MAML:Model-Agnostic Meta-Learning
Posted birds-of-passage
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MAML:Model-Agnostic Meta-Learning相关的知识,希望对你有一定的参考价值。
文章目录
前言
深度神经网络在具有大数据集和充足计算资源的应用上取得了巨大成功,但是在数据缺乏情况下的学习能力及对新任务的快速泛化能力相当有限,而元学习可以解决这一问题。以往将深度神经网络应用到某一具体任务都是让模型从零开始学习任务的
相关领域知识,学习过程往往需要大量标记样本,而元学习则利用模型在已有相关任务上的学习经验(也称元知识)来指导新任务的学习,使得模型能够在很少的标记样本条件下适应新任务。元学习一般分为两个阶段,第一阶段主要是让深度神经网络从
多个任务中学习经验,使得网络具有跨任务的能力;第二个阶段主要是利用经验指导深度神经网络快速学习新任务。元学习方法一般可分为三种类型:基于优化的方法,基于模型的方法和基于度量的方法。
MAML 算法旨在利用少量样本对基本学习器进行训练,以获得一组良好模型初始化参数,该初始化参数能够迅速适应新任务
一、相关概念
1、meta-leaning指的是元学习,元学习是深度学习的一个分支,一个好的元模型(meta-learner)应该具备对新的、少量的数据做出快速而准确的学习。而传统的CNN网络都是输入大量的数据,然后进行分类的学习。但是这样做的问题就是,神经网络的通用性太差了。
2、few-shot learning few-shot learning译为小样本学习,是指从极少的样本中学习出一个模型。
3、N-way K-shot这是小样本学习中常用的数据,用以描述一个任务:它包含N个分类,每个分类只有K张图片。
4、Support set and Query setSupport set指的是参考集,Query set指的是测试集。用人识别动物种类大比分,有5种不同的动物,每种动物2张图片,这样10张图片给人做参考。另外给出5张动物图片,让人去判断各自属于那一种类。那么10张作为参考的图片就称为Support set,5张测试图片就称为Query set。
二、MAML介绍
1.要解决的问题
- 小样本问题
- 模型收敛太慢
普通的分类、检测任务中,因为分类、检测物体的类别是已知的,可以收集大量数据来训练。例如 VOC、COCO 等检测数据集,都有着上万张图片用于训练。而如果我们仅仅只有几张图片用于训练,这给模型预测带来很大障碍。在深度学习中,解决训练数据不足常用的一个技巧是“预训练-微调”(Pretraining-finetune),即大数据集上面预训练模型,然后在小数据集上去微调权重。但是,在训练数据极其稀少的时候(仅有个位数的训练图片),这个技巧是无法奏效的。并且这样的方式有时候反而会让模型陷入局部最优。
2.MAML的关键点
论文的设想是训练一组初始化参数,模型通过初始化参数,仅用少量数据就能实现快速收敛的效果。为了达到这一目的,模型需要大量的先验知识来不停修正初始化参数,使其能够适应不同种类的数据。
3.MAML与Pretraining的区别
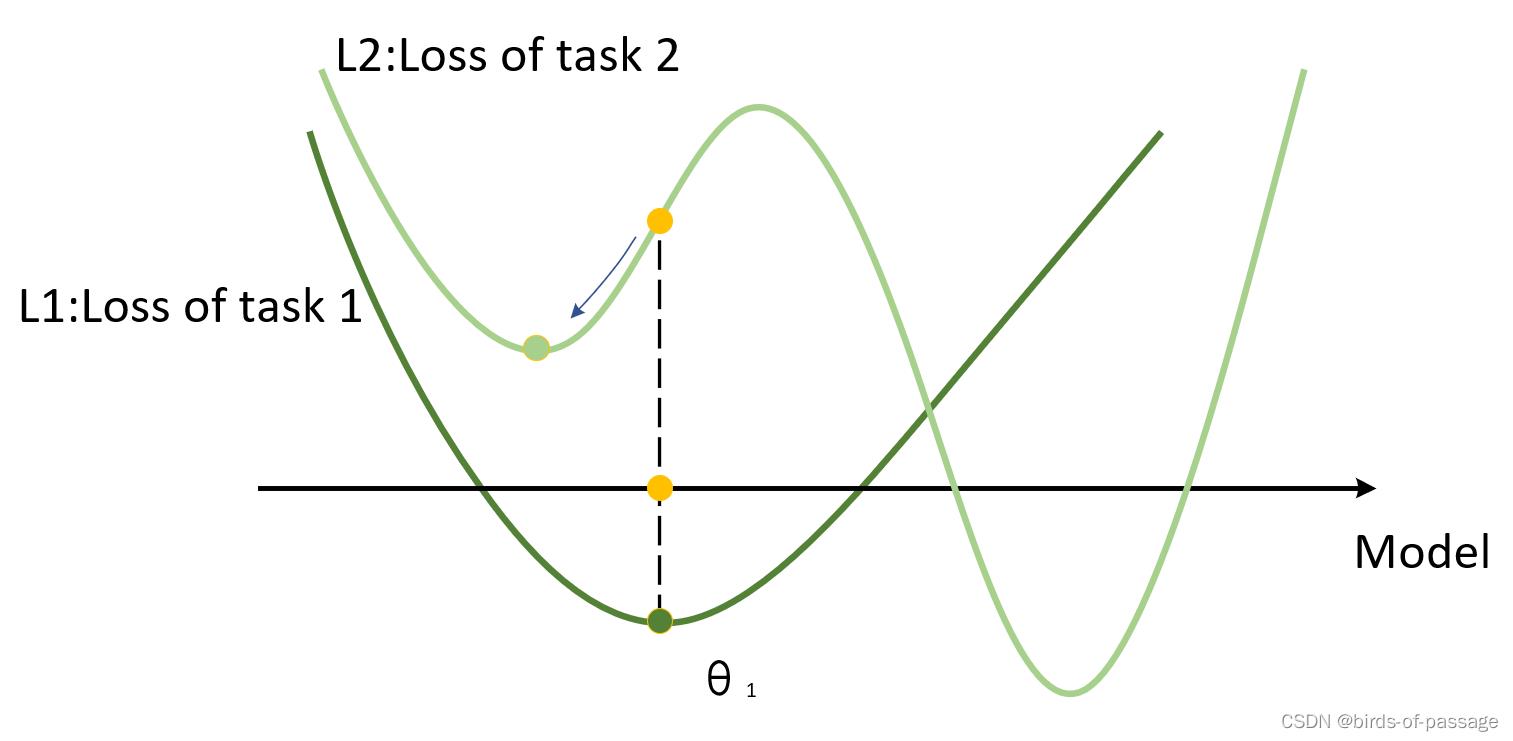
Pretraining
Pretraining假设有一个模型从task1的数据中训练出来了一组权重,我们记为θ1,这个θ1是图中深绿色的点,可以看到,在task1下,他已经达到了全局最优。而如果我们的模型如果用θ1 作为task2的初始值,我们最终将会到达浅绿色的点,而这个点只是task2的局部最优点。产生这样的问题也很简单,就是因为模型在训练task1的数据时并不用考虑task2的数据。
MAML
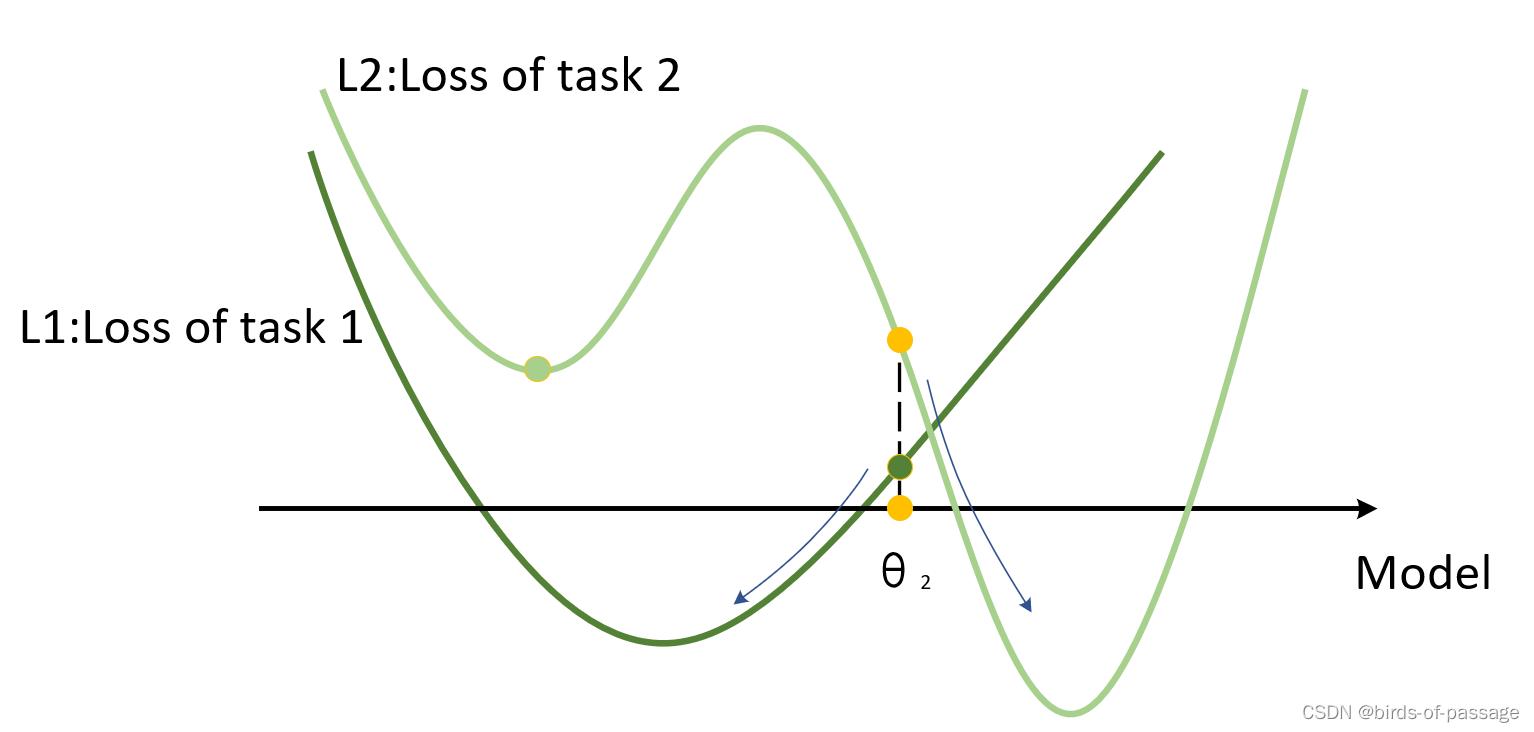
MAML则需要同时考虑两个数据集的分布,假设MAML经过训练以后得到了一组权重我们记为θ2 ,虽然从图中来看,这个权重对于两个任务来说,都没有达到全局最优。但是很明显,经过训练以后,他们都能收敛到全局最优。所以,Pretraining每次强调的都是当下这个模型能不能达到最优,而MAML强调的则是经过训练以后能不能达到最优。
三、MAML的核心算法
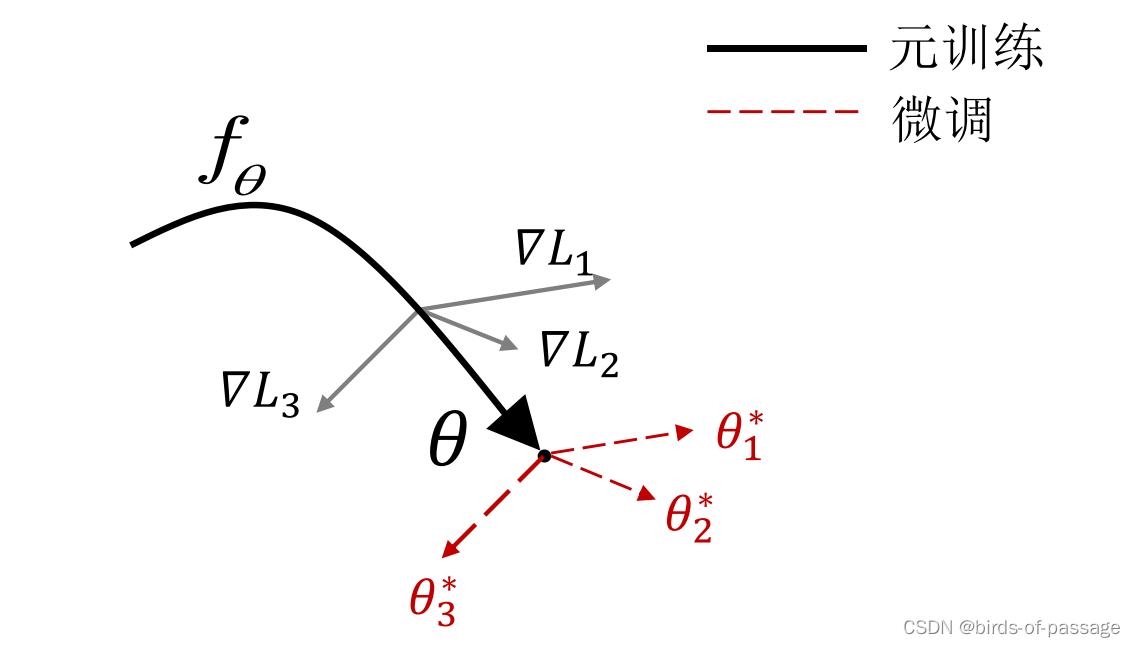
MAML关注的是,模型使用一份适应性很强的权重,它经过几次梯度下降就可以很好的适用于新的任务。
MAML训练的目标: “如何找到这个权重”
那么我们训练的目标就变成了“如何找到这个权重”。而MAML作为其中一种实现方式,它先对一个batch中的每个任务都训练一遍,然后回到这个原始的位置,对这些任务的loss进行一个综合的判断,再选择一个适合所有任务的方向。
其中有监督学习的分类问题算法流程如下:
总结
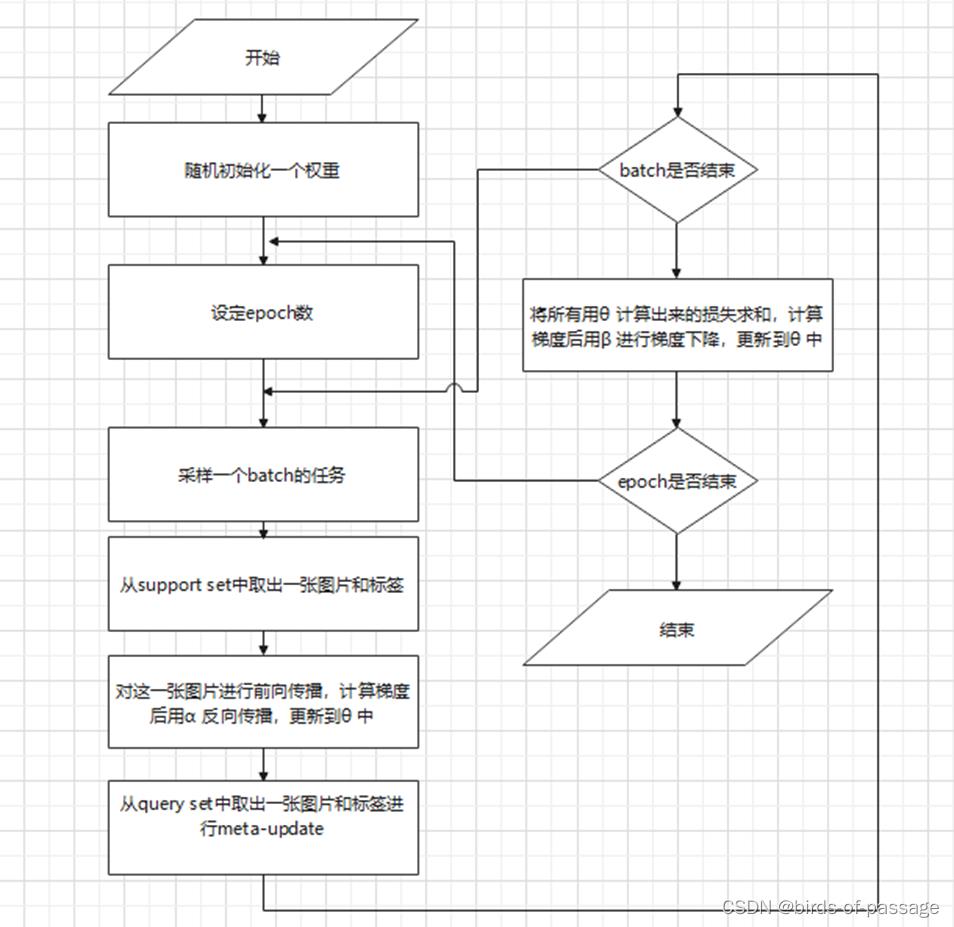
先决条件:以任务为单位的数据集两个学习率 α 、 β
流程解析:
Step 1: 随机初始化一个权重
Step 2: 一个while循环,对应的是训练中的epochs(Step 3-10)
Step 3: 采样一个batch的任务(假设为4个任务)
Step 4: for循环,用于遍历一个任务中的图片(Step 5-8)
Step 5: 从support set中取出一张图片和标签
Step 6-7: 对这一张图片进行前向传播,计算梯度后用α 反向传播,更新到θ 中。
Step 8: 从query set中取出一张图片和标签进行meta-update
Step 10: 将所有用θ 计算出来的损失求和,计算梯度后用β 进行梯度下降,更新到θ 中
以上是关于MAML:Model-Agnostic Meta-Learning的主要内容,如果未能解决你的问题,请参考以下文章