静息态 任务态fmri 啥意思
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了静息态 任务态fmri 啥意思相关的知识,希望对你有一定的参考价值。
fMRI是功能磁共振图像,是MRI图像的一种,通常也叫做T2像,一般是由很多个时间点组成的一系列3D图像;任务态fMRI就是指先设计种任务模式,比如在一段时间内动舌头,动手指,然后在这段时间内连续采集一个人的脑功能系共振图像,这就是任务态fMRI;与之相对的,静息态fMRI就是指被扫描的人躺在机器上啥都不做,采集某一段时间内你的脑功能磁共振图像。最后可以对两种状态下的图像做组间分析,看你在做某个任务时相对应的哪个脑区激活了。 参考技术A 以脑成像为例,fMRI与MRI的区别主要是,传统的MRI为结构性成像(structural),扫描脑灰质,白质,脑脊液的形态结构等以判断是否有病变或损伤.fMRI(functional)功能成像,是基于大脑进行某项活动时局部脑区血氧水平的变化,来观察进行某项任务时所谓"脑激本回答被提问者采纳 参考技术B
功能性磁共振成像(fMRI,functional Magnetic Resonance Imaging)是一种神经影像学技术。其原理是利用磁振造影来测量神经元活动所引发之血液动力的改变。由于fMRI的非侵入性和其较少的辐射暴露量,从1990年代开始其就在脑部功能定位领域占有了重要地位。目前,fMRI主要被运用于对人及动物的脑或脊髓之研究中。
血氧浓度相依对比(BOLD)对于应用MRI于脑部功能性造影的重要性:血红素氧化状态(带氧血红素)的时候为抗磁性的,相对于缺氧血红素为顺磁性的。根据血液中血红素的氧化比率可轻易分辨出不同的磁共振信号。血液中带氧血红素的浓度上升,相对的BOLD信号也会随之加强。借由MRI搜集这些血氧浓度相依比讯号可以得知脑部中的血流与氧气消耗量值。虽然这些讯号是极小量的,但仍可以表现出脑部中脑区的活化程度。当脑部正思考或做动作或是接受一种经验过程,可以利用一系列严密的测量来确定哪些脑区是负责思考、运动、经历经验。
静息态fMRI是指在静息状态(睡眠/镇静状态)下研究脑区激活状态,任务态fMRI则是在完成指定任务的时候的脑区激活状态。由于在清醒状态下会有多个脑区处于激活状态,干扰因素多,所以目前的任务态fMRI都以单任务和少量任务为主(如用光刺激睡着的猴眼,睁眼的一小段时间内,脑区会从静息态切换到任务态,最先起反应的脑区就是与刺眼相关性最大的脑区,便于识别)。
医学影像:静息态fmri数据的预处理
文章目录
静息态fmri数据的预处理
静息态功能磁共振:指正常人脑在静息态下依然存在有规律的功能活动网络,且病理状态下的脑功能活动网络与正常人脑存在差异及重塑,被检者处于静息状态下应用血氧水平依赖脑功能成像获得脑活动功能图的成像技术。

静息态功能磁共振,相较于任务功能磁共振的优势:
该方法要求最小的依从性,避免了任务设计fMRI研究中与认知激活范式相关的潜在表现干扰因素,在临床研究中相对容易实施。
数据预处理的理论部分
STEP1:DICOM-》NIFTI
DICOM格式数据包括被试者的年龄、姓名、性别(扫描参数)、以及采集的时间序列等数据,但是后续我们用不到,所以就去除这些对我们没用的信息,将数据格式转换为NIFTI格式。

每个DICOM文件只是一个VOLUME(全脑)的一个SLICE(层),以“EXERCISE”文件夹中的一个被试者数据文件夹为例,采用GE机器采集,总共180个时间点(volume),每个时间点36层,共有6480个DICOM图像文件,如果是Siemens机器采集,一个DICOM文件就是一个volume信息。
NIFTI格式数据是被试者的一个时间点的VOLUME信息,包含了头文件及图像资料。 NIFTI格式也可使用独立的图像文件(.img)和头文件(.hdr)。单独的.nii格式文件的优势就是可以使用标准的压缩软件(如gzip)进行压缩,而且一些分析软件包(比如FSL)可以直接读取和写入压缩的.nii文件(扩展名为.nii.gz)。
格式转换工具:常用mricron里面的dcm2nii,也可以用SPM或者mricronvert等。
STEP2:删除前5-10个时间点的采集数据
刚开始采集时信号不稳定,并且需要受试者适应环境 。
STEP3:时间层校正(Slice Timing)
机器在扫描的时候,采用隔层扫描的方法,因为连续采集相邻层,两两之间可能会存在信号的干扰,这样会导致相邻Slice的时间间隔为T/2,需要将他们校正为相同时间。
STEP4:头动校正(Realign)
校正在扫描过程中时间点不同volume之间被试者的轻微头动1~2mm,该步骤不能完全去除头动带来的影响,需要进行Regress操作。
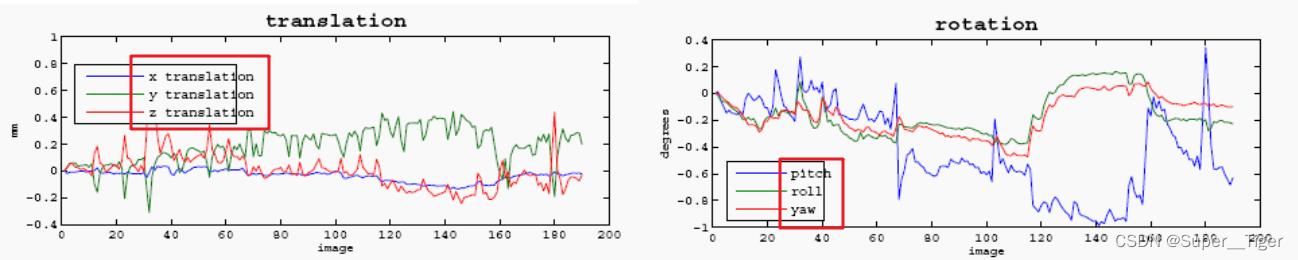
刚体变换在数据处理中的应用:SPM 里coregister(同一被试不同模态的对齐)和fMRI头动校正(realign),主要是平移和旋转操作。
仿射变换在数据处理中的应用:涡流校正、线性配准、非线性配准中的粗配,主要是平移、旋转、错切和缩放操作。
STEP5:配准(Normalize)
将不同被试个体空间的数据配准到标准空间,以解决不同被试之间脑形态的差异和扫描时空间位置不一致的问题。配准后理论上所有被试同一体素对应的解剖结构是相同的,从而可以在标准空间 进行基于体素的统计比较。
STEP6:平滑(Smooth)
1.减少配准误差; 2.增加数据信噪比; 3.增加数据的正态性以便进行统计分析。
STEP7:去除线性偏移(Detrend)
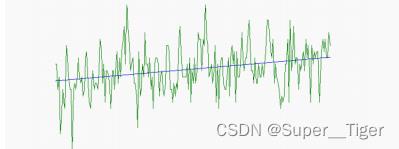
由于机器工作而升温以及被试长久扫描产生的疲劳,随着时间的积累会存在一个线性趋势,如上图所示。
STEP8:去除协变量(Regress)
减少头动、白质、脑脊液信号、全脑信号?的影响。
STEP9:滤波(Filter)
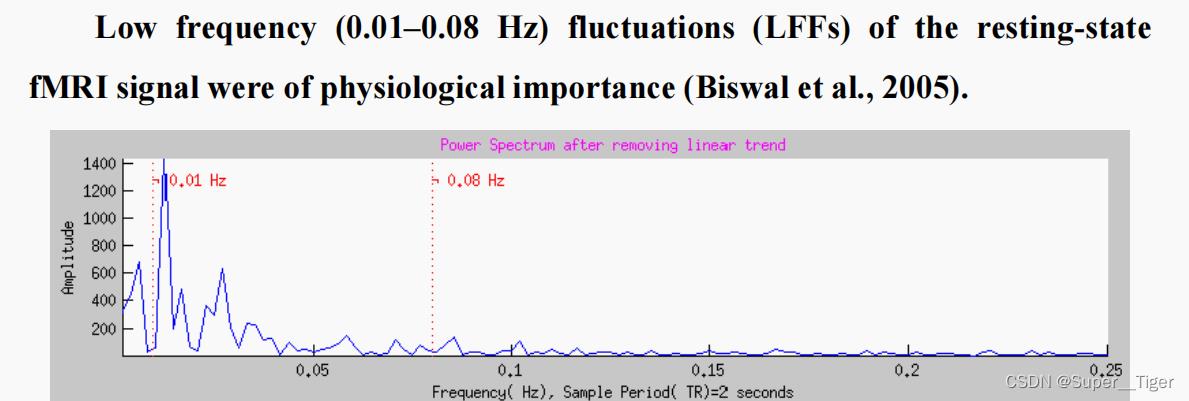
一般认为BOLD信号中低频成分主要反映脑自发的神经活动,具有生理意义(一般0.01~0.08或0.1HZ) 。
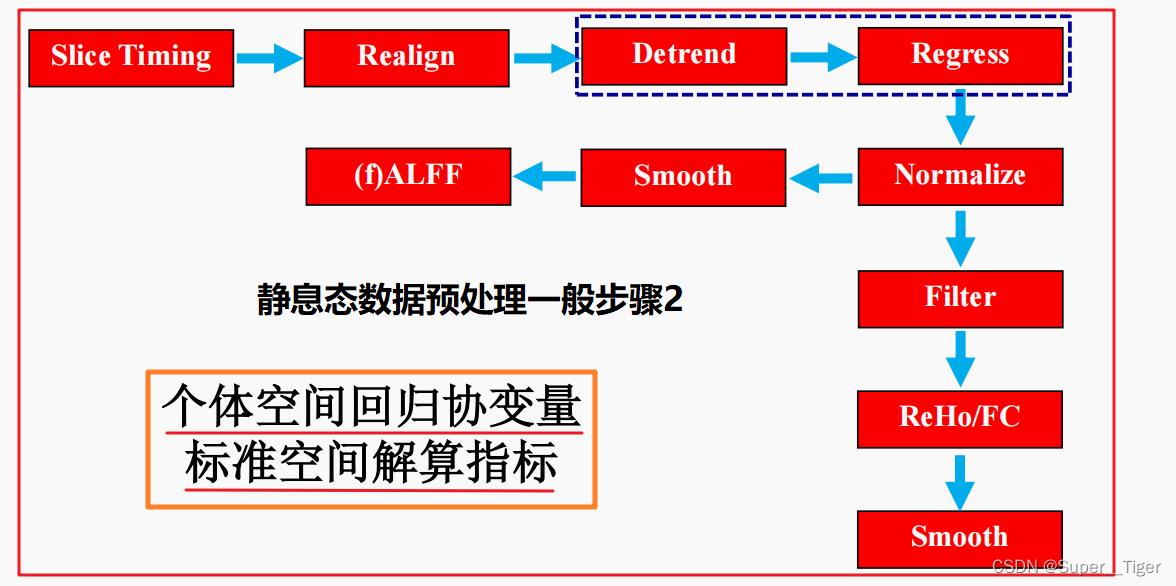
静息态数据预处理的一般步骤(参考)
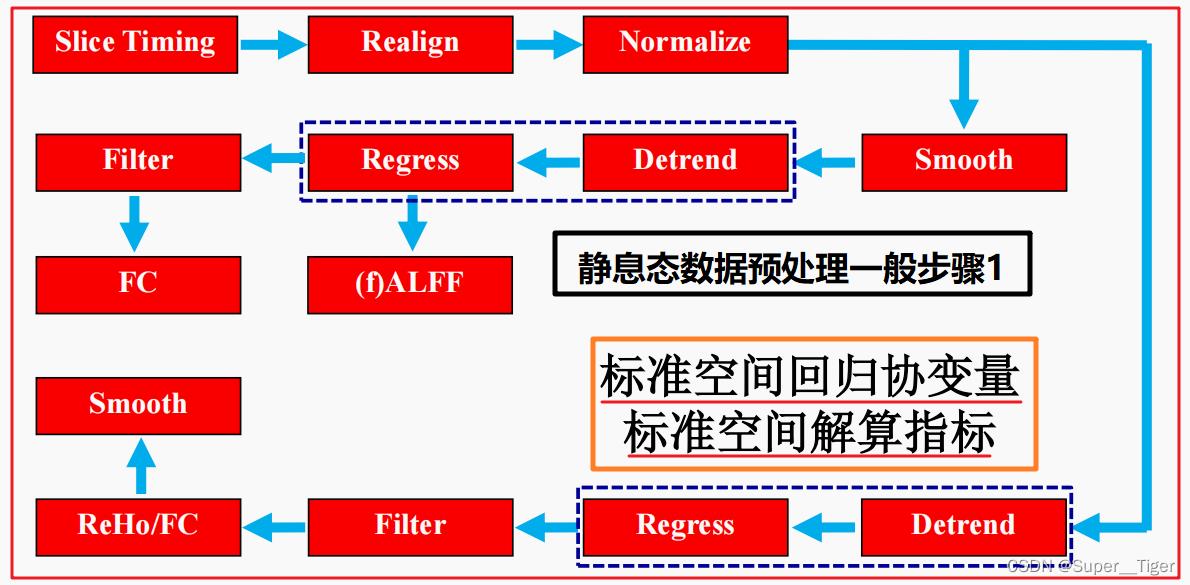
【备注:ReHo一定后平滑,ALFF、FC前后平滑都可以。】

常用的工具
- XJVIEW (section, slice, render)
- REST (section, slice)
- SPM (section, slice, render)
- Mricron (section, slice, render)
- BrainNet (render)
- render
- FSL (section)
- FreeSurfer (render)

【备注:section和slice、render的区别如图所示。】
数据预处理的实践部分
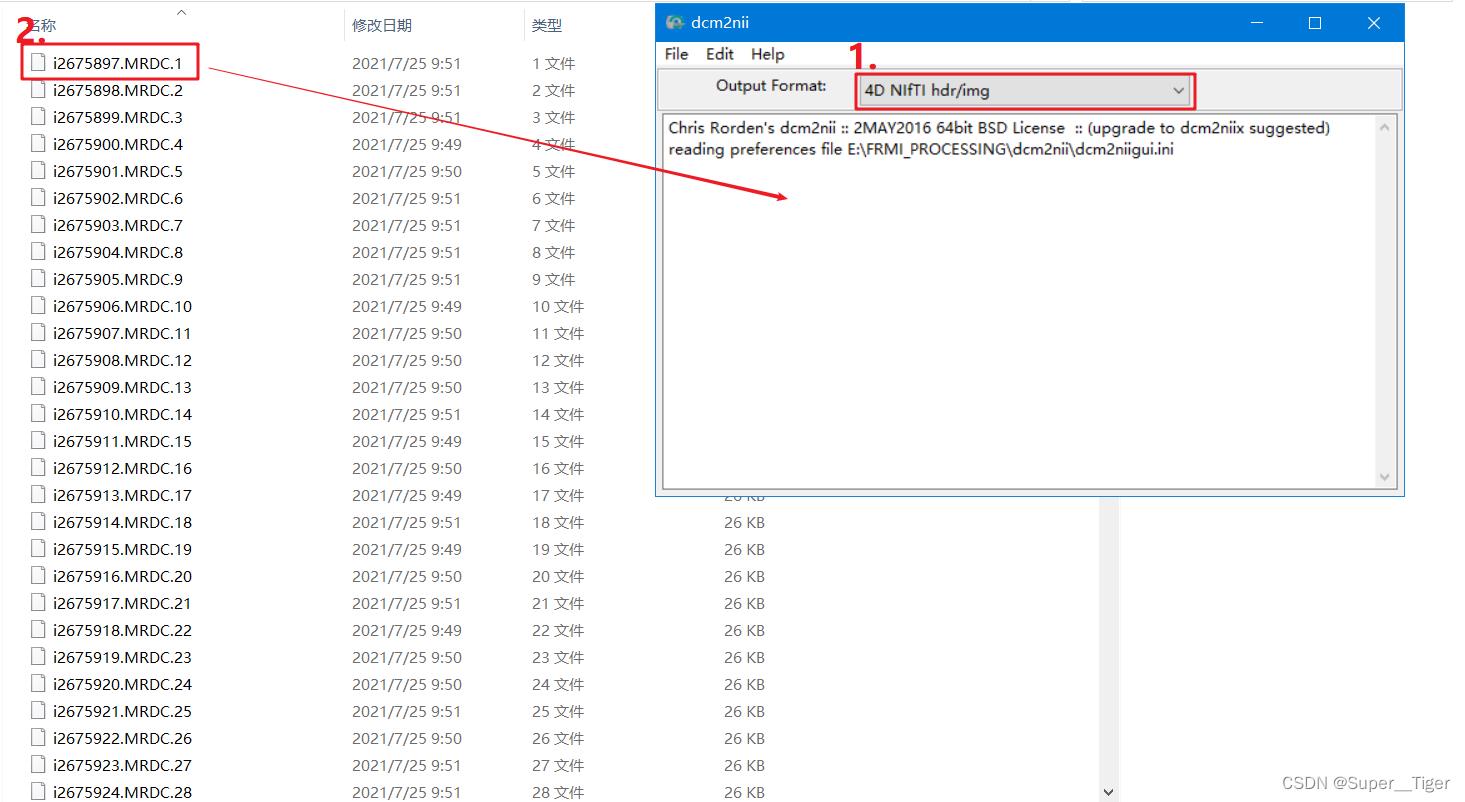
第一步,打开dcm2nii软件,然后选择Output Format为4D NifiTi hdr/img(其他的格式也都可以尝试一下)。
第二步,使用mricron软件打开nii文件,并参看相关的参数信息(TimePoints、RepetitionTime、SliceNumber)。
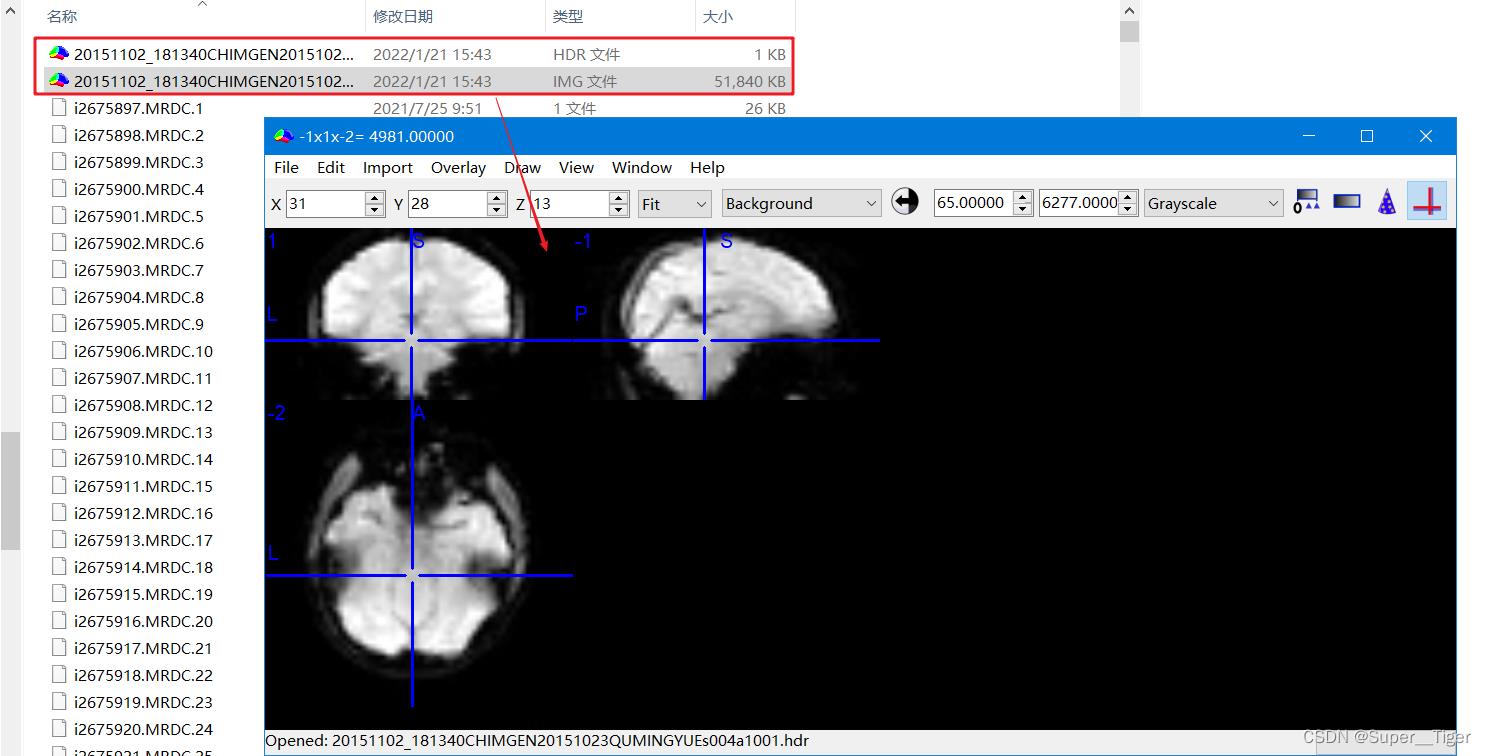

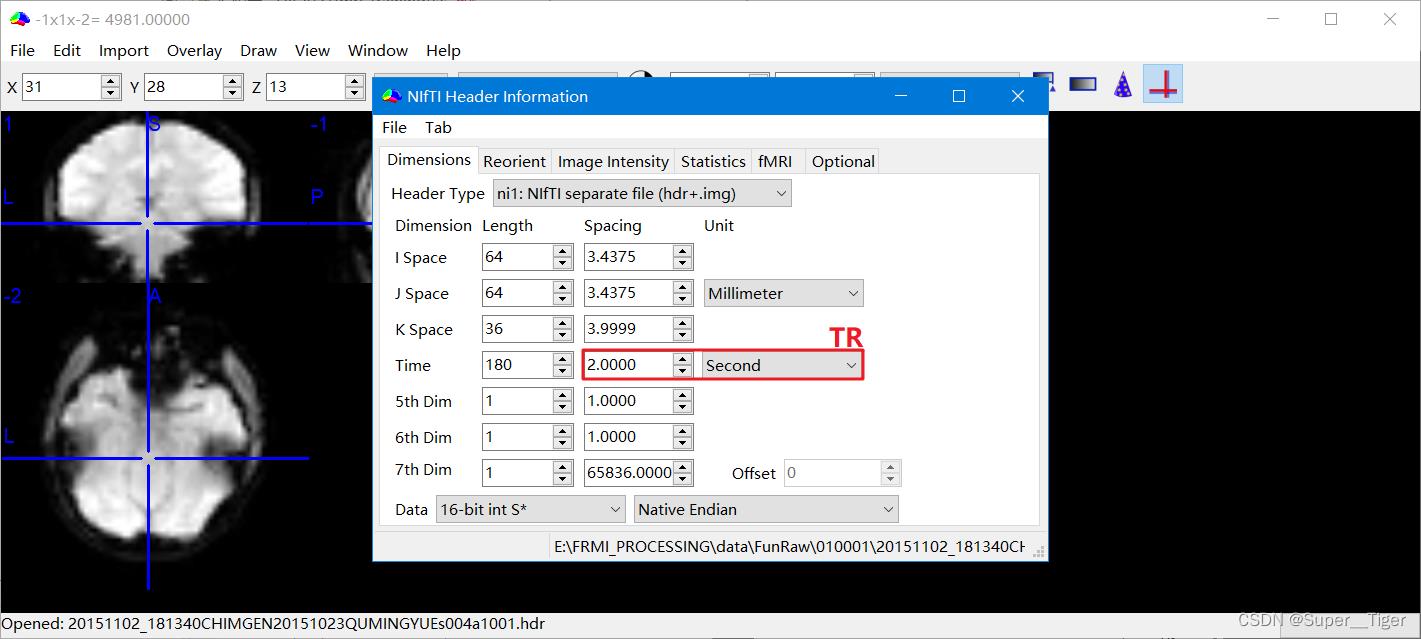
【注:``这里无法从DCM文件直接参看Slice Order,但是如果是处理好的nii文件,直接查看其json文件,可以看到"SliceTiming",依次推断出slice order`。】
第三步,设定好matlab_toolbox的路径,打开matlab的交互窗口,输入:DPARSFA。
第四步,设定好当前工作目录,即FunRaw和T1Raw的上一级目录。然后设定开始目录,按回车键,导入数据。
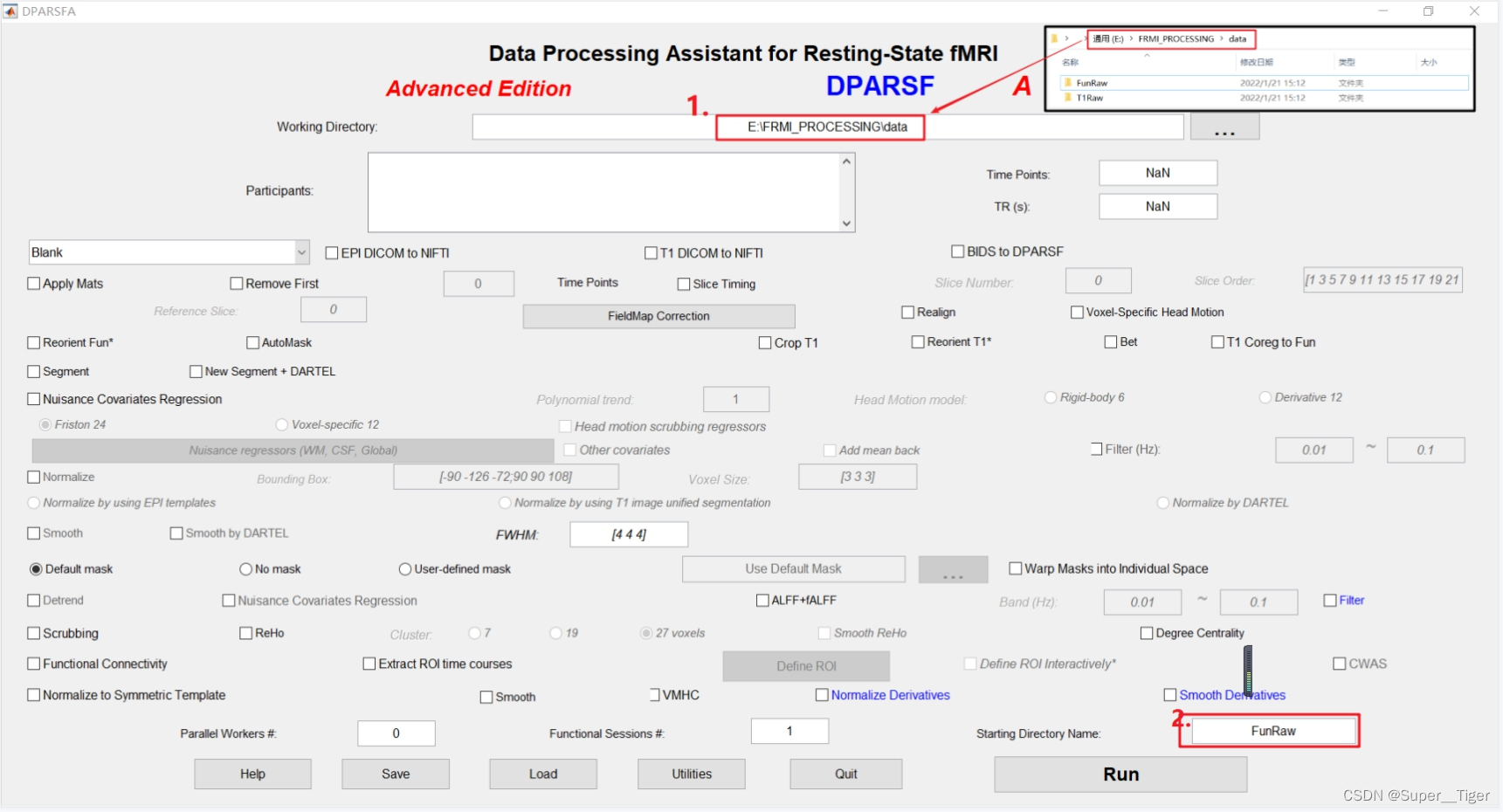
第五步,勾选并设定必要步骤的相关参数,执行RUN,并耐心等待结果的生成。

“A”框的说明:
- 该步骤是将DICOM格式文件转换为NIFTI格式文件,有功能项MRI勾选第一个,有对应的生理项MRI同时勾选第二个,第三个BIDS是新的开源数据格式(一般不用管)。
“B”框的说明:
- 该步骤是去除采集的前几个时间点,Time Points = 20(S)/TR(S),以这个为参考去除时间点数。
“C”框的说明:
- 时间层校正,因为采用的是隔层循环扫描技术,需要校正采集的数据顺序。
“D”框的说明:
- 一个Volume(全脑)影像的扫描层数,然后slice order是预先知道的,或者参看nii文件配套的json数据的SliceTiming,得到该扫描顺序。
“E”框的说明:
- 扫描完一遍的中间参考层,一个完整的Volume包括两次扫描,取第一次扫描的最后一层或者第二次扫描的第一层。
“F”框的说明:
- 头动校正,直接勾选就行。
“G”框的说明:
- 功能项的头动校正,当预处理进行到这里的时候,会弹出对话框,让我们自行对其进行手动输入参数微调人脑的位置,以及对不合格的数据进行筛除。
“H”框的说明:
- 因为生理项MRI包括一部分的脖子,所以有些学者认为去除脖子的部分,再将T1Raw和FunRaw进行配准,效果会更好。但是,这里需要注意的是程序对自动选定截取的位置,可能会导致脑区域的T1MRI也会被会切掉(一般不用选就行)。
“I”框的说明:
- 功能项的头动校正,去除脑壳,以及将T1配准到Fun(都勾选就行)。
“J”框的说明:
- 对脑区域进行分割,一般勾选NewSegment+DARTEL,分割的比较精准。
“K”框的说明:
- 根据采集数据的不同,选择亚洲还是欧美,因为脑骨结构不一样。
“I”框的说明:
- 确认是否回归协变量,勾选就行。
“M”框的说明:
- 回归机器发热带来的信号偏差,1代表线性回归,2代表二次多项式回归,3则代表三次多项式回归。
“N”框和“O”框的说明:
- 选取头动参数的计算和矫正方式,一般选用Friston24,即一个时间点计算24个头动参数,效果一般最好。
“P”框的说明:
- 可以对瞬间产生头动的时间点的数据进行阈值化删除,但是这个阈值需要参考文献,不可以随意设定。
“R”框的说明:
- 是否进行滤波,这里在实际的数据处理中有两种可能:如果是fALFF指标的计算,则不可以先滤波,要保留全频段;如果是其他指标则可以先进行滤波。
“S”框的说明:
- 是否进行组级别配准,勾选就行,把一个组的数据构建一个标准模板,再把这个模板配准到所有扫描的个体数据。
“T”框的说明:
- 输入体素的大小,要根据DICOM文件参看,一般输入的大小都是立方体格式。
“U”框的说明:
- 选择配准的方式,有T1项勾选DARTEL,没T1项勾选EPI,直接EPI也可以,EPI更快,DARTEL更准也更慢。
“V”框的说明:
- 是否进行平滑,并选择平滑的方式。这里有两种情况,对于ReHo、Degree Density等指标是不可以进行提前平滑的,因为是体素级别的指标,平滑会影响结果的准确性。
“W”框的说明:
- 输入平滑核的大小,一般选择voxel size的1.5~2倍大小,当然和具体的精确度要求也有关,平滑核小一些,肯定精度高一些;但是平滑核大一些,也可以提高信噪比,各有利弊。
“X”框的说明:
- 直接勾选Default mask就行。
“Y”框的说明:
- 这里只是选取了ALFF和fALFF(不能提前滤波)指标举例子,勾选就行。
“Z”框的说明:
- 因为需要计算fALFF,所以计算指标后进行滤波,滤波的频段范围在R框内进行设置。
和具体的精确度要求也有关,平滑核小一些,肯定精度高一些;但是平滑核大一些,也可以提高信噪比,各有利弊。
“X”框的说明:
- 直接勾选Default mask就行。
“Y”框的说明:
- 这里只是选取了ALFF和fALFF(不能提前滤波)指标举例子,勾选就行。
“Z”框的说明:
- 因为需要计算fALFF,所以计算指标后进行滤波,滤波的频段范围在R框内进行设置。
【备注:不同的指标计算有很多,这里暂时以ALFF和fALFF为例。】
以上是关于静息态 任务态fmri 啥意思的主要内容,如果未能解决你的问题,请参考以下文章