Java:在Java中String是以Unicode保存的吗?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java:在Java中String是以Unicode保存的吗?相关的知识,希望对你有一定的参考价值。
但是Unicode有UTF8、UTF16、GBK等多种实现方式,说String是以Unicode保存的具体是以哪种实现方式呢?还是说是以纯Unicode保存的?那岂不是会占用很多空间?
参考技术A 字符串在java内存中总是按unicode编码存储的。比如"中文",正常情况下(即没有错误的时候)存储为"4e2d 6587",如果charset为"gbk",则被编码为"d6d0 cec4",然后返回字节"d6 d0 ce c4".如果charset为"utf8"则最后是"e4 b8 ad e6 96 87".如果是"iso8859-1",则由于无法编码,最后返回 "3f 3f"(两个问号)。java虚拟机采用UCS2(通用字符集)标准保存字符,所有的字符在内存中都是2个字节,这样虚拟机处理字符串的截取、长度和判断都非常容易。其他语言如php、Python也是,在运行时采用固定长度存储字符。
相对应编译后的class,java规定采用UTF-8保存,因为大部分是英文字符,只有一个字节,可以大量节省存储空间。本回答被提问者和网友采纳
Java中的String介绍
一、概述
String是代表字符串的类,本身是一个最终类,使用final修饰,不能被继承。
二、String字符串的特征
1. 字符串在内存中是以字符数组的形式来存储的。
示例如下,可以从String的底层源码中看到。
implements java.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */ private final char value[]; /** Cache the hash code for the string */ private int hash; // Default to 0 /** use serialVersionUID from JDK 1.0.2 for interoperability */ private static final long serialVersionUID = -6849794470754667710L; /** * Class String is special cased within the Serialization Stream Protocol. * * A String instance is written into an ObjectOutputStream according to * <a href="{@docRoot}/../platform/serialization/spec/output.html"> * Object Serialization Specification, Section 6.2, "Stream Elements"</a> */ private static final ObjectStreamField[] serialPersistentFields = new ObjectStreamField[0]; /** * Initializes a newly created {@code String} object so that it represents * an empty character sequence. Note that use of this constructor is * unnecessary since Strings are immutable. */ public String() { this.value = "".value; } ... }
2.因为字符串是常量,所以本身是存储在方法区的常量池中。只要字符串的实际值一样,那么用的就是同一个字符串-->字符串是一个常量,字符串是被共享的。直接使用字符串赋值时,在常量池中创建一个字符串对象,然后将栈中的引用指向常量池中的对象。
例如:
String str = "abc"; //重新创建一个地址,使str指向该地址,栈内存直接指向方法区 str = "def"; //在方法区中查找,如果存在,再次指向原地址 str = "abc"; //在方法区中查找,如果存在,新对象也指向原地址 String str2 = "abc"; //栈内存指向堆内存,堆内存指向方法区 String str3 = new String("abc"); System.out.println(str == str2); //true System.out.println(str == str3);
其中,str和str2的地址就是相同的。
当使用new关键字创建String对象时,先在常量池中创建一个字符串常量对象,然后再在堆中new一个字符串对象,将该对象的地址指向常量区;然后在栈中创建一个引用,指向堆中的对象。
String str3 = new String("abc");
相当于在内存中创建了两个对象。其内存结构图如下所示
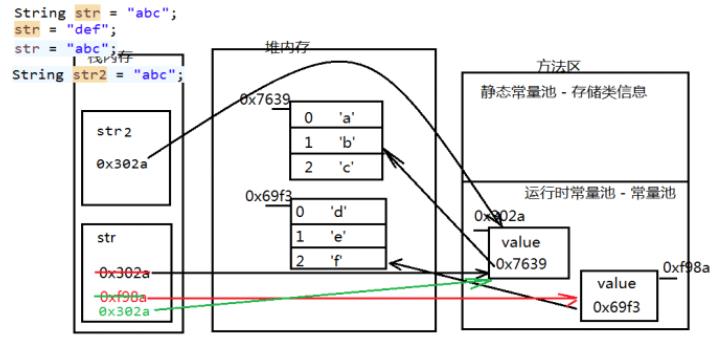
3. 如果需要拼接多个字符串,建议使用StringBuilder。因为使用StringBuilder拼接一次只产生一个新的对象,而使用+要产生3个对象。 具体示例如下;
String[] arr = new String[100]; String result = ""; //1个对象:共301个 for(int i = 0; i < 100000; i++) { //result = new StringBuilder(result).append(str).toString(); result += arr[i]; //没拼接一次,产生3个对象 } //共:102个对象 //产生一个对象 StringBuilder sb = new StringBuilder(); for(int i = 0; i < 100000000; i++) { //每拼接一次,创建一个对象;一共产生了100个对象 sb.append("a"); } result = sb.toString(); //1个对象
4. String类中,提供了一系列的字符串操作方法,但是都不改变原来字符串,都是产生一个新的字符串。
例如查看获取子串函数的源码
public String substring(int beginIndex, int endIndex) { if (beginIndex < 0) { throw new StringIndexOutOfBoundsException(beginIndex); } if (endIndex > value.length) { throw new StringIndexOutOfBoundsException(endIndex); } int subLen = endIndex - beginIndex; if (subLen < 0) { throw new StringIndexOutOfBoundsException(subLen); } return ((beginIndex == 0) && (endIndex == value.length)) ? this : new String(value, beginIndex, subLen); }
5. String字符串“+”在编译时和运行时的区别
预编译是指编译器会在编译时检测是否存在字符串字面量,如果有字面量相加的情况,会提前将字面量字符串进行合并并存储到常量池中。
/** * 继续-编译期无法确定 */ public void test5(){ String str1="abc"; String str2="def"; String str3 = "abc" +"def" String str4 = str1 + str2; System.out.println("===========test============"); System.out.println(str4 == str3 ); //false }
返回结果分析:因为str4指向堆中的"abcdef"对象,而"abcdef"是字符串池中的对象,所以结果为false。JVM对String str="abc"对象放在常量池中是在编译时做的,而String str4= str1+str2是在运行时刻才能知道的。new对象也是在运行时才做的。而这段代码总共创建了6个对象,字符串池中两个、堆中三个。+运算符会在堆中建立起来两个String对象,这两个对象的值分别是通过StringBuilder创建"abc"和通过append方法创建"abcdef",最后通过toString方法再建立对象str4,然后将"abcdef"的堆地址赋给str4,而堆中的“abcdef”地址指向常量池中的地址。
步骤:
1) 栈中开辟一块空间存放引用str1,str1指向池中String常量"abc"。
2) 栈中开辟一块空间存放引用str2,str2指向池中String常量"def"。
3) 栈中开辟一块空间存放引用str3,str3指向常量池中String常量“abcdef”。
4) str1 + str2通过StringBuilder的最后一步toString()方法还原一个新的String对象"abcdef",因此堆中开辟一块空间存放此对象。
5) 引用str4指向堆中(str1 + str2)所还原的新String对象。
6) str4指向的对象在堆中,而常量str3对应的"abcdef"在池中,输出为false。
以上是关于Java:在Java中String是以Unicode保存的吗?的主要内容,如果未能解决你的问题,请参考以下文章