socketserver.py代码阅读笔记
Posted 善良超锅锅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了socketserver.py代码阅读笔记相关的知识,希望对你有一定的参考价值。
socketserver.py源码阅读笔记
前言
一直想弄清楚一个http server和Web框架的工作原理。但以我目前的实力,阅读一个http server或web框架代码还是太难了。后来又对异步IO、并发产生的兴趣。前几天做一个大作业需要写几个各种不同并发模型的TCP Server,写完才想起Python有现成的socketsever模块可以用,完全不需要自己写。于是对比了一下我写的代码和socketsever.py,发现我写的真没socketsever写的好。我的代码经验还是太少了。于是决定从学习封装一个TCP Server开始,慢慢前进。socketsever.py中的代码只有700多行,其中还有大量的注释。所以我决定阅读socketsever模块的代码,分析其中的原理。弄清楚这个模块后,看能不能在它的基础上修改一下,让它支持IO复用,在一个线程或进程中并发处理多个客户端连接。然后分析一个简单的http server框架,一个简单的Web框架?
在正式阅读本篇之前,如果你有以下知识背景会轻松很多,(其实你有这些知识背景,完全可以直接看源码)
- 用过socketsever模块
- 有多进程、多线程编程经验
- 了解设计模式中的模板方法模式
- 了解mix-in模式和Python多继承的符号查找规则
socketserver概述
socketserver提供的类类型
socketserver中类分为三种类型。一是Server类:BaseServer/TCPServer/UDPServer用来接收客户的请求。TCPServer处理TCP请求,UDPServer处理UDP请求。BaserServer是基类,不能直接使用。TCPServer继承自BaseServer,UDPServer继承自TCPServer。暂时不明白为什么UDPServer要继承自TCPServer,后面再说。
二是Handler类:BaseRequestHandler/DatagramRequestHandler/StreamRequestHandler用来处理每一个客户请求。一般用使用BaseRequestHandler就行,但StreamRequestHandler/DatagramRequestHandler提供了一些特别的功能,前者用来处理流式(TCP)请求,后者处理数据报(UDP)请求。Server每收到一个客户请求就会创建一个Handler类示例来处理该请求。默认情况下,TCPServer/UDPServer是单进程单线程的模型,依次处理每个客户请求,一个请求处理完毕才能接着处理下一个请求。
三是MixIn类:ForkingMixIn/ThreadingMixIn用来为Server提供多进程/多线程并发处理能力的。ForkingMixIn是多进程模型,ThreadingMixin是多线程模型。这里特别巧妙的是,你只要创建一个类,同时继承Server类和MixIn类就能自动获得并发处理请求的能力。该模块本身就直接提供了这种类。它们的代码非常简单:
class ForkingUDPServer(ForkingMixIn, UDPServer): pass
class ForkingTCPServer(ForkingMixIn, TCPServer): pass
class ThreadingUDPServer(ThreadingMixIn, UDPServer): pass
class ThreadingTCPServer(ThreadingMixIn, TCPServer): pass你可以直接让你的server类继承自它们就能获得具有并发能力的server。
最后贴一下该模块中类结构。
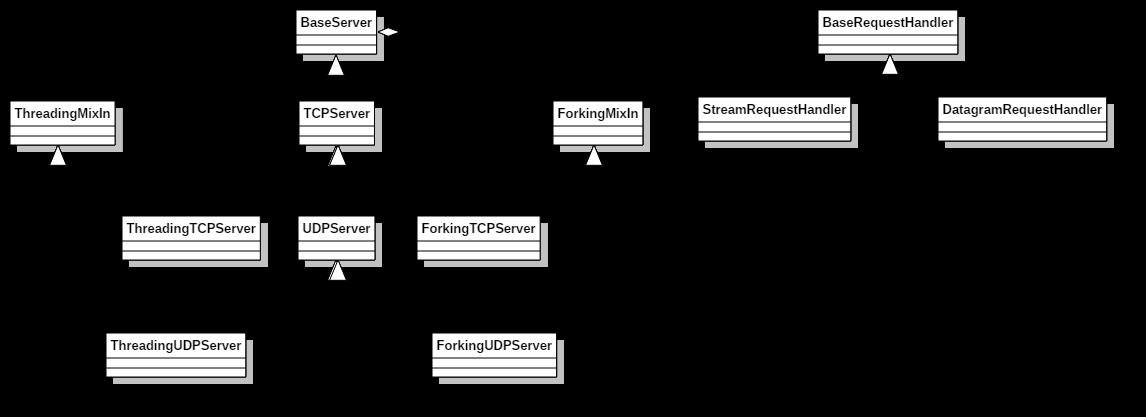
在Linux平台上socketsever模块还提供了UnixStreamServer、UnixDatagramServer、ThreadingUnixStreamServer、ThreadingUnixDatagramServer类,它们都和UNIX域相关,本文不关心它们。
简单使用
最简单的使用方法如下:
- 创建一个Handler类,继承自BaseRequestHandler,重写其handle(),在该方法中完成对请求的处理。
- 实例化一个Server类对象(根据不同的server类型选择不同的Server类)。并将IP、端口和Handler类传递给Server的构造函数。
- 调用server对象的server_forever()开启服务。
一个简单的TCP Server代码示例:
from SocketServer import TCPServer,StreamRequestHandler
# 定义请求处理类
class Handler(StreamRequestHandler):
def handle(self):
addr = self.request.getpeername()
print 'Got connection from ',addr
self.wfile.write('Thank you for connecting')
server = TCPServer(('',1234), Handler) # 实例化服务类对象
server.server_forever() # 开启服务如果要创建的是UDP Server,把代码中的TCPServer替换成UDPServer就行。
如果想使用多进程模型来获得并发处理请求的能力,则创建一个server类,继承自ForkingMixIn和TCPserver(或UDPServer)。该模块直接提供的ForkingTCPServer就是这样的。
一个简单的多进程TCP Server代码示例:
from SocketServer import ForkingTCPServer,StreamRequestHandler
# 定义请求处理类
class Handler(StreamRequestHandler):
def handle(self):
addr = self.request.getpeername()
print 'Got connection from ',addr
self.wfile.write('Thank you for connecting')
server = ForkingTCPServer(('',1234), Handler) # 实例化服务类对象
server.server_forever() # 开启服务疑问列表
本次阅读代码主要是为了解决下面几个疑问
Server的启动和服务流程是怎样的?
TCPServer和UDPServer,以及加入并发处理能力后的Server,它们的使用方式都是一致的。是不是使用了模板方法模式(23种设计模式中的一种),在BaseServer中定义处理请求的骨架,将不确定的步骤延迟到子类中实现?
- Server是怎样和Handler交互的?
- 通过Mixin类混入的多进程和多线程并发能力是怎样混入?
Server的启动
不管TCPServer、UDPServer还是用户自己继承它们所创建的Server,它们的使用方式都是一致的。它们的顶层调用入口都是BaseServer中定义的serve_forever()和handle_request()方法,前者循环处理客户请求,后者只处理单个用户请求。serve_forever()有个参数poll_interval,默认值为0.5,表示轮询的timeout时长。
Server的监听
BaseServer创建socket后使用IO复用来监听socket的可读事件。具体使用的是selectors模块。代码如下:
import selectors
# poll/select have the advantage of not requiring any extra file descriptor,
# contrarily to epoll/kqueue (also, they require a single syscall).
if hasattr(selectors, 'PollSelector'):
_ServerSelector = selectors.PollSelector
else:
_ServerSelector = selectors.SelectSelector可以看出优先使用的是PollSelector,然后才是SelectSelector。至于为什么不使用EpollSelector和KqueueSelector,注释上说是因为它们多了一次系统调用。个人觉得这个解释有点…,不过该模块只监听了一个socket,用哪个效率都差不多,所以无所谓。
具体到serve_forever()和handle_request()中的监听过程是这样的:
先在基类BaseServer的构造函数中设置了需要监听的socket的地址
# BaseServer的构造函数
def __init__(self, server_address, RequestHandlerClass):
"""Constructor. May be extended, do not override."""
self.server_address = server_address
# ...然后在TCPServer的构造函数中创建了socket
# TCPServer
def __init__(self, server_address, RequestHandlerClass, bind_and_activate=True):
"""Constructor. May be extended, do not override."""
BaseServer.__init__(self, server_address, RequestHandlerClass)
self.socket = socket.socket(self.address_family, self.socket_type)
# ...UDPServer继承了TCPServer的该实现。
serve_forever()函数中的监听过程如下:
def serve_forever(self, poll_interval=0.5):
# ...
try:
with _ServerSelector() as selector:
selector.register(self, selectors.EVENT_READ) # 注册,表示关心EVENT_READ事件
while not self.__shutdown_request:
ready = selector.select(poll_interval) # 查询事件
if ready:
self._handle_request_noblock() # 处理请求
self.service_actions()
# 异常处理可以看出serve_forever在一个循环中轮询处理请求。每次轮询的时间间隔是poll_interval。
handle_request()中的监听过程如下:
def handle_request(self):
# 计算超时时间deadline
with _ServerSelector() as selector:
selector.register(self, selectors.EVENT_READ) # 注册EVENT_READ事件
while True:
ready = selector.select(timeout) # 轮询
if ready:
return self._handle_request_noblock() # 处理请求,并返回
else:
# 计算是否超时,超时了就调用handle_timeout并返回可以看出handle_request在deadline之前要么接收到一个客户请求并处理,然后返回。要么调用handle_timeout进行超时处理,然后返回。
你可能会对selector.register(self, selectors.EVENT_READ)这行代码感到奇怪,为什么可以直接传入一个self进去,注册方法要的参数不是描述符吗?是这样的,BaseServer假设子类都实现了fileno()方法,selector.register收到一个非描述符参数后会调用fileno()来获得需要的描述符,所以这里可以直接传入self。
Server接收和处理请求的流程
serve_forever()正常处理流程
serve_forever()处理一个请求的正常流程如下图:

图中有”empty”标记的方法表示该方法在基类(BaseServer)中的实现为空。子类或Mixin可以重写它。有”subclass”标记的方法表示基类中没有定义该方法,子类或MixIin必须提供实现。有”default”和”subclass”标记的方法表示基类只提供了一个默认实现,子类可以根据需要重写它。有”Mixin”标记的方法表示该方法留给Mixin重写,以达到加入新功能的目地。
下面我们开始跟踪serve_forever处理请求的各个步骤。栈可能有点深,你可以时常查看上面的图来判断我们走到了哪里。
用户调用serve_forever()后,假设serve_forever在轮询中收到一个客户请求。serve_forever调用_handle_request_noblock来开始处理客户请求。_handle_request_noblock调用get_request()来获取该用户请求。但TCP和UDP协议中的用户请求获取方式不一样,所以基类没有定义该方法,而已延迟到子类中定义和实现。TCPServer中对该方法的定义为调用socket的accept方法获得与用户连接的socket和用户地址。
# TCPServer
def get_request(self):
return self.socket.accept()UDP对该方法的实现为调用socket的recvfrom方法,获得客户发过来的数据和客户地址。并返回()(数据, socket), 客户地址)。
def get_request(self):
data, client_addr = self.socket.recvfrom(self.max_packet_size)
return (data, self.socket), client_addr_handle_request_noblock()调用get_request()获取完用户请求后,马上调用verify_request()来验证用户请求,记录中该方法默认返回True。如果你想验证客户请求,可以在子类中重写该方法,比如只服务固定IP范围内的客户请求。如果verify_request()返回True,_handle_request_noblock()接着调用process_request()开始正式处理客户请求。Mixin可以重写该方法,比如新建一个进程或线程来处理该客户请求,实现并发。ForkingMixin和ThreadingMixin正是这么干的。process_request()调用finish_request(),finish_request()调用RequestHandleClass类的构造方法来处理该客户请求,这里才是真的处理客户请求的地方。finish_request()返回后process_request()调用shutdown_request()方法来关闭该请求。shutdown_request()方法负责清理操作并关闭客户连接。基类中的该方法的默认实现为直接调用close_request()。
# BaseServer
def shutdown_request(self, request):
self.close_request(request)TCPServer的该方法实现为先调用socket的shutdown主动关闭连接的写端,然后再调用close_request()
# TCPServer
def shutdown_request(self, request):
try:
request.shutdown(socket.SHUT_WR)
except OSError:
pass #some platforms may raise ENOTCONN here
self.close_request(request)UDPServer中的该方法实现和基类中的一样,直接调用close_request()
# UDPServer
def shutdown_request(self, request):
self.close_request(request)再来看close_request()。TCP需要关闭连接,UDP不需要,所以基类中的close_request()实现为空,延迟到子类中实现。TCPServer的close_request()实现为关闭socket连接。UDPServer的该方法实现为空。如果你需要在关闭连接时做一些其他操作,可以重写shutdown_request()或close_request()。
OK,我们已经走的有点远了。现在前面分析过的函数已经执行完毕,开始弹栈。一直到_handle_request_noblock()返回。serve_forever()在调用完_handle_request_noblock()后,接着调用service_actions()。service_actions()表示处理完每个请求后都有执行的操作。基类中该方法实现为空。如果你希望在没处理完一个客户请求就执行某个逻辑操作,可以重写该方法,比如每次处理完一个请求都增加一个计数,表示服务完多少个请求。
serve_forever()出错时的处理流程
如果在调用process_request()时发生异常,流程如下:
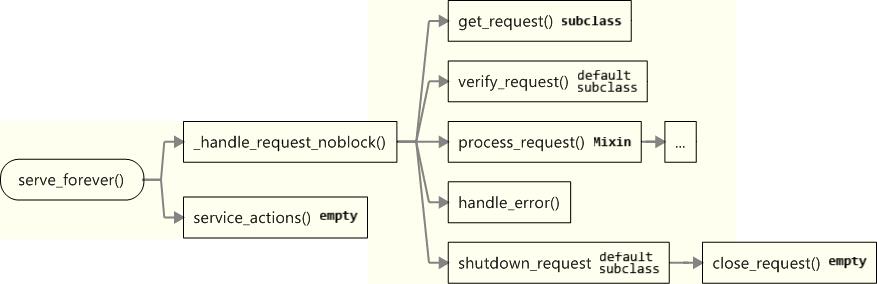
process_request()调用的函数和前面一样,所以用…代表。在调用process_request()出现异常时,_handle_request_noblock()接着会调用handle_error()和shutdown_request()。handle_error()在基类中的默认实现只是简单地打印异常内容,并继续运行。你可以重写它来实现自己的异常处理。
handle_request()正常处理流程

handle_request()用来接收并处理单个客户请求,所以没有轮询。处理流程如上图,_handle_request_noblock()的函数调用栈和前面serve_forever()一样
handle_request()超时处理流程

handle_timeout()表示超时后还没收到请求后的处理。该方法在基类中也是空实现,你可以在子类中重写它。
结束serve_forever()
我们知道只要不发送异常,serve_forever()会在循环中处理客户请求。假如我们在调用server_forever()后的某一时刻想主动结束这种轮询处理该怎么做呢?BaseServer提供了shutdown()方法来接收这种轮询。shutdown()会阻塞直到serve_forever()停止。而且shutdown()只能在和serve_forever()不同的线程中调用,否则会造成死锁。
shutdown()的原理是利用了一个bool变量和threading.Event。在基类的构造函数中,创建了一个Event变量__is_shut_down,表示是否shutdown完成;创建了一个bool变量__shutdown_request,表示是否有shutdown请求。
# BaseServer
def __init__(self, server_address, RequestHandlerClass):
"""Constructor. May be extended, do not override."""
self.server_address = server_address
self.RequestHandlerClass = RequestHandlerClass
self.__is_shut_down = threading.Event() # 用于阻塞shutdownd()调用
self.__shutdown_request = False # 用于记录是有shutdown请求在shutdown()中会检测这两个变量。
# BaseServer
def shutdown(self):
self.__shutdown_request = True # 置为True,表示请求shutdown
self.__is_shut_down.wait() # 等待__is_shut_down的标志置为True,否则一直阻塞下去shutdown()将__shutdown_request置为True,serve_forever()在轮询时会检测该变量,如果该变量为True就跳出循环,结束处理。然后调用__is_shut_down.wait()阻塞到__is_shut_down的标志变为True。serve_forever在停止时会将__is_shut_down的标志置为True,表示shutdown完成。shutdown检测到该标志后就会结束阻塞。serve_forever()函数如下:
# BaseServer
def serve_forever(self, poll_interval=0.5):
self.__is_shut_down.clear() # 将Event置为False
try:
with _ServerSelector() as selector:
selector.register(self, selectors.EVENT_READ)
while not self.__shutdown_request: # 每次循环都检测是否有shutdown请求
ready = selector.select(poll_interval)
if ready:
self._handle_request_noblock()
self.service_actions()
finally:
self.__shutdown_request = False # 重新置为False
self.__is_shut_down.set() # 将Event置为True可以看到serve_forever()刚调用时,将Event变量__is_shut_down的标志置为False。然后每次轮询处理请求前都判断__shutdown_request是否为False,如果是继续接收请求。否则,说明shutdown已被调用,所以结束循环,停止接收请求,执行finally代码块。在finally块中将__shutdown_request重置为False,将__is_shut_down的标志置为True,表示serve_forever已停止,shutdown()检测到该标志后就可以结束阻塞了。
Handler处理请求的流程
通过前面的分析,我们知道serve_forever()和handle_request()最终会在finish_request()中调用Handler类的构造函数来处理请求。socketserver模块提供了三个Handler类:BaseRequestHandler、StreamRequestHandler、DatagramRequestHandler。后两个是第一个的子类。直接使用BaseRequestHandler也行,但StreamRequestHandler、DatagramRequestHandler分别适合处理流式数据和数据报数据。这三个类的设计也使用了模板方法模式,在基类中搭好了处理请求的骨架,具体实现延迟到子类中。
我们来具体分析一下Handler构造函数做了哪些事。BaseRequestHandler的构造函数如下:
# BaseRequestHandler
def __init__(self, request, client_address, server):
self.request = request
self.client_address = client_address
self.server = server
self.setup()
try:
self.handle()
finally:
self.finish()可以看出构造函数记录请求、客户地址和server示例参数。然后依次调用了setup()、handle()、finish()。这三个方法的代码如下:
def setup(self):
pass
def handle(self):
pass
def finish(self):
pass可以看到BaseRequestHandler中的这三个方法都是空实现,所以直接使用BaseRequestHandler,你至少得重写handle(),然后根据需要决定是否重写setup()、finish()。处理请求涉及到的函数调用堆栈如下图:
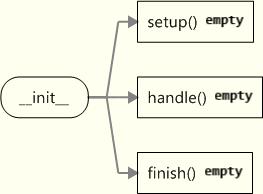
setup()是处理前的初始化操作,handle()是处理请求,finish()是清理操作。
Handle接收和发送数据
上一节提到Handle使用了模板方法模式,BaseRequestHandler的setup()、handle()、 finish()实现都为空。StreamRequestHandler和DatagramRequestHandler都重写了setup()个finish()。客户只需重写handle()。
StreamRequestHandler的setup()和finish()代码如下:
# StreamRequestHandler
def setup(self):
self.connection = self.request
if self.timeout is not None:
self.connection.settimeout(self.timeout) # 如果需要,设置timeout
if self.disable_nagle_algorithm:
self.connection.setsockopt(socket.IPPROTO_TCP,
socket.TCP_NODELAY, True)
self.rfile = self.connection.makefile('rb', self.rbufsize) # 转读文件
self.wfile = self.connection.makefile('wb', self.wbufsize) # 转为写文件
def finish(self):
if not self.wfile.closed:
try:
self.wfile.flush() # 刷新写文件流
except socket.error:
pass
self.wfile.close()
self.rfile.close()可以看到StreamRequestHandler在setup()将socket IO转化为文件IO。在finish()中清理了对应的文件对象。
DatagramRequestHandler的setup()和finish()的代码如下:
# DatagramRequestHandler
def setup(self):
from io import BytesIO
self.packet, self.socket = self.request
self.rfile = BytesIO(self.packet) # 创建内存读文件,并用self.packet初始化
self.wfile = BytesIO() # 创建内存写文件
def finish(self):
# 将内存写文件中的数据发送给客户
self.socket.sendto(self.wfile.getvalue(), self.client_address) 可以看到DatagramRequestHandler也将socket IO转为对内存文件流的IO。
所以如果你使用了StreamRequestHandler和DatagramRequestHandler,你得重写handle(),在handle中你可以直接在rfile、wfile上调用文件IO接口write和read来读取和发送数据。如果你使用的是BaseRequestHandler,重写handle(),在handle()中直接使用socket IO。
异步mix-in类分析
前面介绍时说过ForkingMixIn、ThreadingMixIn可以给Server添加并发功能。ForkingMixIn使用的是进程模型,为每个请求创建一个进程。ThreadingMixIn使用的线程模型,为每个请求创建一个线程。它们都没继承任何类,但是它们实现了BaseServer中的部分方法。假设一个类TestServer同时继承了ForkingMixIn和TCPServer,如下图所示,只展示部分关键的方法。
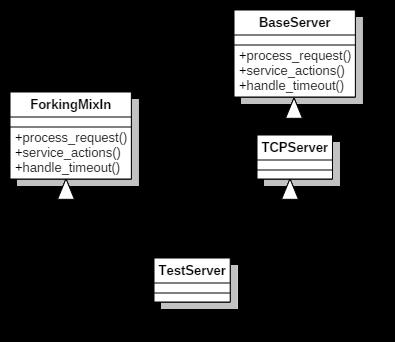
但通过TestServer的示例调用serve_forever()时,serve_forever()调用process_request()来处理请求,根据TestServer的继承层次和Python的属性查找规则(不知道规则的先去看一下Python文档),最先找到的是ForkingMixIn类的process_request()方法。所以最终调用的是ForkingMixIn中的process_request方法。在来看看ForkingMixIn的process_request方法实现。
# ForkingMinIn
def process_request(self, request, client_address):
"""Fork a new subprocess to process the request."""
pid = os.fork() # fork创建进程
if pid:
# Parent process
if self.active_children is None:
self.active_children = set()
self.active_children.add(pid)
self.close_request(request)
return
else:
# Child process.
# This must never return, hence os._exit()!
try:
self.finish_request(request, client_address)
self.shutdown_request(request)
os._exit(0)
except:
try:
self.handle_error(request, client_address)
self.shutdown_request(request)
finally:
os._exit(1)可以看到ForkingMixIn的process_request方法通过fork调用创建了新进程来处理请求。(注意Windows平台不支持fork调用)ThreadingMixIn也是同样的机制。都是用MixIn模式重写了一些方法调用。
要注意的是ForkingMixIn、ThreadingMixIn和TCPServer、UDPServer可能实现了相同的方法或属性,为了让查找规则先找到MixIn中的方法,你在实现自己的server时,最好把MixIn类放到继承顺序的最前面。
结束了
至此,我们的分析也就结束了。前面疑问列表中的问题都搞清楚了。但是本篇还有一些细节性的东西没涉及到,比如Server的timeout实现和处理。
这是作者第一次阅读标准库中的源代码,如有不足之处,还请多多指教!
以上是关于socketserver.py代码阅读笔记的主要内容,如果未能解决你的问题,请参考以下文章