式支持重定位,希望同一套程序在任何 Linux 系统都能顺利运行。然而,有些结构体在不同内核版本上,或者成员名字变了、或者成员的含义变了(从微秒变成了毫秒),这种方式就需要程序处理。在 4.x 等中版本内核上,还需要通过 debuginfo 生成独立的 BTF 文件,过程还是相当复杂。
SEC("kprobe/inet_listen")
int BPF_KPROBE(inet_listen_entry, struct socket *sock, int backlog)
__u64 pid_tgid = bpf_get_current_pid_tgid();
__u32 pid = pid_tgid >> 32;
__u32 tid = (__u32)pid_tgid;
struct event event = ;
if (target_pid && target_pid != pid)
return 0;
fill_event(&event, sock);
event.pid = pid;
event.backlog = backlog;
bpf_map_update_elem(&values, &tid, &event, BPF_ANY);
return 0;
#include "solisten.skel.h"
...
int main(int argc, char **argv)
...
libbpf_set_strict_mode(LIBBPF_STRICT_ALL);
libbpf_set_print(libbpf_print_fn);
obj = solisten_bpf__open();
obj->rodata->target_pid = target_pid;
err = solisten_bpf__load(obj);
err = solisten_bpf__attach(obj);
pb = perf_buffer__new(bpf_map__fd(obj->maps.events), PERF_BUFFER_PAGES,
handle_event, handle_lost_events, NULL, NULL);
...
5、资源共享阶段
BCC 虽然也支持了 CO-RE,但是仍然存在代码相对固定,无法动态配置的问题,同时还需要搭建编译工程。coolbpf 把编译资源放到一台服务器上,提供远程编译能力,大家共享远程服务器资源,只需要把 bpf.c 推送到远端服务器,这台服务器会开动马达,加速输出 .o 和 .so。不管用户使用 Python 还是 Go 语言、Rust 或 C 语言,只需要在程序 ini t的时候加载这些 .o 或 .so 就可以把 BPF 程序 attach 到内核的hook 点,然后专注于处理来自 BPF 程序输出的信息,进行功能开发。
coolbpf 把 BTF 制作、代码编译、数据处理、功能测试集一身,生产效率大幅提升,使BPF 开发进入一个更优雅境界:
- 开箱即用:内核侧仅提供 bpf.c 即可,完全剥离出内核编译工程。
- 复用编译成果:本地侧无编译过程,不存在库依赖和 CPU、内存等资源消耗问题。
- 自适应不同版本差异:更适合在集群多个不同内核版本共存的场景。
pip安装coolbpf命令,它会把xx.bpf.c发送到编译服务器编译。
pip install coolbpf
...
import time
from pylcc.lbcBase import ClbcBase
bpfPog = r"""
#include "lbc.h"
SEC("kprobe/wake_up_new_task")
int j_wake_up_new_task(struct pt_regs *ctx)
struct task_struct* parent = (struct task_struct *)PT_REGS_PARM1(ctx);
bpf_printk("hello lcc, parent: %d\\n", _(parent->tgid));
return 0;
char _license[] SEC("license") = "GPL";
"""
class Chello(ClbcBase):
def __init__(self):
super(Chello, self).__init__("hello", bpf_str=bpfPog)
while True:
time.sleep(1)
if __name__ == "__main__":
hello = Chello()
pass二、coolbpf 功能及架构
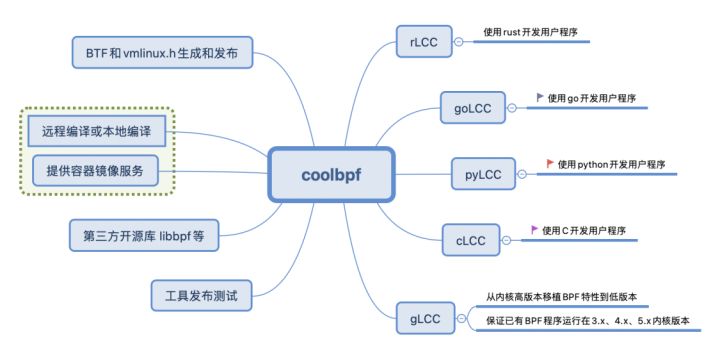
前面分析了 BPF 的开发方式,coolbpf 借助远程编译把开发和编译这个过程进一步优化,总结一下它当前包含的 6 大功能:
1)本地编译服务,基础库封装:客户使用本地容器镜像编译程序,调用封装的通用函数库简化程序编写和数据处理。
本地编译服务,把同样的库和常用工具放在容器镜像里,编译时直接到容器里面编译。我们使用如下镜像进行编译,用户也可以通过 docker 自己搭建容器镜像。
容器镜像: http://registry.cn-hangzhou.aliyuncs.com/alinux/coolbpf:latest
用户可以 pull 这个镜像进行本地编译,一些常用的库和工具,通过我们提供的镜像就已经包含在里面,省去了构建环境的繁杂。
2)远程编译服务:接收 bpf.c,生成 bpf.so 或 bpf.o,提供给高级语言进行加载,用户只专注自己的功能开发,不用关心底层库安装、环境搭建。
远程编译服务,目前用户开发代码时只需要 pip install coolbpf,程序就会自动到我们的编译服务器进行编译。你也可以参考 compile/remote-compile/lbc/ 自己搭建编译服务器(我们后面会陆续开源这个编译服务器源码),过程可能会比较复杂。这样搭建好的服务器,你可以个人使用或者在公司提供给大家一起使用。
3)高版本特性通过 kernel module 方式补齐到低版本,如 ring buffer 特性,backport BPF 特性到 3.10 内核。
由于存量 3.10 内核的服务器依然很多,为了让同一个 BPF 程序也能运行在低版本内核,为了维护方便且不用修改程序代码,只需要 install 一个 ko,就可以支持 BPF,让低版本也享受到了 BPF 的红利。
4)BTF 的自动生成和全网最新内核版本爬虫。自动发现最新的 CentOS、ubuntu、Anolis 等内核版本,自动生成对应的 BTF。
要具备一次编译多处运行 CO-RE 能力,没有 BTF 是行不通的。coolbpf 不仅提供一个制作 BTF 的工具,还会自动发现和制作最新内核版本的 BTF,以供大家下载和使用。
5)各内核版本功能测试自动化,工具编写后自动进行安装测试,保障用户功能在生产环境运行前预测试。
没有上线运行过的BPF程序和工具,一定概率上是存在风险的。coolbpf提供一套自动化测试流程,在大部分内核环境都预先进行基本的功能测试,保证工具真正运行在生产环境时不会出大问题。
6)Python、Rust、Go、C 等高级语言支持。
目前 coolbpf 项目支持使用 Python、Rust、Go 及 C 语言的用户程序开发,不同语言开发者都能在自己最擅长的领域发挥最大的优势。
总之,coolbpf 使得 BPF 程序和应用程序开发在一个平台上闭环解决了,有效提升了生产力,覆盖了当前主流的开发语言,适合更多的 BPF 爱好者入门学习,也适合系统运维人员高效开发监控和诊断程序。
下图为 coolbpf 的功能和工具支持情况,欢迎更多优秀 BPF 工具加入:

三、实践说明
coolbpf 目前包含 pylcc、rlcc、golcc 和 clcc,以及 glcc 子目录,分别是高级语言Python、Rust 和 Go 语言支持远程和本地编译的能力,glcc(g 代表 generic)是通过将高版本的 BPF 特性移植到低版本,通过 kernel module 的方式在低版本上运行。下面我们分别简单介绍它的使用。
1、pylcc(基于 Python 的 LCC)
pylcc 在 libbpf 基础上进行封装,将复杂的编译工程交由容器执行。
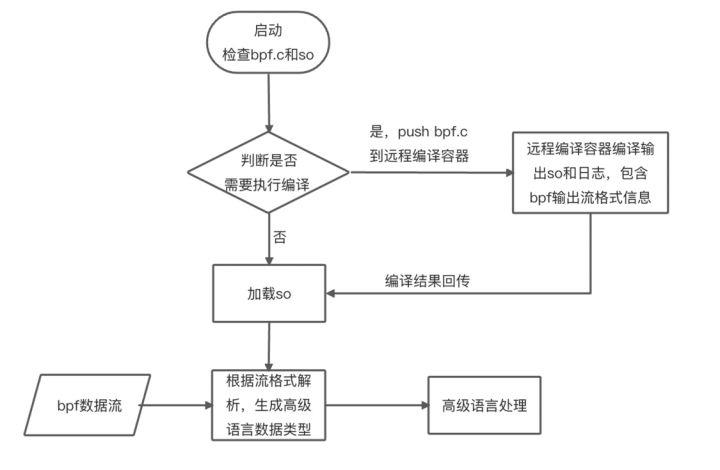
代码编写非常简洁,只需要三步就能完成,pyLCC 技术关键点:
1)执行 pip install coolbpf 安装
2)xx.bpf.c 的编写:
bpfPog = r"""
#include "lbc.h"
LBC_PERF_OUTPUT(e_out, struct data_t, 128);
LBC_HASH(pid_cnt, u32, u32, 1024);
LBC_STACK(call_stack,32);3)xx.py 编写,只需要这一步,程序就可以运行起来。用户关注从内核收到的数据进行分析就可以:
importtimefrompylcc.lbcBaseimportClbcBase
classPingtrace(ClbcBase):def__init__(self):super(Pingtrace, self).__init__("pingtrace")bpf.c 里需要主动包含 lbc.h,它告知远程服务器的行为,本地不需要有这个文件。其内容如下:
#include "vmlinux.h"
#include <linux/types.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_core_read.h>
#include <bpf/bpf_tracing.h>2、rlcc(基于 Rust 的 LCC)
Rust 语言支持远程编译和本地编译的能力。通过在 makefile 中使用 coolbpf 的命令把 bpf.c 发送到服务端,服务端返回 .o,这个与 Python 和 C 返回 .so 有很大区别,Rust 自己处理通用的 load、attach 的过程。其他类似于 Python 的开发,不再赘述。
编译example流程:
SKEL_RS=1 cargo build --release 生成 rust skel 文件;
SKEL_RS=0 cargo build --release 无需在生成 rust skel 文件;
默认 SKEL_RS 为 1.
编译rexample流程:
rexample 使用了远程编译功能,具体编译流程如下:
运行命令 mkdir build & cd build 创建编译目录;
运行命令 cmake .. 生成 Makefile 文件;
运行命令 make rexample;
运行 example 程序: ../lcc/rlcc/rexample/target/release/rexample.fn main() -> Result<()>
let opts = Command::from_args();
let mut skel_builder = ExampleSkelBuilder::default();
if opts.verbose
skel_builder.obj_builder.debug(true);
bump_memlock_rlimit()?;
let mut open_skel = skel_builder.open()?;
let mut skel = open_skel.load()?;
skel.attach()?;
let perf = PerfBufferBuilder::new(skel.maps_mut().events())
.sample_cb(handle_event)
.lost_cb(handle_lost_events)
.build()?;
loop
perf.poll(Duration::from_millis(100))?;
3、glcc(generic LCC,高版本特性移植到低版本)
背景:
- 目前基于 eBPF 编写的程序只能在高版本内核(支持 eBPF 的内核)上运行,无法在不支持 eBPF 功能的内核上运行。
- 线上有很多 Alios 或者 CentOS 低版本内核需要维护。
- 存量 BPF 工具或项目代码,希望不做修改能跨内核运行。
为此我们提出了一种在低版本内核运行 eBPF 程序的方法,使得二进制程序无需任何修改即可在不支持 BPF 的内核上运行。
下面从架构上梳理,低版本内核运行 BPF 的可能。
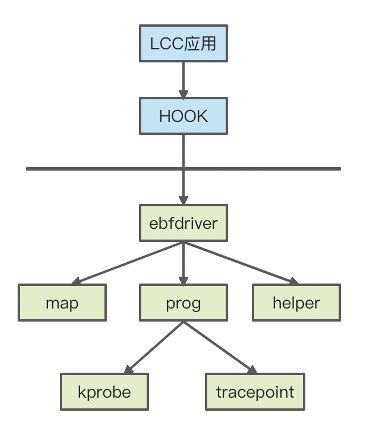
Hook 是一个动态库,由于低版本内核不支持 bpf() 的系统调用,原来在用户态创建 map、创建 prog 以及很多 helper 函数(如 bpf_update_elem 等)将不能运行,Hook 提供一个动态机制,把这些系统调用转成 ioctl 命令,设置到一个叫 ebpfdriver 的 kernel module,通过他进行创建一些数据结构模拟 map 和 prog,同时注册 kprobe 和 tracepoint 的 handler。这样有数据到来时,就会运行注册在 kprobe 和 tracepoint 的回调。
运行机制见下图:
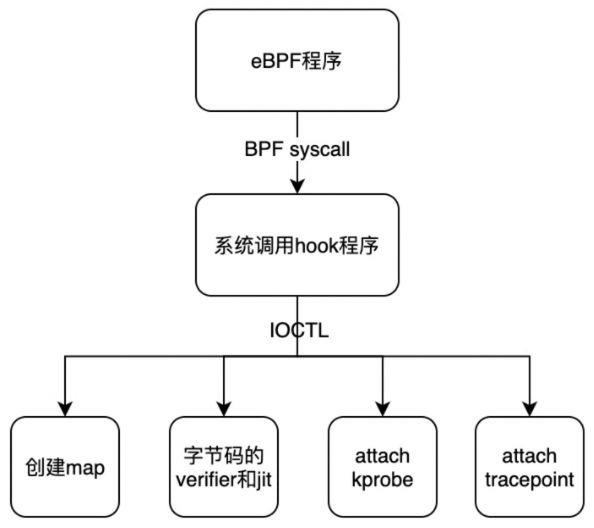
利用 Hook 程序将 BPF 的 syscall 转换成 ioctl 形式,将系统调用参数传递给 eBPF 驱动,包含以下功能:
#define IOCTL_BPF_MAP_CREATE _IOW(';', 0, union bpf_attr *)
#define IOCTL_BPF_MAP_LOOKUP_ELEM _IOWR(';', 1, union bpf_attr *)
#define IOCTL_BPF_MAP_UPDATE_ELEM _IOW(';', 2, union bpf_attr *)
#define IOCTL_BPF_MAP_DELETE_ELEM _IOW(';', 3, union bpf_attr *)
#define IOCTL_BPF_MAP_GET_NEXT_KEY _IOW(';', 4, union bpf_attr *)
#define IOCTL_BPF_PROG_LOAD _IOW(';', 5, union bpf_attr *)
#define IOCTL_BPF_PROG_ATTACH _IOW(';', 6, __u32)
#define IOCTL_BPF_PROG_FUNCNAME _IOW(';', 7, char *)
#define IOCTL_BPF_OBJ_GET_INFO_BY_FD _IOWR(';', 8, union bpf_attr *) eBPF 驱动收到 Ioctl 请求,会根据 cmd 来进行相应的操作,如:
A. IOCTL_BPF_MAP_CREATE:创建map。
B. IOCTL_BPF_PROG_LOAD:加载 eBPF 字节码,进行字节码的安全验证和 jit 生成机器码。
C. IOCTL_BPF_PROG_ATTACH:将该eBPF程序attach到指定的内核函数,利用register_kprobe 和 tracepoint_probe_register 功能完成 eBPF 程序的 attach。
另外,高版本的一些特性,比如 ringbuff,也可以通过 ko 等方式用在低版本。像 clcc 和 golcc 的使用方式,请参考 coolbpf 的 github 链接(见文末),这里不在赘述。
四、总结
coolbpf 当前具备以上 6 大功能,其目的是简化开发和编译过程,让用户专注自己的功能开发,使得广大 BPF 爱好者快速入门,快速编写自己的功能程序而不用担心环境问题。今天我们把这套系统开源,让它服务更多人,以提升他们的生产力,促进社会进步,让更多人参与到这个项目建设中来,形成一股合力,突破一项技术。
我们的远程编译服务,解决的是生产力的效率问题;低版本的 BPF 支持,解决的是困扰各个开发者的同一个 bin 文件如何在多内核版本无差别运行的目的,同时也希望更多人参与进来共同提高,让云计算产业和企业服务的兄弟姐妹们全面享受到 BPF 技术的红利。
龙蜥社区系统运维 SIG(Special Interest Group)致力于打造一个集主机管理、配置部署、监控报警、异常诊断、安全审计等一系列功能的自动化运维平台,coolbpf 是社区的一个子项目,目标是提供一个编译和开发平台,解决 BPF 在不同系统平台的运行和生产效率提升问题。
文/系统运维 SIG(Special Interest Group)
本文为阿里云原创内容,未经允许不得转载。
以上是关于龙蜥社区开源 coolbpf,BPF 程序开发效率提升百倍的主要内容,如果未能解决你的问题,请参考以下文章
什么?Coolbpf 不仅可以远程编译,还可以发现网络抖动!
eunomia-bpf 项目重磅开源!eBPF 轻量级开发框架来了
龙蜥开源内核追踪利器 Surftrace:协议包解析效率提升 10 倍 | 龙蜥技术