SQL调优指南笔记14:Managing Extended Statistics
Posted dingdingfish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL调优指南笔记14:Managing Extended Statistics相关的知识,希望对你有一定的参考价值。
本文为SQL Tuning Guide第14章“Managing Extended Statistics”的笔记。
重要基本概念
- column group statistics
Extended statistics gathered on a group of columns treated as a unit.
在作为一个单元处理的一组列上收集的扩展统计信息。
DBMS_STATS 使您能够收集扩展统计信息,这些统计信息可以在表的不同列上存在多个谓词或谓词使用表达式时改进基数估计。
扩展是列组或表达式。 当同一表中的多个列在 SQL 语句中同时出现时,列组统计信息可以改进基数估计。 当谓词使用表达式(例如,内置或用户定义的函数)时,表达式统计信息会改进优化器的估计。
注意:您不能在虚拟列上创建扩展统计信息。
14.1 Managing Column Group Statistics
列组是被视为一个单元的一组列。
本质上,列组是一个虚拟列。 通过收集列组的统计信息,优化器可以更准确地确定查询将这些列组合在一起时的基数估计值。
以下部分概述了列组统计信息,并说明了如何手动管理它们。
14.1.1 About Statistics on Column Groups
单个列统计信息对于确定 WHERE 子句中单个谓词的选择性很有用。
当 WHERE 子句在同一个表的不同列上包含多个谓词时,各个列的统计信息不会显示列之间的关系。 这是列组解决的问题。
优化器独立计算谓词的选择性,然后将它们组合起来。 但是,如果各个列之间存在相关性,则优化器在确定基数估计时无法将其考虑在内,它通过将每个表谓词的选择性乘以行数来创建基数估计。
下图对比了在 sh.customers 表的 cust_state_province 和 country_id 列上收集统计信息的两种方式。 该图显示 DBMS_STATS 分别收集每个列和组的统计信息。 列组具有系统生成的名称。
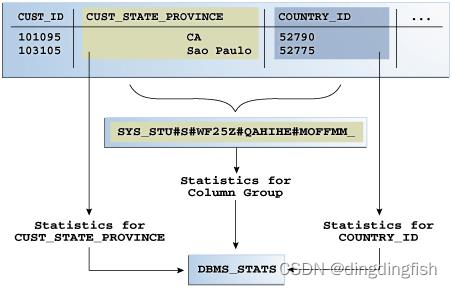
注意:优化器将列组统计信息用于相等谓词、inlist 谓词和估计 GROUP BY 基数。
14.1.1.1 Why Column Group Statistics Are Needed: Example
此示例演示列组统计信息如何使优化器能够提供更准确的基数估计。
DBA_TAB_COL_STATISTICS 表的以下查询显示有关已从 sh.customers 表中的 cust_state_province 和 country_id 列收集的统计信息:
COL COLUMN_NAME FORMAT a20
COL NDV FORMAT 999
SELECT COLUMN_NAME, NUM_DISTINCT AS "NDV", HISTOGRAM
FROM DBA_TAB_COL_STATISTICS
WHERE OWNER = 'SH'
AND TABLE_NAME = 'CUSTOMERS'
AND COLUMN_NAME IN ('CUST_STATE_PROVINCE', 'COUNTRY_ID');
OLUMN_NAME NDV HISTOGRAM
-------------------- ---- ---------------
CUST_STATE_PROVINCE 145 FREQUENCY
COUNTRY_ID 19 FREQUENCY
-- 3341 名客户居住在加利福尼亚:
SELECT COUNT(*)
FROM sh.customers
WHERE cust_state_province = 'CA';
COUNT(*)
----------
3341
EXPLAIN PLAN FOR
SELECT *
FROM sh.customers
WHERE cust_state_province = 'CA'
AND country_id=52790;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1115 | 205K| 445 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| CUSTOMERS | 1115 | 205K| 445 (1)| 00:00:01 |
-------------------------------------------------------------------------------
根据 country_id 和 cust_state_province 列的单列统计,优化器估计美国加利福尼亚客户的查询将返回 1115 行。 事实上,有 3341 位客户居住在加利福尼亚州,但优化器并不知道加利福尼亚州位于美国所在的国家/地区,因此通过假设两个谓词都减少了返回的行数而大大低估了基数。
您可以通过收集列组统计信息使优化器了解 country_id 和 cust_state_province 中的值之间的实际关系。 这些统计信息使优化器能够给出更准确的基数估计。
14.1.1.2 Automatic and Manual Column Group Statistics
Oracle 数据库可以自动或手动创建列组统计信息。
优化器可以使用 SQL 计划指令来生成更优化的计划。 如果 DBMS_STATS 首选项 AUTO_STAT_EXTENSIONS 设置为 ON(默认为 OFF),则 SQL 计划指令可以根据工作负载中谓词的使用情况自动触发列组统计信息的创建。 您可以使用 SET_TABLE_PREFS、SET_GLOBAL_PREFS 或 SET_SCHEMA_PREFS 过程设置 AUTO_STAT_EXTENSIONS。
当您想手动管理列组统计信息时,请使用 DBMS_STATS,如下所示:
- 检测列组
- 创建以前检测到的列组
- 手动创建列组并收集列组统计信息
14.1.1.3 User Interface for Column Group Statistics
几个 DBMS_STATS 程序单元具有与列组相关的首选项。
表 14-1 与列组相关的 DBMS_STATS API:
| 程序单元或首选项 | 描述 |
|---|---|
| SEED_COL_USAGE过程 | 迭代指定工作负载中的 SQL 语句,编译它们,然后为这些语句中出现的列播种列使用信息。 要确定适当的列组,数据库必须观察有代表性的工作负载。 您无需在监控期间自行运行查询。 相反,您可以对工作负载中一些运行时间较长的查询运行 EXPLAIN PLAN,以确保数据库正在记录这些查询的列组信息。 |
| REPORT_COL_USAGE 函数 | 生成一个报告,列出在工作负载中的过滤谓词、连接谓词和 GROUP BY 子句中看到的列。 您可以使用此功能查看为特定表记录的列使用信息。 |
| CREATE_EXTENDED_STATS函数 | 创建扩展,它们可以是列组或表达式。 当用户生成或自动统计收集作业收集表的统计信息时,数据库会收集扩展的统计信息。 |
| AUTO_STAT_EXTENSIONS首选项 | 当收集优化器统计信息时,控制自动创建扩展,包括列组。 使用 SET_TABLE_PREFS、SET_SCHEMA_PREFS 或 SET_GLOBAL_PREFS 设置此首选项。 当 AUTO_STAT_EXTENSIONS 设置为 OFF(默认)时,数据库不会自动创建列组统计信息。 要创建扩展,您必须执行 CREATE_EXTENDED_STATS 函数或在 DBMS_STATS API 的 METHOD_OPT 参数中明确指定扩展统计信息。 当设置为 ON 时,SQL 计划指令可以根据工作负载中谓词中列的使用情况自动触发列组统计信息的创建。 |
14.1.2 Detecting Useful Column Groups for a Specific Workload
您可以使用 DBMS_STATS.SEED_COL_USAGE 和 REPORT_COL_USAGE 根据指定的工作负载确定表需要哪些列组。
当您不知道要创建哪些扩展统计信息时,此技术很有用。 此技术不适用于表达式统计。
本教程假定以下内容:
- 对于使用引用列 country_id 和 cust_state_province 的谓词的 sh.customers_test 表(从 customers 表创建)的查询,基数估计不正确。
- 您希望数据库监控您的工作负载 5 分钟(300 秒)。
- 您希望数据库自动确定需要哪些列组。
-- 创建测试表,注意user的用法
DROP TABLE customers_test;
CREATE TABLE customers_test AS SELECT * FROM customers;
EXEC DBMS_STATS.GATHER_TABLE_STATS(user, 'customers_test');
-- 启用工作负载监控
exec DBMS_STATS.SEED_COL_USAGE(null,null,300);
-- 在customers_test 表上显示两个查询的解释计划
EXPLAIN PLAN FOR
SELECT *
FROM customers_test
WHERE cust_city = 'Los Angeles'
AND cust_state_province = 'CA'
AND country_id = 52790;
SELECT PLAN_TABLE_OUTPUT
FROM TABLE(DBMS_XPLAN.DISPLAY('plan_table', null,'basic rows'));
----------------------------------------------------
| Id | Operation | Name | Rows |
----------------------------------------------------
| 0 | SELECT STATEMENT | | 1 |
| 1 | TABLE ACCESS FULL| CUSTOMERS_TEST | 1 |
----------------------------------------------------
EXPLAIN PLAN FOR
SELECT country_id, cust_state_province, count(cust_city)
FROM customers_test
GROUP BY country_id, cust_state_province;
SELECT PLAN_TABLE_OUTPUT
FROM TABLE(DBMS_XPLAN.DISPLAY('plan_table', null,'basic rows'));
-----------------------------------------------------
| Id | Operation | Name | Rows |
-----------------------------------------------------
| 0 | SELECT STATEMENT | | 1949 |
| 1 | HASH GROUP BY | | 1949 |
| 2 | TABLE ACCESS FULL| CUSTOMERS_TEST | 55500 |
-----------------------------------------------------
第一个计划显示返回 932 行的查询的基数为 1 行。 第二个计划显示返回 145 行的查询的基数为 1949 行。
查看为表记录的列使用信息,可以看到列使用信息全部记录了。
SET LONG 100000
SET LINES 120
SET PAGES 0
SELECT DBMS_STATS.REPORT_COL_USAGE(user, 'customers_test')
FROM DUAL;
LEGEND:
.......
EQ : Used in single table EQuality predicate
RANGE : Used in single table RANGE predicate
LIKE : Used in single table LIKE predicate
NULL : Used in single table is (not) NULL predicate
EQ_JOIN : Used in EQuality JOIN predicate
NONEQ_JOIN : Used in NON EQuality JOIN predicate
FILTER : Used in single table FILTER predicate
JOIN : Used in JOIN predicate
GROUP_BY : Used in GROUP BY expression
...............................................................................
###############################################################################
COLUMN USAGE REPORT FOR SH.CUSTOMERS_TEST
.........................................
1. COUNTRY_ID : EQ
2. CUST_CITY : EQ
3. CUST_STATE_PROVINCE : EQ
4. (CUST_CITY, CUST_STATE_PROVINCE,
COUNTRY_ID) : FILTER
5. (CUST_STATE_PROVINCE, COUNTRY_ID) : GROUP_BY
###############################################################################
所有三列都出现在同一个 WHERE 子句中,因此报告将它们显示为组过滤器。 在第二个查询中,GROUP BY 子句中出现了两列,因此报告将它们标记为 GROUP_BY。 FILTER 和 GROUP_BY 报告中的列集是列组的候选。
14.1.3 Creating Column Groups Detected During Workload Monitoring
您可以使用 DBMS_STATS.CREATE_EXTENDED_STATS 函数来创建先前通过执行 DBMS_STATS.SEED_COL_USAGE 检测到的列组。
-- 根据监控窗口期间捕获的使用信息,为 customers_test 表创建列组。
SELECT DBMS_STATS.CREATE_EXTENDED_STATS(user, 'customers_test') FROM DUAL;
###############################################################################
EXTENSIONS FOR SH.CUSTOMERS_TEST
................................
1. (CUST_CITY, CUST_STATE_PROVINCE,
COUNTRY_ID) : SYS_STUMZ$C3AIHLPBROI#SKA58H_N created
2. (CUST_STATE_PROVINCE, COUNTRY_ID) : SYS_STU#S#WF25Z#QAHIHE#MOFFMM_ created
###############################################################################
-- 数据库为customers_test 创建了两个列组:一个列组用于过滤谓词,一组用于GROUP BY 操作。
-- 重新收集表统计信息。
EXEC DBMS_STATS.GATHER_TABLE_STATS(user,'customers_test');
-- 检查 USER_TAB_COL_STATISTICS 视图以确定数据库创建了哪些附加统计信息,注意最后以SYS_开头的两行:
COL COLUMN_NAME FOR A30
SET PAGES 9999
SELECT COLUMN_NAME, NUM_DISTINCT, HISTOGRAM
FROM USER_TAB_COL_STATISTICS
WHERE TABLE_NAME = 'CUSTOMERS_TEST'
ORDER BY 1;
COLUMN_NAME NUM_DISTINCT HISTOGRAM
------------------------------ ------------ ---------------
COUNTRY_ID 19 FREQUENCY
CUST_CITY 620 HYBRID
CUST_CITY_ID 620 NONE
CUST_CREDIT_LIMIT 8 NONE
CUST_EFF_FROM 1 NONE
CUST_EFF_TO 0 NONE
CUST_EMAIL 1699 NONE
CUST_FIRST_NAME 1300 NONE
CUST_GENDER 2 NONE
CUST_ID 55500 NONE
CUST_INCOME_LEVEL 12 NONE
CUST_LAST_NAME 908 NONE
CUST_MAIN_PHONE_NUMBER 51344 NONE
CUST_MARITAL_STATUS 11 NONE
CUST_POSTAL_CODE 623 NONE
CUST_SRC_ID 0 NONE
CUST_STATE_PROVINCE 145 FREQUENCY
CUST_STATE_PROVINCE_ID 145 NONE
CUST_STREET_ADDRESS 49900 NONE
CUST_TOTAL 1 NONE
CUST_TOTAL_ID 1 NONE
CUST_VALID 2 NONE
CUST_YEAR_OF_BIRTH 75 NONE
SYS_STU#S#WF25Z#QAHIHE#MOFFMM_ 145 NONE
SYS_STUMZ$C3AIHLPBROI#SKA58H_N 620 HYBRID
25 rows selected.
再次解释计划,新计划显示更准确的基数估计(第一个计划中,1032非常接近945,而第二个计划是完全准确)。
EXPLAIN PLAN FOR
SELECT *
FROM customers_test
WHERE cust_city = 'Los Angeles'
AND cust_state_province = 'CA'
AND country_id = 52790;
SELECT PLAN_TABLE_OUTPUT
FROM TABLE(DBMS_XPLAN.DISPLAY('plan_table', null,'basic rows'));
----------------------------------------------------
| Id | Operation | Name | Rows |
----------------------------------------------------
| 0 | SELECT STATEMENT | | 1013 |
| 1 | TABLE ACCESS FULL| CUSTOMERS_TEST | 1013 |
----------------------------------------------------
EXPLAIN PLAN FOR
SELECT country_id, cust_state_province, count(cust_city)
FROM customers_test
GROUP BY country_id, cust_state_province;
SELECT PLAN_TABLE_OUTPUT
FROM TABLE(DBMS_XPLAN.DISPLAY('plan_table', null,'basic rows'));
-----------------------------------------------------
| Id | Operation | Name | Rows |
-----------------------------------------------------
| 0 | SELECT STATEMENT | | 145 |
| 1 | HASH GROUP BY | | 145 |
| 2 | TABLE ACCESS FULL| CUSTOMERS_TEST | 55500 |
-----------------------------------------------------
清理:
drop table customers_test;
14.1.4 Creating and Gathering Statistics on Column Groups Manually
在某些情况下,您可能已经知道要创建的列组。
DBMS_STATS.GATHER_TABLE_STATS 函数的 METHOD_OPT 参数可以自动创建和收集列组的统计信息。 您可以通过使用 FOR COLUMNS 指定列组来创建新列组。
本教程假定以下内容:
- 您想为 sh 模式中的客户表中的 cust_state_province 和 country_id 列创建一个列组。
- 您想要收集有关整个表和新列组的统计信息(包括直方图)。
BEGIN
DBMS_STATS.GATHER_TABLE_STATS( 'sh','customers',
METHOD_OPT => 'FOR ALL COLUMNS SIZE SKEWONLY ' ||
'FOR COLUMNS SIZE SKEWONLY (cust_state_province,country_id)' );
END;
/
14.1.5 Displaying Column Group Information
要获取列组的名称,请使用 DBMS_STATS.SHOW_EXTENDED_STATS_NAME 函数或数据库视图。
您还可以使用视图来获取不同值的数量以及列组是否具有直方图等信息。
本教程假定以下内容:
- 您在 sh 模式的客户表中为 cust_state_province 和 country_id 列创建了一个列组。
- 您想要确定列组名称、不同值的数量以及是否已为列组创建直方图。
SELECT
sys.dbms_stats.show_extended_stats_name('sh', 'customers', '(cust_state_province,country_id)') col_group_name
FROM
dual;
COL_GROUP_NAME
-------------------------------------------
SYS_STU#S#WF25Z#QAHIHE#MOFFMM_
COL EXTENSION_NAME FOR A40
SELECT EXTENSION_NAME, EXTENSION
FROM USER_STAT_EXTENSIONS
WHERE TABLE_NAME='CUSTOMERS';
EXTENSION_NAME EXTENSION
---------------------------------------- -----------------------------------------------------
SYS_STU#S#WF25Z#QAHIHE#MOFFMM_ ("CUST_STATE_PROVINCE","COUNTRY_ID")
SELECT e.EXTENSION col_group, t.NUM_DISTINCT, t.HISTOGRAM
FROM USER_STAT_EXTENSIONS e, USER_TAB_COL_STATISTICS t
WHERE e.EXTENSION_NAME=t.COLUMN_NAME
AND e.TABLE_NAME=t.TABLE_NAME
AND t.TABLE_NAME='CUSTOMERS';
COL_GROUP NUM_DISTINCT HISTOGRAM
-------------------------------------------------------------------
("COUNTRY_ID","CUST_STATE_PROVINCE") 145 FREQUENCY
14.1.6 Dropping a Column Group
使用 DBMS_STATS.DROP_EXTENDED_STATS 函数从表中删除列组。
本教程假定以下内容:
- 您在 sh 模式的客户表中为 cust_state_province 和 country_id 列创建了一个列组。
- 您要删除列组。
EXEC DBMS_STATS.DROP_EXTENDED_STATS( 'sh', 'customers', '(cust_state_province, country_id)' );
14.2 Managing Expression Statistics
当 WHERE 子句具有使用表达式的谓词时,称为表达式统计的扩展统计类型可以改进优化器的估计。
14.2.1 About Expression Statistics
对于应用于 WHERE 子句列的 (function(col)=constant) 形式的表达式,优化器不知道该函数如何影响谓词基数,除非存在基于函数的索引。 但是,您可以收集有关 expression(function(col) 本身的表达式统计信息。
下图显示了优化器使用统计信息为使用函数的查询生成计划。 顶部显示优化器检查列的统计信息。 底部显示优化器检查与查询中使用的表达式相对应的统计信息。 表达式统计产生更准确的估计。
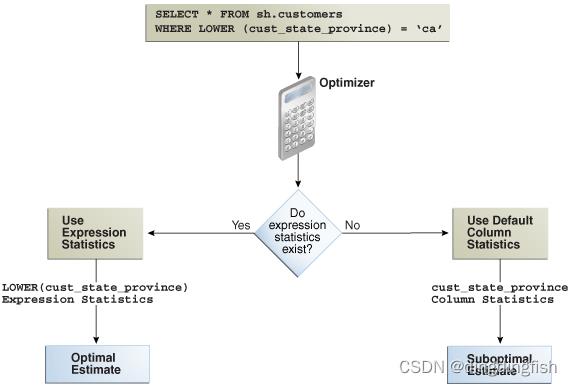
如上图所示,当表达式统计信息不可用时,优化器可以生成次优计划。
14.2.1.1 When Expression Statistics Are Useful: Example
SELECT COUNT(*) FROM sh.customers WHERE cust_state_province='CA';
COUNT(*)
----------
3341
EXPLAIN PLAN FOR
SELECT * FROM sh.customers WHERE LOWER(cust_state_province)='ca';
SELECT * FROM TABLE(dbms_xplan.display);
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 555 | 108K| 445 (1)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| CUSTOMERS | 555 | 108K| 445 (1)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(LOWER("CUST_STATE_PROVINCE")='ca')
因为 LOWER(cust_state_province)=‘ca’ 不存在表达式统计信息,所以优化器估计值明显偏离。 您可以使用 DBMS_STATS 过程来更正这些估计值。
14.2.2 Creating Expression Statistics
您可以使用 DBMS_STATS 为用户指定的表达式创建统计信息。
您可以使用以下任一程序单元:
- GATHER_TABLE_STATS 过程
- CREATE_EXTENDED_STATISTICS 函数后跟 GATHER_TABLE_STATS 过程
本教程假定以下内容:
- 对于使用 UPPER(cust_state_province) 函数的 sh.customers 查询,选择性估计是不准确的。
- 您想收集关于 UPPER(cust_state_province) 表达式的统计信息。
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(
'sh'
, 'customers'
, method_opt => 'FOR ALL COLUMNS SIZE SKEWONLY ' ||
'FOR COLUMNS (LOWER(cust_state_province)) SIZE SKEWONLY'
);
END;
14.2.3 Displaying Expression Statistics
要获取有关表达式统计信息的信息,请使用数据库视图 DBA_STAT_EXTENSIONS 和 DBMS_STATS.SHOW_EXTENDED_STATS_NAME 函数。
您还可以使用视图来获取不同值的数量以及列组是否具有直方图等信息。
本教程假定以下内容:
- 您为 LOWER(cust_state_province) 表达式创建了扩展统计信息。
- 您想要确定列组名称、不同值的数量以及是否已为列组创建直方图。
要监控表达式统计信息:
COL EXTENSION_NAME FORMAT a30
COL EXTENSION FORMAT a35
SELECT EXTENSION_NAME, EXTENSION
FROM USER_STAT_EXTENSIONS
WHERE TABLE_NAME='CUSTOMERS';
EXTENSION_NAME EXTENSION
------------------------------ -----------------------------------
SYS_STUBPHJSBRKOIK9O2YV3W8HOUE (LOWER("CUST_STATE_PROVINCE"))
SELECT e.EXTENSION expression, t.NUM_DISTINCT, t.HISTOGRAM
FROM USER_STAT_EXTENSIONS e, USER_TAB_COL_STATISTICS t
WHERE e.EXTENSION_NAME=t.COLUMN_NAME
AND e.TABLE_NAME=t.TABLE_NAME
AND t.TABLE_NAME='CUSTOMERS';
EXPRESSION NUM_DISTINCT HISTOGRAM
-------------------------------------------------------------------
(LOWER("CUST_STATE_PROVINCE")) 145 FREQUENCY
14.2.4 Dropping Expression Statistics
要从表中删除列组,请使用 DBMS_STATS.DROP_EXTENDED_STATS 函数。
本教程假定以下内容:
- 您为 LOWER(cust_state_province) 表达式创建了扩展统计信息。
- 您想要删除表达式统计信息。
BEGIN
DBMS_STATS.DROP_EXTENDED_STATS(
'sh'
, 'customers'
, '(LOWER(cust_state_province))'
);
END;
/
以上是关于SQL调优指南笔记14:Managing Extended Statistics的主要内容,如果未能解决你的问题,请参考以下文章