造轮子从零开始搭建一个搜索引擎,数据结构和架构实现
Posted 小哈里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了造轮子从零开始搭建一个搜索引擎,数据结构和架构实现相关的知识,希望对你有一定的参考价值。
文章目录
1 前端 & 用户界面
最终效果
- 参考Baidu & Google的界面

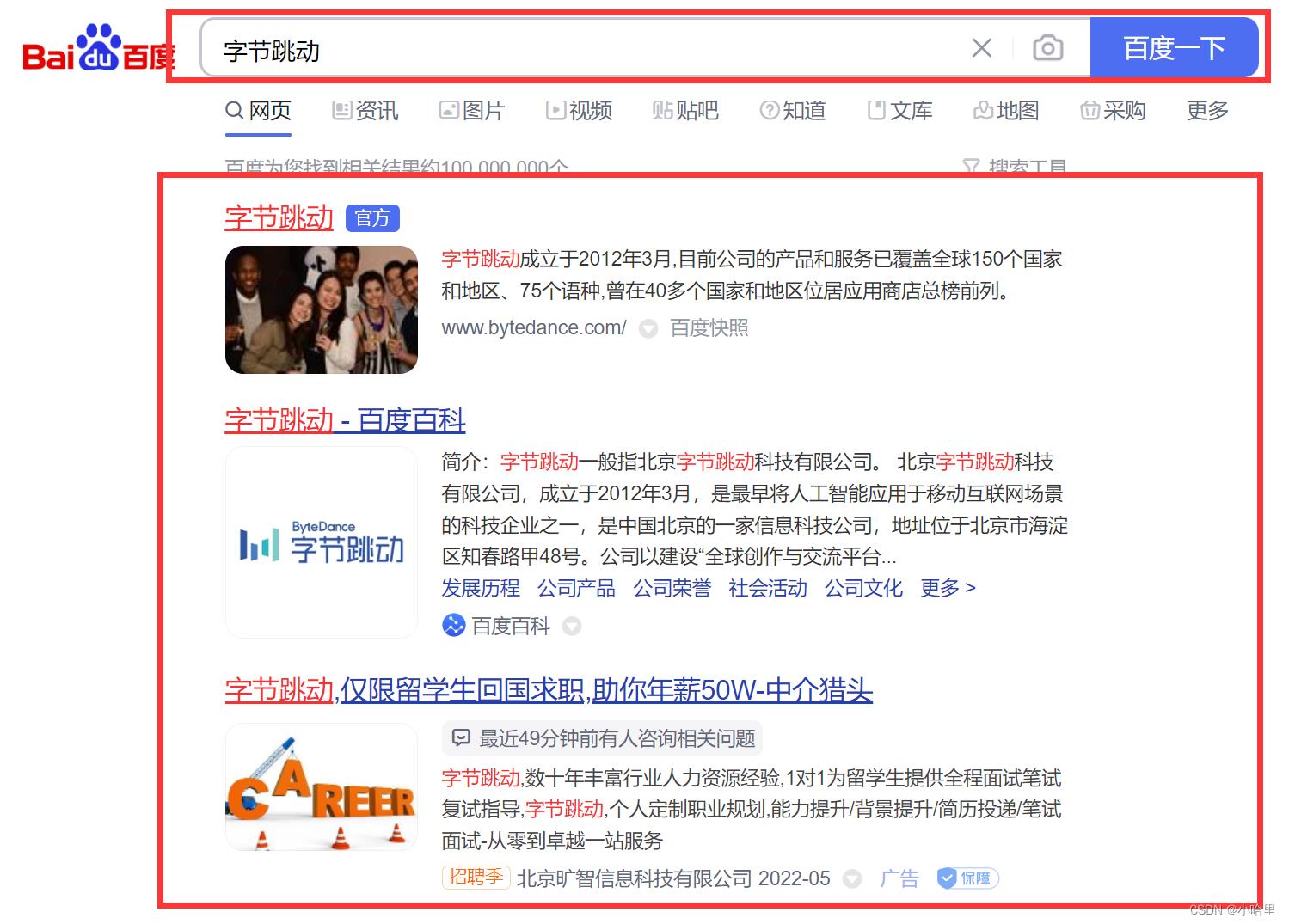
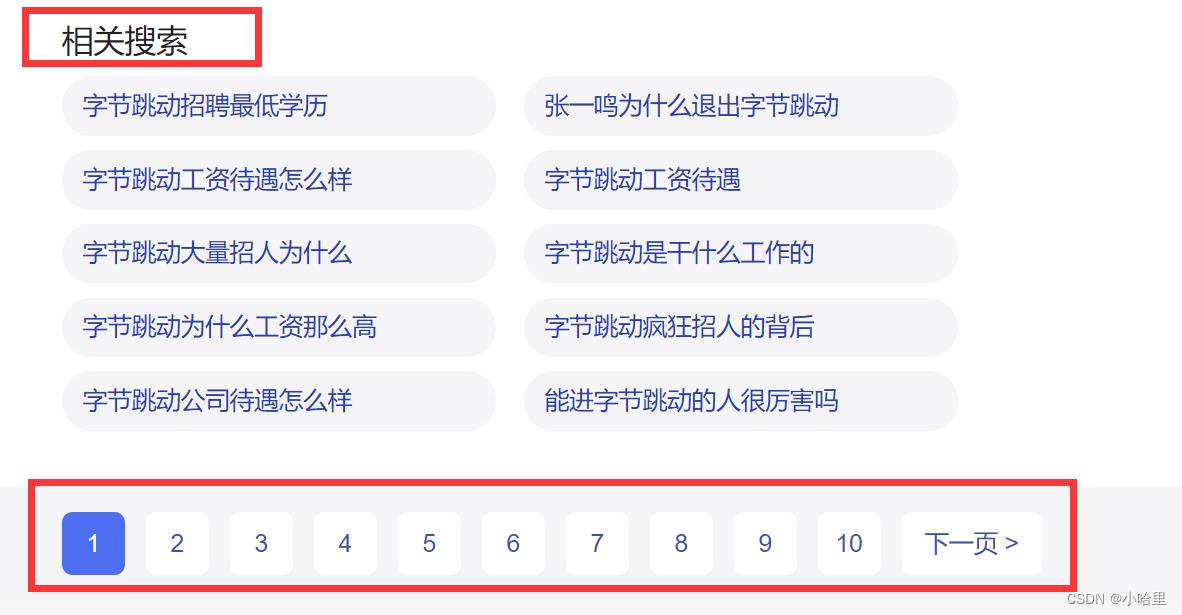
关于功能
-
需要实现的内容有 (4)
搜索框+结果列表+关键词推荐+页面跳转
关键词直接调用专属API返回的JSON
结果列表和页面跳转,考虑在调用API中引入参数第x页,返回1~20条,21~40条的内容。 -
不理解的功能?
支持纯文本信息的存储? 存储什么信息呢,是否是用户检索了xx信息,点击了yyy页面后,更新yyy页面的权重?
数据接口层,需要提供的API
- 返回搜索结果(搜索xxx, 第x页,不含xxx关键词) (占比:60%)
- 返回相关搜索列表(当前关键词) (占比:20%)
- 信息存储(增加索引?删除索引?)
- 在线分词(测试用)
参考文献
-
参考开发框架
Vue -
参考资料:
https://segmentfault.com/a/1190000039318492
https://gitee.com/turbo30/hcvue
https://github.com/xujingguo58/tinySearchEngine
https://github.com/chenhongyun/search_vue
2 服务层 & 功能实现
序,衡量指标
- 搜索性能 & 结果关联度 (占比:10%)
在数据结构上进行改良和优化 - 项目文件结构 & 代码风格 (占比:10%)
google code style 一下
1、将句子分词为关键词
-
参考jieba的原理与使用
https://blog.csdn.net/qq_33957603/article/details/124640588 -
TF-IDF
TF:某个词在句子中出现的次数 / 句子总词数 (感觉毫无意义,谁搜索一样的词啊)
IDF:log(语料库中的句子总数 / 包含该词语的句子数), 这个有用
具体的使用来说,如果包含该词语的句子数越多,那么该词语的权重就下降,因为更通用。
类似于我,你,他,几乎是个句子都会包含。 -
将词语按照IDF降序排序,即如果包含这个词的句子越少,那么这个词语就更重要,因为他很可能是专有名词。
-
考虑语料库的建立,如何索引出包含该词语的文章数量。
词语1,xxx篇包含,词语2,xxx篇包含,快速排序?
2、对于每个词,倒排索引出对应的文章
- 考虑倒排索引(word->docx)
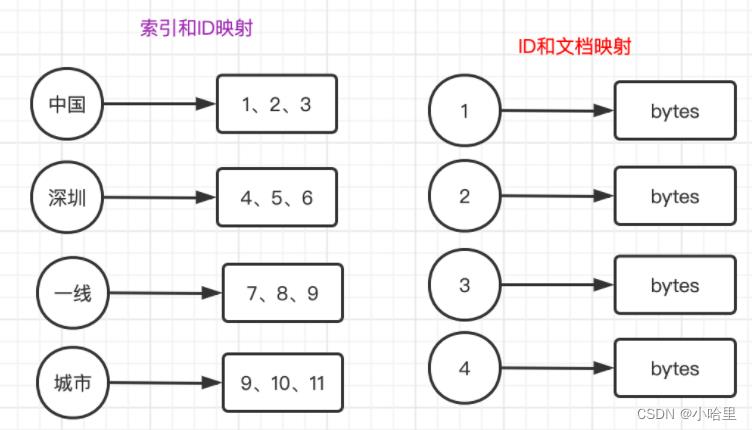
3、考虑对索引本身和索引出的文章进行排序
-
能否对每个词的倒排索引进行排序?(因为可能包含非常多的文章)
word1: docx1,docx2,docx3,docx4。
考虑采用平衡树来维护,维护文章id,维护索引的排序因子采用文章的TF(TF越高,说明该词在该文章中越重要),类似于map,插入和查找都是logn。 -
然后进行取交集操作(可能只取出一部分)
取出word1,word2,word3,word4对应的docx,进行取交集。
假设得到docx1,docx5,docx7,那么都是同时包含word1~4且含量较高的docx。
我们按照IDF作为第一关键词,TF作为第2关键词,对所有docx进行排序 (索引结构维护)? -
现在我们得到了排好序的docx
假设为docx5,docx7,docx1。
然后返回给前端即可。 -
参考资料:
https://developer.aliyun.com/article/765914
https://github.com/newpanjing/gofound/blob/main/docs/api.md
4+、考虑第x页的实现
-
功能实现
在排序文章中,加入第1~10条记录(一般搜索1页10条)。
考虑海量数据的分页,是否要对索引结构进行修改? 尽量不要去修改索引结构,不然维护难度就太大了。
这个暂时不太会 -
参考资料
提问:http://www.itpub.net/thread-570676-1-1.html
分页查询原理:https://www.cnblogs.com/caoweixiong/p/11937517.html
ES分页:https://www.modb.pro/db/61574
5+、考虑禁止词的实现
- 拿到之后再做一次暴力筛选,不用修改索引结构
比如本来请求1~10,现在我们请求1~30条记录,然后暴力统计每篇文章中是否包含禁止词(考虑建立正排索引?docx->word),如果包含禁止词就不做显示,数量不够再去请求。 - 参考资料
精准搜索:https://cloud.tencent.com/developer/article/1622850
精准词:https://juejin.cn/post/6844903861493170189
屏蔽:https://m.fx361.com/news/2017/0918/2276672.html
6+、考虑相关性推荐
-
使用前缀树进行实现
额外建一棵树?(这样就不用修改索引结构了) 只含关键词的,与排名无关?
对所有的关键词,进行前缀匹配和推荐即可。
https://cloud.tencent.com/developer/article/1145300 -
参考资料
推荐搜索(还是这篇文章):https://developer.aliyun.com/article/765914
相关搜索:https://segmentfault.com/a/1190000005754990
相关搜索2:https://singlecool.com/2017/07/29/RelevantSearch/
7+、考虑图片检索
- 对于文字搜图,直接文字搜文档,文档与图片一一对应即可
- 对于以图搜图,考虑如何把图片对应到文字,然后对文字进行分词,
分词后直接转化为搜索
考虑重新造一个数据集,把文字加到图片上,这样问题转化为文字识别?但是数据库要炸,所以不行。不可能直接检索数据库
所以这里需要做一个图像识别。可能会用到CNN卷积神经网络?要实现精准匹配、
3 数据层 & 考虑持久化
1、键值对数据库选用什么
- 参考资料:
leveldb介绍:https://www.cnblogs.com/chenny7/p/4026447.html
参考的import模块:https://github.com/syndtr/goleveldb
2、第一次启动服务端程序
-
需要初始化的
链接数据库:维护id对docx文章,维护关键词word的倒排索引到id编号?能否实现log存取,能否对每个word的docx按照TF(某个词在句子中出现的次数 / 文章总词数)进行排序。
构造平衡树:对关键词按照按照IDF(即语料库中的句子总数 / 包含该词语的句子数)进行排序。
构造前缀树:实现关键词的相关搜索 -
参考资料:
悟空数据源:https://wukong-dataset.github.io/wukong-dataset/download.html
3、是否需要考虑数据持久化
-
哪些数据需要持久化?
搜索结果吗?好像不用
增加索引? - > 增加什么索引呢? -> 搜索记录吗?
是否需要增加新的数据词典,还是说只有支持预处理的数据集进行检索? -
考虑数据词典
初始的数据集训练得到的语料库(关键词有重复,大小可以估算)
是否能支持加载新的语料库和进行一次训练,然后更新索引结构和数据库?
以上是关于造轮子从零开始搭建一个搜索引擎,数据结构和架构实现的主要内容,如果未能解决你的问题,请参考以下文章