Oracle夺命连环25问,你能坚持第几问?
Posted IT邦德
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle夺命连环25问,你能坚持第几问?相关的知识,希望对你有一定的参考价值。
📢📢📢📣📣📣
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10年DBA工作经验
一位上进心十足的【大数据领域博主】!😜😜😜
中国DBA联盟(ACDU)成员,目前从事DBA及程序编程
擅长主流数据Oracle、mysql、PG 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
前言
文人从事多年面试工作,将Oracle面试分享给大家,希望大家顺利拿下offer🐴 第一股 SQL篇
🚀 1.1 Oracle中如何删除表中重复的记录?
平时工作中可能会遇到这种情况,当试图对表中的某一列或几列创建唯一索引时,
系统提示ORA-01452 :不能创建唯一索引,发现重复记录。这个时候只能创建普通索引或者删除重复记录后再创建唯一索引。
重复的数据可能有这样两种情况:第一种是表中只有某些字段一样,第二种是两行记录完全一样。
删除重复记录后的结果也分为两种,第一种是重复的记录全部删除,
第二种是重复的记录中只保留最新的一条记录,在一般业务中,第二种的情况较多。
1、删除重复记录的方法原理
在Oracle中,每一条记录都有一个ROWID,ROWID在整个数据库中是唯一的,ROWID确定了每条记录是在Oracle中的哪一个数据文件、块、行上。在重复的记录中,可能所有列上的内容都相同,但ROWID不会相同,所以,只要确定出重复记录中那些具有最大ROWID的就可以了,其余全部删除。
2、删除重复记录的方法
若想要删除部分字段重复的数据,则使用下面语句进行删除,下面的语句是删除表中字段1和字段2重复的数据:
DELETE FROM 表名
WHERE (字段1, 字段2) IN (SELECT 字段1,字段2 FROM 表名 GROUP BY 字段1,字段2 HAVING COUNT(1) > 1);
也可以利用临时表的方式,先将查询到的重复的数据插入到一个临时表中,然后进行删除,这样,执行删除的时候就不用再进行一次查询了。如下所示:
CREATE TABLE 临时表 AS (SELECT 字段1,字段2,COUNT() FROM 表名 GROUP BY 字段1,字段2 HAVING COUNT() > 1);
上面这句话的功能是建立临时表,并将查询到的数据插入其中。有了上面的执行结果,下面就可以进行删除操作了:
DELETE FROM 表名 A WHERE (字段1,字段2) IN (SELECT 字段1,字段2 FROM 临时表);
假如想保留重复数据中最新的一条记录,应该怎么做呢?可以利用ROWID,
保留重复数据中ROWID最大的一条记录即可,如下所示:
DELETE FROM TABLE_NAME WHERE ROWID NOT IN (SELECT MAX(ROWID)
FROM TABLE_NAME D GROUP BY D.COL1,D.COL2);
🚀 1.2 在Oracle中,有哪些常用的分析函数?
Oracle的分析函数主要用于报表开发和数据仓库。分析函数的功能强大,
可以用于SQL语句的优化,在某些情况下,能达到事半功倍的效果。
分析函数的一般格式是:函数名(参数列表) OVER ([PARTITION BY 字段名或表达式] [ORDER BY 字段名或表达式]),
其中OVER()部分称为开窗函数,它是可以选填的。开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化。
分析函数的写法比较复杂,下面将讲解几个常用的分析函数。
(一)RANK()分析函数
该函数的作用是根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置。
该函数的结果是不连续的,如果有4个人,其中有3个是并列第1名,那么最后的排序结果结果如:1 1 1 4。
还有一个类似的函数为:DENSE_RANK()OVER(ORDER BY 列名排序),它的排序结果是连续的,
如果有4个人,其中有3个是并列第1名,那么最后的排序结果如:1 1 1 2
(二)LAG和LEAD分析函数
LAG和LEAD函数可以在一次查询中取出同一字段的前N行的数据和后N行的值。
这种操作可以使用对相同表的表连接来实现,不过使用LAG和LEAD有更高的效率。
LAG可以访问当前行之前的行,LEAD与LAG相反,LEAD可以访问当前行之后的行。
(三)RULLUP分析函数
ROLLUP分组函数可以理解为Group By分组函数封装后的精简用法。
除此之外,还有COUNT() OVER、GROUP BY CUBE、RATIO_TO_REPORT、AVG OVER、MAX OVER等等常用的分析函数
🚀 1.3 Oracle日期函数可实现哪些功能?
有关日期函数需要了解以下几点:
(1)日期函数用于处理DATE类型的数据。
(2)在日期上加上或减去一个数字结果仍为日期。
(3)两个日期相减返回日期之间相差的天数。
(4)默认情况下,日期格式为DD-MON-RR。
(5)查询当前数据库日期格式的命令:
SELECT SYS_CONTEXT(‘USERENV’,‘NLS_DATE_FORMAT’) FROM DUAL;。
(6)SYSDATE:该函数返回系统时间。
(7)LAST_DAY(D):返回指定日期所在月份的最后一天。
(8)MONTHS_BETWEEN:表示两个日期的月份之差,即在给定的两个日期之间有多少个月。
(9)ADD_MONTHS(D,N):该函数将给定的日期增加N个月。当N为正数时,
该函数将给定的日期增加N个月,
为负数时减去N个月,该函数很常用,可以用来表示上个月、下个月,去年和下一年等等。
(10)NEXT_DAY(D,N):返回以时间点D为基准(开始),下一个“目标日N”的日期。
由于数据库以数字方式存储日期,因此,日期类型可以进行算术运算(加法或减法)。
例如:可以给日期增加或减去一个数字,得到的结果还是一个日期值,两个日期相减,得到两个日期之间的天数,用小时除以24就可以得到天数。
🚩 奇淫巧技,难缠的日期处理大全,真香
https://jeames.blog.csdn.net/article/details/124906602
🚀 1.4 在Oracle中,ROWID和ROWNUM的区别是什么?
Oracle有两个著名的伪列ROWID和ROWNUM,下面分别来介绍它们。
(一)ROWID
ROWID是一个伪列,既然是伪列,那么这个列就不是用户定义,而是系统自己给加上的。对每个表都有一个ROWID的伪列,但是表中并不物理存储ROWID列的值。
不过可以像使用其它列那样使用它,但是不能删除该列,也不能对该列的值进行修改、插入。
ROWID对访问一个表中的给定的行提供了最快的访问方法,通过ROWID可以直接定位到相应的数据块上,然后将其读到内存。
当创建一个索引时,该索引不但存储索引列的值,而且也存储索引值所对应的行的ROWID,这样通过索引就可以快速找到相应行的ROWID,
通过该ROWID,就可以迅速将数据查询出来。这也就是在使用索引查询时,速度比较快的原因。
一般来说,当表中的行确定后,ROWID就不会发生变化,一旦一行数据插入数据库,ROWID在该行的生命周期内是唯一的,
即使该行产生行迁移,行的ROWID也不会改变,UPDATE不会改变ROWID,INSERT更不会。
从ROWID定义可知,只有当数据行的物理位置改变时才会导致ROWID改变,
所以,只需要关心那些会导致数据物理位置变化的操作即可。
ROWID可以分为以下几种类型:
l 物理ROWID:存储堆组织表、表簇、表分区、和索引分区中的行地址。
l 逻辑ROWID:存储索引组织表中的行地址。
l 外部ROWID:是外来表(如通过网关访问的DB2表)中的标识符。它们不是标准的Oracle数据库ROWID。
有一种数据类型称为通用ROWID或UROWID,支持各种ROWID。
当如下情况发生时,ROWID将发生改变,即当数据迁移到其它块的时候,ROWID就会改变:
(1)对一个表做表空间的移动或重建后。
(2)对一个表进行了exp/imp或expdp/impdp后。
(3)MOVE、FLASHBACK TABLE、修改分区键值到另一个分区、分区表的分区数据转移到其它分区、SHRINK TABLE等。
通过DBMS_ROWID可以获取文件号、块号等信息。
(二)ROWNUM
ROWNUM是一个伪列,不是真正的列,在表中并不真实存在,
它是Oracle数据库从数据文件或缓冲区中读取数据的顺序。
切勿理解成记录的行号(这是很多人一直这样认为的),例如想查询第二行记录按下面的方法是查询不到的:
SELECT * FROM SCOTT.TABLE_LHR WHERE ROWNUM=2;
ROWNUM主要应用于Top-N查询中。
🚀 1.5 简述下Oracle的对象?
1.数据库对象
表:列组成表的结构,行组成表的数据;
视图:存储在数据字典中的一条 select 语句;
序列:一种生成唯一数字的结构,有序的发出数字;
索引:可以减少对表中行的访问次数、提高查询性能;
同义词:别名
2 对象命名规则
【表名和列名】
必须以字母开头
必须在1-30个字符之间
必须只能包含A-Z,a-z,0-9,_,$和#
必须不能和用户定义的其他对象重名
必须不能是Oralce的保留字
🚀 1.6 简述下Oracle的事务?如何开始及结束
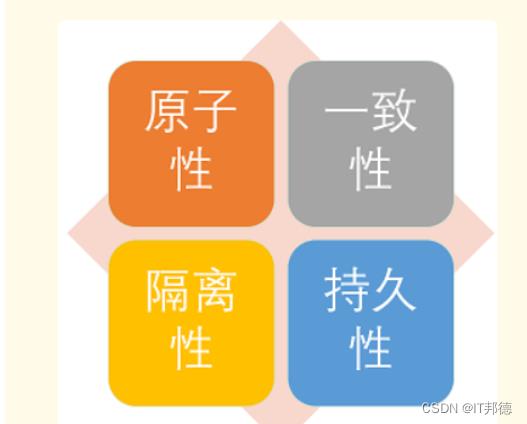
事务的ACID 属性
原子性:Atomicity 一致性:Consistency 隔离性:Isolation 持久性:Durability
原子性:一个事务的所有部分必须都完成,或者都不完成;
一致性:查询的结果必须与数据库在查询开始时的状态一致;
隔离性:除了作出变更的会话,其他会话都无法看到未提交的数据;
持久性:事务一旦完成,所有用户必须能够立刻看到所做的变更,同时数据库必须保证这些 变更不会丢失(数据库通过日志保持事务的持久性)
【事务开始和结束】
开始:以第一个DML语句的执行作为开始
结束:以下面的其中之一作为结束
COMMIT或者ROLLBACK语句
DDL或者DCL语句(自动提交)
SQL Developer or SQL*Plus用户正常退出(提交)
系统崩溃(异常终止时自动进行隐式回滚提交)
🐴 第二股 体系架构
🚀 2.1 Oracle的逻辑存储结构有哪些?
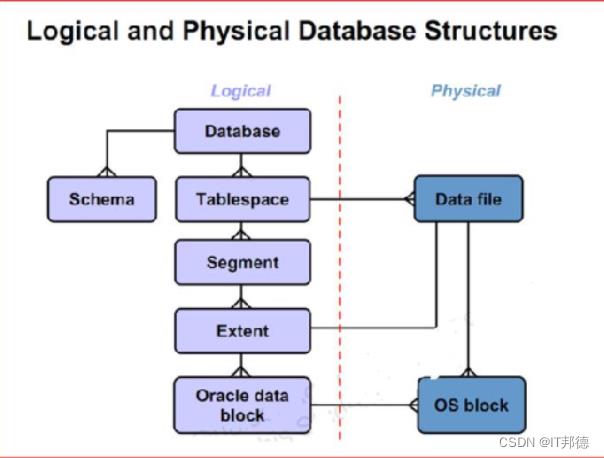
将逻辑存储与物理存储分开是关系数据库范例的要求之一。
oracle 数据库的数据的处理发生在 instance(内存)中,但数据的存储发生在磁盘的 database上。
oracle 数据库逻辑存储结构可分为数据库、表空间、段、区、块几个层次。
【表空间和数据文件】
数据在物理上是存储在数据文件(data files)上,从逻辑上看数据存储在段(通常是表)中,表空间是二者的抽象, 是一个逻辑的概念
表空间的使用解决了这个问题, 消除了段和数据文件之间多对多的关系,一个表空间可能包含多个段(对象),并由多个数据文件组成,但一个数据文件只能对应一个表空间。
查看表空间信息
SYS@PROD>select tablespace_name,contents,status from dba_tablespaces;
查看表空间对应数据文件
SYS@PROD>select file_id,file_name,tablespace_name,bytes/1024/1024 m from dba_data_files;
② 段、区、块
段(segment): 段是表空间中存储数据的数据库对象。
表是典型的段,还有其他段类型比如索引段、 undo 段。
任何一个段可以仅存在于一个表空间中,但表空间可以由多个数据文件组成。
这样表的大小就不再受单个数据文件大小限制。
段是模式对象,由具体某一个用户(模式)限定。
注意: PL/SQL 过程、视图、序列不是段,它们不存储数据,存在于数据字典中。
SYS@PROD>select segment_name,segment_type,tablespace_name,bytes/1024 k,extents,blocks
from dba_segments where owner=‘SCOTT’;
区(extent)
区是 oracle 空间分配的基本单元。 区是一组连续编号的 oracle 块。
这些区可能位于构成表空间的一个或多个数据文件中。
块(block)
oracle 块是数据库 I/O 的基本单位。 数据文件设置为连续编号的 oracle 块。
一个块中可能有多个行,但当会话需要某行数据时,是从磁盘将整个块读入到数据缓冲区。
同样,dbwr 写脏块时也是把整个块写入数据文件。
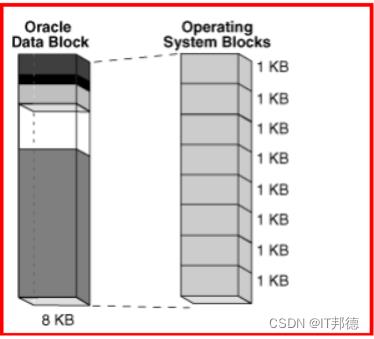
对表空间来说,块大小是固定不变的。 11g 默认标准块大小是 8KB,
在创建数据库时确定db_block_size 参数,不能修改。
从物理上讲,数据文件由操作系统块组成,操作系统块是文件系统 I/O 的基本单位。通常 oracle
块和操作系统块是一对多的关系,比如上图, oracle 块是 8KB,操作系统块大小是 1KB
🚀 2.2 在Oracle中,如何启动监听日志?
Oracle监听器是一个服务器端程序,用于监听所有来自客户端的请求,并为其提供数据库服务。
监听器日志有如下特性:
① 监听器日志是一个纯文本文件,通常位于$ORACLE_HOME/network/log目录下,
与sqlnet.log日志文件处于同一路径。在Oracle 11g下,可能位于$ORACLE_BASE/diag/tnslsnr/$hostname/listener/trace下。
② 监听器日志缺省的文件名为listener.log。对于非缺省的监听器,则产生的日志文件通常为listenername.log。
③ 监听器日志文件缺省由监听器自动创建,当日志文件丢失时或不存在时,会自动重新创建一个同名的文件,与告警日志文件类似。
④ 监听器日志文件的尺寸会不断自动增长,当尺寸过大时可能产生一些监听错误,这个时候可以考虑将其备份。
⑤ Oracle监听器在运行时不允许对日志文件做删除,重命名操作。
⑥ 可以设置日志状态为ON或OFF来实现启用或关闭日志。
以下是一些常用的设置:
l 设置监听器日志文件目录:lsnrctl SET LOG_DIRECTORY directory
l 设置监听器日志文件名:lsnrctl SET LOG_FILE file_name
l 设置监听器日志的状态:lsnrctl SET LOG_STATUS on | off
🚀 2.3 简述下Oracle实例启动的过程?
1 nomount 阶段:started
读取初始化参数文件,分配内存、启动后台进程(生成 instance)
SYS@PROD>startup nomount;
SYS@PROD>select status from v$instance;
查看告警日志信息 查看后台进程
[oracle@enmoedu1 ~]$ ps -ef | grep ora_
nomount 状态可以查看参数信息
SYS@PROD>show parameter sga
2 mount 阶段:mounted
读取控制文件,获取文件位置和数据库相关信息(控制文件是二进制文件,记录数据库的物理状态,维护数据库的一致性)
SYS@PROD>alter database mount;
mounted 状态可以查看 v$视图信息。
如:SYS@PROD>select name from v$datafile;
v$instance 特殊,nomount 状态也能查。
3 open 阶段:open
1、检查所有的 datafile、redo log、 group 、password file 正常
2、检查数据库的一致性(controlfile、datafile、redo file 的检查点是否一致)
SYS@PROD>select file#,checkpoint_change#,last_change# from v$datafile; 从控制文件读出
SYS@PROD>select file#,checkpoint_change# from v$datafile_header; 从数据文件读出
注意:启动到 mount 状态时,last_change#不为空说明之前是干净的关闭数据库
【启动数据库时的一些特殊选项】
startup force; 相当于 shutdown abort 后再接 startup
startup nomount; (启动到 nomount 状态,alter database mount;alter database open;)
startup mount; (启动到 mount 状态太,alter database open;)
startup upgrade 只有 sysdba 能连接
startup restrict 有 restrict session 权限才可登录,sys 不受限制
alter system enable restricted session;
open 后再限制 alter database open read only; 只读方式开库,scn 不会增
SCN:system change number 系统改变号
oracle 内部时钟,不断增长,记录事务发生的先后顺序 controlfile、logfile、datafile_header、block
SYS@PROD> select current_scn,dbms_flashback.get_system_change_number from v$database;
🚀 2.4 简述下Oracle的控制文件?
- 功能和特点
记录数据库当前物理状态
维护数据库的一致性
是一个二进制小文件
在 mount 阶段被读取
记录 RMAN 备份的元数据
物理状态记录在控制文件中:
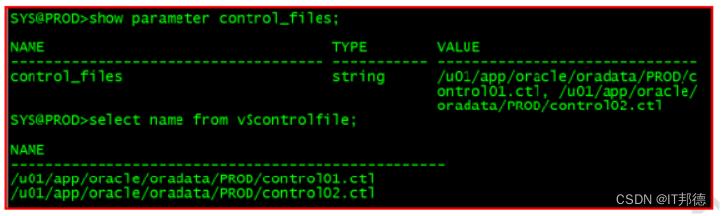
SYS@PROD>select name from v d a t a f i l e ; S Y S @ P R O D > s e l e c t m e m b e r f r o m v datafile; SYS@PROD>select member from v datafile;SYS@PROD>selectmemberfromvlogfile;
查看控制文件位置:
SYS@PROD>show parameter control_files;
SYS@PROD>select name from v$controlfile;
通常使用多个控制文件存放在不同位置(多路复用),互为镜像。- 实时更新机制
当增加、重命名、删除一个数据文件或者一个联机日志文件时,Oracle 服务器进程(Server Process)会立即更新控制文件以反映数据库结构的变化。
日志写进程 LGWR 负责把当前日志序列号记录到控制文件中。
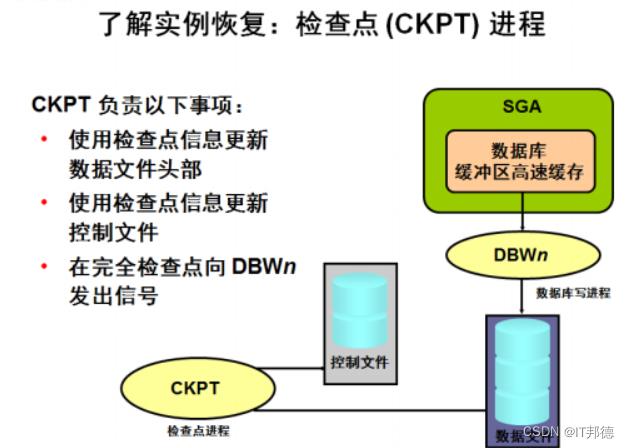
检查点进程 CKPT 负责把校验点的信息记录到控制文件中。
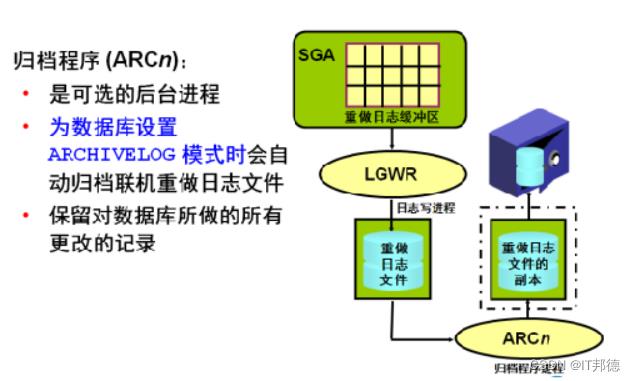
归档进程 ARCN 负责把归档日志的信息记录到控制文件中。
通过视图 v$controlfile_record_section 可以了解到控制文件中记录了大量的数据库当前状态信息
🚀 2.5 Oracle中redo日志的作用是?
- 作用和特征
作用:数据 recovery 特征:
1)记录数据库中块的变化(DML、DDL)
2)用于数据块的 recover
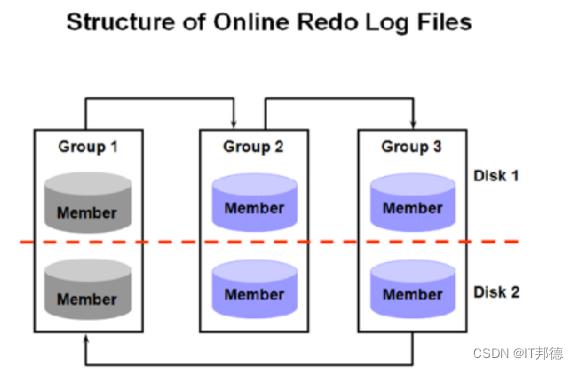
3)以组的方式管理 redo file,最少两组 redo,循环使用
4)和数据文件存放到不同的磁盘上,需读写速度快的磁盘(比如采用 RAID10)
5)日志的 block 和数据文件的 block 不是一回事
SYS@PROD>select max(lebsz) from x$kccle;
2.日志组
1)最少两组,最好每组有两个成员(多路复用),并存放到不同的磁盘上,大小形同,互相 镜像
2)日志在组写满时将自动切换
①归档模式:将历史日志连续的进行保存
②非归档:历史日志被覆盖
③切换产生 checkpoint(延迟),通知 dbwn 写脏块 并且更新控制文件
3)在归档模式,日志进行归档,并把相关的信息写入 controlfile
🚀 2.6 归档和非归档的区别
1)归档会在日志切换时,备份历史日志,对于 OLTP 系统都应考虑归档模式,
以便数据库能 支持热备,并提供数据库完全恢复和不完全恢复(基于时间点)
2)归档会启用 arcn 的后台进程、也会占用磁盘空间
3)非归档适用某种静态库、测试库、或者可由远程提供数据恢复的数据库。
非归档只能冷备, 且仅能还原最后一次全备。归档可以恢复到最后一次 commit
🚀 2.7 Oracle中Undo 作用是?
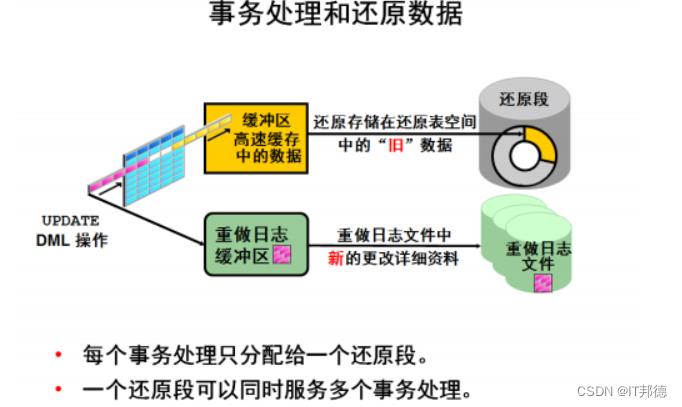
UNDO数据是原始的、修改之前的数据副本;是针对更改数据的每个事务处理所捕获的,至少保留到事务处理结束。
UNDO 提供以下四种情况所需要的信息
1)回滚事务:rollback
2)读一致性:正在做 DML 操作的数据块,事务结束前,其他用户读 undo 里面的数据前镜像
3)实例的恢复:instance recover(undo -->rollback)
4)闪回技术 :flashback query、flashback table 等
🚀 2.8 什么是Oracle的 checkpoint?作用是?
1.检查点概念
“检查点”是一种数据结构,用于定义数据库的重做日志中的系统更改号 (SCN)。
检查点 被记录在控制文件和每个数据文件头中。
每隔三秒,CKPT 进程就会在控制文件中存储一次数据,以记录 DBWn 已将哪些脏块从 SGA 写到磁盘。
每次刷新截止的那个块的位置就叫检查点位置 checkpoint position。
如果发生日志切换,则 CKPT 进程还会将此检查点信息写入数据文件的头部。
文件头中记录的 SCN 可保证将该 SCN 之前对数据库块进行的所有更改写入到磁盘中。
2. 检查点作用
1)保证数据库的一致性。一致性关闭数据库时,确保所有 commit 的数据写到磁盘上。
2)确保内存中脏块定期写入磁盘。
3)缩短实例恢复的时间。实例恢复时,要把实例异常关闭前没有写到硬盘的脏数据通过日志 进行恢复。
只需要处理上一个检查点之后的联机重做日志文件条目,从而减少实例恢复的时间。
3. 检查点分类
在 Oracle8i 之前,数据库的发生的检查点都是完全检查点。
完全检查点会将数据缓冲区 里面所有的脏数据块写入相应的数据文件中,并且同步数据文件头和控制文件,保证数据库 的一致。
由于完全检查点会将所有的脏数据库块写入,巨大的 IO 往往会影响到数据库的性能。
因 此 Oracle 从 8i 开始引入了增量检查点的概念。
🐴 第三股 备份恢复篇
🚀 3.1 Oracle备份恢复的分类有哪些?

1.逻辑备份与恢复
①传统的导入导出:exp/imp:
②数据泵导入导出:expdp/impdp
面向 object,逻辑备份就是热备数据库对象某一时刻状态,不能运用在 media failure 上,
逻辑备份的恢复就是还原备份,没有 recover 的概念。
2. 物理备份与恢复
面向 media failure
①手工备份与恢复,也叫用户管理的备份与恢复(UMAN),
通过 OS 的命令,完成备份与还原,然后再运用日志进行恢复。
②自动备份与恢复,利用 oracle 的备份恢复工具 RMAN,使还原与恢复过程自动完成。
物理备份从方式上可以有 一致性备份(冷备) 和 非一致性备份(热备)
完整的备份策略应该以物理备份为主,逻辑备份为辅(用于备份一些重要的表)
3 闪回技术
一种利用 undo 数据或闪回日志的快速恢复技术。可以针对不同层面问题进行逻辑恢复,
11g 支持七种 flashback 方式,其中快速恢复区只和闪回数据库有关。
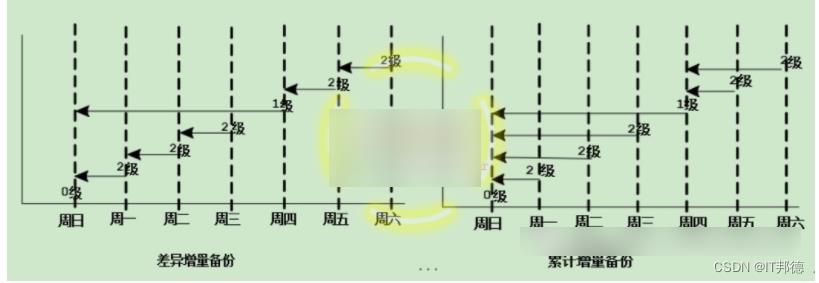
🚀 3.2 在Oracle中,差异和累积增量备份区别是什么?
数据库备份可以分为完全备份和增量备份。完全数据文件备份是包含文件中所有已用数据块的备份。RMAN将所有块复制到备份集或映像副本中,仅跳过从未使用的数据文件块。完全映像副本可准确地再现整个文件的内容。完全备份不能成为增量备份策略的一部分;它也不能作为后续增量备份的基础。
增量备份就是将那些与前一次备份相比发生变化的数据块复制到备份集中。通过RMAN可以为单独的数据文件、表空间、或者整个数据库进行增量备份。增量备份是0级备份,其中包含数据文件中除从未使用的块之外的所有块;或者是1级备份,其中仅包含自上次备份以来更改过的那些块。0级增量备份在物理上与完全备份完全一样。唯一区别是0级备份可用作1级备份的基础,但完全备份不可用作1级备份的基础。要使用增量备份,必须先执行0级增量备份。
通过BACKUP命令中的INCREMENTAL关键字可指定增量备份,可以指定INCREMENTAL LEVEL[0|1]。在RMAN中建立的增量备份可以具有不同的级别,每个级别都使用一个不小于0的整数来标识,也就是在BACKUP命令中使用LEVEL关键字指定的,例如LEVEL = 0表示备份级别为0,LEVEL = 1表示备份级别为1。每次进行增量备份仅操作那些发生了“变化”的数据块。RMAN中增量备份有两种:差异增量备份(DIFFERENTIAL)和累计增量备份(CUMULATIVE),
它们的区别如下表所示:

🚀 3.3 在Oracle中,如何闪回表?
原理:利用的是Undo表空间的undo数据,闪回表到某个时间点或某个SCN
##连接SCOTT用户创建业务表:
conn scott/tiger
create table fb_1 (id number);
insert into fb_1 values(10);
commit;
alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss';
select sysdate from dual;
##查看此时的时间或者SCN:
时间:
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual;
2021-09-11 10:17:27
SCN:conn / as sysdba
select current_scn from v$database;
CURRENT_SCN
-----------
1071438
##执行数据删除操作:
delete from scott.fb_1;
commit;
##闪回表到数据删除之前
开启被闪回表的行迁移:
14:42:45 SYS@PROD> alter table scott.fb_1 enable row movement;
闪回查询确认数据:
select * from scott.fb_1 as of scn 1071438;
执行闪回,可以执行多次闪回操作:
flashback table scott.fb_1 to scn 1071438;
或者
flashback table scott.fb_1
to timestamp to_timestamp('2021-09-11 10:17:27','yyyy-mm-dd hh24:mi:ss');
验证数据:
SYS@PROD> select * from scott.fb_1;
ID
----------
10
##关闭行迁移
SYS@PROD> alter table scott.fb_1 disable row movement;
🚀 3.3 简述下Oracle的数据泵技术
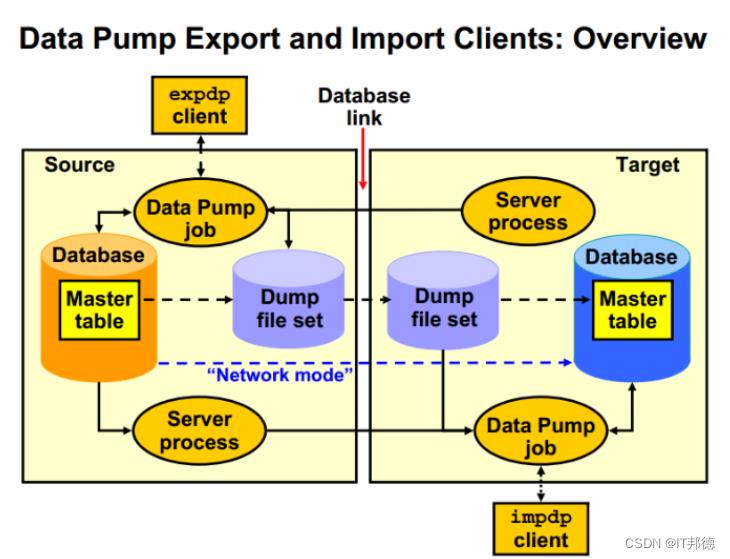
1.1 数据泵组成部分
①数据泵核心部分程序包:DBMS_DATAPUMP
②提供元数据的程序包:DBMS_MATADATA
③命令行客户机(实用程序):EXPDP,IMPDP
1.2 数据泵文件
①转储文件:此文件包含对象数据
②日志文件:记录操作信息和结果
③SQL 文件: 将导入作业中的 DDL 语句写入 SQLFILE 指定的参数文件中
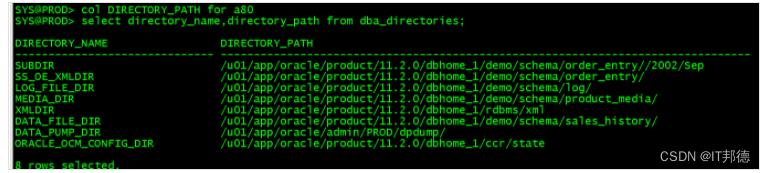
1.3 数据泵的目录及文件位置
以 sys 或 system 用户完成数据泵的导入导出时,可以使用缺省的目录 DATA_PUMP_DIR
如果设置了环境变量 ORACLE_BASE,则 DATA_PUMP_DIR 缺省目录位置是:
$ORACLE_BASE/admin/database_name/dpdump
否则是:
$ORACLE_HOME/admin/database_name/dpdump
也可以指定自定义创建的 directory
SYS@PROD>col directory_name for a25
col DIRECTORY_PATH for a80
select directory_name,directory_path from dba_directories;
🐴 第四股 高可用篇
🚀 4.1 在Oracle中,集群(Cluster)后台进程有哪些?
集群由若干进程组成,其中,最重要的几个进程包括:OCSSD、CRSD、EVMD等。在安装集群软件的最后阶段,会要求在每个节点执行root.sh脚本,这个脚本会在/etc/inittab文件的最后把这3个进程加入启动项(从Oracle 11g开始变为了ohasd这一个进程),这样以后每次系统启动时,集群也会自动启动。如果EVMD和CRSD两个进程出现异常,那么系统会自动重启这两个进程。如果是OCSSD进程出现异常,那么系统会立即重启。
(1)OCSSD(ocssd.bin)
OCSSD(Oracle Cluster Synchronization Service Daemon)进程是集群最关键的进程,它提供CSS服务。如果这个进程出现异常,那么会导致系统重启。CSS服务通过多种心跳机制实时监控集群状态,提供脑裂保护等基础集群服务功能。需要注意的是,除了集群需要这个进程外,在单实例环境中,如果使用了ASM(Auto Storage Management,自动存储管理),那么也需要这个进程。这个进程用于支持ASM实例和RDBMS实例之间的通信。
(2)CRSD(crsd.bin)
CRSD(Cluster Ready Service Daemon)是实现“高可用性(HA)”的主要进程,它提供的服务叫作CRS服务。Oracle集群是位于集群层的组件,它要为应用层资源(CRS Resource)提供“高可用性服务”,所以,Oracle集群必须监控这些资源,并在这些资源运行异常时进行干预,包括关闭、重启进程或者转移服务。CRSD进程提供的就是这些服务。所有需要高可用性的组件,都会在安装配置的时候,以CRS Resource的形式登记到OCR(Oracle Cluster Registry)中,而CRSD进程就是根据OCR中的内容决定监控哪些进程,如何监控,出现问题时又如何解决。也就是说,CRSD进程负责监控CRS Resource的运行状态,并要启动、停止、监控、Failover这些资源。默认情况下,CRS会自动尝试重启资源5次,若还是失败,则放弃尝试。
CRS Resource包括GSD(Global Serveice Daemon)、ONS(Oracle Notification Service)、VIP、Database、Instance和Service。这些资源被分成2类:GSD、ONS、VIP和Listener属于Nodeapps类,Database、Instance和Service属于Database-Related Resource类。Nodeapps是指每个节点只需要一个就够了,例如每个节点只有一个Listener,而Database-Related Resource是指这些资源和数据库有关,不受节点的限制,例如一个节点可以有多个实例,每个实例可以有多个Service。GSD、ONS和VIP这3个服务是在安装Clusterware的最后,执行VIPCA时创建并登记到OCR中的。Database、Listener、Instance和Service是在各自的配置过程中自动或者手动登记到OCR中的。
(3)EVMD(evmd.bin)
EVMD(Event Manager Daemon)这个进程负责发布CRS产生的各种事件(Event)。这些事件可以通过两种方式发布给客户:ONS和Callout Script。EVMD进程除了发布复杂事件之外,它还是CRSD和CSSD两个进程之间的桥梁。CRS和CSS两个服务之间的通信就是通过EVMD进程完成的。
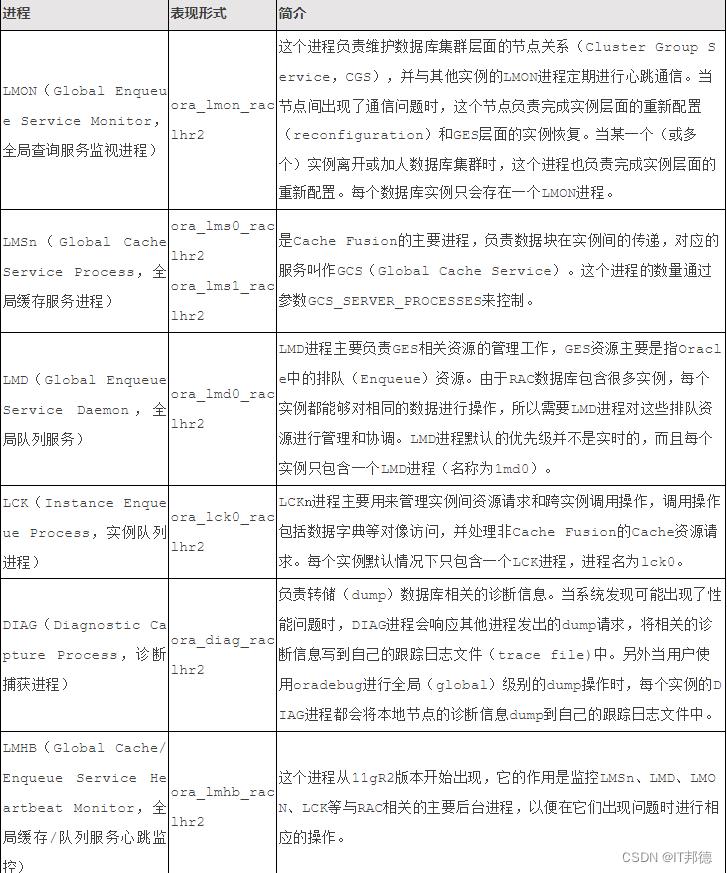
除了以上3个进程外,还有一些其它的进程参考下表:
🚀 4.2 在Oracle中,ASM是什么?它有哪些优点?
ASM(Auto Storage Management,自动存储管理)是一种用于管理磁盘的工具。ASM是Oracle为了简化数据库的管理而推出来的一项新功能,这是Oracle自己提供的卷管理器,主要用于替代操作系统所提供的LVM,它不仅支持单实例,同时对RAC的支持也是非常好。ASM可以自动管理磁盘组并提供有效的数据冗余功能。使用ASM后,DBA不再需要对Oracle中成千上万的数据文件进行管理和分类,从而简化了DBA的工作量,可以使得工作效率大大提高。ASM支持Data Files,Online Log Files,Control Files,Archived Logs,RMAN backup sets等文件。
有关ASM需要掌握如下几点内容:
① ASM能够在多个物理设备之间实现条带化、镜像数据文件、恢复文件等。
② 文件按分配单元AUs(Allocation Units)平衡分布在磁盘组的所有磁盘中,ASM使用索引技术来跟踪每个AUs的位置。
③ 支持联机磁盘的动态增加和减少,当磁盘发生变化后,AUs会自动重新实现动态分布。
④ 支持RAC集群技术,每一节点上运行一个ASM实例,各ASM实例间能实现点对点通讯。
⑤ 是一个纯软件级别的实现方式,第三方RAID工作在卷层次上,使用统一条带大小,ASM可以工作在文件层次级别,不同文件可以使用不同的条带大小。
ASM具有如下的优点:
① 磁盘增加:增加磁盘变得非常容易。无需停机时间,并且文件区域自动重新分配。
② I/O分配:I/O自动分布在所有可用的磁盘上,无需人工干预,从而减少了热点出现的可能性。
③ 带区宽度:在REDO日志文件中分段可以细分(KB,以获得更快的传输速率),对于数据文件,带区则略大一些(MB,以一次性传输大量的数据块)。
④ 缓冲:ASM文件系统不进行缓冲,直接进行输入/输出。
⑤ 镜像:若硬件镜像不可用,则可以非常容易地建立软件镜像。
⑥ 核心化的异步I/O:实现核心化的异步I/O无需特殊的设置,并且无需使用原始或第三方的文件系统(例如Veritas Quick I/O)。
🚀 4.2 在Oracle中,DG是什么?它有哪些后台进程?
- Data Guard 概念
Oracle的一个高可用机制,用于做数据冗余,DataGuard可以提供Oracle数据库的冗灾、数据保护、故障恢复等,实现数据库快速切换与灾难性恢复。
RAC —实例级的冗余方案
Data guard —数据级的冗余方案
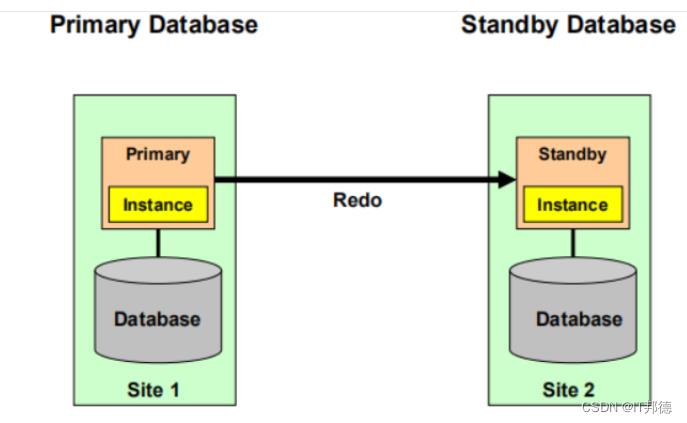
DG相关的后台进程
ARCH (archiver) :心跳检测,探测对方,进程通过Net把归档日志发送给Standby
RFS (remote file server) :远程接数据
FAL (Fetch Archive Log ) :解决Redo的间隔Gap
MRP (Managed Recovery Process) :日志被应用,恢复的过程
LNS (log-write network-server) :log传送
🚀 4.3 在DG中Switchover和Failover的区别是?
切换是在主数据库与其备数据库之间进行角色反转,切换确保不丢失数据。
这是对于主系统计划维护的典型操作。
在切换期间,主数据库转换到备角色,备数据库转换到主角色。
转换发生不需要重建任何数据库。
(1)Switchover
用到的场景:计划中的角色转换或用户操作系统和硬件的维护等。
(2)Failover
故障转移是当主数据库不可用时执行的。
故障转移只有在主数据库灾难故障的情况下执行,并且故障转移导致备数据库转换到主角色。
用到的场景:非计划中的角色切换,一般在紧急情况下使用。
根据保护模式的不同,可能会没有或者很少的数据损失。
(3)角色转换决策树
角色转换(switchover&failover)的最终目的是尽快地使主库在线,
而同时尽量减少数据损失或者是实现无数据损失。
尽量选择宕机时间最短,同时数据损失最小的策略。
总之在失败切换前,应该先考虑修复主数据库或者进行无数据损失的角色转换。
即使使用无数据损失的备库方案,修复主库可能会比切换到备库更快点。
如果修复了主库,那么就不需要修改客户端的连接。
但是如果修复工作导致了任何的数据损失,那么可能需要重新创建所有的备用数据库。
通常情况下,最合适切换的备库为已经应用了最多的归档日志的备用数据库。
🚀 4.4 简述下Oracle高可用OGG的原理和进程
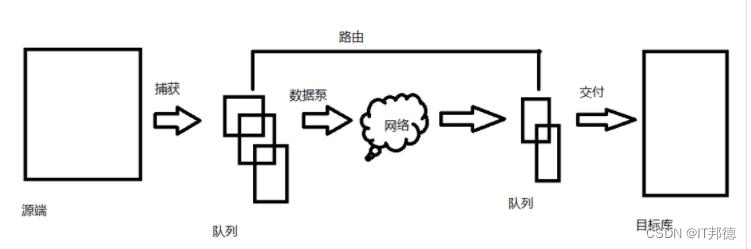
1.原理
补获:读取在线日志,在事务发生的时候捕获(提交的事务)
队列:讲数据排入队列,以备路由
数据泵:分发数据到目标端
路由:压缩加密数据,按顺序到达
交付阶段:保证事务的完成性,根据规则转换数据
2.进程
manger:OGG的主进程,启动、监控、重启OGG的其他进程,报告错误及其他事件
分配数据的存储空间,在目标端和源端只有一个进程
extract:运行在OGG的源端,负责从源端数据表或者日志当中捕获数据
初始化的阶段:从表中同步数据
同步变换的捕获阶段:从源端日志当中捕获数据(DML\\DDL操作)
pump:运行在数据源端,把抽取到的数据,转换成trail文件(数据块的形式保存)
collector:运行在目标端,接收到的数据从新组装成trail文件
replicat:应用进程,负责读取trail,将其解析为DML、DDL语句,应用到目标数据库
trail文件:防止单点故障,讲事务的信息持久化,可以使用Checkpoint机制来记录
读写的位置,如果发生故障,可以根据记录的位置来重传
🐴 第五股 性能优化篇
🚀 5.1 在Oracle中,SQL如何优化?SQL优化的关注点有哪些?
随着数据库中数据量的增长,系统的响应速度就成为目前系统需要解决的最主要的问题之一。系统优化中一个很重要的方面就是SQL语句的优化。对于大量数据,劣质SQL语句和优质SQL语句之间的速度差别可以达到上千倍。对于一个系统不是简单地能实现其功能就可以了,而是要写出高质量的SQL语句,提高系统的可用性。
在多数情况下,Oracle使用索引来更快地遍历表,优化器主要根据定义的索引来提高性能。如果在SQL语句的WHERE子句中写的SQL条件不合理,那么就会造成优化器舍去索引而使用全表扫描,一般这种SQL语句的性能都是非常差的。在编写SQL语句时,应清楚优化器根据何种原则来使用索引,这有助于写出高性能的SQL语句。
SQL的优化主要涉及如下几个方面的内容:
(1)索引问题。是否可以使用组合索引;限制条件、连接条件的列是否有索引;能否使用到索引,避免全表扫描。一般情况下,尽量使用索引,因为索引在很多情况下可以提高查询效率。排序字段有正确的索引,驱动表的限制条件有索引,被驱动表的连接条件有索引。
(2)相关的统计信息缺失或者不准确。查看SQL的执行计划是不是最优,然后结合统计信息查看执行计划是否正确。
(3)直方图使用错误。
(4)SQL本身的效率问题,例如使用绑定变量,批量DML采用BULK等,这个就考验写SQL的基本功了。
(5)数据量大小。如果就是几百条数据,那么就没有所谓效率之分,一般情况下怎么写效率都不低。如果数据量很大,那么就得考虑是否要分页或排序。
(6)绑定变量:大多数情况绑定变量能提高查询效率,但也有降低效率的情况。
(7)批量和并行的考虑。
(8)业务需求需要正确理解,实现业务的逻辑需要正确,减少一些重复计算。有可能是设计的不合理、业务需求的不合理,而问题SQL并非根本原因。
(9)查询特别频繁的结果是否可以缓存,比如Oracle的/*+ result_cache */。
(10)分析表的连接方式。若是NL连接,则根据业务或表的数据质量情况,分析能否减少驱动表的结果集。
(11)是否可以固定执行计划。
(12)大表是否存在高水位。
(13)在创建表的时候,应尽量建立主键,可以根据实际需要调整数据表的PCTFREE参数。
SQL优化的一般性原则如下所示:
l 目标:
减少服务器的资源消耗(主要是磁盘I/O)。
l 设计方面:
① 尽量依赖Oracle的优化器,并为其提供条件。
② 建立合适的索引,注意索引的双重效应,还有列的选择性。
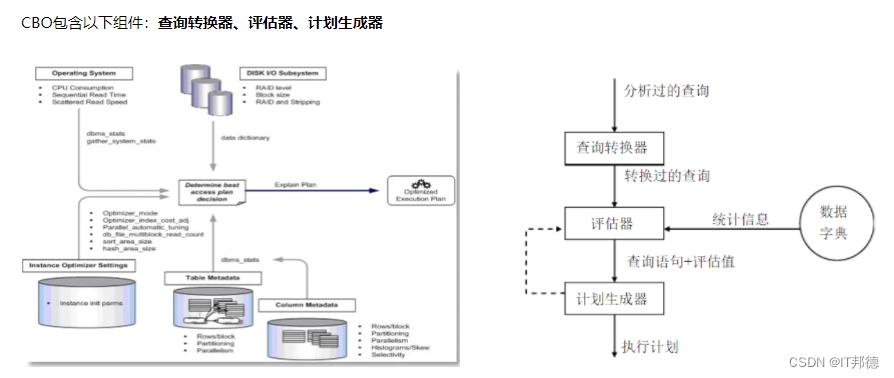
🚀 5.2 简述Oracle优化器及种类
优化器是 SQL 分析和执行的优化工具,他负责制定 SQL 的执行计划,比如什么时候是全表扫描(FTS full table scan),什么时候是索引范围搜索(Index Range
Scan),或者是全索引扫描(INDEX fast full scan,INDEX_FFS);如果是表于表之间连接的时候,它会负责去定表之间以一种什么样子的形式来关联,比如 HASH_JOIN 还是 NESTED LOOPS 或者是 MERGE JOIN。这些因素直接决定了 SQL 的执行效率,所以优化器是 SQL 执行的核心!!!
注释:SQL 执行一定会有代价。
优化器的种类
Cost Based Optimizer(CBO)基于成本,或者讲统计信息,依据一套数据模型,计算数据访问和处理的成本,选择最优成本作为执行方案
CBO 方式:它是看语句的代价(Cost),这里的代价主要指 Cpu 和内存。优化器在判断是否用这种方式时,主要参照的是表及索引的统计信息。统计信息给出表的大小、有少行、每行
的长度等信息。这些统计信息起初在库内是没有的,是做完收集统计信息后才出现的,很多的时侯过期统计信息会令优化器做出一个错误的执行计划,因些应及时更新这些信息。
注意:走索引不一定就是优的,比如一个表只有两行数据,一次 IO 就可以完成全表的检索,而此时走索引时则需要两次 IO,这时全表扫描(full table scan)是最好。

以上是关于Oracle夺命连环25问,你能坚持第几问?的主要内容,如果未能解决你的问题,请参考以下文章