Hive--01---基本概念
Posted 高高for 循环
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive--01---基本概念相关的知识,希望对你有一定的参考价值。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
Hive 基本概念
大数据 – 04-- Hive
1.什么是Hive
Hive是一个建立在Hadoop基础之上的数据仓库工具,以HiveQL(类SQL)的操作方式让我们能够轻松的实现分布式的海量离线数据处理。而不必去编写调试繁琐的MR程序。
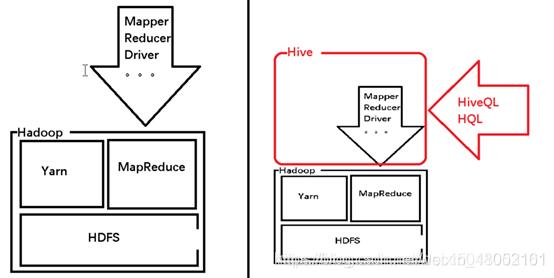
- Hive:由Facebook 开源用于解决海量结构化日志的数据统计工具。
- Hive 是基于Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL 查询功能。
2.Hive 本质
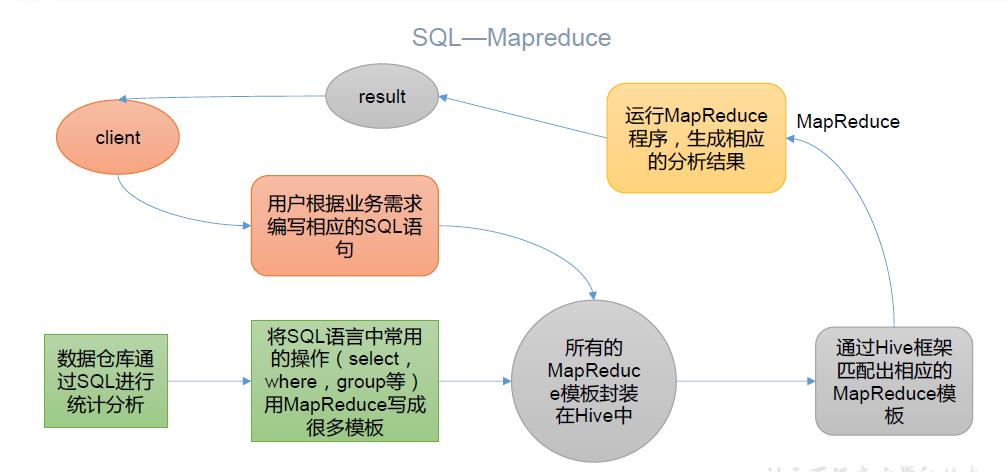
将HQL 转化成MapReduce 程序
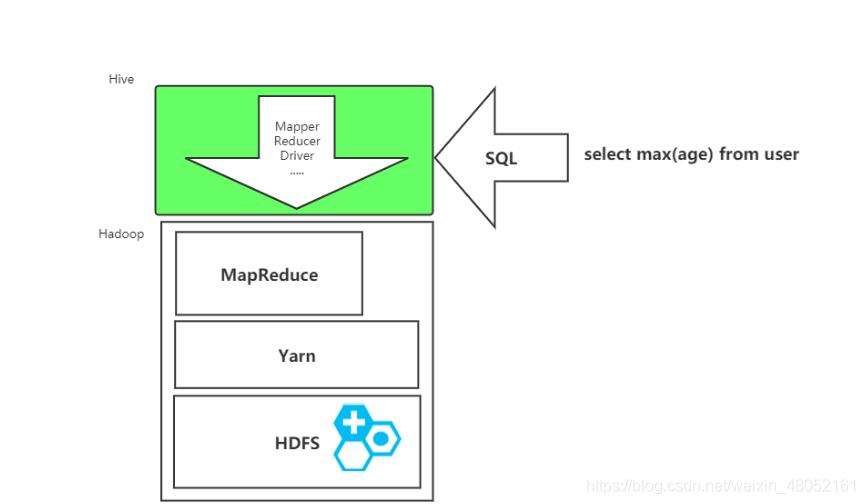
Hive 相当于是hadoop的一个客户端,通过提交sql,让hive底层去解析,封装成MapReduce任务,去HDFS读数据,提交给Yarn去执行

3.Hive 的优缺点
优点

缺点

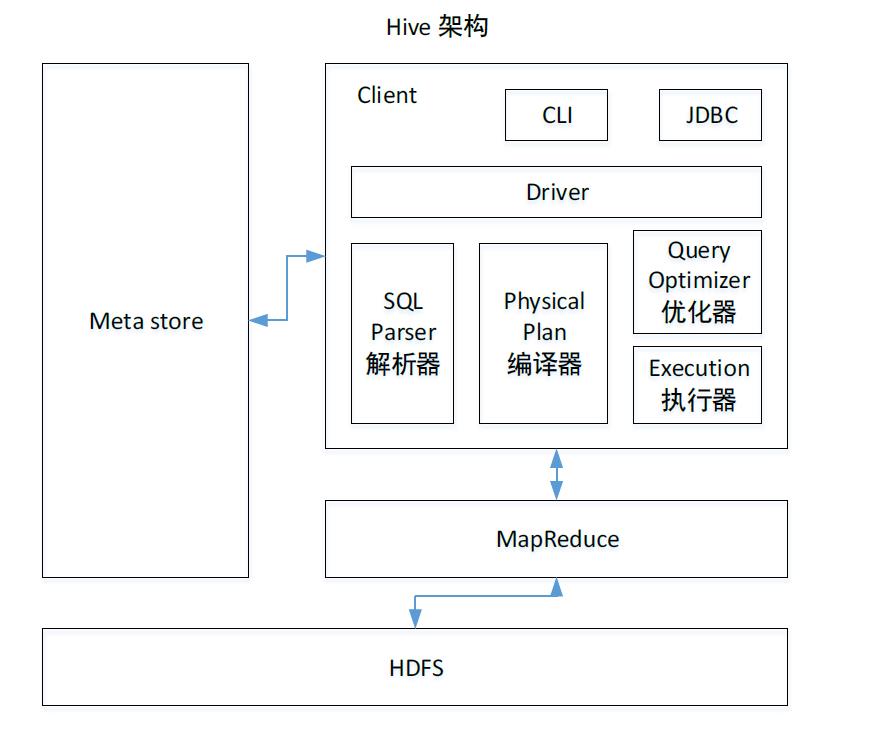
4.Hive 架构原理



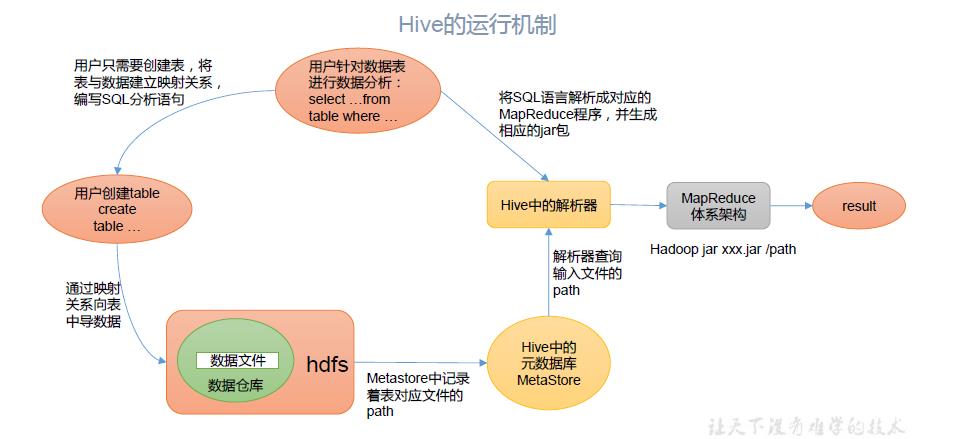

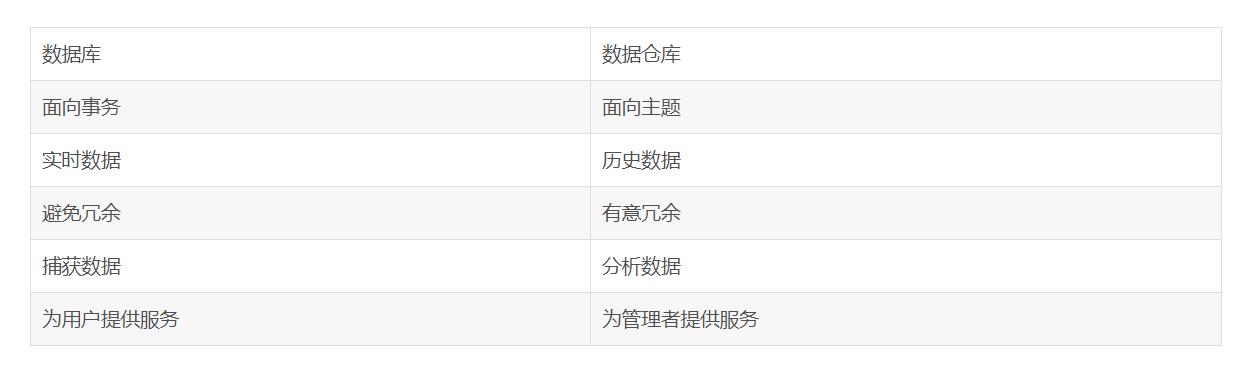
Hive 和数据库比较



数据仓库和关系型数据库的区别:
1.所有的离线数据处理场景都适用hive吗?
并不是所有场景都适合,逻辑简单又要求快速出结果的场景Hive优势更大。但是在业务逻辑非常复杂的情况下还是需要开发MapReduce程序更加直接有效。
2.Hive能作为业务系统的数据库使用吗?
不能。传统数据库要求能够为系统提供实时的增删改查,而Hive不支持行级别的增删改,查询的速度也不比传统关系型数据库,而是胜在吞吐量高,所以不能作为关系型数据库来使用。
3.Hive与传统MR方式处理数据相比能够提高运行效率吗?能够提高工作效率吗?
Hive的使用中需要将HQL编译为MR来运行,所以在执行效率上要低于直接运行MR程序。但是对于我们来说,由于只需要编写调试HQL,而不用开发调试复杂的MR程序,所以工作效率能够大大提高。
4.Hive为什么不支持行级别的增删
Hive不支持行级别的增删改的根本原因在于他的底层HDFS本身不支持。在HDFS中如果对整个文件的某一段或某一行内容进行增删改,势必会影响整个文件在集群中的存放布局。需要对整个集群中的数据进行汇总,重新切块,重新发送数据到每个节点,并备份,这样的情况是得不偿失的。所以HDFS的设计模式使他天生不适合做这个事
HDFS只提供追加写的API. 如果非要跟新,HDFS就得先把整个文件全部下载下来,修改完了,再重新覆盖上传 ,效率极低.
以上是关于Hive--01---基本概念的主要内容,如果未能解决你的问题,请参考以下文章