SQL调优指南笔记10:Optimizer Statistics Concepts
Posted dingdingfish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL调优指南笔记10:Optimizer Statistics Concepts相关的知识,希望对你有一定的参考价值。
本文为SQL Tuning Guide第10章“Optimizer Statistics Concepts”的笔记。
重要基本概念
-
execution plan
The combination of steps used by the database to execute a SQL statement. Each step either retrieves rows of data physically from the database or prepares them for the session issuing the statement. You can override execution plans by using a hint.
数据库用于执行 SQL 语句的步骤组合。 每个步骤要么从数据库物理检索数据行,要么为发出语句的会话准备它们。 您可以使用提示覆盖执行计划。 -
extended statistics
A type of optimizer statistics that improves estimates for cardinality when multiple predicates exist or when predicates contain an expression.
扩展统计
当存在多个谓词或谓词包含表达式时,一种优化器统计信息可改进对基数的估计。 -
cardinality
The number of rows that is expected to be or is returned by an operation in an execution plan.
执行计划中的操作预期或将返回的行数。 -
synopsis
A set of auxiliary statistics gathered on a partitioned table when the INCREMENTAL value is set to true.
当 INCREMENTAL 值设置为 true 时,在分区表上收集的一组辅助统计信息。 -
SQL compilation
In the context of Oracle SQL processing, this term refers collectively to the phases of parsing, optimization, and plan generation.
在 Oracle SQL 处理的上下文中,该术语统称为解析、优化和计划生成阶段。 -
SQL profile
A set of auxiliary information built during automatic tuning of a SQL statement. A SQL profile is to a SQL statement what statistics are to a table. The optimizer can use SQL profiles to improve cardinality and selectivity estimates, which in turn leads the optimizer to select better plans.
SQL 配置文件
在自动调优 SQL 语句期间构建的一组辅助信息。 SQL 配置文件之于 SQL 语句就像统计信息之于表一样。 优化器可以使用 SQL 配置文件来改进基数和选择性估计,从而引导优化器选择更好的计划。 -
automatic reoptimization
The ability of the optimizer to automatically change a plan on subsequent executions of a SQL statement. Automatic reoptimization can fix any suboptimal plan chosen due to incorrect optimizer estimates, from a suboptimal distribution method to an incorrect choice of degree of parallelism.
优化器在 SQL 语句的后续执行中自动更改计划的能力。 自动重新优化可以修复由于不正确的优化器估计而选择的任何次优计划,从次优分布方法到错误选择并行度。
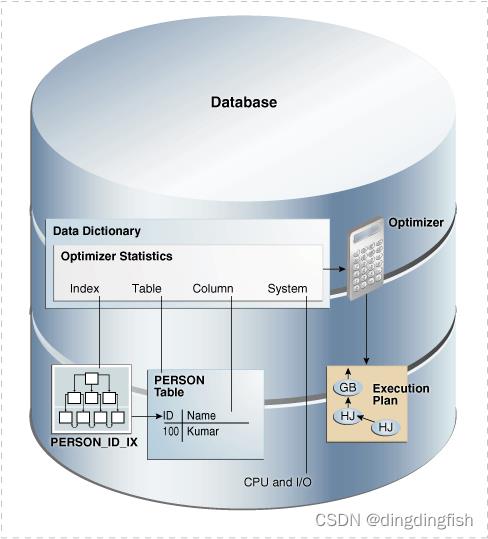
Oracle 数据库优化器统计信息描述了有关数据库及其对象的详细信息。
10.1 Introduction to Optimizer Statistics
优化器成本模型依赖于收集的有关查询中涉及的对象以及查询运行所在的数据库和主机的统计信息。
优化器使用统计信息来估计从表、分区或索引中检索到的行数(和字节数)。 优化器估计访问成本,确定可能计划的成本,然后选择成本最低的执行计划。
优化器统计信息包括以下内容:
- 表统计
- 行数
- 块数
- 平均行长
- 列统计
- 列中不同值 (NDV) 的数量
- 列中的空值数
- 数据分布(直方图)
- 扩展统计
- 索引统计
- 叶块数
- 层数
- 索引聚类因子
- 系统统计
- I/O 性能和利用率
- CPU 性能和利用率
如图 10-1 所示,数据库将表、列、索引和系统的优化器统计信息存储在数据字典中。 您可以使用数据字典视图访问这些统计信息。
注意:优化器统计信息与通过 V$ 视图可见的性能统计信息不同。
10.2 About Optimizer Statistics Types
优化器收集关于不同类型的数据库对象和数据库环境特征的统计信息。
10.2.1 Table Statistics
表统计信息包含优化器在研制执行计划时使用的元数据。
10.2.1.1 Permanent Table Statistics
在 Oracle 数据库中,表统计信息包括有关行和块的信息。
优化器使用这些统计信息来确定表扫描和表连接的成本。 数据库跟踪有关永久表的所有相关统计信息。 例如,存储在 DBA_TAB_STATISTICS 中的表统计信息跟踪以下内容:
- 行数
数据库在确定基数时使用存储在 DBA_TAB_STATISTICS 中的行计数。 - 平均行长
- 数据块数
优化器使用带有 DB_FILE_MULTIBLOCK_READ_COUNT 初始化参数的数据块数来确定基表访问成本。 - 空数据块数
DBMS_STATS.GATHER_TABLE_STATS 在收集永久表的统计信息之前提交。
此示例查询 sh.customers 表的表统计信息。
SELECT NUM_ROWS, AVG_ROW_LEN, BLOCKS,
EMPTY_BLOCKS, LAST_ANALYZED
FROM DBA_TAB_STATISTICS
WHERE OWNER='SH'
AND TABLE_NAME='CUSTOMERS';
NUM_ROWS AVG_ROW_LEN BLOCKS EMPTY_BLOCKS LAST_ANAL
---------- ----------- ---------- ------------ ---------
55500 189 1551 0 28-MAY-22
10.2.1.2 Temporary Table Statistics
DBMS_STATS 可以收集永久和全局临时表的统计信息,但对后者有其他注意事项。
10.2.1.2.1 Types of Temporary Tables
临时表分为全局、私有或游标持续时间。
在所有类型的临时表中,数据只对插入它的会话可见。这些表的区别如下:
-
全局临时表是显式创建的持久对象,用于存储特定持续时间的中间会话私有数据。
该表是全局的,因为该定义对所有会话可见。 CREATE GLOBAL TEMPORARY TABLE 的 ON COMMIT 子句指示该表是特定于事务的 (DELETE ROWS) 还是特定于会话的 (PRESERVE ROWS)。全局临时表的优化器统计信息可以是共享的或特定于会话的。 -
私有临时表是一个显式创建的对象,由私有内存元数据定义,在特定持续时间内存储中间会话私有数据。
该表是私有的,因为该定义仅对创建该表的会话可见。 CREATE PRIVATE TEMPORARY TABLE 的 ON COMMIT 子句指示该表是特定于事务的 (DROP DEFINITION) 还是特定于会话的 (PRESERVE DEFINITION)。 -
游标持续时间临时表是与游标关联的隐式创建的仅内存对象。
与全局和私有临时表不同,DBMS_STATS 不能收集游标持续时间临时表的统计信息。
这些表的不同之处在于它们存储数据的位置、创建和删除它们的方式以及元数据的持续时间和可见性。请注意,数据库在会话首次将数据插入全局临时表时分配存储空间,而不是在创建表时。
下表为临时表的重要特征:
| 特征 | Global Temporary Table | Private Temporary Table | Cursor-Duration Temporary Table |
|---|---|---|---|
| 数据的可见性 | 会话插入数据 | 会话插入数据 | 会话插入数据 |
| 数据存储 | 持久 | 内存或临时文件,但仅在会话或事务期间 | 仅在内存中 |
| 元数据的可见性 | 所有会话 | 创建表的会话(在基于 V$ 视图的 USER_PRIVATE_TEMP_TABLES 视图中) | 执行游标的会话 |
| 元数据的持续时间 | 直到表被显式删除 | 直到表被显式删除,或会话结束 (PRESERVE DEFINITION) 或事务结束 (DROP DEFINITION) | 直到游标清除出共享池 |
| 创建表 | CREATE GLOBAL TEMPORARY TABLE (支持 AS SELECT) | CREATE PRIVATE TEMPORARY TABLE (支持 AS SELECT) | 当优化器认为它有用时隐式创建 |
| 创建对现有事务的影响 | 无隐式提交 | 无隐式提交 | 无隐式提交 |
| 命名规则 | 与永久表相同 | 必须以 ORA$PTT_ 开头 | 内部生成的唯一名称 |
| 删除表 | DROP GLOBAL TEMPORARY TABLE | DROP PRIVATE TEMPORARY TABLE,或在会话 (PRESERVE DEFINITION)和事务(DROP DEFINITION)结束时隐式删除 | 在会话结束时隐式删除 |
10.2.1.2.2 Statistics for Global Temporary Tables
DBMS_STATS 为全局临时表收集和永久表相同类型的统计信息。
注意:您不能收集私有临时表的统计信息。
下表显示了全局临时表在收集和存储优化器统计信息方面的不同之处,具体取决于表的范围是事务还是会话。
| 特征 | 特定于事务 | 特定于会话 |
|---|---|---|
| DBMS_STATS 收集的影响 | 不提交 | 提交 |
| 统计信息存储 | 仅内存 | 字典表 |
| 直方图创建 | 不支持 | 支持 |
以下过程不会提交特定于事务的临时表,因此不会删除这些表中的行:
- GATHER_TABLE_STATS
- DELETE_obj_STATS,其中 obj 是 TABLE、COLUMN 或 INDEX
- SET_obj_STATS,其中 obj 是 TABLE、COLUMN 或 INDEX
- GET_obj_STATS,其中 obj 是 TABLE、COLUMN 或 INDEX
前面的程序单元遵守 GLOBAL_TEMP_TABLE_STATS 统计首选项(这是个初始化参数,默认为空)。 例如,如果表首选项设置为 SESSION,则 SET_TABLE_STATS 设置会话统计信息,而 GATHER_TABLE_STATS 保留特定于事务的临时表中的所有行。 但是,如果表首选项设置为 SHARED,则 SET_TABLE_STATS 会设置共享统计信息,而 GATHER_TABLE_STATS 会从特定于事务的临时表中删除所有行。
10.2.1.2.3 Shared and Session-Specific Statistics for Global Temporary Tables
从 Oracle Database 12c 开始,您可以设置表级首选项 GLOBAL_TEMP_TABLE_STATS 以对全局临时表共享 (SHARED) 或会话特定 (SESSION) 进行统计。
当 GLOBAL_TEMP_TABLE_STATS 为 SESSION 时,您可以在一个会话中收集全局临时表的优化器统计信息,然后仅使用该会话的统计信息。 同时,用户可以继续维护一个共享版本的统计数据。 在优化期间,优化器首先检查全局临时表是否具有特定于会话的统计信息。 如果是,则优化器使用它们。 否则,优化器将使用共享统计信息(如果存在)。
注意:在 Oracle Database 12c 之前的版本中,数据库维护全局临时表和非全局临时表的优化器统计信息的方式相同。 数据库维护所有会话共享的统计数据的一个版本,即使不同会话中的数据可能不同。
特定于会话的优化器统计信息具有以下特征:
- 跟踪统计信息的字典视图显示当前会话中的共享统计信息和特定于会话的统计信息。
- CREATE … AS SELECT 自动收集优化器统计信息。 但是,当 GLOBAL_TEMP_TABLE_STATS 设置为 SHARED 时,您必须使用 DBMS_STATS 手动收集统计信息。
这些视图是 DBA_TAB_STATISTICS、DBA_IND_STATISTICS、DBA_TAB_HISTOGRAMS 和 DBA_TAB_COL_STATISTICS(每个视图都有对应的 USER_ 和 ALL_ 版本)。 SCOPE 列显示统计信息是特定于会话的还是共享的。 会话特定的统计信息必须存储在数据字典中,以便多个进程可以在 Oracle RAC 中访问它们。 - 不支持待处理的统计信息。
- 其他会话不共享使用特定于会话的统计信息的游标。
不同的会话可以共享一个使用共享统计信息的游标,就像在 Oracle Database 12c 之前的版本中一样。 同一个会话可以共享一个使用会话特定统计信息的游标。 - 默认情况下,临时表的 GATHER_TABLE_STATS 立即使在同一会话中编译的先前游标无效。 但是,此过程不会使在其他会话中编译的游标无效。
10.2.2 Column Statistics
列统计信息跟踪有关列值和数据分布的信息。
优化器使用列统计信息来生成准确的基数估计,并就索引使用、连接顺序、连接方法等做出更好的决策。 例如,DBA_TAB_COL_STATISTICS 中的统计信息跟踪以下内容:
- 不同值的数量
- 空值数
- 最大最小值
- 直方图相关信息
优化器可以使用扩展统计信息,这是一种特殊类型的列统计信息。 这些统计信息对于通知优化器列之间的逻辑关系很有用。
10.2.3 Index Statistics
索引统计信息包括索引级别数、索引块数以及索引与数据块之间的关系等信息。 优化器使用这些统计信息来确定索引扫描的成本。
10.2.3.1 Types of Index Statistics
DBA_IND_STATISTICS 视图跟踪索引统计信息。
统计数据包括以下内容:
- 层级
BLEVEL 列显示从根块到叶块所需的块数。 B-tree 索引有两种类型的块:用于搜索的分支块和存储值的叶块。 - 不同的键
此列跟踪不同索引值的数量。 如果定义了唯一约束,并且没有定义 NOT NULL 约束,则该值等于非空值的数量。 - 每个不同索引键的平均叶块数
- 每个不同索引键指向的平均数据块数
已知CUSTOMERS表由1664个block。
SELECT INDEX_NAME, BLEVEL, LEAF_BLOCKS AS "LEAFBLK", DISTINCT_KEYS AS "DIST_KEY",
AVG_LEAF_BLOCKS_PER_KEY AS "LEAFBLK_PER_KEY",
AVG_DATA_BLOCKS_PER_KEY AS "DATABLK_PER_KEY"
FROM DBA_IND_STATISTICS
WHERE OWNER = 'SH'
AND INDEX_NAME IN ('CUST_LNAME_IX','CUSTOMERS_PK');
INDEX_NAME BLEVEL LEAFBLK DIST_KEY LEAFBLK_PER_KEY DATABLK_PER_KEY
-------------- ------ ------- -------- --------------- ---------------
CUSTOMERS_PK 1 115 55500 1 1
CUST_LNAME_IX 1 141 908 1 10
10.2.3.2 Index Clustering Factor
对于 B 树索引,索引聚簇因子测量与索引值(例如姓氏)相关的行的物理聚集度。
索引聚集因子帮助优化器决定对于某些查询,索引扫描还是全表扫描更有效。 低聚集因子表示索引扫描更有效。
接近表中块数的聚类因子表明行在表块中按索引键物理排序。 如果数据库执行全表扫描,则数据库倾向于检索这些行,因为它们存储在按索引键排序的磁盘上。 接近行数的聚类因子表示行相对于索引键随机分散在数据库块中。 如果数据库执行全表扫描,那么数据库将不会按此索引键以任何排序顺序检索行。
聚集因子是特定索引的属性,而不是表。 如果一个表上存在多个索引,则不同索引的聚集因子可能不同。 尝试重新组织表以提高一个索引的聚集因子可能会降低另一个索引的聚集因子。
此示例显示优化器如何使用索引聚集因子来确定使用索引是否比全表扫描更有效。
SELECT table_name, num_rows, blocks
FROM user_tables
WHERE table_name='CUSTOMERS';
TABLE_NAME NUM_ROWS BLOCKS
------------------------------ ---------- ----------
CUSTOMERS 55500 1551
-- 在customers.cust_last_name 列上创建索引
CREATE INDEX CUSTOMERS_LAST_NAME_IDX ON customers(cust_last_name);
-- 查询新建索引的索引聚簇因子。
SELECT index_name, blevel, leaf_blocks, clustering_factor
FROM user_indexes
WHERE table_name='CUSTOMERS'
AND index_name= 'CUSTOMERS_LAST_NAME_IDX';
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
------------------------------ ---------- ----------- -----------------
CUSTOMERS_LAST_NAME_IDX 1 141 9936
-- 创建customers 表的新副本,其中的行按cust_last_name 排序。
CREATE TABLE customers3 AS
SELECT *
FROM customers
ORDER BY cust_last_name;
-- 收集有关 customers3 表的统计信息。
EXEC DBMS_STATS.GATHER_TABLE_STATS(null,'CUSTOMERS3');
-- 查询customers3 表中的行数和块数。
SELECT TABLE_NAME, NUM_ROWS, BLOCKS
FROM USER_TABLES
WHERE TABLE_NAME='CUSTOMERS3';
TABLE_NAME NUM_ROWS BLOCKS
------------------------------ ---------- ----------
CUSTOMERS3 55500 1550
-- 在customers3 的cust_last_name 列上创建索引。
CREATE INDEX CUSTOMERS3_LAST_NAME_IDX ON customers3(cust_last_name);
-- 查询customers3_last_name_idx 索引的索引聚簇因子。
SELECT INDEX_NAME, BLEVEL, LEAF_BLOCKS, CLUSTERING_FACTOR
FROM USER_INDEXES
WHERE TABLE_NAME = 'CUSTOMERS3'
AND INDEX_NAME = 'CUSTOMERS3_LAST_NAME_IDX';
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
------------------------------ ---------- ----------- -----------------
CUSTOMERS3_LAST_NAME_IDX 1 141 1516
-- 查询customers表,显示执行计划,走全表扫描
SELECT cust_first_name, cust_last_name
FROM customers
WHERE cust_last_name BETWEEN 'Puleo' AND 'Quinn';
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR());
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 423 (100)| |
|* 1 | TABLE ACCESS FULL| CUSTOMERS | 2335 | 35025 | 423 (1)| 00:00:01 |
-------------------------------------------------------------------------------
-- 查询customers3表,显示执行计划,走索引
SELECT cust_first_name, cust_last_name
FROM customers3
WHERE cust_last_name BETWEEN 'Puleo' AND 'Quinn';
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR());
----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 71 (100)| |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| CUSTOMERS3 | 2335 | 35025 | 71 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | CUSTOMERS3_LAST_NAME_IDX | 2335 | | 7 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------------------
-- 使用强制优化器使用索引的提示查询客户。成本高出很多。
SELECT /*+ index (Customers CUSTOMERS_LAST_NAME_IDX) */ cust_first_name,
cust_last_name
FROM customers
WHERE cust_last_name BETWEEN 'Puleo' and 'Quinn';
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR());
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 425 (100)| |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| CUSTOMERS | 2335 | 35025 | 425 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | CUSTOMERS_LAST_NAME_IDX | 2335 | | 7 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------------
-- 清理
DROP TABLE customers3 PURGE;
DROP INDEX CUSTOMERS_LAST_NAME_IDX;
上面的计划表明,对客户使用索引的成本高于全表扫描的成本。 因此,使用索引不一定会提高性能。 索引聚集因子是衡量索引扫描是否比全表扫描更有效的指标。
10.2.3.3 Effect of Index Clustering Factor on Cost: Example
此示例说明了索引聚集因素如何影响表访问成本。
考虑以下场景:
- 一个表包含 9 行,存储在 3 个数据块中。
- col1 列当前存储值 A、B 和 C。
- 此表的 col1 上存在名为 col1_idx 的非唯一索引。
假设这些行存储在数据块中,如下所示:
Block 1 Block 2 Block 3
------- ------- -------
A A A B B B C C C
在此示例中,col1_idx 的索引聚集因子较低。 col1 具有相同索引列值的行位于表中的相同数据块中。 因此,使用索引范围扫描返回所有值为 A 的行的成本很低,因为只需读取表中的一个块。
假设相同的行分散在数据块中,如下所示:
Block 1 Block 2 Block 3
------- ------- -------
A B C A C B B A C
在此示例中,col1_idx 的索引聚集因子较高。 数据库必须读取表中的所有三个块以检索 col1 中值为 A 的所有行。
10.2.4 System Statistics
系统统计信息描述了硬件特性,例如 I/O 和 CPU 性能和利用率。
系统统计信息使查询优化器在选择执行计划时能够更准确地估计 I/O 和 CPU 成本。 更新系统统计信息时,数据库不会使之前解析的 SQL 语句失效。 数据库使用新的统计信息解析所有新的 SQL 语句。
10.2.5 User-Defined Optimizer Statistics
可扩展优化器使用户定义函数和索引的作者能够创建统计数据收集、选择性和成本函数。
优化器成本模型被扩展为集成用户提供的信息以评估 CPU 和 I/O 成本。 统计类型充当影响执行计划选择的用户定义函数的接口。 但是,要使用统计类型,优化器需要一种机制来将该类型绑定到数据库对象,例如列、独立函数、对象类型、索引、索引类型或包。 SQL 语句 ASSOCIATE STATISTICS 允许发生这种绑定。
用于用户定义统计的函数与使用标准 SQL 数据类型和对象类型的列以及域索引相关。 当您将统计类型与列或域索引相关联时,只要 DBMS_STATS 收集统计信息,数据库就会调用统计信息类型中的统计信息收集方法。
10.3 How the Database Gathers Optimizer Statistics
Oracle 数据库提供了几种收集统计信息的机制。
10.3.1 DBMS_STATS Package
DBMS_STATS PL/SQL 包收集和管理优化器统计信息。
该软件包使您能够控制收集统计信息的内容和方式,包括并行度、采样方法和分区表中统计信息收集的粒度。
注意:不要使用 ANALYZE 语句的 COMPUTE 和 ESTIMATE 子句来收集优化器统计信息。 这些条款已被弃用。 相反,请使用 DBMS_STATS。
创建准确的执行计划需要使用 DBMS_STATS 包收集的统计信息。 例如,DBMS_STATS 收集的表统计信息包括行数、块数和平均行长度。
默认情况下,Oracle 数据库使用自动优化器统计信息收集。在这种情况下,数据库会为所有统计信息丢失或过时的模式对象自动运行 DBMS_STATS 收集优化器统计信息。该过程消除了许多与管理优化器相关的手动任务,并显著降低了由于缺少或过时的统计信息而生成次优执行计划的风险。您还可以通过手动执行 DBMS_STATS 来更新和管理优化器统计信息。
Oracle Database 19c 引入了高频自动优化器统计信息收集。这个轻量级任务会定期收集陈旧对象的统计信息。默认间隔为 15 分钟。与自动统计信息收集作业相比,高频任务不执行诸如清除不存在对象的统计信息或调用 Optimizer Statistics Advisor 之类的操作。您可以使用 DBMS_STATS.SET_GLOBAL_PREFS 过程为高频任务设置首选项,并使用 DBA_AUTO_STAT_EXECUTIONS 查看元数据。
10.3.2 Supplemental Dynamic Statistics
默认情况下,当优化器统计信息丢失、过时或不足时,数据库会在解析期间自动收集动态统计信息。 数据库使用递归 SQL 来扫描一个小的随机表块样本。
注意:动态统计补充而非替代统计信息。
动态统计信息补充优化器统计信息,例如表和索引块计数、表和连接基数(估计的行数)、连接列统计信息和 GROUP BY 统计信息。 此信息通过更好地估计谓词基数来帮助优化器改进计划。
动态统计在以下情况下很有用:
- 由于复杂的谓词,执行计划不是最理想的。
- 采样时间是查询总执行时间的一小部分。
- 查询执行多次,以便摊销采样时间。
10.3.3 Online Statistics Gathering
在某些情况下,DDL 和 DML 操作会自动触发在线统计数据收集。
10.3.3.1 Online Statistics Gathering for Bulk Loads
数据库可以在以下类型的批量加载期间自动收集表统计信息:INSERT INTO … SELECT 使用直接路径插入和 CREATE TABLE AS SELECT。
默认情况下,并行插入使用直接路径插入。 您可以使用 /*+APPEND*/ 提示强制插入直接路径。
10.3.3.1.1 Purpose of Online Statistics Gathering for Bulk Loads
数据仓库应用程序通常将大量数据加载到数据库中。 例如,销售数据仓库可能每天、每周或每月加载数据。
在 Oracle Database 12c 之前的版本中,最佳做法是在批量加载后手动收集统计信息。 但是,由于疏忽或等待维护窗口启动收集,许多应用程序在加载后没有收集统计信息。 缺少统计数据是次优执行计划的主要原因。
在批量加载期间自动收集统计信息具有以下好处:
- 提高性能
在加载期间收集统计信息可以避免额外的表扫描来收集表统计信息。 - 改进的可管理性
批量加载后无需用户干预即可收集统计信息。
10.3.3.1.2 Global Statistics During Inserts into Partitioned Tables
将行插入分区表时,数据库会在插入期间收集全局统计信息。
例如,如果 sales 是一个分区表,并且如果您运行 INSERT INTO sales SELECT,那么数据库会收集全局统计信息。 但是,数据库不收集分区级别的统计信息。
假设您使用分区扩展语法将行插入特定分区或子分区的不同情况。 数据库在插入期间收集有关分区的统计信息。 但是,数据库不收集全局统计信息。
假设您运行 INSERT INTO sales PARTITION (sales_q4_2000) SELECT。 数据库在插入期间收集统计信息。 如果为 sales 启用了 INCREMENTAL 首选项,那么数据库还会收集 sales_q4_2000 的概要。 插入后统计信息立即可用。 但是,如果您回滚事务,那么数据库会自动删除在批量加载期间收集的统计信息。
10.3.3.1.3 Histogram Creation After Bulk Loads
收集在线统计数据后,数据库不会自动创建直方图。
如果需要直方图,那么在批量加载之后,Oracle 建议使用 options=>GATHER AUTO 运行 DBMS_STATS.GATHER_TABLE_STATS。
EXEC DBMS_STATS.GATHER_TABLE_STATS(user, 'MYT', options=>'GATHER AUTO');
前面的 PL/SQL 程序只收集丢失或过时的统计信息。 数据库不收集在批量加载期间收集的表和基本列统计信息。
注意:您可以在计划批量加载的表上将表首选项设置为 GATHER AUTO。 这样,您在运行 GATHER_TABLE_STATS 时无需显式设置 options 参数。
10.3.3.1.4 Restrictions for Online Statistics Gathering for Bulk Loads
在某些情况下,批量加载不会自动收集优化器统计信息。
具体来说,当以下任何条件适用于目标表、分区或子分区时,批量加载不会自动收集统计信息:
- 该对象包含数据。 批量加载仅在对象为空时自动收集在线统计信息。
- 它位于 Oracle 拥有的模式中,例如 SYS。
- 它是以下类型的表之一:嵌套表、索引组织表 (IOT)、外部表或定义为 ON COMMIT DELETE ROWS 的全局临时表。
注意:数据库会自动为混合分区表的内部分区收集在线统计信息。 - 它的 PUBLISH 首选项设置为 FALSE。
- 它的统计数据被锁定。
- 它是使用多表 INSERT 语句加载的。
10.3.3.1.5 User Interface for Online Statistics Gathering for Bulk Loads
默认情况下,数据库在批量加载期间收集统计信息。
您可以使用 GATHER_OPTIMIZER_STATISTICS 提示在语句级别启用该功能。 您可以使用 NO_GATHER_OPTIMIZER_STATISTICS 提示在语句级别禁用该功能。 例如,以下语句禁用批量加载的在线统计信息收集:
CREATE TABLE employees2 AS
SELECT /*+NO_GATHER_OPTIMIZER_STATISTICS*/ * FROM employees
10.3.3.2 Online Statistics Gathering for Partition Maintenance Operations
Oracle 数据库在特定分区维护操作期间为在线统计提供了类似的支持。
对于 MOVE、COALESCE 和 MERGE,数据库维护全局和分区级别的统计信息,如下所示:
- 如果分区使用增量或非增量统计信息,那么数据库会直接更新全局表统计信息中的 BLOCKS 值。请注意,此更新不是统计信息收集操作。
- 数据库为生成的分区生成新的统计信息。如果启用了增量统计,那么数据库会维护分区概要。
对于 TRUNCATE 或 DROP PARTITION,数据库会更新全局表统计信息中的 BLOCKS 和 NUM_ROWS 值。此更新不需要收集统计信息操作。使用增量或非增量统计信息时会发生统计信息更新。
注意:数据库不维护具有多个目标段的维护操作的分区级统计信息。
10.3.3.3 Real-Time Statistics
Oracle 数据库可以在常规 DML 操作期间自动收集实时统计信息。
10.3.3.3.1 Purpose of Real-Time Statistics
在线统计,无论是批量加载还是传统 DML,旨在减少优化器被陈旧统计信息误导的可能性。
Oracle Database 12c 为 CREATE TABLE AS SELECT 语句和直接路径插入引入了在线统计信息收集。 Oracle Database 19c 引入了实时统计信息,将在线支持扩展到传统的 DML 语句。 由于 DBMS_STATS 作业之间的统计信息可能会过时,因此实时统计信息有助于优化器生成更优化的计划。
批量加载操作收集所有必要的统计数据,而实时统计数据增加而不是取代传统统计数据。 因此,您必须继续使用 DBMS_STATS 定期收集统计信息,最好使用 AutoTask 作业。
10.3.3.3.2 How Real-Time Statistics Work
Oracle 数据库在 DML 操作期间动态计算最重要的统计信息的值。
考虑一个事务当前正在向 oe.orders 表添加数万行的场景。 实时统计记录重要的统计变化,例如最大列值。 这使优化器能够获得更准确的成本估算。
当实时统计值更改时,现有游标不会标记为无效。
10.3.3.3.2.1 Regression Models for Real-Time Statistics
从 21c 版开始,Oracle 数据库自动构建回归模型来预测可变表统计信息的不同值 (NDV) 的数量。 模型的使用使优化器能够以低成本产生准确的 NDV 估计值。
注意:建立回归模型所需的时间可能会有所不同。 该过程的第一步是对列的 NDV 如何随时间变化进行建模。 这依赖于从统计历史中派生的有关 NDV 更改的信息。 如果立即可用的信息不充分,则模型的构建将保持等待状态,直到收集到足够的历史信息。
使用 DBMS_STATS 删除、导出和导入回归模型
回归模型由数据库根据需要自动构建,不需要 DBA 干预。 但是,您可以使用 DBMS_STATS 删除、导入或导出回归模型。 默认 stat_category 包括默认参数值 MODELS 以及先前支持的值 OBJECT_STATS、SYNOPSES 和 REALTIME_STATS。 这些是相关的 API:
DBMS_STATS.DELETE_*_STATS
DBMS_STATS_EXPORT_*_STATS
DBMS_STATS.IMPORT_*_STATS
用于检查实时统计模型的字典视图
从 Oracle Database 21c 开始,这些新的字典视图可用于检查保存的实时统计模型。
- ALL_TAB_COL_STAT_MODELS
- DBA_TAB_COL_STAT_MODELS
- USER_TAB_COL_STAT_MODELS
10.3.3.3.3 User Interface for Real-Time Statistics
您可以通过 PL/SQL 包、数据字典视图和提示使用管理和访问实时统计信息。
OPTIMIZER_REAL_TIME_STATISTICS 初始化参数
当 OPTIMIZER_REAL_TIME_STATISTICS 初始化参数设置为 TRUE 时,Oracle 数据库会在常规 DML 操作期间自动收集实时统计信息。 默认设置为 FALSE,表示禁用实时统计。
默认情况下,DBMS_STATS 子程序包括实时统计信息。 您还可以指定参数以仅包含这些统计信息。
| 子程序 | 描述 |
|---|---|
| EXPORT_TABLE_STATS 和 EXPORT_SCHEMA_STATS | 这些子程序使您能够导出统计数据。 默认情况下,stat_category 参数包括实时统计信息。 REALTIME_STATS 值仅指定实时统计信息。 |
| IMPORT_TABLE_STATS 和 IMPORT_SCHEMA_STATS | 这些子程序使您能够导入统计数据。 默认情况下,stat_category 参数包括实时统计信息。 REALTIME_STATS 值仅指定实时统计信息。 |
| DELETE_TABLE_STATS 和 DELETE_SCHEMA_STATS | 这些子程序使您能够删除统计数据。 默认情况下,stat_category 参数包括实时统计信息。 REALTIME_STATS 值仅指定实时统计信息。 |
| DIFF_TABLE_STATS_IN_STATTAB | 此函数比较来自两个来源的表统计信息。 统计数据始终包括实时统计数据。 |
| DIFF_TABLE_STATS_IN_HISTORY | 此函数比较表截至两个指定时间戳的统计信息。 统计数据始终包括实时统计数据。 |
当 NOTES 列为 STATS_ON_CONVENTIONAL_DML 时,可以在数据字典表统计视图(如 USER_TAB_STATISTICS 和 USER_TAB_COL_STATISTICS)中查看实时统计信息,如下表所述。
DBA_* 视图有 ALL_* 和 USER_* 版本。
| 视图 | 描述 |
|---|---|
| DBA_TAB_COL_STATISTICS | 此视图显示从 DBA_TAB_COLUMNS 中提取的列统计信息和直方图信息。 实时统计信息由 NOTES 列中的 STATS_ON_CONVENTIONAL_DML 指示。 |
| DBA_TAB_STATISTICS | 此视图显示当前用户可访问的表的优化器统计信息。 实时统计信息由 NOTES 列中的 STATS_ON_CONVENTIONAL_DML 指示。 |
NO_GATHER_OPTIMIZER_STATISTICS 提示阻止收集实时统计信息。
10.3.3.3.4 Real-Time Statistics: Example
在此示例中,传统的 INSERT 语句触发实时统计信息的收集。
在此实验前,请先备份SH schema中的sales表,以便后续恢复。
create table sales_orig as select * from sales;
这是Exadata独有特性:
alter system set "_exadata_feature_on"=true scope=spfile;
shutdown immediate;
startup;
同时设置以下参数:
alter session set OPTIMIZER_REAL_TIME_STATISTICS=TRUE;
此示例假定 sh 用户已被授予 DBA 角色,并且您已以 sh 身份登录到数据库。 您执行以下步骤:
- 收集销售表的统计信息:
exec DBMS_STATS.GATHER_TABLE_STATS('SH', 'SALES');
- 查询销售表的列级统计信息
SET PAGESIZE 5000
SET LINESIZE 200
COL COLUMN_NAME FORMAT a13
COL LOW_VALUE FORMAT a14
COL HIGH_VALUE FORMAT a14
COL NOTES FORMAT a5
COL PARTITION_NAME FORMAT a13
-- Notes 字段为空,表示尚未收集实时统计信息
SELECT COLUMN_NAME, LOW_VALUE, HIGH_VALUE, SAMPLE_SIZE, NOTES
FROM USER_TAB_COL_STATISTICS
WHERE TABLE_NAME = 'SALES'
ORDER BY 1, 5;
COLUMN_NAME LOW_VALUE HIGH_VALUE SAMPLE_SIZE NOTES
------------- -------------- -------------- ----------- -----
AMOUNT_SOLD C10729 C2125349 918843
CHANNEL_ID C103 C10A 918843
CUST_ID C103 C30B0B 918843
PROD_ID C10E C20231 918843
PROMO_ID C122 C20A64 918843
QUANTITY_SOLD C102 C102 918843
TIME_ID 77C60101010101 78650C1F010101 918843
- 查询销售表的表级统计信息
SELECT NVL(PARTITION_NAME, 'GLOBAL') PARTITION_NAME, NUM_ROWS, BLOCKS, NOTES
FROM USER_TAB_STATISTICS
WHERE TABLE_NAME = 'SALES'
ORDER BY 1, 4;
-- Notes 字段为空,表示尚未收集实时统计信息
PARTITION_NAM NUM_ROWS BLOCKS NOTES
------------- ---------- ---------- -----
GLOBAL 918843 1874
SALES_1995 0 0
SALES_1996 0 0
SALES_H1_1997 0 0
SALES_H2_1997 0 0
SALES_Q1_1998 43687 97
SALES_Q1_1999 64186 126
SALES_Q1_2000 62197 125
SALES_Q1_2001 60608 124
SALES_Q1_2002 0 0
SALES_Q1_2003 0 0
SALES_Q2_1998 35758 86
SALES_Q2_1999 54233 110
SALES_Q2_2000 55515 114
SALES_Q2_2001 63292 124
SALES_Q2_2002 0 0
SALES_Q2_2003 0 0
SALES_Q3_1998 50515 103
SALES_Q3_1999 67138 128
SALES_Q3_2000 58950 118
SALES_Q3_2001 65769 130
SALES_Q3_2002 0 0
SALES_Q3_2003 0 0
SALES_Q4_1998 48874 116
SALES_Q4_1999 62388 121
SALES_Q4_2000 55984 112
SALES_Q4_2001 69749 140
SALES_Q4_2002 0 0
SALES_Q4_2003 0 0
29 rows selected.
- 使用传统的 INSERT 语句将 918,843 行加载到 sales 中
INSERT INTO sales(prod_id, cust_id, time_id, channel_id, promo_id,
quantity_sold, amount_sold)
SELECT prod_id, cust_id