Ceph Crush算法详解
Posted 厚积_薄发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Ceph Crush算法详解相关的知识,希望对你有一定的参考价值。
Ceph作为最近关注度比较高的统一分布式存储系统,其有别于其他分布式系统就在于它采用Crush(Controlled Replication Under Scalable Hashing)算法使得数据的存储位置都是计算出来的而不是去查询专门的元数据服务器得来的。另外,Crush算法还有效缓解了普通hash算法在处理存储设备增删时带来的数据迁移问题。接下面我会分三篇博文介绍这个重量级的算法,第一篇主要回答三个问题:什么是CRUSH?它能做什么?它是怎么工作的?第二篇主要介绍CRUSH中一个重要的概念Bucket。第三篇主要介绍如何通过CRUSH控制数据迁移。
1. 什么是CRUSH?
随着大规模分布式系统的出现,系统必须能够平均的分布数据和负载,最大化系统的利用率,并且能够处理系统的扩展和系统故障。一般的分布式系统都会采用一个或者多个中心服务用来控制数据的分布,这种机制使得每次IO操作都会先去一个地方查询数据在集群中的元数据信息。当集群的规模变大或者系统的workload比较大时,这些中心服务器必然会成为性能上的瓶颈。Ceph摒弃了这种做法,而是通过引入CRUSH算法,将数据分布的查询操作变成了计算操作,并且是在client端完成。
CRUSH是受控复制的分布式hash算法,是ceph里面用于控制数据分布的一种方法,能够高效稳定的将数据分布在普通的结构化的集群中。它是一种伪随机的算法,在相同的环境下,相似的输入得到的结果之间没有相关性,相同的输入得到的结果是确定的。它只需要一个集群的描述地图和一些规则就可以根据一个整型的输入得到存放数据的一个设备列表。Client在有IO操作的时候,可能会执行CRUSH算法。
2. CRUSH能干什么?
如上面介绍的,它主要是ceph用来控制数据分布的。通过下图,我们看一下它在整个IO流程中处于什么位置。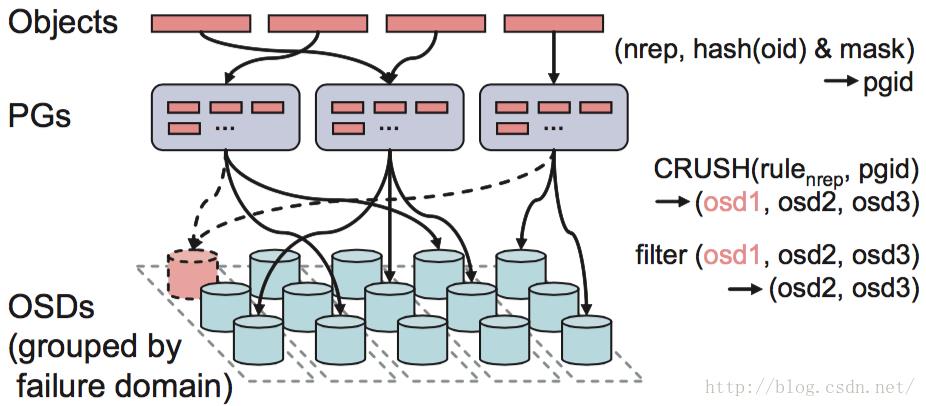
Ceph的后端是一个对象存储(RADOS),所以所有的数据都会按照一个特定的size(ceph系统默认是4M)被切分成若干个对象,也就是上面的Objects。每一个Object都有一个Objectid(oid),Objectid的命名规则是数据所在image的block_name_prefix再跟上一个编号,这个编号是顺序递增的。通过(poolid, hash(oid) & mask),每个object都可以得到它对应的pgid。有了这个pgid之后,Client就会执行CRUSH算法得到一个OSD列表(OSD1,OSD2,OSD3)。然后对它们进行筛选,根据副本数找出符合要求的OSD,比如OSD不能是failed、overloaded的。知道数据要存在哪些OSD上之后,Client会向列表中的第一个OSD(primary osd)发起IO请求。然后这个OSD按照读写请求分别做相应的处理。
所以一句话说明CRUSH的作用就是,根据pgid得到一个OSD列表。
3. CRUSH是如何工作的?
CRUSH是基于一张描述当前集群资源状态的map(Crush map)按照一定的规则(rules)得到这个OSD列表的。Ceph将系统的所有硬件资源描述成一个树状结构,然后再基于这个结构按照一定的容错规则生成一个逻辑上的树形结构作为Crush map。数的叶子节点是OSD。
3.1 Crush map
一个Crush map一般包括四个部分:
1)配置参数
- # begin crush map
- tunable choose_local_tries 0
- tunable choose_local_fallback_tries 0
- tunable choose_total_tries 50
- tunable chooseleaf_descend_once 1
- tunable straw_calc_version 1
[plain] view plain copy
- # devices
- device 0 osd.0
- device 1 osd.1
- device 2 osd.2
[plain] view plain copy
- # types
- type 0 osd
- type 1 host
- type 2 chassis
- type 3 rack
- type 4 row
- type 5 pdu
- type 6 pod
- type 7 room
- type 8 datacenter
- type 9 region
- type 10 root
4)bucket的具体定义
[plain] view plain copy
- root default
- id -1 # do not change unnecessarily
- # weight 3.000
- alg straw
- hash 0 # rjenkins1
- item rack1 weight 3.000
weight:bucket的权重
alg:bucket的类型
hash:bucket中使用到的hash算法
item:bucket里包含哪些元素
3.2 Rules
有了Crush map之后,如何一步一步从bucket中选出元素,这个就是有rule来定义的。一个rule就是一系列的操作,一般一个pool都会对应有一个rule。
一个rule的定义是这样的:
- rule replicated_ruleset
- ruleset 0
- type replicated
- min_size 1
- max_size 10
- step take default
- step choose firstn 0 type osd
- step emit
type:表明这个rule在哪使用,storage drive (replicated) or a RAID。
min_size和max_size用来限定这个rule的使用范围,即当一个pool的副本数小于min_size或者大于max_size的时候不使用这个rule。
step开头的就是三个操作。take是选择一个bucket,然后从这个bucket开始往下遍历,找出OSD。choose是从bucket中找出若干个type类型的项,还有一个chooseleaf操作是bucket中选出若干个leaf节点。至于个数是由firstn后面的数字指定的。如果是0,就按照副本数选择,如果是正数,就按个数来,如果是负数,就按副本数+负数得到的值来选。最后一步是emit,就是输出结果。
下面是sage论文上的一个例子:
rule和对应的结果是:
- take(root) root
- select(1, row) row2
- select(3, cabinet) cab21, cab23, cab24
- select(1, disk) disk2107, disk2313, disk2437
- emit
Crush算法按照rule从bucket中选择item的时候,一般和bucket的权重有关系,每个bucket的权重是所有孩子的权重的和。所以权重是按照自下往上的顺序,依次计算的,也就是先算出osd的权重,然后再算出它父辈的权重。OSD的权重和它的容量有关系,现在的约定是1T容量的权重是1,OSD的权重就是它的容量/1T。
以上是关于Ceph Crush算法详解的主要内容,如果未能解决你的问题,请参考以下文章