PDCA的运用特点是啥呢?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PDCA的运用特点是啥呢?相关的知识,希望对你有一定的参考价值。
参考技术A特点:
1、大环套小环、小环保大环、推动大循环。
PDCA循环作为质量管理的基本方法,不仅适用于整个工程项目,也适应于整个企业和企业内的科室、工段、班组以至个人。
各级部门根据企业的方针目标,都有自己的PDCA循环,层层循环,形成大环套小环,小环里面又套更小的环。
大环是小环的母体和依据,小环是大环的分解和保证。各级部门的小环都围绕着企业的总目标朝着同一方向转动。通过循环把企业上下或工程项目的各项工作有机地联系起来,彼此协同,互相促进。
2、不断前进、不断提高。
PDCA循环就像爬楼梯一样,一个循环运转结束,生产的质量就会提高一步,然后再制定下一个循环,再运转、再提高,不断前进,不断提高。
3、门路式上升。
PDCA循环不是在同一水平上循环,每循环一次,就解决一部分问题,取得一部分成果,工作就前进一步,水平就进步一步。每通过一次PDCA循环,都要进行总结,提出新目标,再进行第二次PDCA循环,使品质治理的车轮滚滚向前。PDCA每循环一次,品质水平和治理水平均更进一步。
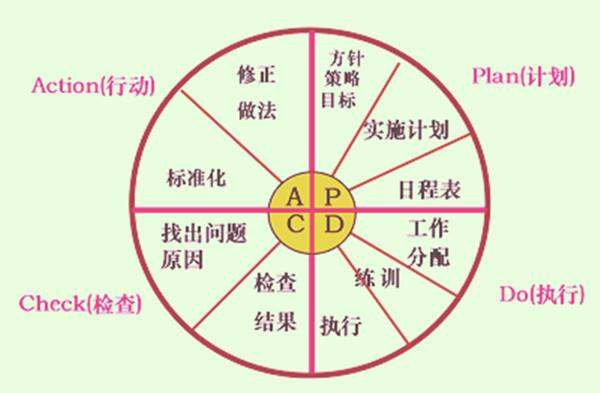
扩展资料:
应用阶段:
1、计划阶段。要通过市场调查、用户访问等,摸清用户对产品质量的要求,确定质量政策、质量目标和质量计划等。包括现状调查、分析、确定要因、制定计划。
2、设计和执行阶段。实施上一阶段所规定的内容。根据质量标准进行产品设计、试制、试验及计划执行前的人员培训。
3、检查阶段。主要是在计划执行过程之中或执行之后,检查执行情况,看是否符合计划的预期结果效果。
4、处理阶段。主要是根据检查结果,采取相应的措施。巩固成绩,把成功的经验尽可能纳入标准,进行标准化,遗留问题则转入下一个PDCA循环去解决。
随着更多项目管理中应用PDCA,在运用的过程中发现了很多问题,因为PDCA中不含有人的创造性的内容。他只是让人如何完善现有工作,所以这导致惯性思维的产生,习惯了PDCA的人很容易按流程工作,因为没有什么压力让他来实现创造性。所以,PDCA在实际的项目中有一些局限。
中国成长型企业结合自身的管理实践,把PDCA简化为4Y管理模式,让这一经典理论得到了新的发展。
4Y即Y1计划到位、Y2责任到位、Y3检查到位、Y4激励到位。
计划到位:好的结果来自于充分的事前准备和有效的协同配合。
责任到位:计划的完成需要行动的支撑,责任到人才会有真正的行动,中国成长型企业普遍存在指令不清,责任不明的状况,所以责任到位。
检查到位:人们不会做你期望的,只会做你监督和检查的,检查到位
激励到位:有反馈必有激励,好报才会有好人,所以激励到位。
结果导向:结果决定着企业的有效产出,所以,4Y强调结果导向。
参考资料:百度百科——PDCA循环
HBase是啥呢,有哪些特点呢?
HBase是什么呢,都有哪些特点呢?
参考技术AHbase是一种NoSQL数据库,这意味着它不像传统的RDBMS数据库那样支持SQL作为查询语言。Hbase是一种分布式存储的数据库,技术上来讲,它更像是分布式存储而不是分布式数据库,它缺少很多RDBMS系统的特性,比如列类型,辅助索引,触发器,和高级查询语言等待
那Hbase有什么特性呢?如下:
强读写一致,但是不是“最终一致性”的数据存储,这使得它非常适合高速的计算聚合
自动分片,通过Region分散在集群中,当行数增长的时候,Region也会自动的切分和再分配
自动的故障转移
Hadoop/HDFS集成,和HDFS开箱即用,不用太麻烦的衔接
丰富的“简洁,高效”API,Thrift/REST API,Java API
块缓存,布隆过滤器,可以高效的列查询优化
操作管理,Hbase提供了内置的web界面来操作,还可以监控JMX指标
什么时候用Hbase?
Hbase不适合解决所有的问题:
首先数据库量要足够多,如果有十亿及百亿行数据,那么Hbase是一个很好的选项,如果只有几百万行甚至不到的数据量,RDBMS是一个很好的选择。因为数据量小的话,真正能工作的机器量少,剩余的机器都处于空闲的状态
其次,如果你不需要辅助索引,静态类型的列,事务等特性,一个已经用RDBMS的系统想要切换到Hbase,则需要重新设计系统。
最后,保证硬件资源足够,每个HDFS集群在少于5个节点的时候,都不能表现的很好。因为HDFS默认的复制数量是3,再加上一个NameNode。
Hbase在单机环境也能运行,但是请在开发环境的时候使用。
内部应用
存储业务数据:车辆GPS信息,司机点位信息,用户操作信息,设备访问信息。。。
存储日志数据:架构监控数据(登录日志,中间件访问日志,推送日志,短信邮件发送记录。。。),业务操作日志信息
存储业务附件:UDFS系统存储图像,视频,文档等附件信息
不过在公司使用的时候,一般不使用原生的Hbase API,使用原生的API会导致访问不可监控,影响系统稳定性,以致于版本升级的不可控。
HFile
HFile是Hbase在HDFS中存储数据的格式,它包含多层的索引,这样在Hbase检索数据的时候就不用完全的加载整个文件。索引的大小(keys的大小,数据量的大小)影响block的大小,在大数据集的情况下,block的大小设置为每个RegionServer 1GB也是常见的。
探讨数据库的数据存储方式,其实就是探讨数据如何在磁盘上进行有效的组织。因为我们通常以如何高效读取和消费数据为目的,而不是数据存储本身。
Hfile生成方式
起初,HFile中并没有任何Block,数据还存在于MemStore中。
Flush发生时,创建HFile Writer,第一个空的Data Block出现,初始化后的Data Block中为Header部分预留了空间,Header部分用来存放一个Data Block的元数据信息。
而后,位于MemStore中的KeyValues被一个个append到位于内存中的第一个Data Block中:
注:如果配置了Data Block Encoding,则会在Append KeyValue的时候进行同步编码,编码后的数据不再是单纯的KeyValue模式。Data Block Encoding是HBase为了降低KeyValue结构性膨胀而提供的内部编码机制。
以上是关于PDCA的运用特点是啥呢?的主要内容,如果未能解决你的问题,请参考以下文章