第100篇博客——用Python爬取我前99篇博客内容,分词并生成词云图
Posted bit_kaki
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第100篇博客——用Python爬取我前99篇博客内容,分词并生成词云图相关的知识,希望对你有一定的参考价值。
这是我的第100篇博客,从2016年7月1日发表第一篇博客至今,也有两个多年头了。
回首自己前99篇博客,各种类型都有,有技术总结,有随感,有读书笔记,也有BUG修改。内容千奇百怪,质量参差不齐,篇幅长短不一,但总的来说也是写了也有几十万字了。
写博客对于我来说渐渐也成为了一个习惯,通过写博客,我能定期进行自我总结,归纳自己的进步和了解自己的不足。同时也通过不断地笔耕,使得自己文笔上有了不小的进步。
这第100篇博客,我打算用咱程序员自己的方式对我前99篇文章做个小结。采用Python爬取我博客整体情况和前99篇博客内容,做分词处理,然后生成词云图。
一、运行环境
Python 3.6.3
二、博客整体情况爬取
博客的整体情况爬取可以参考我之前的文章:https://blog.csdn.net/bit_kaki/article/details/80254646
其实采用Python爬取数据的核心思想是通过模拟浏览器访问服务器,从响应的结果中获取自己想要的内容。
所以比起我之前的文章,访问服务器这块没有任何改变,而随着CSDN自身前端页面的更改,所以在获取内容这块代码会有所更改。
这里我再重新说明下吧,首先是模拟浏览器访问服务器,其代码为:
#输入CSDN博客ID
account = str(raw_input('print csdn id:'))
#首页地址
baseUrl = 'http://blog.csdn.net/'+account
#连接页号,组成爬取的页面网址
myUrl = baseUrl+'/article/list/'+str(page_num)
#伪装成浏览器访问,直接访问的话csdn会拒绝
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = 'User-Agent':user_agent
#构造请求
req = urllib2.Request(myUrl,headers=headers)
#访问页面
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
type=sys.getfilesystemencoding()
myPage = myPage.decode("UTF-8").encode(type)这里需要注意的我都以注释形式给予了备注。
接下来就是解析服务器响应的数据。在我们自己解析前,可以先打开浏览器,看看页面源代码:

在总体情况这里,我想爬取的是我的博客标题、原创、粉丝、喜欢、评论、访问量等基本信息,于是我们在源代码里找到相应的信息:

然后我们就可以利用正则表达式来获取相应的信息,其代码如下所示:
#获取总体信息
#利用正则表达式来获取博客的标题
title = re.findall('<title>(.*?)</title>',myPage,re.S)
titleList=[]
for items in title:
titleList.append(str(items).lstrip().rstrip())
print '%s %s' % ('标题'.decode('utf8').encode('gbk'),titleList[0])
#利用正则表达式来获取博客的数量
num = re.findall('<span class="count">(.*?)</span>',myPage,re.S)
numList=[]
for items in num:
numList.append(str(items).lstrip().rstrip())
#利用正则表达式来获取粉丝的数量
fan = re.findall('<dd><span class="count" id="fan">(.*?)</span></dd>',myPage,re.S)
fanList=[]
for items in fan:
fanList.append(str(items).lstrip().rstrip())
#输出原创、粉丝、喜欢、评论数
print '%s %s %s %s %s %s %s %s' % ('原创'.decode('utf8').encode('gbk'),numList[0],'粉丝'.decode('utf8').encode('gbk'),fanList[0],'喜欢'.decode('utf8').encode('gbk'),numList[1],'评论'.decode('utf8').encode('gbk'),numList[2])
#利用正则表达式来获取访问量
fangwen = re.findall('<dd title="(.*?)">',myPage,re.S)
fangwenList=[]
for items in fangwen:
fangwenList.append(str(items).lstrip().rstrip())
#利用正则表达式来获取排名
paiming = re.findall('<dl title="(.*?)">',myPage,re.S)
paimingList=[]
for items in paiming:
paimingList.append(str(items).lstrip().rstrip())
#输出总访问量、积分、排名
print '%s %s %s %s %s %s' % ('总访问量'.decode('utf8').encode('gbk'),fangwenList[0],'积分'.decode('utf8').encode('gbk'),fangwenList[1],'排名'.decode('utf8').encode('gbk'),paimingList[0])
运行结果如下:

于是第一部分获取博客整体情况就完成了。内容很简单,步骤总结下就是网络请求——获取数据——截取自己需要的数据。
三、获取每篇博客的内容
刚刚我们是获取博客整体情况,通过一次网络请求即可获取整体信息。
那么我们如何获取每篇文章的内容呢?
其实答案也挺简单,那就是做一次遍历,访问每篇文章所在地址,获取博客数据即可。
在CSDN里,每个博客展示页面仅仅展现20篇博客内容,而我的博客数是大于20的,所以在博客综述页面里是进行了分页展示。所以首先,我应该获取到每页博客综述页面的数据。代码如下:
#不是最后列表的一页
notLast = []
#获取每一页的信息
while not notLast:
#首页地址
baseUrl = 'http://blog.csdn.net/'+account
#连接页号,组成爬取的页面网址
myUrl = baseUrl+'/article/list/'+str(page_num)
#伪装成浏览器访问,直接访问的话csdn会拒绝
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = 'User-Agent':user_agent
#构造请求
req = urllib2.Request(myUrl,headers=headers)
#访问页面
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
type=sys.getfilesystemencoding()
myPage = myPage.decode("UTF-8").encode(type)
#在页面中查找最后一页,这里我用了我博客的最后一页的一个标签
notLast = re.findall('android.media.projection',myPage,re.S)
print '-----------------------------the %d page---------------------------------' % (page_num,)
#利用正则表达式来获取博客的标题
title = re.findall('<span class="article-type type-1">(.*?)</a>',myPage,re.S)
titleList=[]
for items in title:
titleList.append(str(items)[32:].lstrip().rstrip())
#利用正则表达式获取博客的访问地址
url = re.findall('<a href="(.*?)" target="_blank">',myPage,re.S)
urlList=[]
for items in url:
urlList.append(str(items).lstrip().rstrip())
#将结果输出
for n in range(len(titleList)):
print '%s %s' % (titleList[n],urlList[n*2+1])
#页号加1
page_num = page_num + 1这里,我设置了一个参数notLast作为是否为最后一页的标签,然后在我博客综述的最后一页找到个特殊的内容“ android.media.projection” 作为判定依据,这样我就可以找到博客综述的所有数据了。
运行结果为:

接下来我就是要获取我每一篇博客的内容了。方法依然是遍历,根据每一页博客综述里获取的博客地址,进行请求访问,然后从响应结果里获取博客内容。代码为:
#将结果输出
for n in range(len(titleList)):
print '%s %s' % (titleList[n],urlList[n*2+1])
#每篇博客地址
baseUrl = urlList[n*2+1]
#伪装成浏览器访问,直接访问的话csdn会拒绝
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = 'User-Agent':user_agent
#构造请求
req = urllib2.Request(baseUrl,headers=headers)
#访问页面
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
type=sys.getfilesystemencoding()
myPage = myPage.decode("UTF-8").encode(type)
#利用正则表达式来获取博客的内容
content = re.findall('<article>(.*?)</article>',myPage,re.S)
contentList=[]
for items in content:
contentList.append(str(items).lstrip().rstrip())
try:
fh = open('F:\\\\study\\\\article\\\\'+titleList[n]+'.txt', 'a')
fh.write('%s' % (contentList[0]))
fh.write('\\n')
fh.close()
except IOError:
print '发生了错误'运行的结果,我们就在指定位置获取了每篇博客的内容:

不过目前的博客内容还有大量html标签,我们再把这些html标签去掉,并且全部保存到一个文件里。代码为:
#将结果输出
for n in range(len(titleList)):
print '%s %s' % (titleList[n],urlList[n*2+1])
#每篇博客地址
baseUrl = urlList[n*2+1]
#伪装成浏览器访问,直接访问的话csdn会拒绝
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = 'User-Agent':user_agent
#构造请求
req = urllib2.Request(baseUrl,headers=headers)
#访问页面
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
type=sys.getfilesystemencoding()
myPage = myPage.decode("UTF-8").encode(type)
#利用正则表达式来获取博客的内容
content = re.findall('<article>(.*?)</article>',myPage,re.S)
contentList=[]
for items in content:
contentList.append(str(items).lstrip().rstrip())
text = contentList[0]
dr = re.compile(r'<[^>]+>',re.S)
dd = dr.sub('',text)
try:
fh = open('F:\\\\study\\\\article\\\\ALL\\\\all.txt', 'a')
fh.write('%s' % (dd))
fh.write('\\n')
fh.close()
except IOError:
print '发生了错误'然后在一个名为all.txt的文档,就可以看到我所有博客的文档内容了:

四、利用jieba分词
jieba是目前最常用的中文分词工具包,分为三种模式:精确模式(默认)、全模式和搜索引擎模式。下面举例说明:
精确模式:主要将句子最精确的切开,适合文本分析;
比如:'我想和女朋友一起去北京故宫博物院参观和闲逛。'
拆分结果为:我,想,和,女朋友,一起,去,北京故宫博物院,参观,和,闲逛。
全模式:把句子中所有的可能成词语都扫描出来,速度非常快,但是不能解决歧义
比如:'我想和女朋友一起去北京故宫博物院参观和闲逛。'
拆分结果为:我,想,和,女朋友,朋友,一起,去,北京,北京故宫,北京故宫博物院,故宫,故宫博物院,博物,博物院,参观,和,闲逛。
搜索引擎模式 :在精准模式的基础上,对长词再次切分,提高招呼率,适合用于搜索引擎分词。
比如:'我想和女朋友一起去北京故宫博物院参观和闲逛。'
拆分结果为:我,想,和,朋友,女朋友,一起,去,北京,故宫,博物,博物院,北京故宫博物院,参观,和,闲逛。
本文采用精确模式,词库选择清华大学的thulac中文词库。
首先需要安装两个分析包:
pip install thulac #安装清华大学的thulac中文词法分析包
pip install jieba #安装中文词法分析包jieba然后直接附上代码:
#! python3
# -*- coding: utf-8 -*-
import jieba #导入结巴模块
from collections import Counter #导入collections模块的Counter类
#对文本文件txt进行分词,并统计词频,再显示结果
def get_words(txt):
#对文本进行分词
list = jieba.cut(txt) #结巴模块的cut函数用于中文分词
#统计词频
c = Counter() #创建空的Counter计数器
for x in list: #分词结果中循环提取词语
if len(x) > 1 and x != '\\r\\n' and x != 'nbsp' and x !='gt' and x !='lt': #略掉只有一个字的词语和回车、换行、空格、大于、小于
c[x] += 1 #统计每个单词的计数值
#S3 将结果可视化
fh = open('F:\\\\study\\\\article\\\\ALL\\\\tongji.txt', 'a')
fh.write('卡小基博客常用词')
fh.write('\\n')
fh.close()
for(k,v) in c.most_common(150): #只取出现值最高的前150个词语
fh = open('F:\\\\study\\\\article\\\\ALL\\\\tongji.txt', 'a')
fh.write('%s %d' % (k, v))
fh.write('\\n')
fh.close()
#读取某文本文件(默认uft-8格式)
with open('F:\\\\study\\\\article\\\\ALL\\\\all.txt','rb') as f :
txt = f.read()
txtlength=len(txt)
fh = open('F:\\\\study\\\\article\\\\ALL\\\\tongji.txt', 'a')
fh.write('卡小基博客总字数为'+str(txtlength))
fh.write('\\n')
fh.close()
#对该文件进行分词,并统计词频,显示结果
get_words(txt)运行可以得出结果:
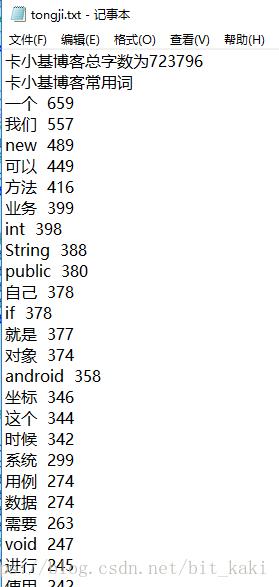
就可以得出我的博客总字数以及常用词的字数了。用得最多的都是一些日常常见词,以及代码里涉及到的new、int、string的名号关键词。
五、生成词云图
根据我们的统计结果,下一步就是生成词云图了。
在Python里,我们可以使用WorldCloud生成词云图,代码也很简单,详见:
https://blog.csdn.net/CSDN2497242041/article/details/77175112?locationNum=5&fps=1
不过效果来说真的一般,于是后来我找到了WordArt,在上面制作词云图。
WordArt的网址为:https://wordart.com/create
首先是导入文字:
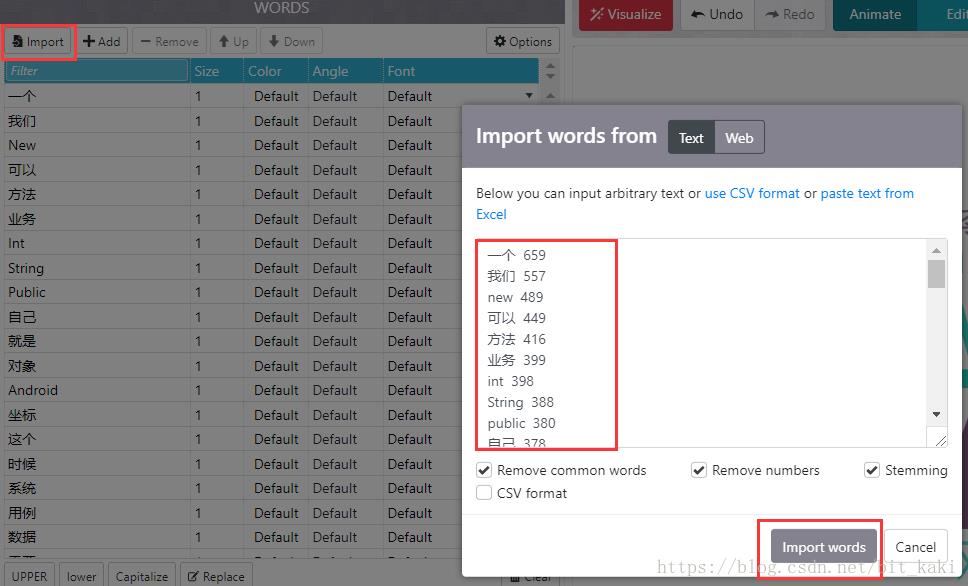
接下来是选择背景图,背景图我选择了CSDN的一个LOGO作为背景图:
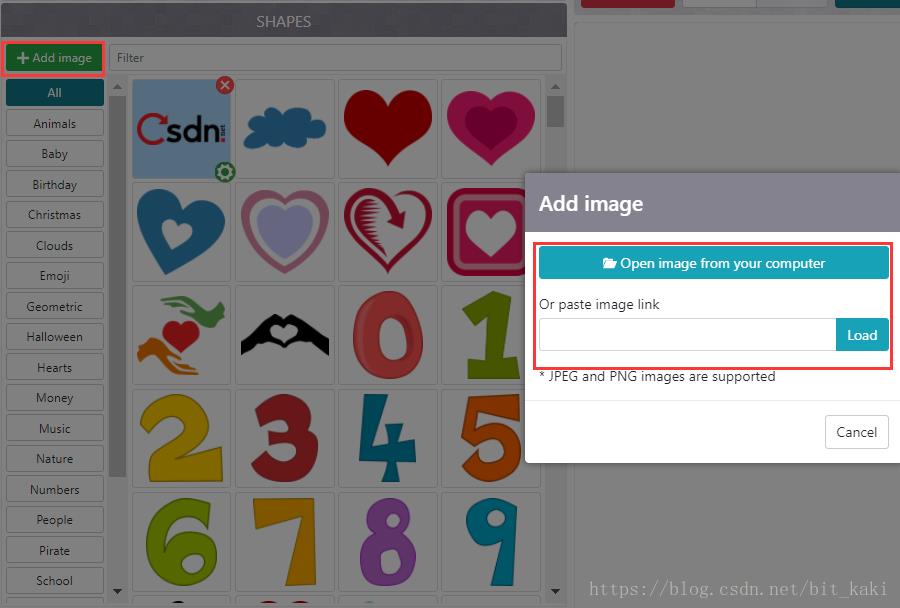
接下来就是选择字体。因为我这里中文汉字较多,所以选择自己导入微软雅黑字体。步骤和上两步相似。
然后就是布局和类型选择,这里我都采取的是其默认选择内容。
选择完毕后,点击visualize按钮,即可生成词云图,效果如下:

就这样,就完成了我前99篇博客词云图统计。
以上是关于第100篇博客——用Python爬取我前99篇博客内容,分词并生成词云图的主要内容,如果未能解决你的问题,请参考以下文章