注意力模型(Attention Model)理解和实现
Posted ChainingBlocks
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了注意力模型(Attention Model)理解和实现相关的知识,希望对你有一定的参考价值。
1. 直观感受和理解注意力模型
在我们视野中的物体只有少部分被我们关注到,在某一时刻我们眼睛的焦点只聚焦在某些物体上面,而不是视野中的全部物体,这是我们大脑的一个重要功能,能够使得我们有效过滤掉眼睛所获取的大量无用的视觉信息,提高我们的视觉识别能力;神经网络中的注意力模型借鉴了我们人脑的这一功能,让神经网络模型对输入数据的不同部位的关注点不一样,权重不一样。

上面的图片出自论文 Xu et.al., 2015. Show attention and tell: neural image caption generation with visual attention, 它提出了一个能够根据图片中的内容自动生成描述性标题的神经网络模型。上面图片中左边图片是原图,右边是模型注意力的关注点,下划线上的文字描述了关注点上的物体名字。
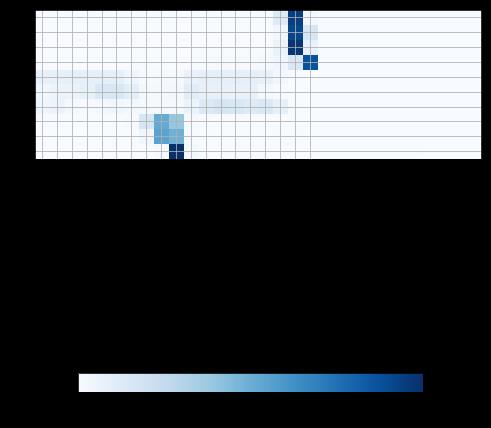
另一个例子如上面图片所示,有一个神经网络模型能够把适合人读写习惯的日期格式转换成统一的”yyyy-mm-dd“格式,也就是将上图行坐标所示的输入日期格式转换成纵坐标所示的日期格式。比如把 “3 May 1979”和“21th of August 2016“分别转换成“1979-05-03”和”2016-08-21“。上面图片中横向的格子的颜色深浅程度表示当前输出字符对各个输入字符的关注程度。比如在模型预测生成这个输出字符3的时候,对输入字符3(行坐标的3)是最关注的,也可以理解为行坐标的3对该结果输出3的贡献是最大的。
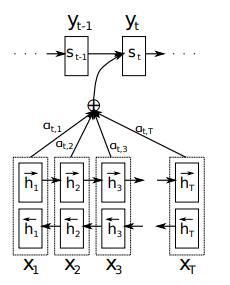
上面的分析过程可使用输入数据的概率分布来表示。假设现在是一个句子翻译模型,输入一个句子为”X1,X2,X3、、、XT“,长度为T;输出为”y1,y2、、、yt“,长度为t。T和t可能不相等。在每一次生成一个结果yi的时候,模型都计算一次当前模型对输入的句子的各个单词的概率分布(注意力)(
a
t
,
1
,
a
t
,
2
,
.
.
.
a
t
,
T
a_t,1, a_t, 2, ...a_t, T
at,1,at,2,...at,T)。该概率分布表示的是当前的输出值yi对所输入句子的每个单词的关注程度,或者说是这个句子中每一个输入的单词对当前输出结果yi的贡献程度。
2. 建模和实现
上面我们讲了注意力模型的直观感受,下面我们来讲具体如何建模和实现。
其实上图已经表示出了注意力模型,下面我们给出另外一个更加具体的表示:
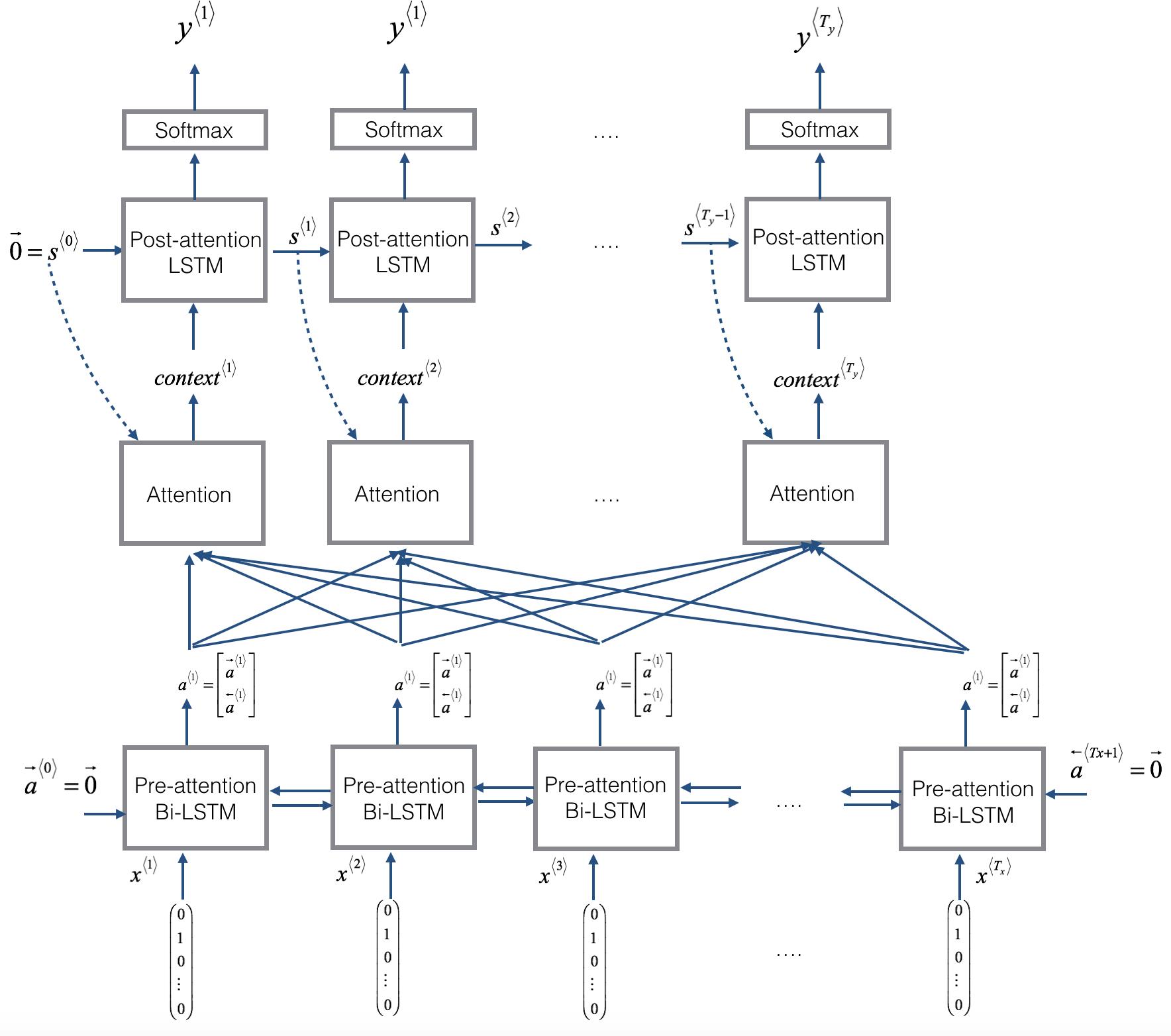
从下往上看,显示模型的输入值X,然后是双向的Bi-LSTM,再往上是将两个方向所产生的隐藏状态a1和a2拼接成a,再向上,结合s值计算出context值,然后将context作为另一个LSTM模型的输入值,最后通过softmax函数计算出y值。上面图片的长方形Attention部分是一个黑盒子,下面的图片是该盒子的具体展开。
a
<
1
>
,
a
<
2
>
,
a
<
T
x
>
a^<1>,a^<2>, a^<T_x>
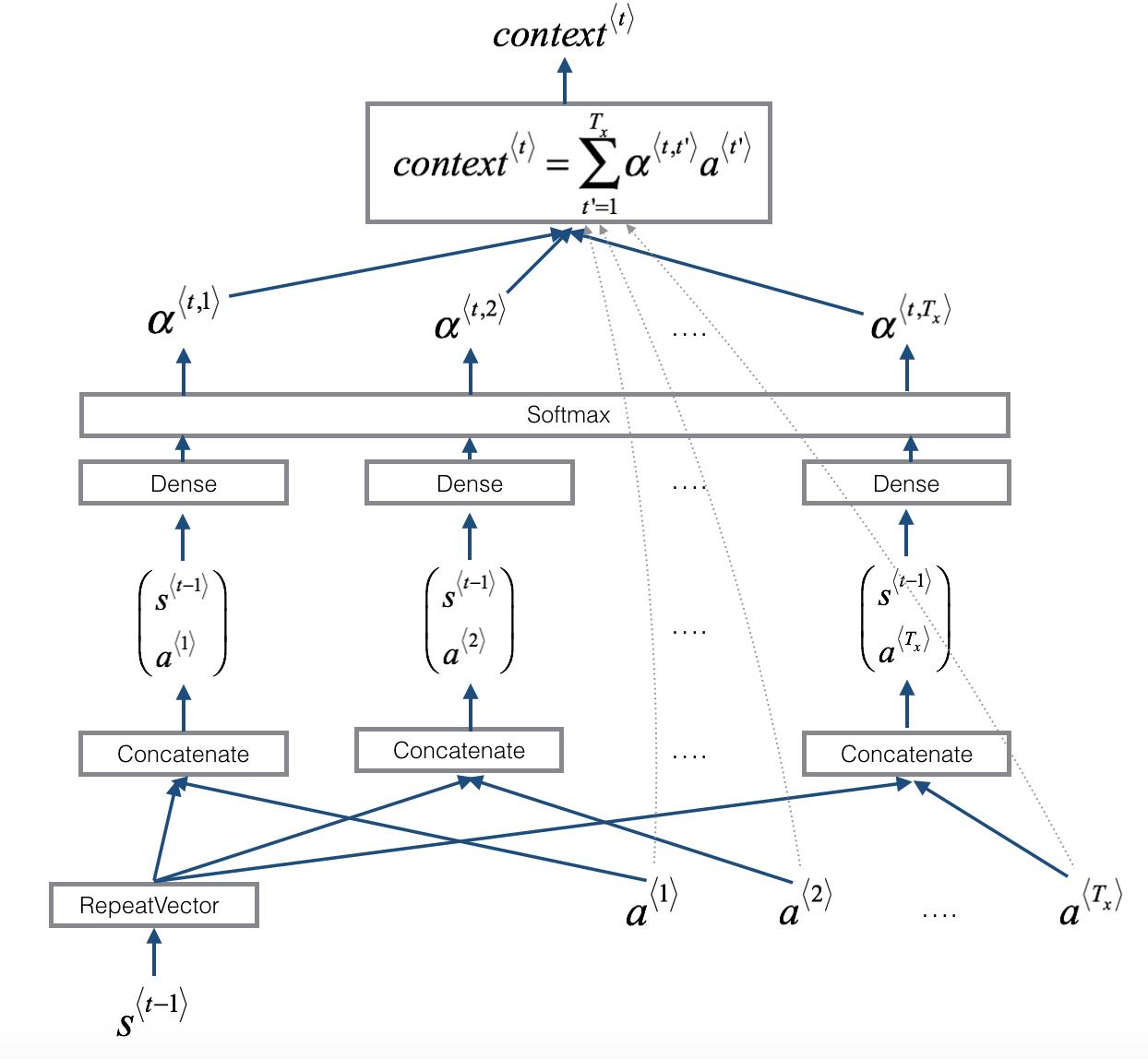
a<1>,a<2>,a<Tx>是Bi-LSTM模型的隐藏状态值,其中T表示所输入的句子的长度,也就是单词的个数。因为每预测/生成一个y值,都需要计算所输入的句子中各个单词对该预测值的贡献程度,所以,在上图中,将
S
<
t
−
1
>
S^<t-1>
S<t−1>跟1到T每一个时刻的a值拼接,然后通过Dense和Softmax函数,得到每一个输入的单词的权重(0-1之间),最后求加权平均,获取最后的结果
c
o
n
t
e
x
t
t
context^t
contextt,其中t表示第t个输出的y值。
3. 具体使用
下面使用具体的数据来讲解注意力模型。
我们希望有一个模型能够做下面所示的转换:
将格式不确定的日期比如"the 29th of August 1958", “03/30/1968”, “24 JUNE 1987"转换成固定格式的日期"1958-08-29”, “1968-03-30”, “1987-06-24”,也就是“yyyy-mm-dd”。更过的数据例子有:
(‘9 may 1998’, ‘1998-05-09’),
(‘10.09.70’, ‘1970-09-10’),
(‘4/28/90’, ‘1990-04-28’),
(‘thursday january 26 1995’, ‘1995-01-26’),
(‘monday march 7 1983’, ‘1983-03-07’),
(‘sunday may 22 1988’, ‘1988-05-22’),
(‘tuesday july 8 2008’, ‘2008-07-08’),
(‘08 sep 1999’, ‘1999-09-08’),
(‘1 jan 1981’, ‘1981-01-01’),
(‘monday may 22 1995’, ‘1995-05-22’)]
在我们的数据集中,最长的输入句子X不大于30,而输出值Y的长度为10。并且表示Y的只有11种不同的字母。
结合上图和数据集,我们下面给出各个张量的维度值:
- 输入的句子长度为30,Bi-LSTM一个方向的隐藏状态a的维度为(m,32),所以两个不同方向的a1,a2叠加起来之后的维度为a(m,64),其中m表示同时输入模型的句子条数,相对于batch或者mini batch而言。上图中上面一个LSTM的隐藏状态s的维度为(m,64)。
- concatenate长方形中的输出值的维度为(m,30,128),是a和s的在最后一个维度拼接的结果。
- 当concatenate的输出值经过两个Dense函数之后(第一个输出节点为10,第二个为1,上图只显示了一个Dense),结果的维度由(m,30,128)变为(m,30,10)再变为(m,30,1).
- 在使用求和公式计算加权平均值context的时候, a < t , t ′ > a^<t,t'> a<t,t′>的维度为(m,30,1),而 a < t ′ > a^<t'> a<t′>的维度为(m,30,64),结果的维度为(m,1,64)。因为 a < t , t ′ > a^<t,t'> a<t,t′>和 a < t ′ > a^<t'> a<t′>在第二个维度进行点乘运算,两个向量的点乘的结果为一个数字。 a < t , t ′ > a^<t,t'> a<t,t′>和 a < t ′ > a^<t'> a<t′>的第三维度不一样,一个是1,一个是64,但是点乘运算不是作用在给该维度,所以,使用了python的广播机制。
- 上面一个的隐藏变量c的维度为(m,64)
- 通过post-attention LSTM上面的softmax之后,再次经过了一个Dense函数,其输出节点为11,所以,输入LSTM数据的维度为(m,1,64),将LSTM的s(m,64)状态值输入一个Dense(输出节点个数为11)中得到y值,使得最后的y的维度为(m,11)。
下面是具体的代码实现,使用到了Tensorflow和Keras框架。完整的源码见文末:
根据Bi-LSTM的隐藏状态值a和LSTM的s来求解的 c o n t e x t t context^t contextt值。因为s_prev的维度是(m,64),所以我们使用RepeatVector函数将其维度变为(m,30,64),然后跟a拼接。代码中的a表示Bi-LSTM从1到T时刻所有的中间状态。
# Defined shared layers as global variables
repeator = RepeatVector(Tx)
concatenator = Concatenate(axis=-1)
densor1 = Dense(10, activation = "tanh")
densor2 = Dense(1, activation = "relu")
activator = Activation(softmax, name='attention_weights') # We are using a custom softmax(axis = 1) loaded in this notebook
dotor = Dot(axes = 1)
def one_step_attention(a, s_prev):
"""
Performs one step of attention: Outputs a context vector computed as a dot product of the attention weights
"alphas" and the hidden states "a" of the Bi-LSTM.
Arguments:
a -- hidden state output of the Bi-LSTM, numpy-array of shape (m, Tx, 2*n_a)
s_prev -- previous hidden state of the (post-attention) LSTM, numpy-array of shape (m, n_s)
Returns:
context -- context vector, input of the next (post-attetion) LSTM cell
"""
# Use repeator to repeat s_prev to be of shape (m, Tx, n_s) so that you can concatenate it with all hidden states "a" (≈ 1 line)
s_prev = repeator(s_prev)
# Use concatenator to concatenate a and s_prev on the last axis (≈ 1 line)
concat = concatenator([a, s_prev])
# Use densor1 to propagate concat through a small fully-connected neural network to compute the "intermediate energies" variable e. (≈1 lines)
e = densor1(concat)
# Use densor2 to propagate e through a small fully-connected neural network to compute the "energies" variable energies. (≈1 lines)
energies = densor2(e)
# Use "activator" on "energies" to compute the attention weights "alphas" (≈ 1 line)
alphas = activator(energies)
# Use dotor together with "alphas" and "a" to compute the context vector to be given to the next (post-attention) LSTM-cell (≈ 1 line)
context = dotor([alphas, a])
return context
先调用函数Bidirectional(LSTM(n_a, return_sequences=True))(X)得到Bi-LSTM的隐藏状态的值a,然后for循环Ty次,每一个都通过计算一个context值来生成一个y值,这样最后生成Ty个y值。下面的函数最终返回模型的对象。
n_a = 32
n_s = 64
post_activation_LSTM_cell = LSTM(n_s, return_state = True)
output_layer = Dense(len(machine_vocab), activation=softmax)
def model(Tx, Ty, n_a, n_s, human_vocab_size, machine_vocab_size):
"""
Arguments:
Tx -- length of the input sequence
Ty -- length of the output sequence
n_a -- hidden state size of the Bi-LSTM
n_s -- hidden state size of the post-attention LSTM
human_vocab_size -- size of the python dictionary "human_vocab"
machine_vocab_size -- size of the python dictionary "machine_vocab"
Returns:
model -- Keras model instance
"""
# Define the inputs of your model with a shape (Tx,)
# Define s0 and c0, initial hidden state for the decoder LSTM of shape (n_s,)
X = Input(shape=(Tx, human_vocab_size))
s0 = Input(shape=(n_s,), name='s0')
c0 = Input(shape=(n_s,), name='c0')
s = s0
c = c0
# Initialize empty list of outputs
outputs = []
### START CODE HERE ###
# Step 1: Define your pre-attention Bi-LSTM. Remember to use return_sequences=True. (≈ 1 line)
a = Bidirectional(LSTM(n_a, return_sequences=True))(X)
# Step 2: Iterate for Ty steps
for t in range(Ty):
# Step 2.A: Perform one step of the attention mechanism to get back the context vector at step t (≈ 1 line)
context = one_step_attention(a, s)
# Step 2.B: Apply the post-attention LSTM cell to the "context" vector.
# Don't forget to pass: initial_state = [hidden state, cell state] (≈ 1 line)
s, _, c = post_activation_LSTM_cell(context, initial_state=[s, c])
# Step 2.C: Apply Dense layer to the hidden state output of the post-attention LSTM (≈ 1 line)
out = output_layer(s)
# Step 2.D: Append "out" to the "outputs" list (≈ 1 line)
outputs.append(out)
print('out.shape = ', out.shape)
# Step 3: Create model instance taking three inputs and returning the list of outputs. (≈ 1 line)
model = Model(inputs=[X, s0, c0], outputs=outputs)
print("outputs.size = ", len(outputs))
### END CODE HERE ###
return model
本文所讲内容基于这两篇论文:
- Bahdanau et.al., 2014. Neural machine translation by jointly learning to align and tranlate
- Xu et.al., 2015. Show attention and tell: neural image caption generation with visual attention
以上是关于注意力模型(Attention Model)理解和实现的主要内容,如果未能解决你的问题,请参考以下文章