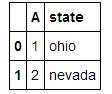
Python的pandas 数组如何得到索引值,如图,我要得到ohio 的索引值,应该怎样做?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python的pandas 数组如何得到索引值,如图,我要得到ohio 的索引值,应该怎样做?相关的知识,希望对你有一定的参考价值。
b['state'].index("ohio")
返回TypeError: 'Int64Index' object is not callable的错误。
该怎样获得索引值呢?
直接上实例:
df = pd.DataFrame(np.random.randn(5,3),index = list('abcde'),columns = ['one','two','three']) #创建一个数据框
df 内容
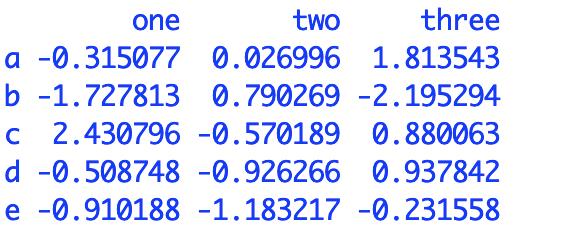
获取所有的列名,并形成列表:list(df.keys())

获取所有的行名,并形成列表:list(df.index)

如果要获得某一个元素的具体位置可以使用:np.where("条件"),如:np.where(df >0)

第一个arrary代表第几行,第二个代表第几列。
如,如何条件的元素存在在:第一行第三列,第三行第一列,....
参考技术A 你列的这个是pandas里面的数据框DataFrame数据类型,其实和R语言里面的差不多。访问某一列可以通过b['state']和b.state这两种方法进行,但是输出的pandas里面的Series这种数据类型,因此b['state'].index()返回Index([0,1], dtype=object)。因为数据分析某个值并不是非常重要,所以据我所知没有直接输出索引值的函数,不过可以通过query()函数,b.query('state == "obio"'),输出含有ohio的行自然也就知道了索引了。 参考技术B 可以将pandas 的dataframe数据类型先转换为numpy的矩阵。然后用np.argwhere去获取特定值的索引 参考技术C In [36]: list(df['state']).index('ohio')Out[36]: 0
In [37]: list(df['state']).index('nevada')
Out[37]: 1 参考技术D b[b.['state']=='ohio'].index
Python、Pandas:80/20 随机拆分数据;当索引值“丢失”时如何循环?
【中文标题】Python、Pandas:80/20 随机拆分数据;当索引值“丢失”时如何循环?【英文标题】:Python, Pandas: 80/20 Randomly Split Data; How to loop when index value is 'missing'? 【发布时间】:2016-05-07 13:46:59 【问题描述】:我正在尝试遍历从现有数据集随机生成的 Series 数据类型,以用作训练数据集)。这是我的Series数据集拆分后的输出:
Index data
0 1150
1 2000
2 1800
. .
. .
. .
1960 1800
1962 1200
. .
. .
. .
20010 1500
没有 1961 年的索引,因为创建训练数据集的随机选择过程删除了它。当我尝试循环计算我的残差平方和时,它不起作用。这是我的循环代码:
def ResidSumSquares(x, y, intercept, slope):
out = 0
temprss = 0
for i in x:
out = (slope * x.loc[i]) + intercept
temprss = temprss + (y.loc[i] - out)
RSS = temprss**2
return print("RSS: ".format(RSS))
KeyError: 'the label [1961] is not in the [index]'
我对 Python 还是很陌生,我不确定解决这个问题的最佳方法。
提前谢谢你。
【问题讨论】:
【参考方案1】:我在发布问题后立即找到了答案,我深表歉意。 @mkln 发表
How to reset index in a pandas data frame?
df = df.reset_index(drop=True)
这会重置整个Series 的索引,它不是DataFrame 数据类型独有的。
我更新的函数代码就像一个魅力:
def ResidSumSquares(x, y, intercept, slope):
out = 0
myerror = 0
x = x.reset_index(drop=True)
y = y.reset_index(drop=True)
for i in x:
out = slope * x.loc[i] + float(intercept)
myerror = myerror + (y.loc[i] - out)
RSS = myerror**2
return print("RSS: ".format(RSS))
【讨论】:
【参考方案2】:您省略了对ResidSumSquares 的实际调用。不重置函数内的索引并将训练集作为 x 传递怎么样?迭代一个不寻常的(不是 1,2,3,...)索引应该不是问题
【讨论】:
【参考方案3】:一些观察:
-
目前编写的函数是计算误差的平方和,而不是误差的平方和...这是故意的吗?后者通常用于回归类型的应用程序。由于您的变量名为
RSS--我假设残差总和 of 个平方,您将需要重新访问。
如果x 和y 是同一个较大数据集的一致子集,那么您应该对两者都有相同的索引,对吧?否则,通过删除索引,您可能会匹配不相关的 x 和 y 变量并掩盖代码前面的错误。
由于您使用的是 Pandas,因此可以轻松对其进行矢量化以提高可读性和速度(Python 循环的开销很高)
(3)的示例,假设(2),并说明(1)中方法之间的差异:
#assuming your indices should be aligned,
#pandas will link xs and ys by index
vectorized_error = y - slope*x + float(intercept)
#your residual sum of squares--you have to square first!
rss = (vectorized_error**2).sum()
# if you really want the square of the summed errors...
sse = (vectorized_error.sum())**2
编辑:没有注意到这已经死了一年。
【讨论】:
以上是关于Python的pandas 数组如何得到索引值,如图,我要得到ohio 的索引值,应该怎样做?的主要内容,如果未能解决你的问题,请参考以下文章