深度学习系列44. Siren和Deep-Daze模型
Posted IE06
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习系列44. Siren和Deep-Daze模型相关的知识,希望对你有一定的参考价值。
1. Siren
Siren就是用sin函数代替原先的激活函数(例如ReLU)
1.1 代码实现
首先定义一个sineLayer层,输出为 s i n ( ω 0 f ( x ) ) sin(\\omega_0f(x)) sin(ω0f(x)),其中f(x)为全连接层。
class SineLayer(nn.Module):
def __init__(self, in_features, out_features):
self.linear = nn.Linear(in_features, out_features)
def forward(self, input):
return torch.sin(self.omega_0 * self.linear(input))
然后基于此定义siren层
class Siren(nn.Module):
def __init__(self, in_features, hidden_features, hidden_layers, out_features, outermost_linear=False):
self.net = []
# 第一层
self.net.append(SineLayer(in_features, hidden_features))
# 隐藏层
for i in range(hidden_layers):
self.net.append(SineLayer(hidden_features, hidden_features))
if outermost_linear:
# 最后一层
final_linear = nn.Linear(hidden_features, out_features)
self.net.append(final_linear)
else:
# 中间层
self.net.append(SineLayer(hidden_features, out_features))
self.net = nn.Sequential(*self.net)
def forward(self, coords):
coords = coords.clone().detach().requires_grad_(True) # allows to take derivative w.r.t. input
output = self.net(coords)
return output, coords
1.2 测试
我们使用经典的摄影师图像,首先来进行图像拟合。使用像素点坐标作为输入,尝试拟合出图像:
cameraman = ImageFitting(256)
dataloader = DataLoader(cameraman, batch_size=1, pin_memory=True, num_workers=0)
img_siren = Siren(in_features=2, out_features=1, hidden_features=256, hidden_layers=3, outermost_linear=True)
total_steps = 500
optim = torch.optim.Adam(lr=1e-4)
for step in range(total_steps):
model_output, coords = img_siren(model_input)
loss = ((model_output - ground_truth)**2).mean()
optim.zero_grad()
loss.backward()
optim.step()
原始图、梯度图、拉普拉斯变换图分别如下:
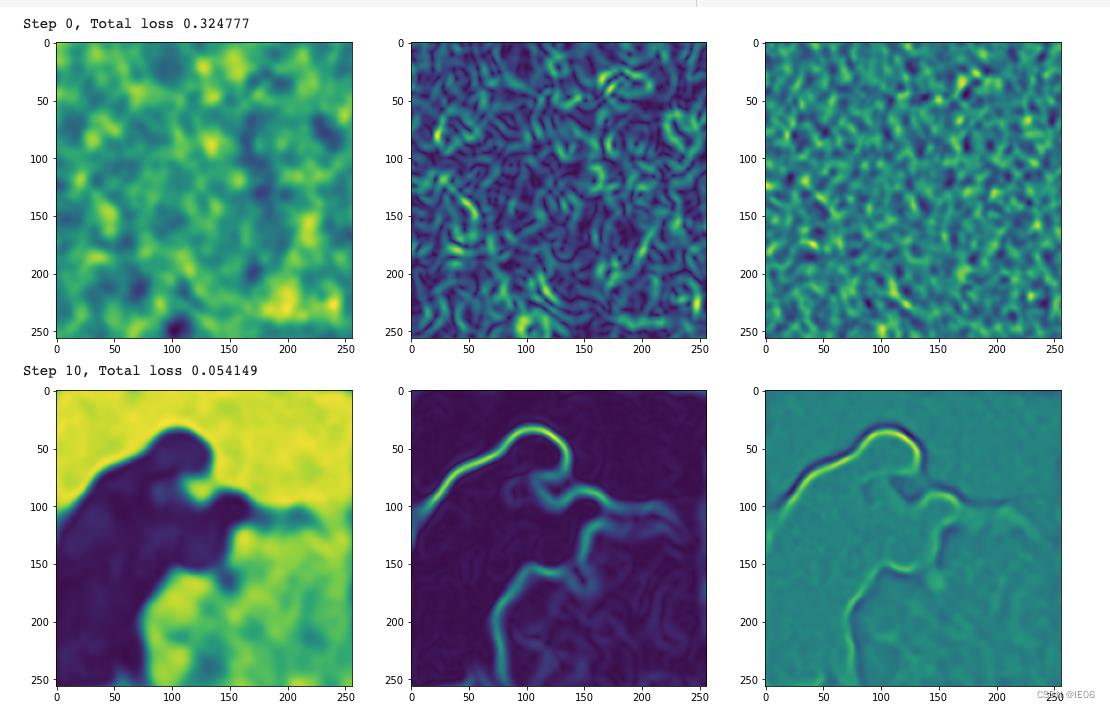
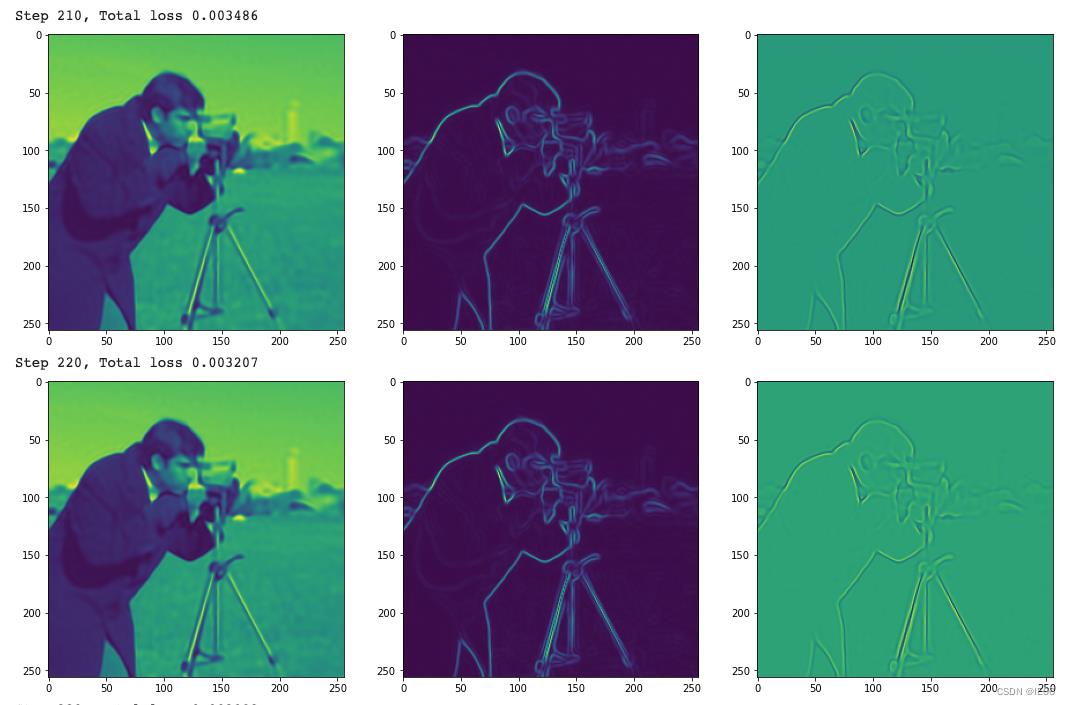
2. 模型使用
安装pip install deep-daze
2.1 命令行模式
调用$ imagine "a house in the forest",效果图如下:

如果内存足够,可以加上$ imagine "shattered plates on the ground" --deeper
也可以加深层数(默认是16):$ imagine "stranger in strange lands" --num-layers 32
也可以从一张初始图开始:$ imagine 'a clear night sky filled with stars' --start_image_path ./cloudy-night-sky.jpg

查看Deep-Daze对于图片的理解:
$ imagine --img samples/hot-dog.jpg

或者:$ imagine "A psychedelic experience." --img samples/hot-dog.jpg

2.2 python api
from deep_daze import Imagine
imagine = Imagine(
text = 'cosmic love and attention',
# 下面的都是可选项
num_layers = 24,
save_every=4,
save_date_time=True,
save_progress=True
)
imagine()
如果显存足够(>16G)/中等/很少(<4G),可以如下配置:
num_layers=42/24/256,
batch_size=64/16/16,
gradient_accumulate_every=1/2/16
2.3 代码简析
model = Siren(2, 256, 16, 3).cuda()
optimizer = torch.optim.Adam()
out = model(get_mgrid(sideX))
tx = clip.tokenize("a beautiful Waluigi")
t = perceptor.encode_text(tx.cuda())
for epochs in range(10000):
# 对out做各种裁剪和缩放(64个),然后拼接成into
iii = perceptor.encode_image(into)
loss = -100*torch.cosine_similarity(t, iii, dim=-1).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
以上是关于深度学习系列44. Siren和Deep-Daze模型的主要内容,如果未能解决你的问题,请参考以下文章