深度学习之数据处理
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习之数据处理相关的知识,希望对你有一定的参考价值。
数据操作
- 数据类型,我们最常用的便是数组了


创建数组需要
- 形状:几行几列
- 元素类型:int还是float
- 元素值
数组访问方式:
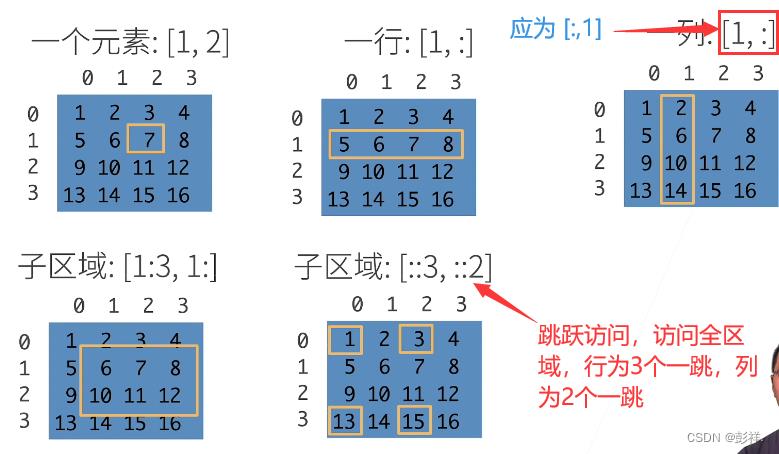
代码:




这种机制的工作方式如下:首先,通过适当复制元素来扩展一个或两个数组, 以便在转换之后,两个张量具有相同的形状。 其次,对生成的数组执行按元素操作。
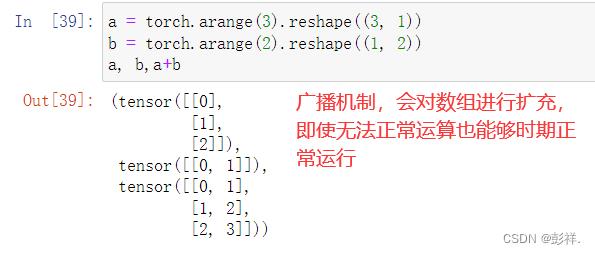
由于a和b分别是和矩阵,如果让它们相加,它们的形状不匹配。 我们将两个矩阵广播为一个更大的矩阵,如下所示:矩阵a将复制列, 矩阵b将复制行,然后再按元素相加。
数据预处理
创建文件并写入数据
import os
os.makedirs(os.path.join('.', 'data'), exist_ok=True)#在当前目录下创建data文件夹
data_file = os.path.join('.', 'data', 'house_tiny.csv')#在data文件夹下创建house_tiny.csv
print(data_file)
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\\n') # 列名
f.write('NA,Pave,127500\\n') # 每行表示一个数据样本
f.write('2,NA,106000\\n')
f.write('4,NA,178100\\n')
f.write('NA,NA,140000\\n')
读取文件,对于csv文件多用pandas这个库
import pandas as pd
data=pd.read_csv(data_file)
print(data)
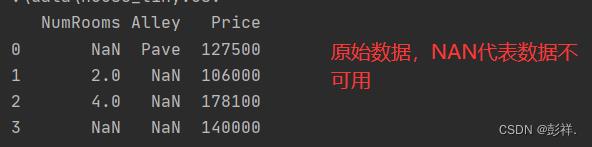
数据处理缺失值与转换
对于缺失值,我们可以采用插入法和删除法两种,插入即我们给定取值,删除则是直接删除不再考虑,这里我们采用缺失值取均值的方式
inputs,outputs = data.iloc[:, 0:2], data.iloc[:, 2]#按照文件格式读取数据,读第一列至第二列
inputs = inputs.fillna(inputs.mean())#对于缺少的数值我们一般取其他值的均值
inputs = pd.get_dummies(inputs, dummy_na=True)#对于string类型我们看到Alley取值只有Pave和NaN,所以我们可以将Pave记为1,NaN记为0
print(inputs)

将我们的数据转换为张量
import torch
x,y=torch.tensor(inputs.values),torch.tensor(outputs.values)
print(x,y)
到这里,我们便将数据转换为tensor的张量,这种对于计算机是可处理的

完整代码:
import os
os.makedirs(os.path.join('.', 'data'), exist_ok=True)
data_file = os.path.join('.', 'data', 'house_tiny.csv')
print(data_file)
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\\n') # 列名
f.write('NA,Pave,127500\\n') # 每行表示一个数据样本
f.write('2,NA,106000\\n')
f.write('4,NA,178100\\n')
f.write('NA,NA,140000\\n')
import pandas as pd
data=pd.read_csv(data_file)
print(data)
inputs,outputs = data.iloc[:, 0:2], data.iloc[:, 2]#按照文件格式读取数据,读第一列至第二列
inputs = inputs.fillna(inputs.mean())#对于缺少的数值我们一般取其他值的均值
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
import torch
x,y=torch.tensor(inputs.values),torch.tensor(outputs.values)
print(x,y)
以上是关于深度学习之数据处理的主要内容,如果未能解决你的问题,请参考以下文章