10个常见触发IO瓶颈的高频业务场景
Posted 华为云开发者联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了10个常见触发IO瓶颈的高频业务场景相关的知识,希望对你有一定的参考价值。
摘要:本文从应用业务优化角度,以常见触发IO慢的业务SQL场景为例,指导如何通过优化业务去提升IO效率和降低IO。
本文分享自华为云社区《GaussDB(DWS)性能优化之业务降IO优化》,作者:along_2020。
IO高?业务慢?在DWS实际业务场景中因IO高、IO瓶颈导致的性能问题非常多,其中应用业务设计不合理导致的问题占大多数。本文从应用业务优化角度,以常见触发IO慢的业务SQL场景为例,指导如何通过优化业务去提升IO效率和降低IO。
说明 :因磁盘故障(如慢盘)、raid卡读写策略(如Write Through)、集群主备不均等非应用业务原因导致的IO高不在本次讨论。
一、确定IO瓶颈&识别高IO的语句
1、查等待视图确定IO瓶颈
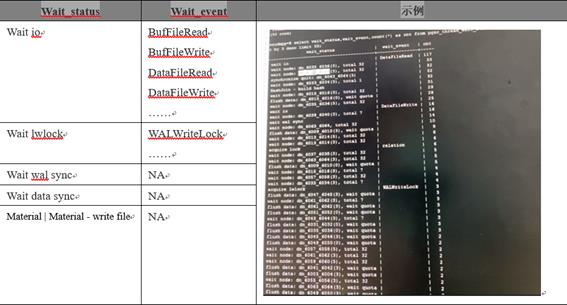
SELECT wait_status,wait_event,count(*) AS cnt FROM pgxc_thread_wait_status
WHERE wait_status <> 'wait cmd' AND wait_status <> 'synchronize quit' AND wait_status <> 'none'
GROUP BY 1,2 ORDER BY 3 DESC limit 50;IO瓶颈时常见等待状态如下:
2、抓取高IO消耗的SQL
主要思路为先通过OS命令识别消耗高的线程,然后结合DWS的线程号信息找到消耗高的业务SQL,具体方法参见附件中iowatcher.py脚本和README使用介绍
3、SQL级IO问题分析基础
在抓取到消耗IO高的业务SQL后怎么分析?主要掌握以下两点基础知识:
1)PGXC_THREAD_WAIT_STATUS视图功能,详细介绍参见:
PGXC_THREAD_WAIT_STATUS_数据仓库服务 GaussDB(DWS)_开发指南(8.1.0)_系统表和系统视图_系统视图_华为云
2)EXPLAIN功能,至少需掌握的知识点有Scan算子、A-time、A-rows、E- rows,详细介绍参见:
GaussDB(DWS)性能调优系列基础篇二:大道至简explain分布式计划-云社区-华为云
二、常见触发IO瓶颈的高频业务场景
场景1:列存小CU膨胀
某业务SQL查询出390871条数据需43248ms,分析计划主要耗时在Cstore Scan
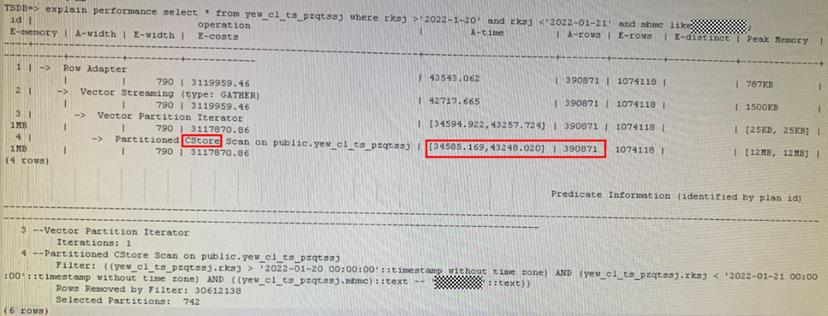
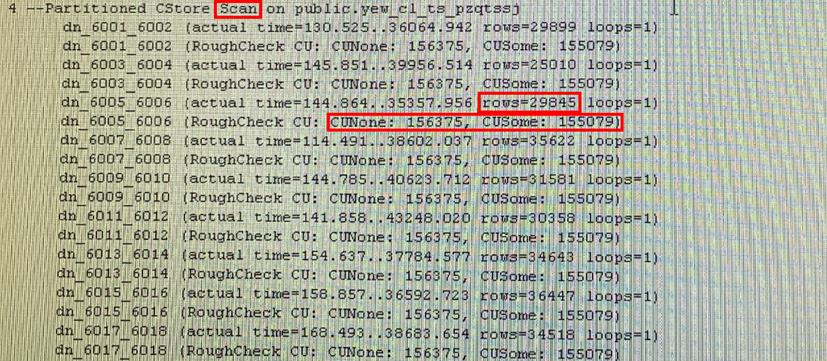
Cstore Scan的详细信息中,每个DN扫描出2w左右的数据,但是扫描了有数据的CU(CUSome) 155079个,没有数据的CU(CUNone) 156375个,说明当前小CU、未命中数据的CU极多,也即CU膨胀严重。
触发因素:对列存表(分区表尤甚)进行高频小批量导入会造成CU膨胀
处理方法:
1、列存表的数据入库方式修改为攒批入库,单分区单批次入库数据量大于DN个数*6W为宜
2、如果确因业务原因无法攒批,则考虑次选方案,定期VACUUM FULL此类高频小批量导入的列存表。
3、当小CU膨胀很快时,频繁VACUUM FULL也会消耗大量IO,甚至加剧整个系统的IO瓶颈,这时需考虑整改为行存表(CU长期膨胀严重的情况下,列存的存储空间优势和顺序扫描性能优势将不复存在)。
场景2:脏数据&数据清理
某SQL总执行时间2.519s,其中Scan占了2.516s,同时该表的扫描最终只扫描到0条符合条件数据,过滤了20480条数据,也即总共扫描了20480+0条数据却消耗了2s+,这种扫描时间与扫描数据量严重不符的情况,基本就是脏数据多影响扫描和IO效率。
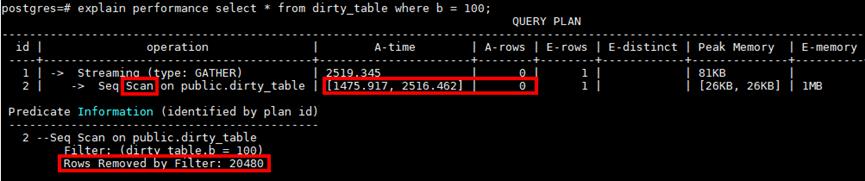
查看表脏页率为99%,Vacuum Full后性能优化到100ms左右

触发因素:表频繁执行update/delete导致脏数据过多,且长时间未VACUUM FULL清理
处理方法:
- 对频繁update/delete产生脏数据的表,定期VACUUM FULL,因大表的VACUUM FULL也会消耗大量IO,因此需要在业务低峰时执行,避免加剧业务高峰期IO压力。
- 当脏数据产生很快,频繁VACUUM FULL也会消耗大量IO,甚至加剧整个系统的IO瓶颈,这时需要考虑脏数据的产生是否合理。针对频繁delete的场景,可以考虑如下方案:1)全量delete修改为truncate或者使用临时表替代 2)定期delete某时间段数据,设计成分区表并使用truncate&drop分区替代
场景3:表存储倾斜
例如表Scan的A-time中,max time dn执行耗时6554ms,min time dn耗时0s,dn之间扫描差异超过10倍以上,这种集合Scan的详细信息,基本可以确定为表存储倾斜导致
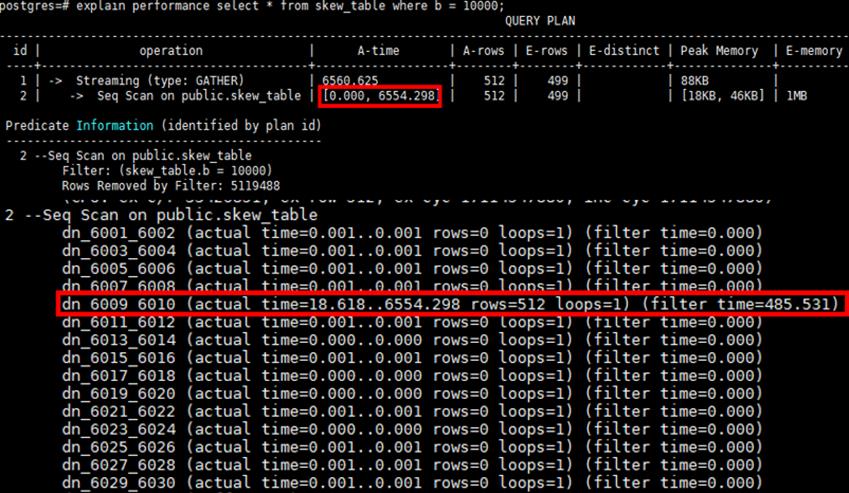
通过table_distribution发现所有数据倾斜到了dn_6009单个dn,修改分布列使的表存储分布均匀后,max dn time和min dn time基本维持在相同水平400ms左右,Scan时间从6554ms优化到431ms。

触发因素:分布式场景,表分布列选择不合理会导致存储倾斜,同时导致DN间压力失衡,单DN IO压力大,整体IO效率下降。
解决办法:修改表的分布列使表的存储分布均匀,分布列选择原则参《GaussDB 8.x.x 产品文档》中“表设计最佳实践”之“选择分布列章节”。
场景4:无索引、有索引不走
例如某点查询,Seq Scan扫描需要3767ms,因涉及从4096000条数据中获取8240条数据,符合索引扫描的场景(海量数据中寻找少量数据),在对过滤条件列增加索引后,计划依然是Seq Scan而没有走Index Scan。
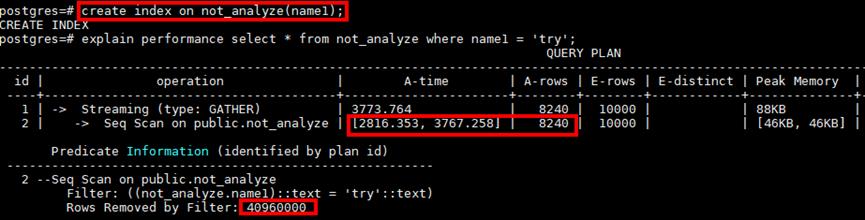
对目标表analyze后,计划能够自动选择索引,性能从3s+优化到2ms+,极大降低IO消耗

常见场景:行存大表的查询场景,从大量数据中访问极少数据,没走索引扫描而是走顺序扫描,导致IO效率低,不走索引常见有两种情况:
- 过滤条件列上没建索引
- 有索引但是计划没选索引扫描
触发因素:
- 常用过滤条件列没有建索引
- 表中数据因DML产生数据特征变化后未及时ANALYZE导致优化器无法选择索引扫描计划,ANALYZE介绍参见GaussDB(DWS)性能调优系列基础篇一:万物之始analyze统计信息-云社区-华为云
处理方式:
1、对行存表常用过滤列增加索引,索引基本设计原则:
- 索引列选择distinct值多,且常用于过滤条件,过滤条件多时可以考虑建组合索引,组合索引中distinct值多的列排在前面,索引个数不宜超过3个
- 大量数据带索引导入会产生大量IO,如果该表涉及大量数据导入,需严格控制索引个数,建议导入前先将索引删除,导数完毕后再重新建索引;
2、对频繁做DML操作的表,业务中加入及时ANALYZE,主要场景:
- 表数据从无到有
- 表频繁进行INSERT/UPDATE/DELETE
- 表数据即插即用,需要立即访问且只访问刚插入的数据
场景5:无分区、有分区不剪枝
例如某业务表进场使用createtime时间列作为过滤条件获取特定时间数据,对该表设计为分区表后没有走分区剪枝(Selected Partitions数量多),Scan花了701785ms,IO效率极低。
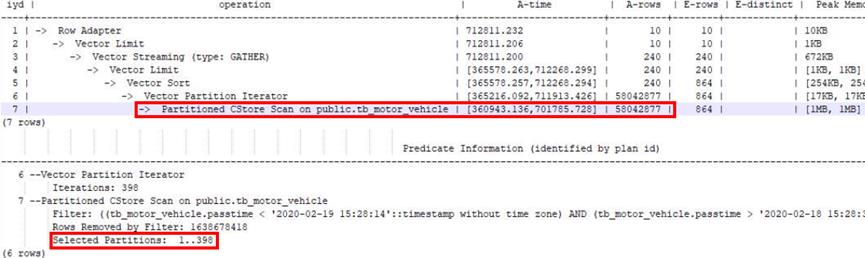
在增加分区键creattime作为过滤条件后,Partitioned scan走分区剪枝(Selected Partitions数量极少),性能从700s优化到10s,IO效率极大提升。

常见场景:按照时间存储数据的大表,查询特征大多为访问当天或者某几天的数据,这种情况应该通过分区键进行分区剪枝(只扫描对应少量分区)来极大提升IO效率,不走分区剪枝常见的情况有:
- 未设计成分区表
- 设计了分区没使用分区键做过滤条件
- 分区键做过滤条件时,对列值有函数转换
触发因素:未合理使用分区表和分区剪枝功能,导致扫描效率低
处理方式:
- 对按照时间特征存储和访问的大表设计成分区表
- 分区键一般选离散度高、常用于查询filter条件中的时间类型的字段
- 分区间隔一般参考高频的查询所使用的间隔,需要注意的是针对列存表,分区间隔过小(例如按小时)可能会导致小文件过多的问题,一般建议最小间隔为按天。
场景6:行存表求count值
例如某行存大表频繁全表count(指不带filter条件或者filter条件过滤很少数据的count),其中Scan花费43s,持续占用大量IO,此类作业并发起来后,整体系统IO持续100%,触发IO瓶颈,导致整体性能慢。

对比相同数据量的列存表(A-rows均为40960000),列存的Scan只花费14ms,IO占用极低

触发因素:行存表因其存储方式的原因,全表scan的效率较低,频繁的大表全表扫描,导致IO持续占用。
解决办法:
- 业务侧审视频繁全表count的必要性,降低全表count的频率和并发度
- 如果业务类型符合列存表,则将行存表修改为列存表,提高IO效率
场景7:行存表求max值
例如求某行存表某列的max值,花费了26772ms,此类作业并发起来后,整体系统IO持续100%,触发IO瓶颈,导致整体性能慢。

针对max列增加索引后,语句耗时从26s优化到32ms,极大减少IO消耗

触发因素:行存表max值逐个scan符合条件的值来计算max,当scan的数据量很大时,会持续消耗IO
解决办法:给max列增加索引,依靠btree索引天然有序的特征,加速扫描过程,降低IO消耗。
场景8:大量数据带索引导入
某客户场景数据往DWS同步时,延迟严重,集群整体IO压力大。
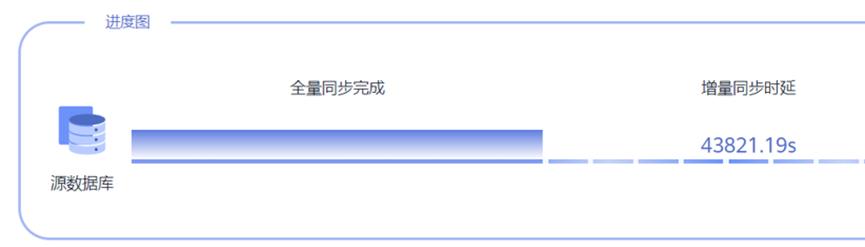
后台查看等待视图有大量wait wal sync和WALWriteLock状态,均为xlog同步状态

触发因素:大量数据带索引(一般超过3个)导入(insert/copy/merge into)会产生大量xlog,导致主备同步慢,备机长期Catchup,整体IO利用率飙高。历史案例参考:GaussDB(DWS)实例长期处于catchup问题分析-云社区-华为云
解决方案:
- 严格控制每张表的索引个数,建议3个以内
- 大量数据导入前先将索引删除,导数完毕后再重新建索引;
场景9:行存大表首次查询
某客户场景出现备DN持续Catcup,IO压力大,观察某个sql等待视图在wait wal sync

排查业务发现某查询语句执行时间较长,kill后恢复
触发因素:行存表大量数据入库后,首次查询触发page hint产生大量XLOG,触发主备同步慢及大量IO消耗。
解决措施:
- 对该类一次性访问大量新数据的场景,修改为列存表
- 关闭wal_log_hints和enable_crc_check参数(故障期间有丢数风险,不推荐)
场景10:小文件多IOPS高
某业务现场一批业务起来后,整个集群IOPS飙高,另外当出现集群故障后,长期building不完,IOPS飙高,相关表信息如下:
SELECT relname,reloptions,partcount FROM pg_class c INNER JOIN (
SELECT parented,count(*) AS partcount FROM pg_partition
GROUP BY parentid ) s ON c.oid = s.parentid ORDER BY partcount DESC;
触发因素:某业务库大量列存多分区(3000+)的表,导致小文件巨多(单DN文件2000w+),访问效率低,故障恢复Building极慢,同时building也消耗大量IOPS,发向影响业务性能。
解决办法:
- 整改列存分区间隔,减少分区个数来降低文件个数
- 列存表修改为行存表,行存的存储特征决定其文件个数不会像列存那么膨胀严重
三、小结
经过前面案例,稍微总结下不难发现,提升IO使用效率概括起来可分为两个维度,即提升IO的存储效率和计算效率(又称访问效率),提升存储效率包括整合小CU、减少脏数据、消除存储倾斜等,提升计算效率包括分区剪枝、索引扫描等,大家根据实际场景灵活处理即可。

华为伙伴暨开发者大会2022火热来袭,重磅内容不容错过!
【精彩活动】
勇往直前·做全能开发者→12场技术直播前瞻,8大技术宝典高能输出,还有代码密室、知识竞赛等多轮神秘任务等你来挑战。即刻闯关,开启终极大奖!点击踏上全能开发者晋级之路吧!
【技术专题】
未来已来,2022技术探秘→华为各领域的前沿技术、重磅开源项目、创新的应用实践,站在智能世界的入口,探索未来如何照进现实,干货满满点击了解
以上是关于10个常见触发IO瓶颈的高频业务场景的主要内容,如果未能解决你的问题,请参考以下文章