算法小抄10-二叉树的遍历方式
Posted 兴趣使然的CV工程师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法小抄10-二叉树的遍历方式相关的知识,希望对你有一定的参考价值。
上节中我们学到了链表,这一节中学习一个新的数据结构二叉树,对于链表它拥有的属性时值val,和下一个链表节点指针next,而二叉树其实就比他多一个属性,它的形状看起来是下面这样的:
class TreeNode:
def __init__(self, val=0, left=None,right=None):
self.val = val
self.left = left
self.right = right
head=TreeNode(1,TreeNode(2),TreeNode(3))
print(head.val)#1
print(head.left.val)#2
print(head.right.val)#3这样的方式组成的二叉树如下图所示:
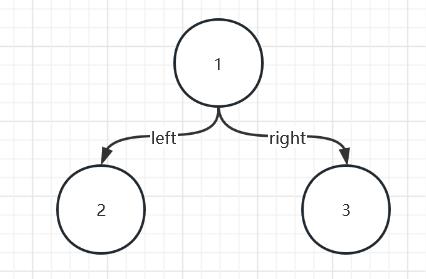
和之前一样,我们先介绍二叉树的遍历方式
二叉树的遍历
二叉树的有三种递归遍历方式和一种层序遍历方式,都是需要掌握的,我们使用如下图所示的二叉树来进行讲解:
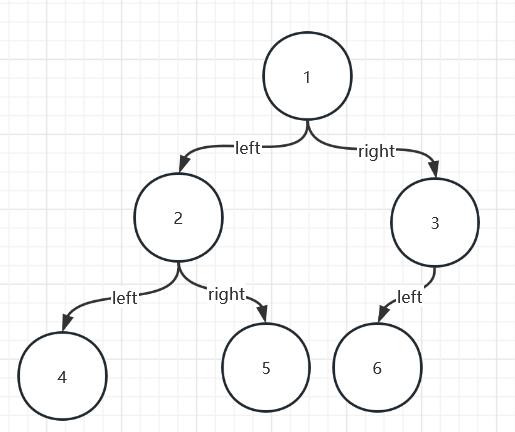
前序遍历
前序遍历的方式是<根,左,右>的遍历方式,因为先遍历根节点所以叫前序遍历,根据上述二叉树,从根节点1出发,那么整体二叉树会输出成什么样呢?这里我们先给出代码,根据代码来推一推吧:
class TreeNode:
def __init__(self, val=0, left=None,right=None):
self.val = val
self.left = left
self.right = right
@staticmethod
def pre_order(head):
if head is None:return
print(head.val)
TreeNode.pre_order(head.left)
TreeNode.pre_order(head.right)
head=TreeNode(1,TreeNode(2,TreeNode(4),TreeNode(5)),TreeNode(3,TreeNode(6),None))
TreeNode.pre_order(head)答案是1 2 4 5 3 6,有答对嘛,没有答对没有关系,因为这里牵扯到一个新的知识点递归,我们根据当前二叉树来分析一下代码如何运行:
如下图所示,那个长方形的东西叫做栈,函数是右边那个pre_order,函数只有进栈后才能正确的运行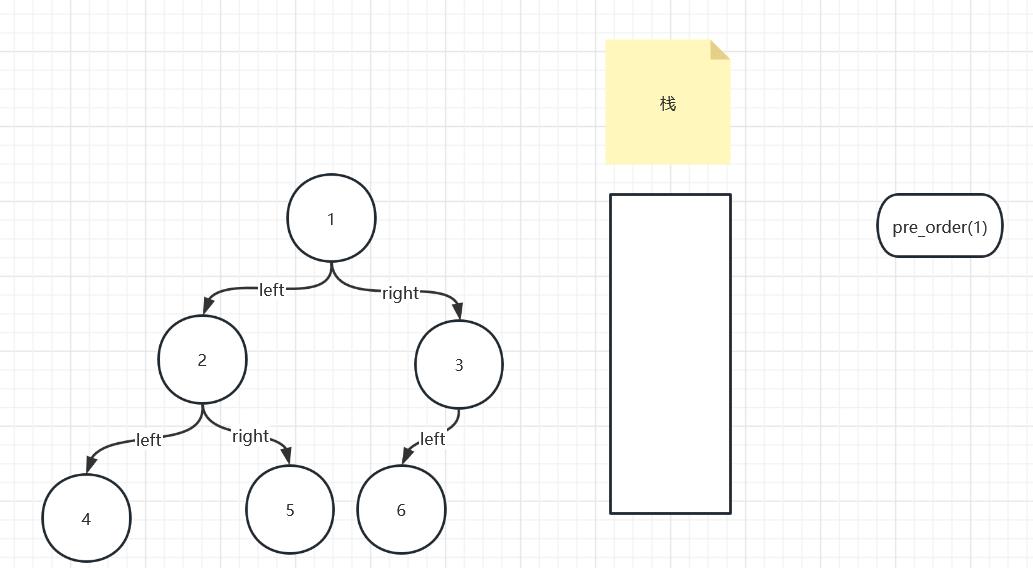
来看一下进栈的过程,进入栈后pre_order(1)开始运行,第一句不为空吧,继续往下运行,第二句打印1,第三句设计到了递归函数,需要创建一个新的函数pre_order(2),而且需要在pre_order(2)进栈运行完成之后再继续第四句话的运行
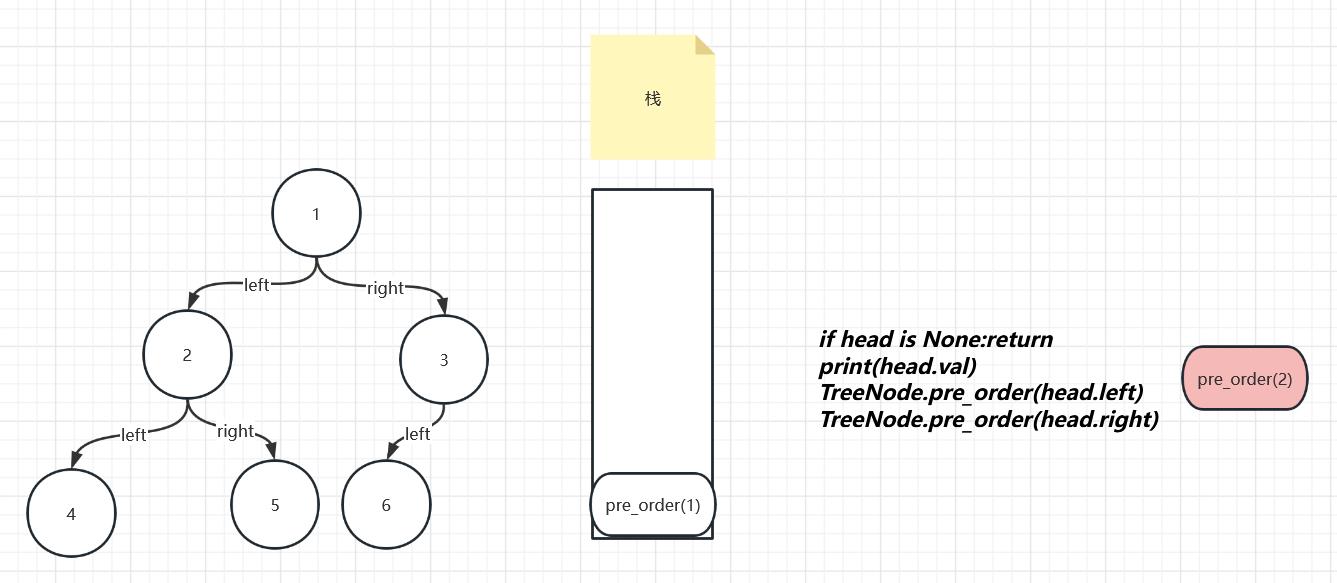
继续pre_order(2)进栈后,重复刚刚的过程在第三句的时候创建了pre_order(4)
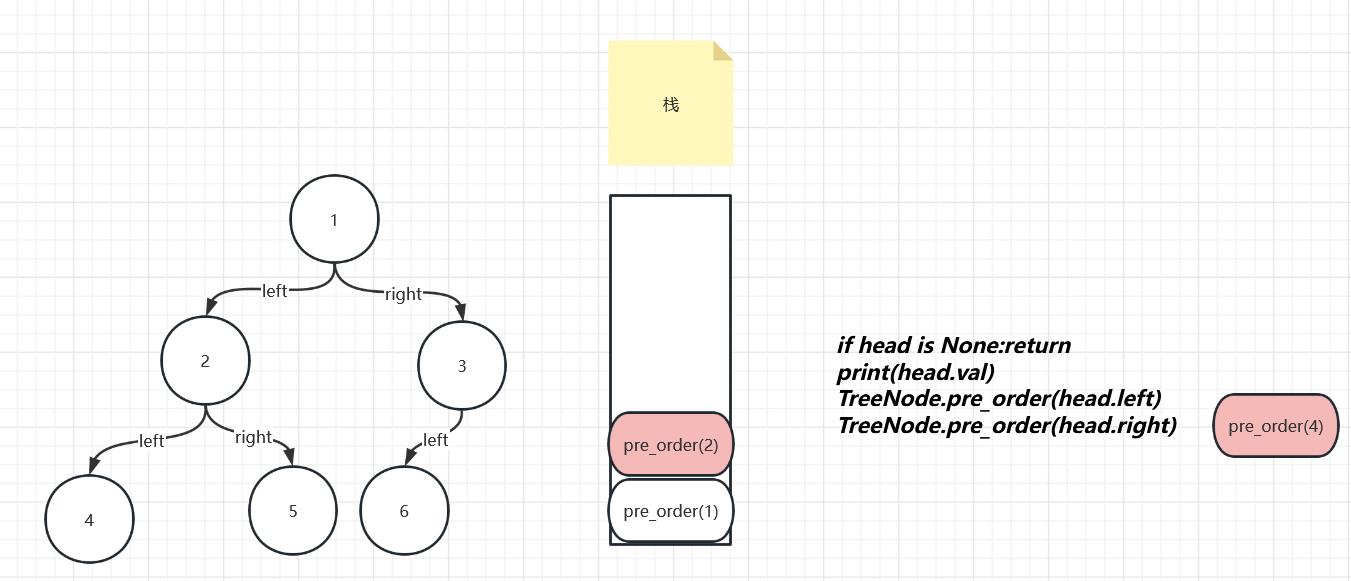
接着pre_order(4)进栈,重复以上过程创建了pre_order(None),因为对于4这个节点并没有左子节点嘛,对是不对
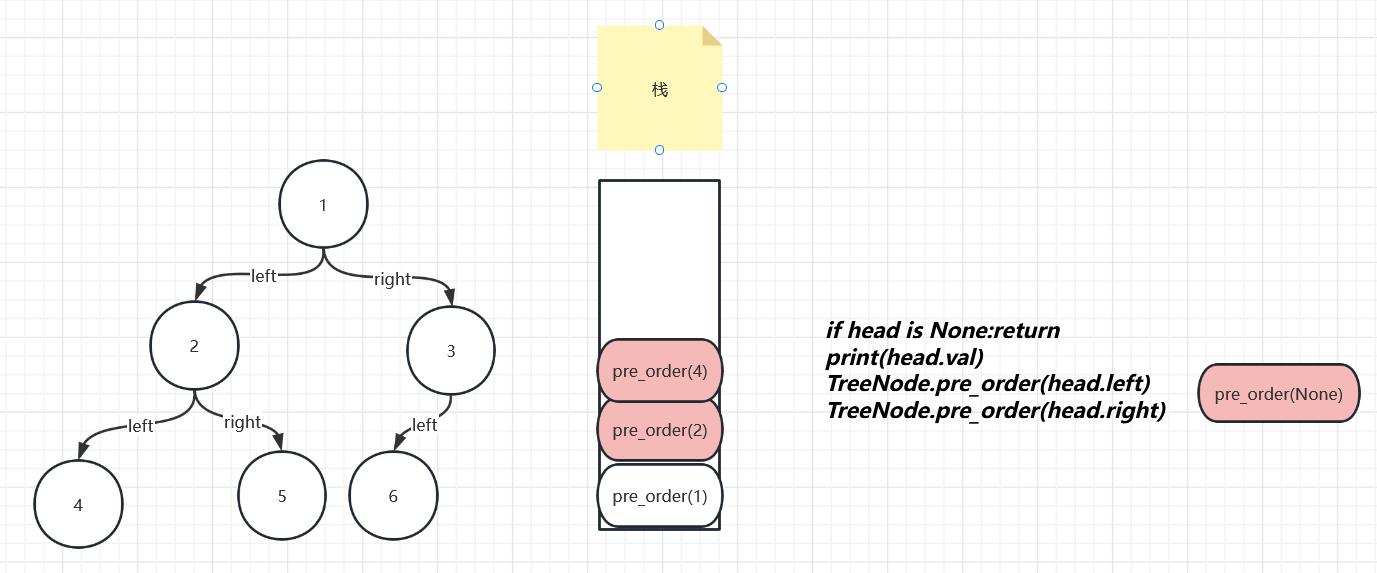
延续刚刚的过程,pre_order(None)进栈,开始执行代码,在第一句的时候整个代码就已经执行完了,执行完之后的函数会进行出栈操作
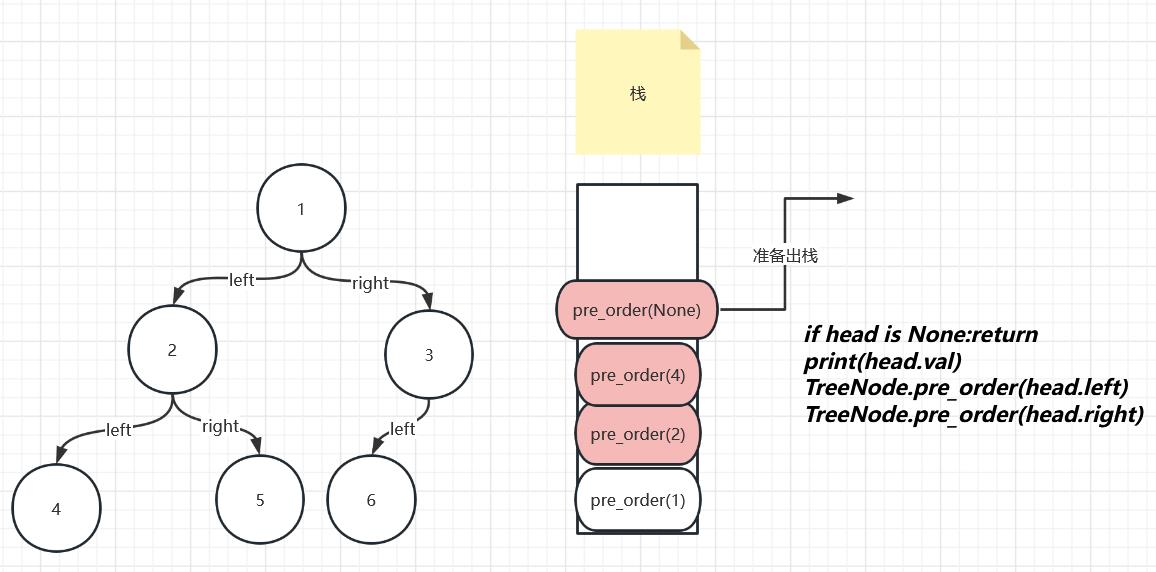
出栈后我们栈顶的函数为pre_order(4),还记得上次这个函数运行到哪行代码了吗?是第三句哦,所以现在会继续运行第四句代码,4这个节点是不是依然没有右节点,那么生成的函数还是pre_order(None),和上述过程完全一样,这里就不再赘述了,我们继续往下看
在又一个pre_order(None)出栈之后,pre_order(4)也全部执行结束了,所以pre_order(4)也该出栈
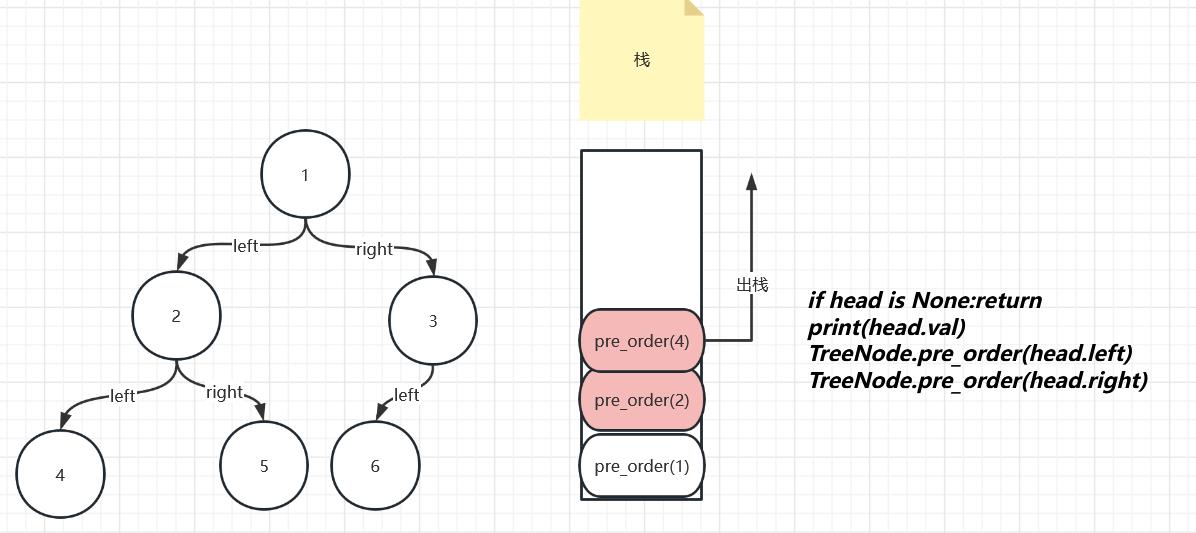
接着看,在pre_order(4)出栈后,栈顶的函数是pre_order(2),这个函数上次也是执行到第三句话,该接着执行第四局了,这里又创建了一个函数pre_order(5),因为2的右节点是5嘛
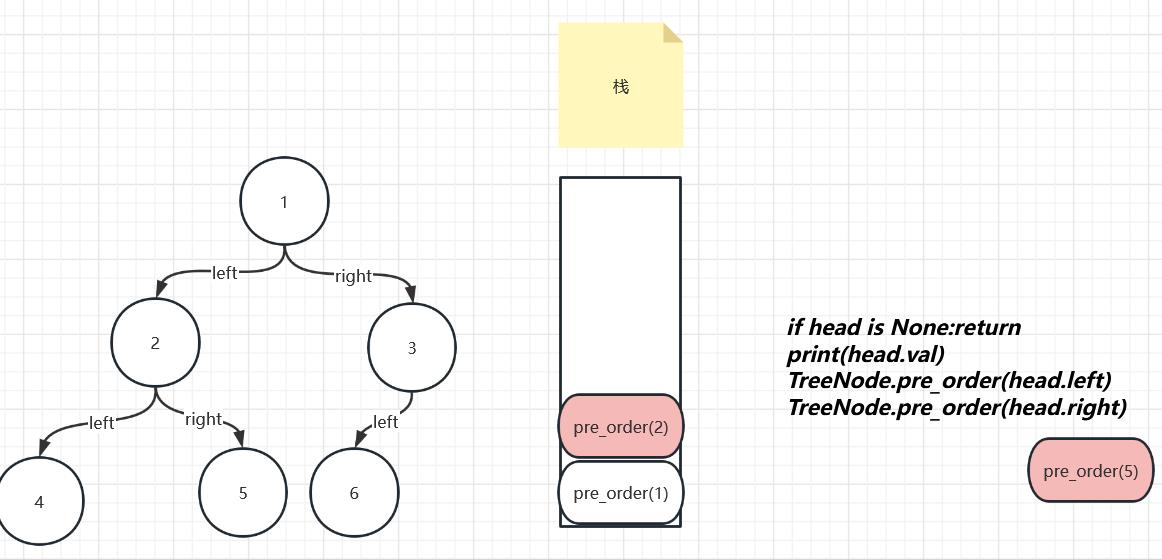
接着pre_order(5)入栈打印5,最后再开始打印节点1的右节点,分析的过程和我们上面是一样的哦,羊羊可以自己分析一下
最后的打印结果就是1,2,4,5,3,6了
中序遍历
理解了递归和前序遍历,中序遍历就显得十分简单了,它的代码如下,只是输出语句换了一个位置罢了:
class TreeNode:
def __init__(self, val=0, left=None,right=None):
self.val = val
self.left = left
self.right = right
@staticmethod
def in_order(head):
if head is None:return
TreeNode.in_order(head.left)
print(head.val)
TreeNode.in_order(head.right)
head=TreeNode(1,TreeNode(2,TreeNode(4),TreeNode(5)),TreeNode(3,TreeNode(6),None))
TreeNode.in_order(head)他的输出结果是:4 2 5 1 6 3,因为他的打印方式是《左,根,右》会最先输出左子树的节点
后序遍历
是不是已经可以自己写出后序遍历了,真的很简单呢
class TreeNode:
def __init__(self, val=0, left=None,right=None):
self.val = val
self.left = left
self.right = right
@staticmethod
def post_order(head):
if head is None:return
TreeNode.post_order(head.left)
TreeNode.post_order(head.right)
print(head.val)
head=TreeNode(1,TreeNode(2,TreeNode(4),TreeNode(5)),TreeNode(3,TreeNode(6),None))
TreeNode.post_order(head)他的输出结果是:4 5 2 6 3 1
随堂检测
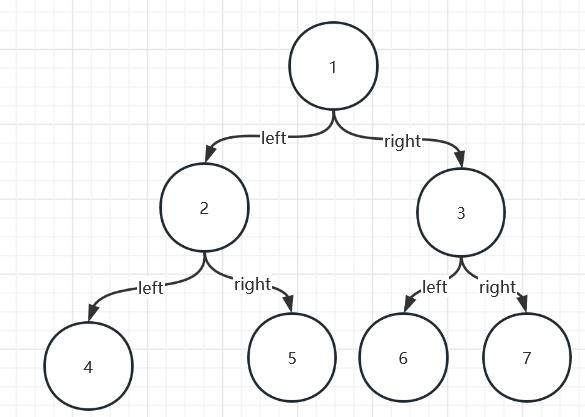
不借助代码能否写出如下这颗树的前序,中序和后续遍历呢,后续自己可以使用代码来测试一下哦:
层序遍历
是不是感觉前中后序遍历都没有什么规律可言,好像是给电脑看的,我作为一个人我就想遍历出来就是1,2,3,4,5,6,7,8这样的,这就要说到层序遍历了
其思路是这样的,我们先将头节点放入容器,然后在遍历到头节点的左节点和右节点的时候也将其加入容器,在一个节点的左节点和右节点都被遍历完以后将这个节点丢出容器,现在容器里是不是只剩下头节点的左右节点了,我们继续上述操作,按照先来先到的原则,对这两个节点执行上述操作,直到容器内什么都不剩下
思考一下要找到最先进入的节点我们该使用什么数据结构呢?栈的特点(先序遍历的时候讲过了,栈只有一个口子进出)是先进后出与我们的用法相悖,所以该使用的是队列(队列是一个先进先出的数据结构,像一根管子一样,add函数从管子的头进入,poll函数从管子的后面取出,python中的栈和队列都是用deque双端队列来实现的,这里要记得import哦)
import collections #别忘记导入容器工具
class TreeNode:
def __init__(self, val=0, left=None,right=None):
self.val = val
self.left = left
self.right = right
@staticmethod
def post_order(head):
if head is None:return
TreeNode.post_order(head.left)
TreeNode.post_order(head.right)
print(head.val)
@staticmethod
def levelOrder(root):
if root == None: return [] # 特判
que = collections.deque([root]) # 双端队列,初始化并且将root丢进队列
ans = []
while len(que) != 0:
size = len(que)
level = []
for _ in range(size): # 遍历当前层节点
cur = que.popleft() # 从左边弹出队列
level.append(cur.val) # 将当前节点值加入当前层的列表
if cur.left != None: que.append(cur.left)
if cur.right != None: que.append(cur.right)
ans.append(level) # 将当前层结果加入答案列表
return ans
@staticmethod
def printList(list):
for subList in list:
print(subList)
head=TreeNode(1,TreeNode(2,TreeNode(4),TreeNode(5)),TreeNode(3,TreeNode(6),None))
ans=TreeNode.levelOrder(head)
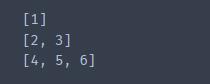
TreeNode.printList(ans)结果打印出来如下图所示:
Luna Tech | 二叉树的前序中序后序遍历
0. 前言
Reference: 手把手带你刷二叉树(第一期) - labuladong 的算法小抄 (gitbook.io)[1]
为什么要先刷二叉树?
因为很多经典的算法,包括回溯(Backtracking Algorithm)、动态规划(Dynamic Programming)、分治算法(Divide-and-conquer Algorithm)都是树的问题。
有人说五大常用算法是:动态规划算法,分治算法,回溯算法、贪心算法(Greedy Algorithm)以及分支限界算法(Branch and bound Algorithm)。
所有树的问题都跟树的递归遍历框架代码息息相关,二叉树相关的题目能帮助我们练好递归基本功和框架思维,而递归是学好算法的基本功,所以我们应该先刷二叉树的题目。
换言之,只要涉及递归,都可以抽象成二叉树的问题。
/* 二叉树遍历框架 */
void traverse(TreeNode root) {
// 前序遍历(在调用所有递归function之前)
traverse(root.left)
// 中序遍历(在调用了一个递归function之后)
traverse(root.right)
// 后序遍历(在调用了所有递归function之后)
}
两种遍历框架:
线性 - while/for 迭代 非线性 - recursive 递归
相关题目
226. 翻转二叉树 - 力扣(LeetCode) (leetcode-cn.com)
114. 二叉树展开为链表 - 力扣(LeetCode) (leetcode-cn.com)
116. 填充每个节点的下一个右侧节点指针 - 力扣(LeetCode) (leetcode-cn.com)
1. 二叉树递归遍历框架的重要性
快速排序(Quicksort)和归并排序(Mergesort)这两种算法可以理解为:
-
快速排序是二叉树的前序遍历; -
归并排序是二叉树的后序遍历;
为什么呢?
快速排序的代码框架
快速排序的逻辑:
-
对一个 number array nums[lo..hi]进行排序,先找到一个 p 元素作为分界点; -
交换元素,使得 nums[lo...p-1]小于等于nums[p],nums[p+1..hi]大于nums[p] -
递归思维,继续在 nums[lo...p-1]和nums[p+1..hi]里面分别找新的分界元素 p',然后继续进行元素交换
注意:nums[lo...p-1] 小于等于 nums[p] 这个条件可以保证和 nums[p] 相等的元素都放在左边的 array 里面。
void sort(int[] nums, int lo, int hi) {
/********************** 前序遍历位置 *********************/
/* 假定我们有个 partition function,通过交换元素构建分界点 p */
int p = partition(nums, lo, hi);
/*******************************************************/
sort(nums, lo, p - 1);
sort(nums, p + 1, hi);
}
先构造分界点,然后再把问题分解成左右子数组两个小问题,分别构造子分界点,持续递归遍历。
这就是二叉树前序遍历的应用。
归并排序的代码框架
归并排序的逻辑:
-
对 nums[lo..hi]进行排序,先找到中点,对nums[lo..mid]排序,再对nums[mid+1..hi]排序 -
最后把这两个有序的子数组合并,整个数组就排好序了
void sort(int[] nums, int lo, int hi) {
int mid = (lo + hi) / 2;
sort(nums, lo, mid);
sort(nums, mid + 1, hi);
/****** 后序遍历位置 ******/
/* 合并两个排好序的子数组 */
merge(nums, lo, mid, hi);
/************************/
}
先分成左右子数组,分别排序,然后合并起来,这就是分治算法。
根据 merge 的调用位置,我们可以发现这是二叉树后序遍历的应用。
2. 写递归算法的秘诀
写递归算法的关键是要明确函数的「定义」是什么,然后相信这个定义,利用这个定义推导最终结果,绝不要跳入递归的细节。
初学者学递归最容易犯的错误就是跳进递归里面出不来(我也是,经常把自己搞晕)。
但是我们换个思路,递归其实就是数学归纳法的应用,已知 k = 1 的时候如何,k = 2 的时候如何,k = n 的时候如何。
我们不需要再次去证明这个公式,只需要搞清楚函数的定义,并且使用这个函数就行了。
举例:计算二叉树一共有几个节点
这道题很简单,root + 左右子树的节点就是总节点数。
// 定义:count(root) 返回以 root 为根的树有多少节点
int count(TreeNode root) {
// base case
if (root == null) return 0;
// 自己加上子树的节点数就是整棵树的节点数
return 1 + count(root.left) + count(root.right);
}
那么如何计算左右子树的节点数呢?
和整棵树一样,root' + 左右子树' 的节点数。
这就是递归的思维了。
写树相关的算法/递归算法,简单说就是,先搞清楚当前 root 节点「该做什么」以及「什么时候做」,然后根据函数定义递归调用子节点,递归调用会让子节点做相同的事情。
-
该做什么 = 实现题目所要求的,比如这里就是计算总节点数
1 + count(root.left) + count(root.right) -
什么时候做 = 判断代码的位置,到底是前序、中序还是后序。
3. 题目实战
226. 翻转二叉树
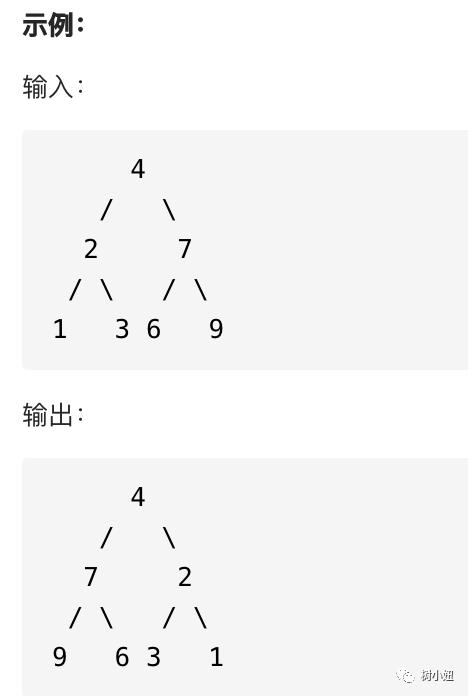
输入:二叉树节点 root
输出:镜像翻转的二叉树节点 root
思路:把每个节点的左右节点互换
代码
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode invertTree(TreeNode root) {
// 特殊 case
if (root == null)
return null;
// 前序遍历,左右互换
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
// 进入递归,左右子树重复操作
invertTree(root.left);
invertTree(root.right);
// 返回结果
return root;
}
}
其他解法
我们是否可以使用后序遍历来完成这个题目呢?
答案是:可以,前序和后序在这个题目里面不重要,只要两个 invertTree 放在一起就行了。
class Solution {
public TreeNode invertTree(TreeNode root) {
// 特殊 case
if (root == null)
return null;
// 进入递归,左右子树重复操作
invertTree(root.left);
invertTree(root.right);
// 后序遍历,左右互换
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
// 返回结果
return root;
}
}
我们是否可以用中序遍历来完成这个题目呢?
答案是:可以,但是得改动。
假如你按照之前的代码,只是换个位置的话,root.right 其实在进行第二次递归的时候已经变成了 root.left。
// not working
class Solution {
public TreeNode invertTree(TreeNode root) {
// 特殊 case
if (root == null)
return null;
// 进入递归,左子树重复操作
invertTree(root.left);
// 中序遍历,左右互换
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
// 进入递归,右子树重复操作
invertTree(root.right);
// 返回结果
return root;
}
}
所以呢,假如你要用中序遍历,得把 invertTree(root.right); 改成 invertTree(root.left);
class Solution {
public TreeNode invertTree(TreeNode root) {
// 特殊 case
if (root == null)
return null;
// 进入递归,左子树重复操作
invertTree(root.left);
// 中序遍历,左右互换
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
// 进入递归,右子树重复操作
invertTree(root.left); // 注意这里的 node 实际上是之前的 right
// 返回结果
return root;
}
}
116. 填充每个节点的下一个右侧节点指针

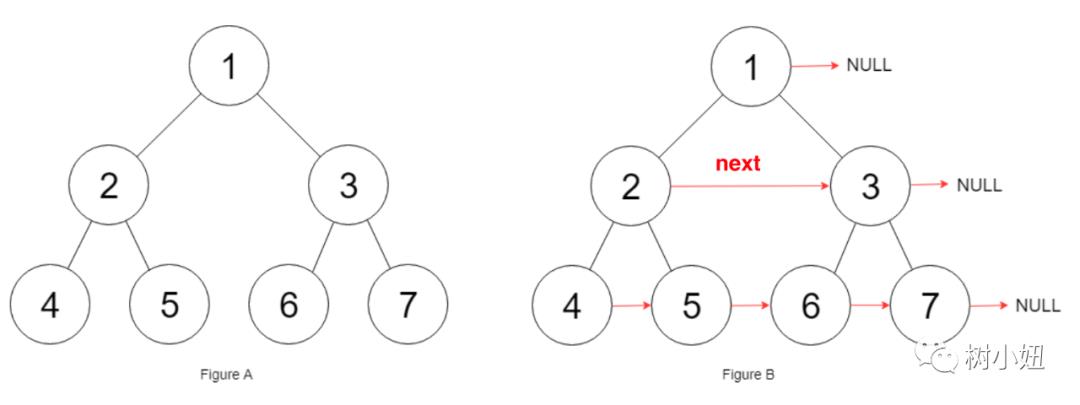
这道题目要求我们把每一层的左右节点联系起来。
root.left.next = root.right; 就是我们的核心逻辑;
那我们想到的第一个解法可能是这样的:
/*
// Definition for a Node.
class Node {
public int val;
public Node left;
public Node right;
public Node next;
public Node() {}
public Node(int _val) {
val = _val;
}
public Node(int _val, Node _left, Node _right, Node _next) {
val = _val;
left = _left;
right = _right;
next = _next;
}
};
*/
class Solution {
public Node connect(Node root) {
if (root == null || root.left == null) {
return root;
}
root.left.next = root.right;
connect(root.left);
connect(root.right);
return root;
}
}
但是这个解法有问题,什么问题呢?
我们没法把 5 和 6 连起来啊!因为它俩不属于一个子树。
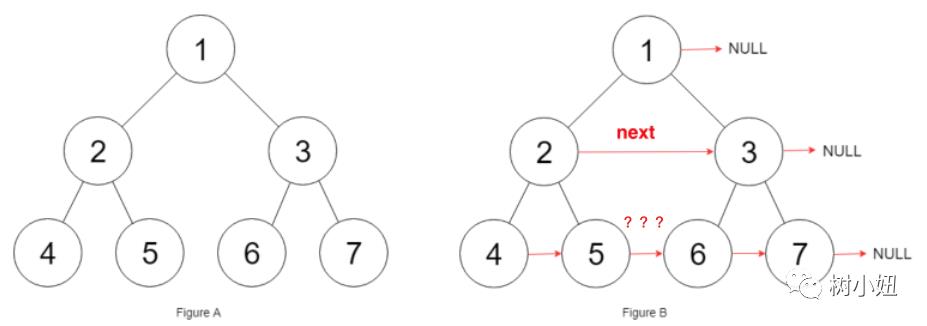
那怎么办呢?
我们要利用节点 2 和 3 之间的关系,已知 root.left.next = root.right;,那么 root.left.right.next = root.left.next.left; 就可以建立两个子树之间的关系了。
但是我们要怎么用递归的方式来抽象出这个逻辑呢?
我们可以通过写一个辅助 function,输入两个节点(左右子树 root),然后把这两个节点的子树 node 之间建立联系,也就是把「每一层二叉树节点连接起来」这个问题抽象成「将每两个相邻节点都连接起来」:
/*
// Definition for a Node.
class Node {
public int val;
public Node left;
public Node right;
public Node next;
public Node() {}
public Node(int _val) {
val = _val;
}
public Node(int _val, Node _left, Node _right, Node _next) {
val = _val;
left = _left;
right = _right;
next = _next;
}
};
*/
class Solution {
// 主函数
public Node connect(Node root) {
if (root == null) return null;
connectTwoNode(root.left, root.right);
return root;
}
// 辅助函数
void connectTwoNode(Node node1, Node node2) {
if (node1 == null || node2 == null) {
return;
}
/**** 前序遍历位置 ****/
// 将传入的两个节点连接
node1.next = node2;
// 连接相同父节点的两个子节点
connectTwoNode(node1.left, node1.right);
connectTwoNode(node2.left, node2.right);
// 连接跨越父节点的两个子节点
connectTwoNode(node1.right, node2.left);
}
}
这样,connectTwoNode 函数不断递归,把两个子树的内部节点联系起来的同时,也把两个子树之间的节点连起来,就可以解决问题了。
114. 二叉树展开为链表
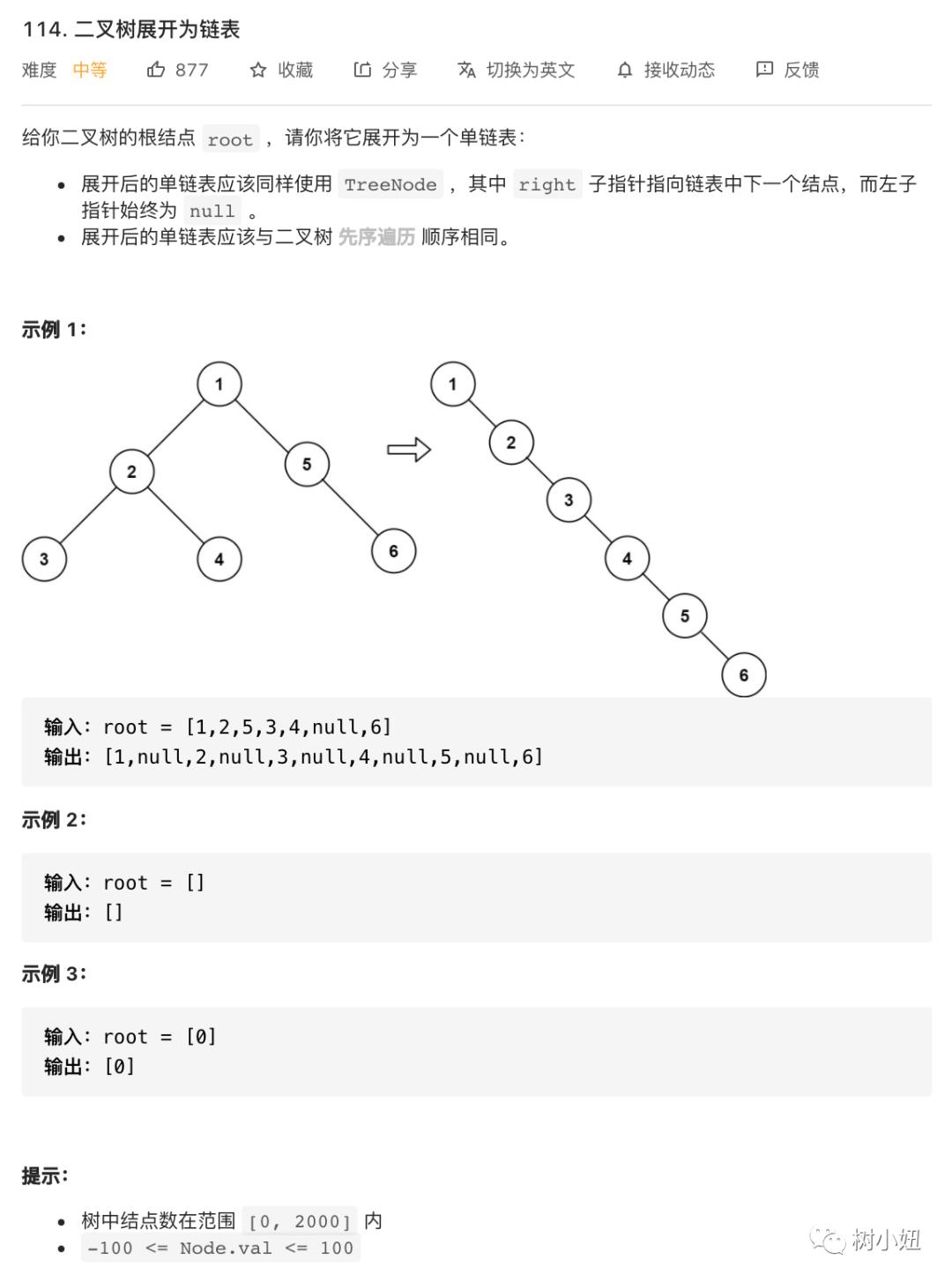
思路:从最小 case 开始考虑,当 root 只有一个左节点和一个右节点的时候,我们需要把左节点变成右节点,再把原右节点变成新右节点的右节点。
这段代码可以表示为:
TreeNode orgRight = root.right;
root.right = null;
root.right = root.left;
root.right.right = orgRight;
那么,假设 root.left 和 root.right 都是经过 flatten 之后的结果,我们只需要最后返回 root 即可。
PS: 题目给的 method 是 void type,所以我们不需要 return root,只需要 return 就可以了(有点绕)。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
// 定义:将以 root 为根的树拉平为链表
public void flatten(TreeNode root) {
// base case, 根据题目示例2来写
if (root == null) return;
// flatten both left and right trees
flatten(root.left);
flatten(root.right);
/**** 后序遍历位置 ****/
// 1、左右子树已经被拉平成一条链表
TreeNode left = root.left;
TreeNode right = root.right;
// 2、将左子树作为右子树
root.left = null;
root.right = left;
// 3、将原先的右子树接到当前右子树的末端
TreeNode p = root;
while (p.right != null) {
p = p.right;
}
p.right = right;
}
}
为什么要做后序遍历呢?
因为我们的假设是 root.left 和 root.right 都已经经过 flatten 了,所以我们只需要关注如何把最小 case 的节点进行 flatten 即可。
假如我们要做前序遍历的话,调用 flatten 递归的时候 root.left 和 root.right 需要指向最初的那两个 node。
class Solution {
public void flatten(TreeNode root) {
// base case
if (root == null) return;
/**** 前序遍历 ****/
// 1、储存最初的左右节点
TreeNode left = root.left;
TreeNode right = root.right;
// 2、进行第一步 flatten 操作(左子树)
root.left = null;
root.right = left;
// 3、进行第二步 flatten 操作(右子树)
TreeNode p = root;
while (p.right != null) {
p = p.right;
}
p.right = right;
// 调用递归(使用未经改变的两个节点)
flatten(left);
flatten(right);
}
}
References
Reference: 手把手带你刷二叉树(第一期) - labuladong 的算法小抄 (gitbook.io): https://labuladong.gitbook.io/algo/mu-lu-ye-1/mu-lu-ye-1/er-cha-shu-xi-lie-1
[2]226. 翻转二叉树: https://leetcode-cn.com/problems/invert-binary-tree/
[3]116. 填充每个节点的下一个右侧节点指针: https://leetcode-cn.com/problems/populating-next-right-pointers-in-each-node/
[4]114. 二叉树展开为链表: https://leetcode-cn.com/problems/flatten-binary-tree-to-linked-list/
以上是关于算法小抄10-二叉树的遍历方式的主要内容,如果未能解决你的问题,请参考以下文章