爆火的Transformer,到底火在哪?
Posted striving长亮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爆火的Transformer,到底火在哪?相关的知识,希望对你有一定的参考价值。
传送门:
第一章 细讲:Attention模型的机制原理
第二章 Attention实现超详细解析( tfa, keras 方法调用源码分析 & 自建网络)
推荐阅读:The Illustrated Transformer——Jay Alammar
目录
前言
与传统的 Soft Attention(如Bahdanau Attention、Luong Attention) 相比, Self-Attention 可有效缩短远距离依赖特征之间的距离,更容易捕获时间序列数据中相互依赖的特征,在大多数实际问题中,Self-Attention 更被研究者们所青睐,并具有更加优异的实际表现。
Transformer在Goole的一篇论文Attention is all you need被提出,其火爆程度相信已经不需要我多说了,大部分AIers应该都听过Transformer。本人在接下来的课题研究中也会用到与之有关的知识,因此,结合网上一些已有的博客(尤其感谢Alammar教授[1])以及Attention is all you need这篇paper,本篇文章对Transformer做一个详细的个人理解记录。
Transformer是我的一个重点学习、讲解内容,如果有哪里写的不对,欢迎大家批评指正,感谢~
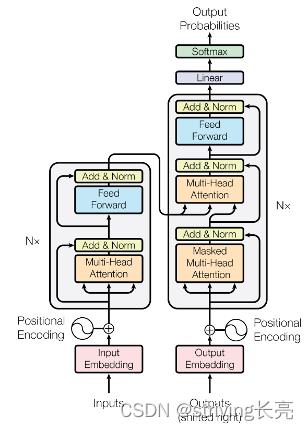
1.总体架构
以机器翻译为例,先整体看一下Tranformer的结构,注意:Encoders和Decoders均为N层:
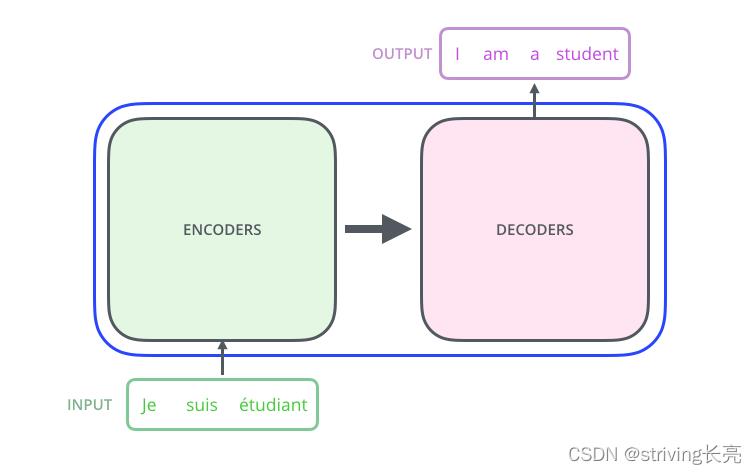
如果我们把Transformer想象成一个黑匣子,在机器翻译的领域中,这个黑匣子的功能就是输入一种语言然后将它翻译成其他语言。如下图所示:

这个黑匣子主要有两部分构成,分别是Encoders以及Decoders:
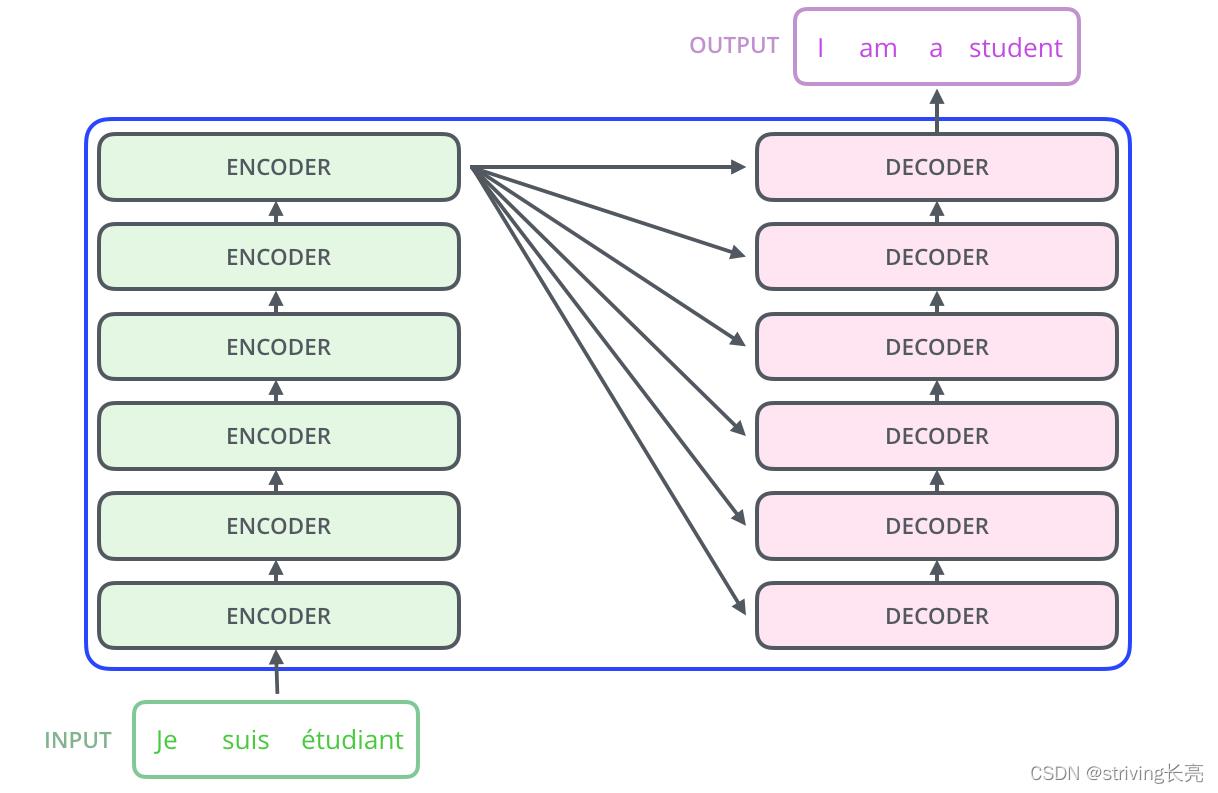
具体地说,每一个Encoder和Decoder分别由6个子Encoder以及Decoder构成(论文中是这么配置的),有一个细节,最顶端Encoder的输出会传递给每一个Decoders:
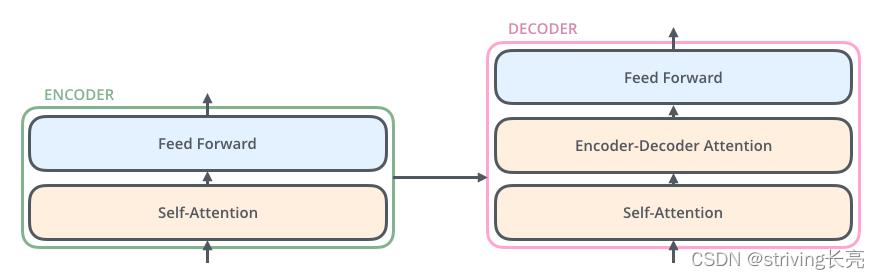
对于Encoders中的每一个Encoder,结构都是相同的,但并不会共享权值。每层Encoder有2个部分组成,如下图:
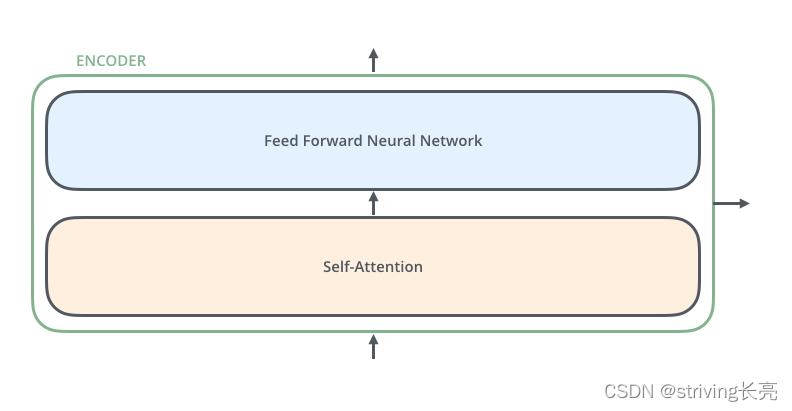
每个Encoder的输入首先会通过一个self-attention层,通过self-attention层帮助Endcoder在编码单词的过程中查看输入序列中的其他单词。
Self-attention的输出会被传入一个全连接的前馈神经网络,每个encoder的前馈神经网络参数个数都是相同的,但他们的作用是独立的。
每个Decoder也同样具有这样的层级结构,但是在这之间有一个Attention层,帮助Decoder专注于与输入句子中对应的那个单词(类似与seq2seq models的结构)
2.基本单元
2.1 Word Embedding (词嵌入)
首先,我们需要将单词变成词向量形式,不明白的可以看Glossary of Deep Learning: Word Embedding,我也会在接下来的新文章中详细介绍一下Word Embedding。
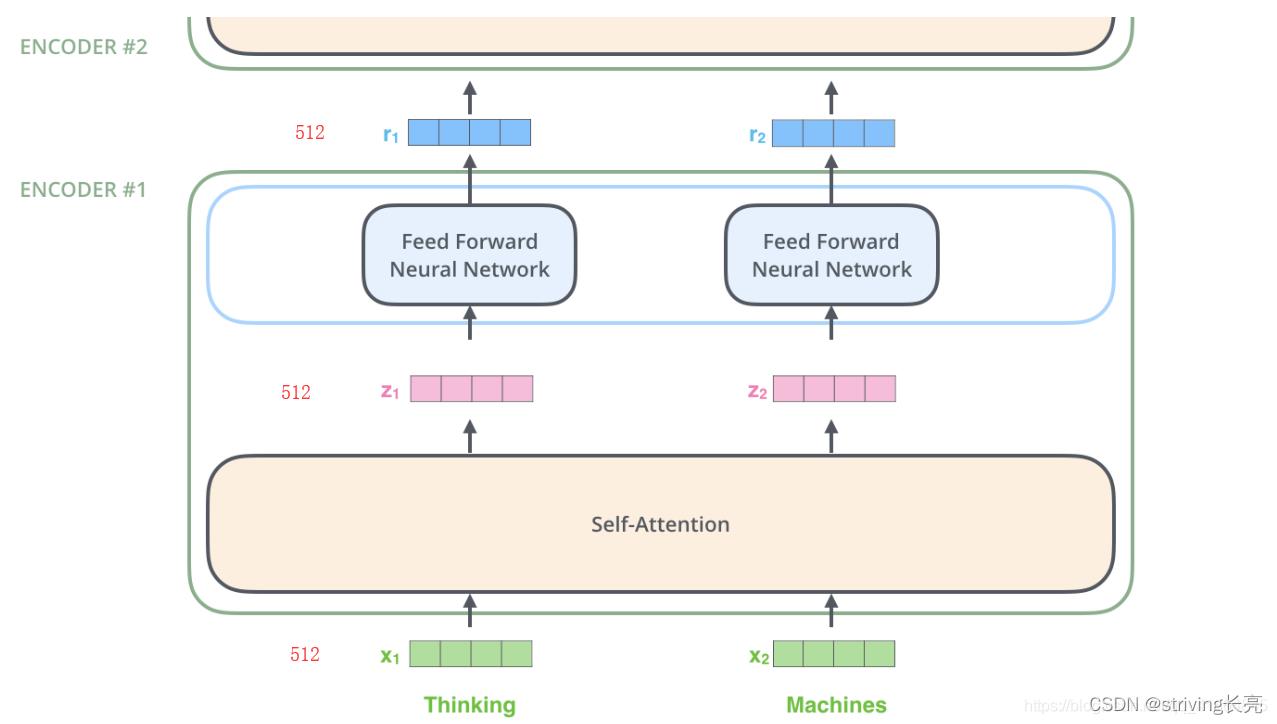
每个单词都嵌入到大小为512的向量中。我们将用这些简单的方框来表示这些向量。

词嵌入的过程只发生在最底层的Encoder。并且Encoder的输入输出维度不会发生变化:
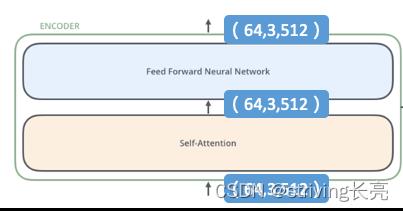
64是batch_size,3是单词个数,512是词向量维度。Transformer中的每个Encoder接收一个512维度的向量的列表作为输入,然后将这些向量传递到self-attention层,self-attention层产生一个等量512维向量列表,然后进入前馈神经网络,前馈神经网络的输出也为一个512维度的列表,然后将输出向上传递到下一个encoder。
因此,对于所有的Encoder来说,我们都可以按下图来理解,具体地:
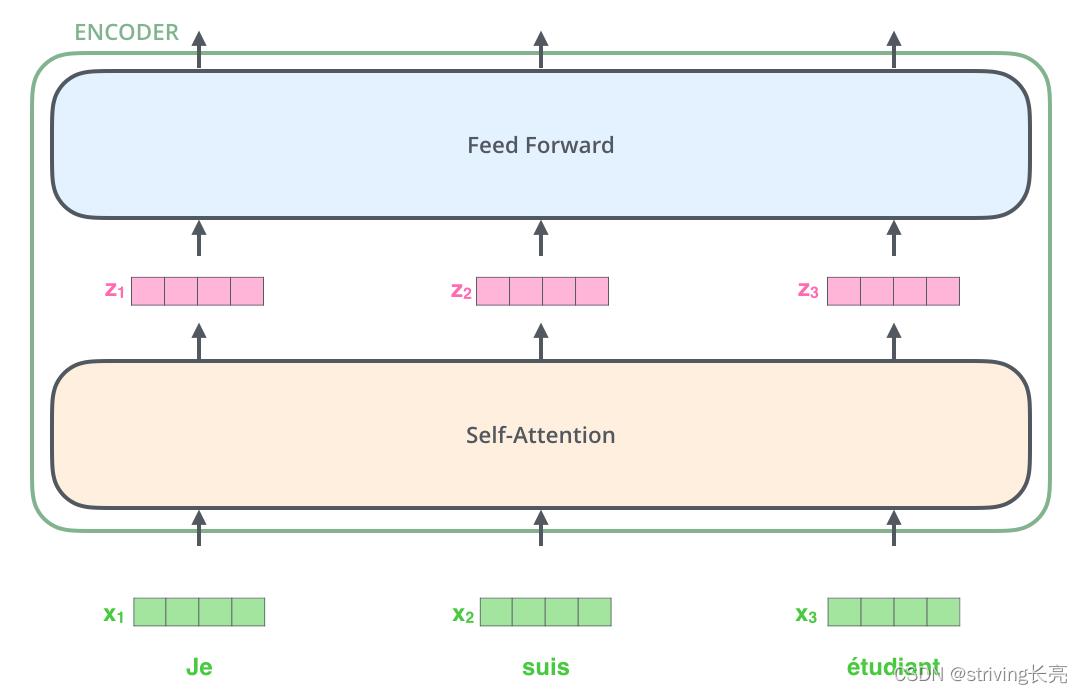
输入(一个向量的列表,每个向量的维度为512维,在最底层Encoder作用是词嵌入,其他层就是其前一层的output)。
另外这个列表的大小和词向量维度的大小都是可以设置的超参数。一般情况下,它是我们训练数据集中最长的句子的长度。
注意观察,在每个单词进入Self-Attention层后都会有一个对应的输出。Self-Attention层中的输入和输出是存在依赖关系的,而前馈层则没有依赖,每个单词对应一个独立的前馈神经网络层(网络层结构相同),所以在前馈层,我们可以用到并行化来提升速率。
2.2 Self- Attention
Self- Attention是Transformer的重点,与 Soft Attention 所不同的是,Self-Attention 是 Encoder 内部或者 Decoder 内部之间所发生的注意力机制,是由 Google AI 研究院所提出的预训练语言表征模型——BERT(Bidirectional Encoder Representations from Transformers) 的主要组成部分之一。
由于包括 LSTM、GRU 在内的众多 RNN 模型需按照固定方向顺序计算,为有效缩短远距离依赖特征之间的距离,在 Self-Attention 中,各隐藏层状态可通过特定的计算步骤被直接联系,也就是说,各隐藏层状态不必按照固定方向顺序串联
因此,Self-Attention 更容易捕获时间序列数据中相互依赖的特征。
关于注意力机制的部分在已经在我之前的文章做了详细的阐述,在此不再赘述,只是大体再做一个总结。
传送门:细讲:Attention模型的机制原理
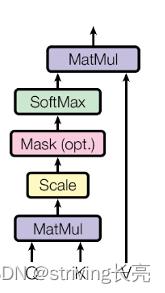
Self- Attention的计算涉及三个对象:
-
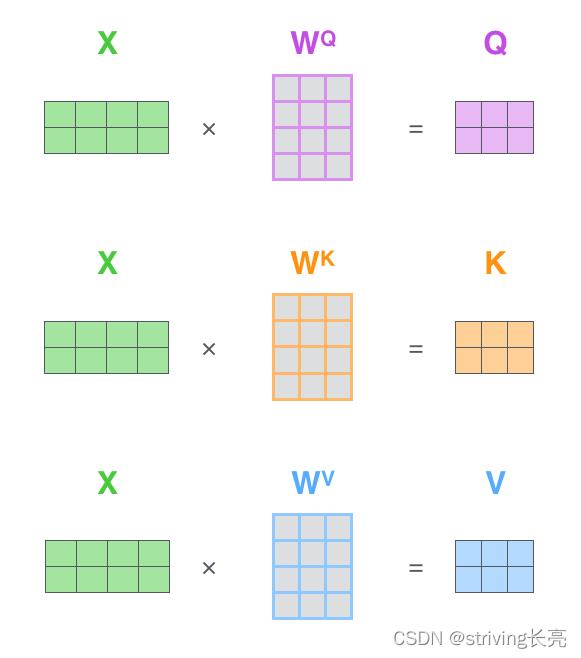
查询序列 Q:在 Self-Attention 中,Q 用于检索序列之间的信息。Q 由查询序列隐向量所组成,即 Q = X ∗ W Q Q=X*W^Q Q=X∗WQ, Q = [ q 1 ; q 2 ; … ; q n ] ∈ R d ∗ n Q= [q_1; q_2;…; q_n ] ∈ ℝ ^d∗ n Q=[q1;q2;…;qn]∈Rd∗n ,由 n n n 个维度为 d d d的 列向量组成,其中 q i q_i qi 代表第 i i i 个列向量,表示该序列第 i i i个位置的隐状态。
-
键序列K:作为被检索的序列,键序列是查询序列的匹配对象。 K = X ∗ W K K=X*W^K K=X∗WK, K = [ k 1 ; k 2 ; … ; k n ] ∈ R d ∗ n K= [k_1 ; k_2 ;…;k_n ] ∈ ℝ ^d∗ n K=[k1;k2;…;kn]∈Rd∗n ,也是由 n n n 个维度为 d d d的 列向量组成,其中 k i k_i ki代表键序列和值序列中第 i i i 个位置的隐向量。
-
值序列V:模型计算Query和各个Key的相似性或者相关性,再利用softmax函数,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention值。
本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。 V = X ∗ W V V=X*W^V V=X∗WV,由键序列 V = [ v 1 ; v 2 ; … ; v m ] ∈ R d ∗ m V= [v_1 ; v_2 ;…;v_m ] ∈ ℝ ^d∗ m V=[v1;v2;…;vm]∈Rd∗m ,由 m m m个维度为 d d d 的列向量组成, v i v_i vi 代表值序列中第 i i i 个位置的隐向量。
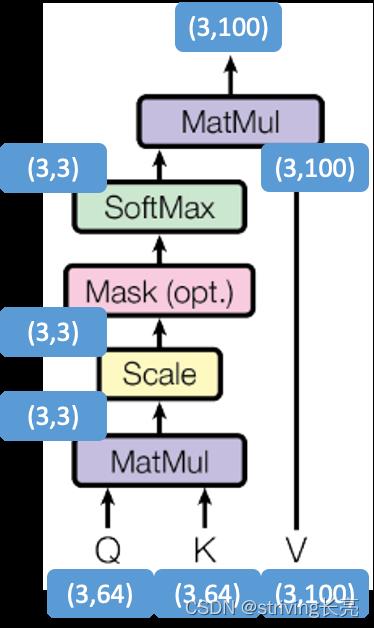
X矩阵中的每一行对应于输入句子中的一个单词。我们再次看到词嵌入向量(512,或图中的4个框)和q/k/v向量(64,或图中的3个框)的大小差异:

Attention ( Q , K , V ) = softmax ( Q K T d k ) V \\operatornameAttention(Q, K, V)=\\operatornamesoftmax\\left(\\fracQ K^T\\sqrtd_k\\right) V Attention(Q,K,V)=softmax(dkQKT)V
其中, Attention ( Q , K , V ) \\operatornameAttention(Q, K, V) Attention(Q,K,V) 为一个维度为 d ∗ m d*m d∗m 的矩阵。在具体实现中,随着隐向量维度 d d d增大,点乘的方差也在逐渐增大,在计算Softmax的时候会出现梯度消失的情况,因为计算过程加了 d k \\sqrtd_k dk 归一化因子,归 一化因子可有效缓解梯度消失情况的发生,并保证点乘结果的方差不随隐藏层维度 d 变化。
注意看这个公式,
Q
K
T
Q K^T
QKT其实就会组成一个word2word的attention map!(加了softmax之后就是一个合为1的权重了)。比如说你的输入是一句话 “i have a dream” 总共4个单词,这里就会形成一张4x4的注意力机制的图:

这样一来,每一个单词就对应每一个单词有一个权重。
注意encoder里面是叫self-attention,decoder里面是叫masked self-attention。
这里的masked就是要在做language modelling(或者像翻译)的时候,不给模型看到未来的信息,即采用教师强制(Teacher- forcing)模式进行训练。
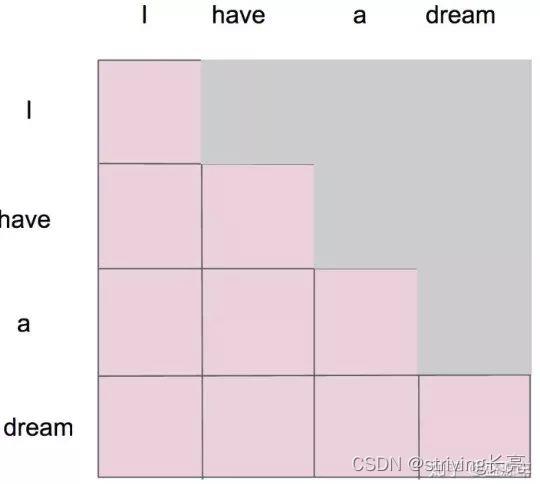
mask就是沿着对角线把灰色的区域用0覆盖掉,不给模型看到未来的信息。详细来说,i作为第一个单词,只能有和i自己的attention。have作为第二个单词,有和i, have 两个attention。 a 作为第三个单词,有和i,have,a 前面三个单词的attention。到了最后一个单词dream的时候,才有对整个句子4个单词的attention。
做完softmax后就像这样,横轴合为1
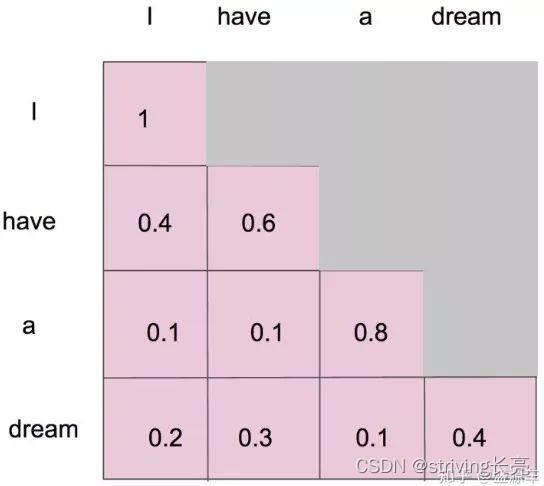
需要说明的是,键序列和值序列一般是具有对应关系的,即 m = n m=n m=n,也就是三者的维度一致,但在实际计算当中,并不强制要求三者维度一致,即便值序列的维度与键序列不一致,也不会导致错误发生。
最终我们得到一个可以放到独立的前馈神经网络的矢量!
2.3 Multi-Head Attention (MHA)
Multi-headed的机制是Transformer的另外一个特色,其目的是进一步完善self-attention层。
原始的attention, 就是一个query 和一组key算相似度, 然后对一组value做加权和; 假如每个Q和K都是512维的向量, 那么这就相当于在512维的空间里比较了两个向量的相似度.
multi-head相当于把这个512维的空间人为地拆成了多个子空间, 比如head number=8, 就是把一个高维空间分成了8个子空间, 相应地,V也要分成8个head; 然后在这8个子空间里分别计算Q和K的相似度, 再分别组合V. 这样可以让attention能从多个不同的角度进行结合, 这对于NMT是很有帮助的, 因为我们在翻译的时候源语言和目标语言的词之间并不是一一对应的, 而是受很多词共同影响的. 每个子空间都会从自己在意的角度或者因素去组合源语言, 从而得到最终的翻译结果.
以”The animal didn’t cross the street because it was too tired”这句话为例。这句话中的"it"指的是什么?它指的是“animal”还是“street”?

Multi-headed主要有以下作用:
-
拓展了模型关注不同位置的能力。在上面例子中可以看出,上图是我们第五层Encoder针对单词’it’的图示,可以发现,我们的Encoder在编码单词‘it’时,部分注意力机制集中在了‘animal’上,这部分的注意力会通过权值传递的方式影响到’it’的编码,这在对语言的理解过程中是很有用的。 -
为attention层提供了多个representation subspaces。由下图可以看到,在self-attention中,我们有多个个Query / Key / Value权重矩阵(Transformer使用8个attention heads)。这些集合中的每个矩阵都是随机初始化生成的。然后通过训练,用于将词嵌入(或来自较低Encoder/Decoder的矢量)投影到不同的representation subspaces(表示子空间)中。
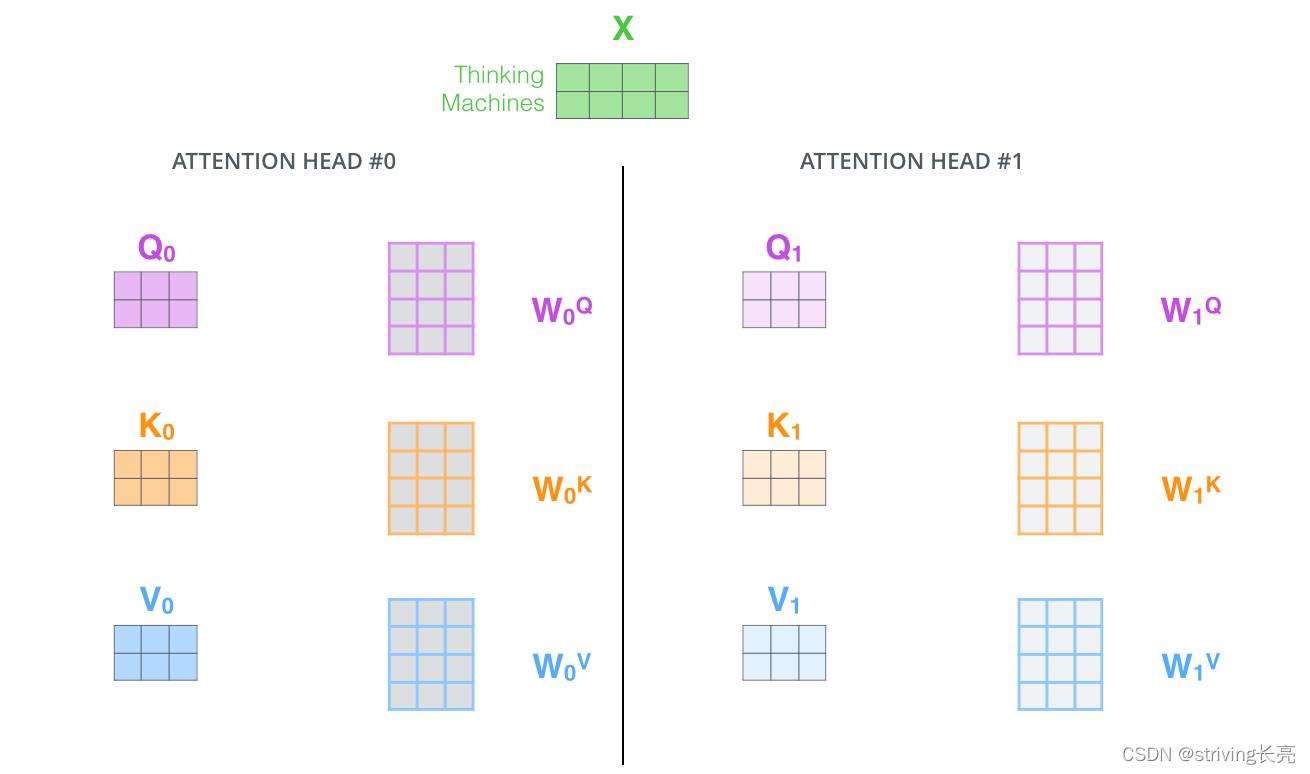
通过multi-headed attention,我们为每个“header”都独立维护一套Q/K/V的权值矩阵。然后我们还是如之前单词级别的计算过程一样处理这些数据。
因为我们有8头attention,所以我们会在八个时间点去计算这些不同的权值矩阵,但最后结束时,我们会得到8个不同的矩阵。
由于self-attention后面紧跟着的是前馈神经网络,而前馈神经网络接受的是单个矩阵向量,而不是8个矩阵。所以我们把这8个矩阵压缩成一个矩阵,将这8个矩阵连接在一起然后再与另一个权重矩阵 W O W^O WO相乘。
以上是关于爆火的Transformer,到底火在哪?的主要内容,如果未能解决你的问题,请参考以下文章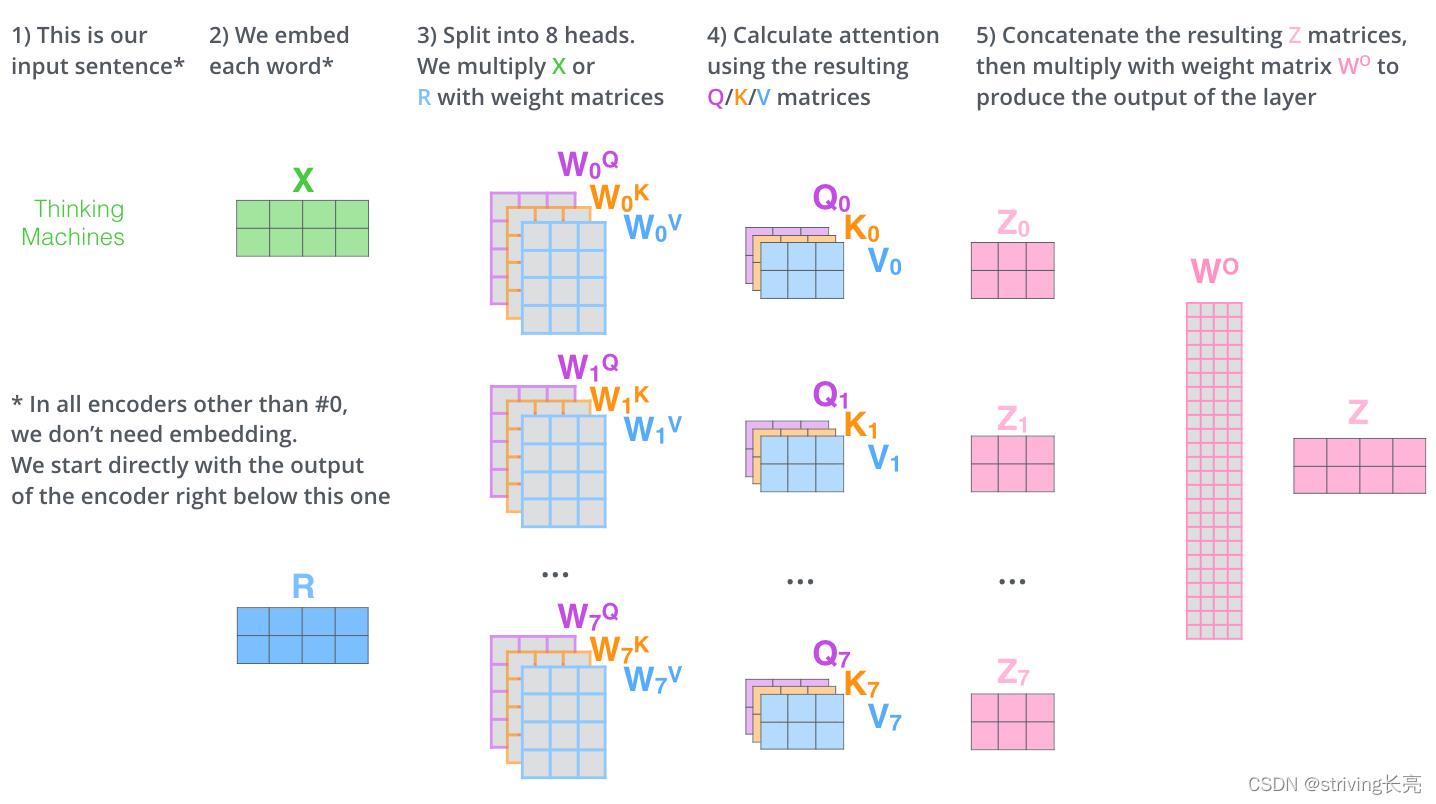
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
head
1
,
…
,
head
h
)
W
O
where head
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
\\beginaligned \\operatornameMultiHead(Q, K, V) &=\\text Concat \\left(\\text head _1, \\ldots, \\text head _\\mathrmh\\right) W^O \\\\ \\text where head &=\\text Attention \\left(Q W_i^Q, K W_i^K, V W_i^V\\right) \\endaligned
MultiHead(Q,K,V) where head = Concat ( head 1,…, head h)WO= Attention (QWiQ,KW