交换机——交换架构
Posted monologuezjp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了交换机——交换架构相关的知识,希望对你有一定的参考价值。
交换机的交换架构是框式交换机才有的概念,它最主要的作用是任意输入端可以交换为任意输出端。交换架构的最基本组成为:输入端口、输出端口和连接输入输出端口的交换网络。
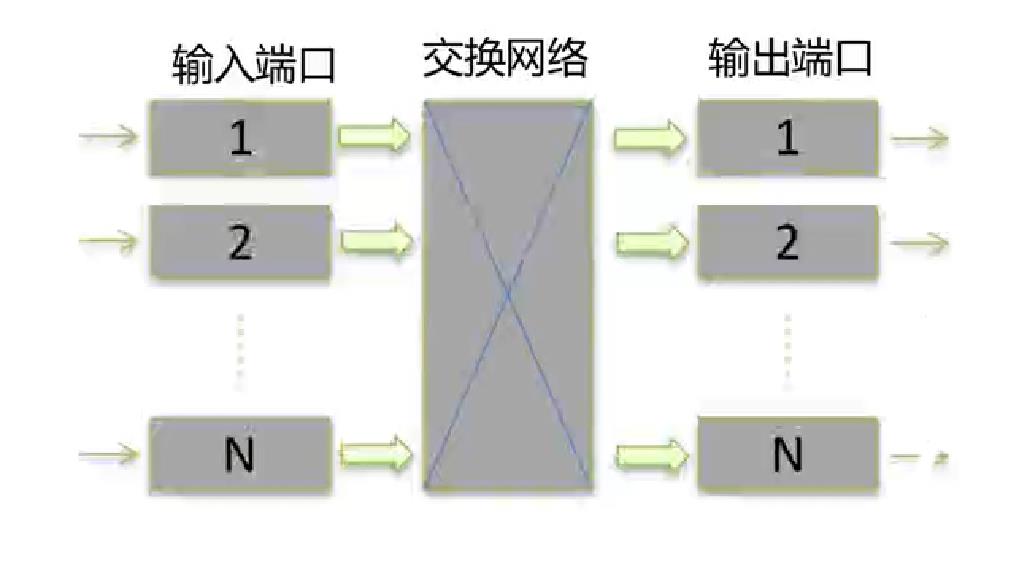
业界主要的三种交换架构如下图所示:
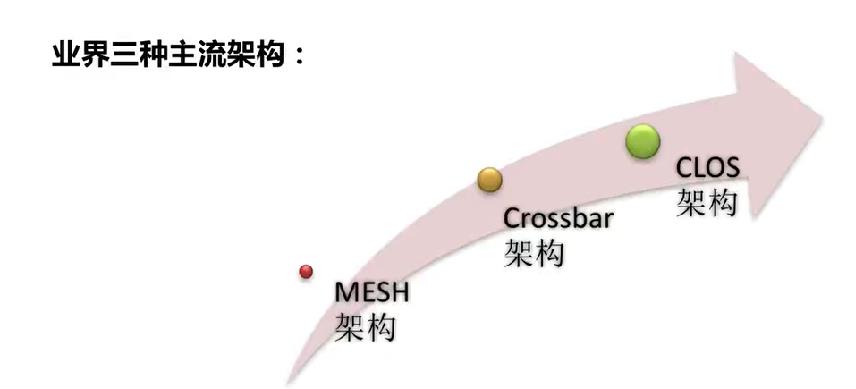
为什么会出现架构的变化?交换架构本质的出现就是为了解决多个端口之间转发效率的问题。随着数据量的增大,客户对交换机接口数量的要求增多,框式交换机灵活的端口扩展,这些情况导致在硬件上,传统的架构很难部署,在转发效率上,也容易出现转发瓶颈。
一、MESH架构
MESH架构又叫全连接架构。实际上就是将交换机的每一个端口(线卡),都通过背板走线的方式连接在一起, 每两个端口之间都有一条线直接连接,所有的数据都是直接从输入端转发到输出端。
线卡和线卡之间通过背板直接相连。每两两线卡之间都通过背板走线相连。典型为两级交换架构,即 LC<--->LC。
架构图如下图所示:
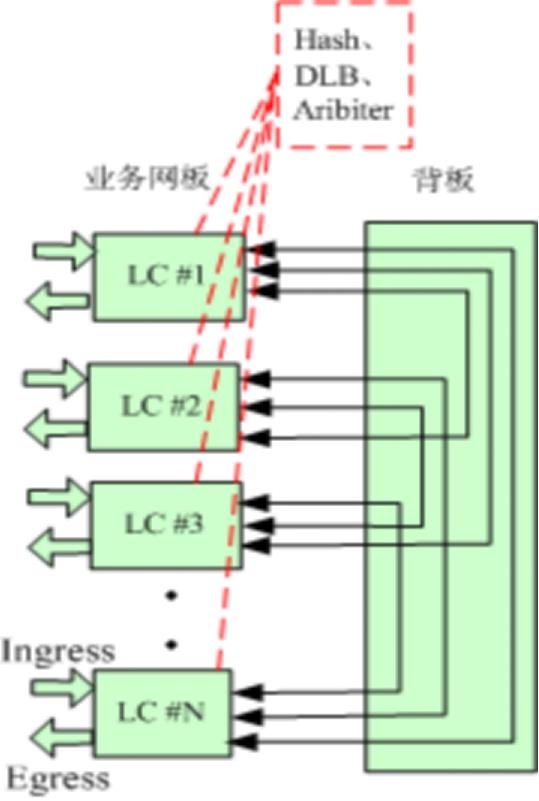
数据报文转发流程:
1、报文从线卡1进入,跨卡报文送到与目的线卡连接的背板通路;
2、线卡1发送到背板的报文通过Hash等算法实现流量的均衡;
3、报文到达目的线卡发出。
整个架构优势如下:
- 专用高速通道,数据可以无阻塞交换
- 转发时延小,线卡之间直接转发数据
- 绿色节能,没有交换芯片,降低整个机身的功耗
架构缺点:
- 对背板走线要求高
- 由于需要全端口互联,所以仅适合底槽位的设备,原因如下:
1、全互联,扩展性差
2、槽位数越多,需要连的线越多
3、槽位越多,需要的走线越长,走线越长信号越差,影响通讯的质量
- 转发速率受限于背板带宽,
- 因为没有转发芯片,所以转发效率不是很高。
业界典范:
思科N7004
华为S7703/S9303/S9703
锐捷N18007、S8605E、S8607E、S7505C
二、Crossbar架构
Crossbar介绍
为了解决MESH架构无法灵活扩展,转发效率不高等问题,设计除了Crossbar架构。在该架构中,将交换业务交给交换网板或者集成了交换芯片的引擎来完成。
线卡之间需要经过交换网板才能转发出去。
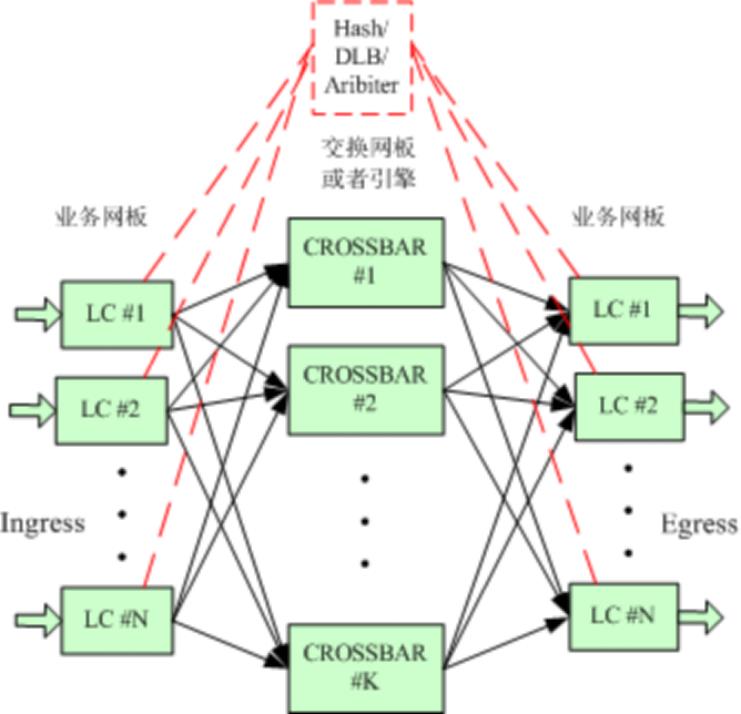
Crossbar架构特征:
包含一到多个并行工作的Crossbar芯片,业务线卡通过背板走线连接到Crossbar芯片上,Crossbar芯片集成在主控引擎上。业务调度和均衡通常采用集中仲裁或者Hash方式
多级交换,典型为三级:LC<--crossbar-->LC。
Crossbar交换芯片架构:
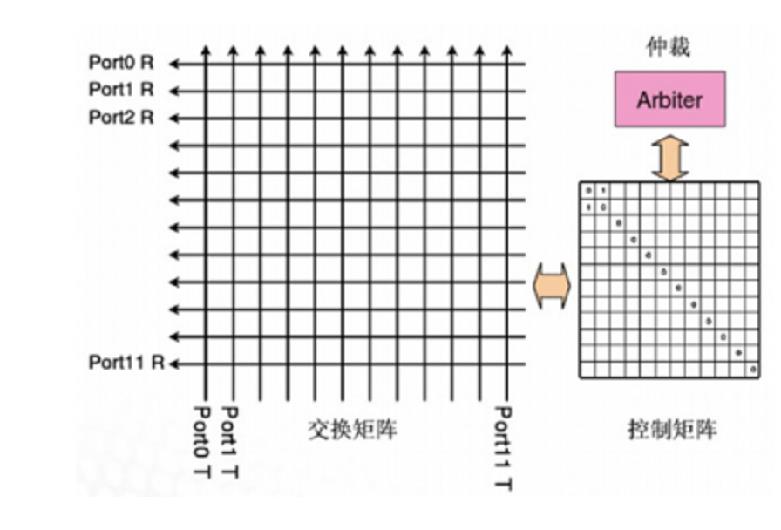
如图所示,每一条输入链路和输出链路都有一个CrossPoint,在CrossPoint处有一个半导体开关连接输入线路和输出线路,当来自某个端口的输入线路需要交换到另一个端口的输出点时,在CPU或交换矩阵的控制下,将交叉点的开关连接,数据就被发到另一个接口。
简单地说,Crossbar 架构是一种三级架构,它是一个开关矩阵,每一个CrossPoint都是一个开关,交换机通过控制开关来完成输入到特定输出的转发。如果交换具有N个输入和N个输出,那么该Crossbar Switch就是一个带有N*(N-1)≈N²个CrossPoint点的矩阵,可见,随着端口数量的增加,交叉点开关的数量呈几何级数增长。对于Crossbar芯片的电路集成水平、矩阵控制开关的制造难度、制造成本都会呈几何级数增长。所以,采用一块Crossbar交换背板的交换机,所能连接的端口数量也是有限的。
优点:
CrossBar内部无阻塞(相对的)。一个CrossBar,只要同时闭合多个交叉节点(crosspoint),多个不同的端口就可以同时传输数据。从这个意义上,我们认为所有的CrossBar在内部是无阻塞的,因为它可以支持所有端口同时线速交换数据
劣势:
线卡间虽有多路径,但无法实现严格的负载均衡和无阻塞。且受限于Crossbar芯片,在满插槽位的情况下,也可能无法支持无阻塞。引擎和交换芯片集成在一起,一旦引擎挂了,就不能转发数据了。
Crossbar在实现上又具体分为两种架构,一种是无缓存的Crossbar架构,一种是有缓存的Crossbar架构,主要区别就是在每个Crosspoint处是否有缓存,当然随着技术的发展,有缓存的Crossbar架构也逐渐在输入端加了缓存。
无缓存的Crossbar架构
所谓的无缓存的Crossbar架构,就是每个交叉点没有缓存,业务调度采用集中调度的方式,对输入输出进行统一调度,报文转发流程如下:
1. 报文从线卡进入,线卡先向仲裁器请求发送;
2. 仲裁器根据输出端口队列拥塞情况,决定是否允许线卡发送报文到输出端口;
每个输入口会定期去检查自己链路是否拥塞,反馈给仲裁器。
业务调度通常采用集中仲裁器,连到所有的输入输出FA芯片和Crossbar芯片;出口FA定时或实时地向仲裁器报告出口拥塞情况
3. 报文通过Crossbar转发到目的线卡输出端口。
但由于是集中调度,所以仲裁器的调度算法复杂度很高,扩展性较差,系统容量大时仲裁器容易形成瓶颈,难以做到精确调度。
缓存式Crossbar架构
最早的缓存式Crossbar只有交叉节点带缓存,而输入端是无缓存的,被称为”bus matrix”,后来,CICQ(联合输入交叉点排队 )的概念被引入,即在输入端用大的Input Buffer,在中间节点用小的CrossPoint Buffer。这种结构采用分布式调度的方式进行业务调度,即输入和输出端都有各自的调度器,报文转发流程如下:
1. 报文从线卡进入,输入端口通过特定的调度算法(如RR算法)独立地选择有效的VOQ(虚拟输出队列);
2. 将VOQ队列头部分组发送到相应的交叉点缓存;
3. 输出端口通过特定的算法在非空的交叉点缓存中选择进行服务。
由于输入和输出的调度策略相互独立,所以很难保证交换系统在每个时隙整体上达到最佳匹配状态,并且调度算法复杂度和交换系统规模有关,限制了其扩展性。
基于CICQ的Crossbar同时满足了较大容量交换和较好的业务调度的需求,是一种比较完善的交换架构,交换容量可以从几百G到几T,通常支持10G接口但无法支持40G和100G接口。由于交换容量不是很大,交换网通常集成在主控板上,采用1+1主备或负荷分担工作方式。
这种交换网版集成在主控板上的方式,好处是减少了槽位的占用,但是缺点比较多,比如:一旦主控板挂了,交换芯片也就挂了,无法继续进行转发;芯片在管理板上,与线卡互联,因为线的速率是有限的,且不能扩展交换网版,所以交换性能是有限的。
至于为什么Crossbar架构无法支持40G以上接口的流量呢?个人觉得有以下几个原因:
- 初步觉的不支持40G以上的接口是受交换容量的限制。交换芯片毕竟是集成在引擎上的,每块芯片的容量有上线,最多只能有两块交换芯片的前提下,交换容量的上限无法满足40G端口的需求。
- 查阅资料说crossbar的数据转发静态IP转发,也就是说同一条IP的数据会走同一条路径,可能出现源自同一IP的大流量数据,被转发到同一条路径中,造成阻塞,而此时其他路径却是空闲的。比如当使用40G以上端口进行视频业务转发时,路径压力会变大,导致造成阻塞。
- 由于是通过仲裁器集中调度,所以系统流量大时,调度算法的设计会很复杂,不好设计。
业界典范:
思科N7K系列(7004除外)
华为S7700/S9300/S9700系列(3槽\\10槽除外)
H3C S75E、S10506/S10510、S7506E-X/S7510E-X【不配独立FE情况下就是Crossbar架构】
锐捷 S12000、S8600、S7808C
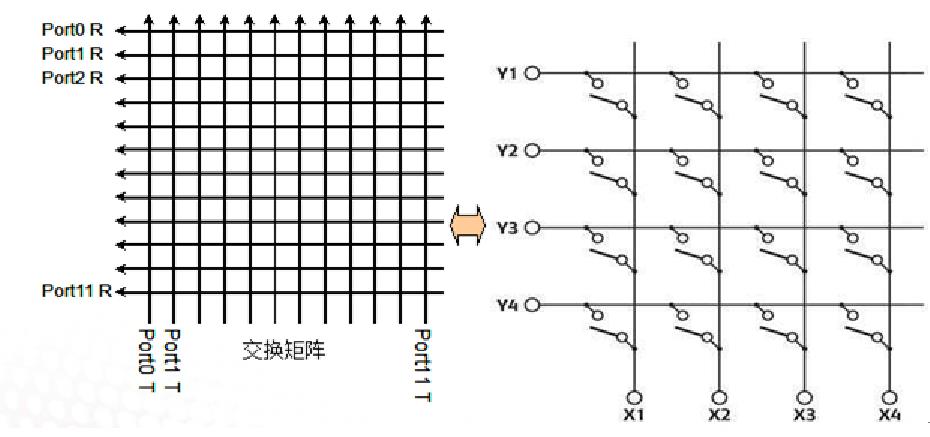
MESH与Crossbar架构区别:
三、CLOS架构
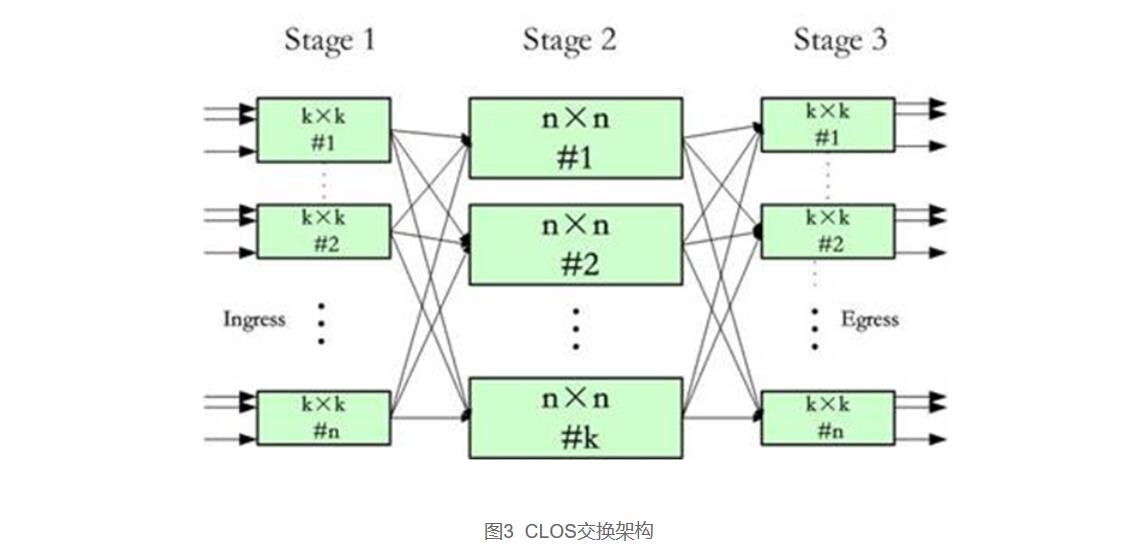
近二十年来包交换网络的高速发展,10G接口已经逐渐无法满足要求,40G口甚至100G口的交换机开始出现在市场,迫切需要超大容量和具备优异可扩展性的交换架构,CLOS这个古老而新颖的技术再一次焕发出旺盛的生命力。
CLOS交换架构是一个多级架构;在每一级,每个交换单元都和下一级的所有交换单元相连接。一个典型的CLOS交换三级架构由(k,n)两个参数定义,如下图所示,参数k是中间级交换单元的数量,n表示的是第一级(第三级)交换单元的数量。第一级和第三级由n个k×k的交换单元组成,中间级由k个n×n的交换单元组成。整个构成了k×n的交换网络,即该网络有k×n个输入和输出端口。
对于需要更高容量的交换网,中间级也可以是一个3级的CLOS网络(即CLOS网络可以递归构建),比如4个第一(三)级n×n芯片加上2个n×n的第二级芯片可构成一个2n×2n的交换网。由于CLOS网络的递归特性,它理论上具有无与伦比的可扩展性,支持交换机端口数量、端口速率、系统容量的平滑扩展。
CLOS交换架构可以做到严格的无阻塞(Non-blocking)、可重构(Re-arrangeable)、可扩展(Scalable)。
(下图是个人对上图理解后画的个人理解图。 )
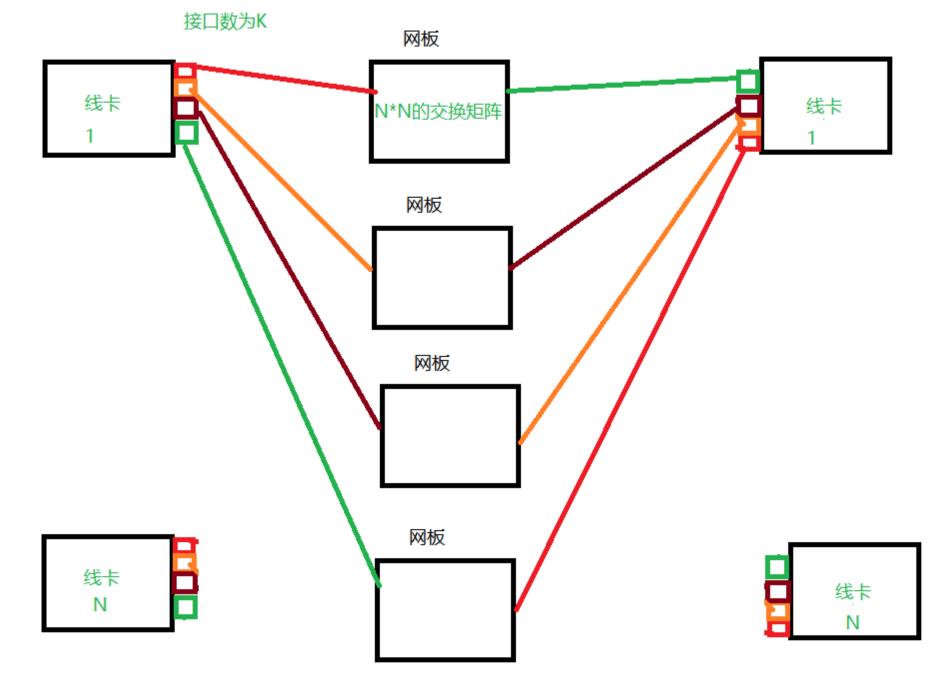
CLOS架构特征:包含多块独立的交换网板(简称 FE),每块网板上包含1个或多个FE交换芯片。
CLOS架构中,我们又分为广义CLOS架构和狭义CLOS架构。但一般来说,我们所说的CLOS架构都是指的狭义CLOS架构。
3.1 广义CLOS架构
广义CLOS架构类似于Crossbar架构,只不过是将交换举证与管理引擎分离了,交换矩阵可以有多块,具备多级交换架构
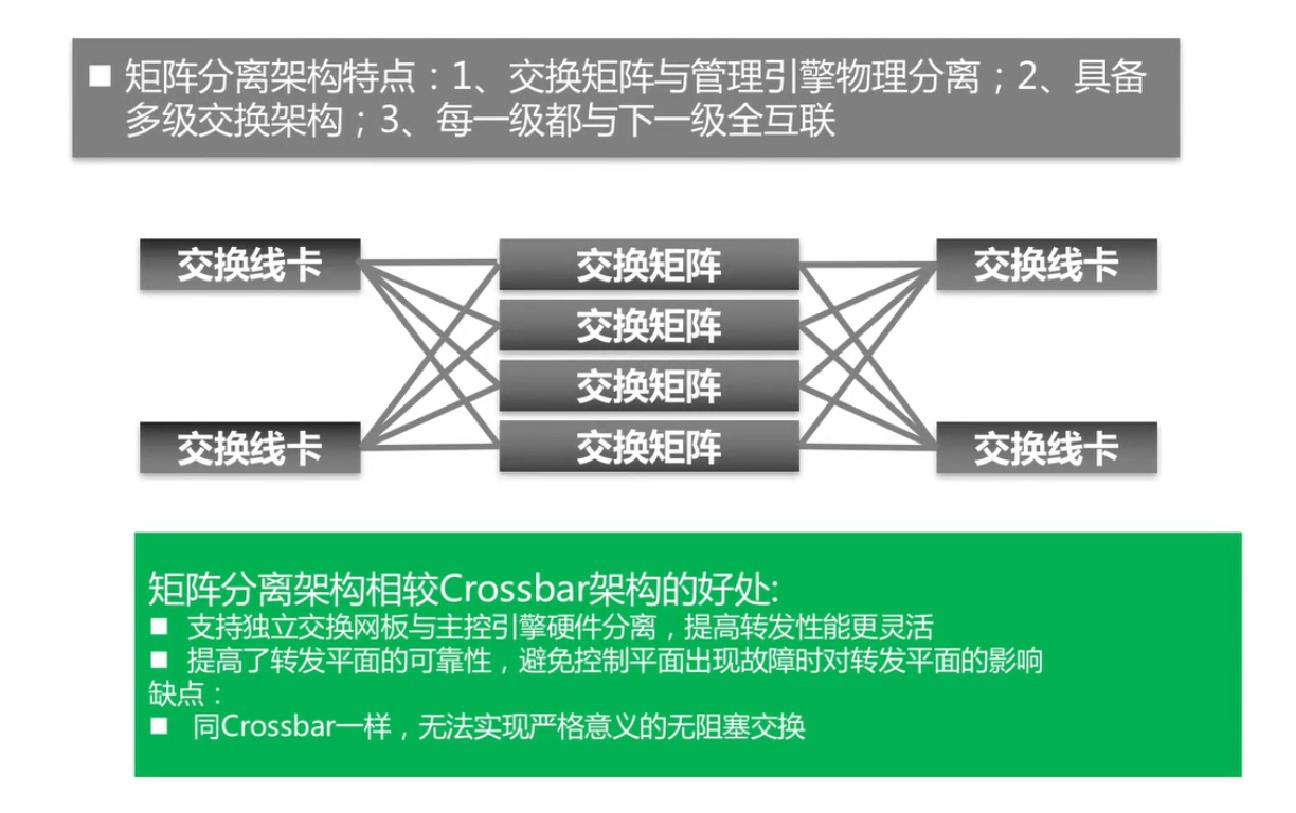
在几何拓扑上将多个Crossbar连成与上文描述的CLOS架构相类似的形式,并采用静态路由方式,即业务流进入交换网前,根据源端口指定或基于Hash算法选择一条路径。所以,属于同一条流的所有报文将选择同一条路径进入交换网。显然,当系统中业务流较为单一时,被Hash算法选中的路径容易形成阻塞,而其它路径则较为空闲。类似道理,业务流从第二级交换到第三级时,也容易形成阻塞。这种架构不是严格意义上的无阻塞CLOS交换架构,其交换性能与基于CIOQ的Crossbar相当。
3.2 狭义CLOS架构
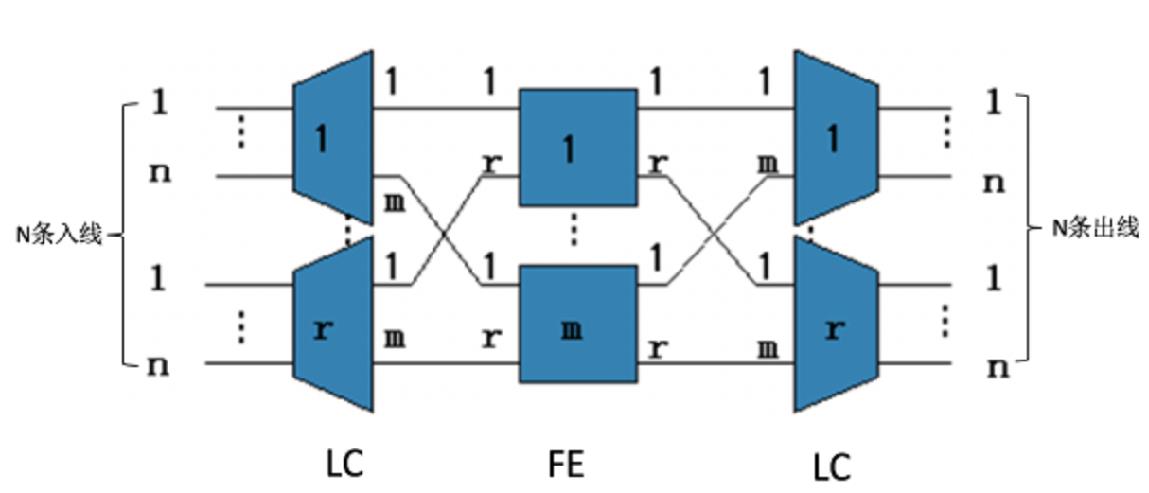
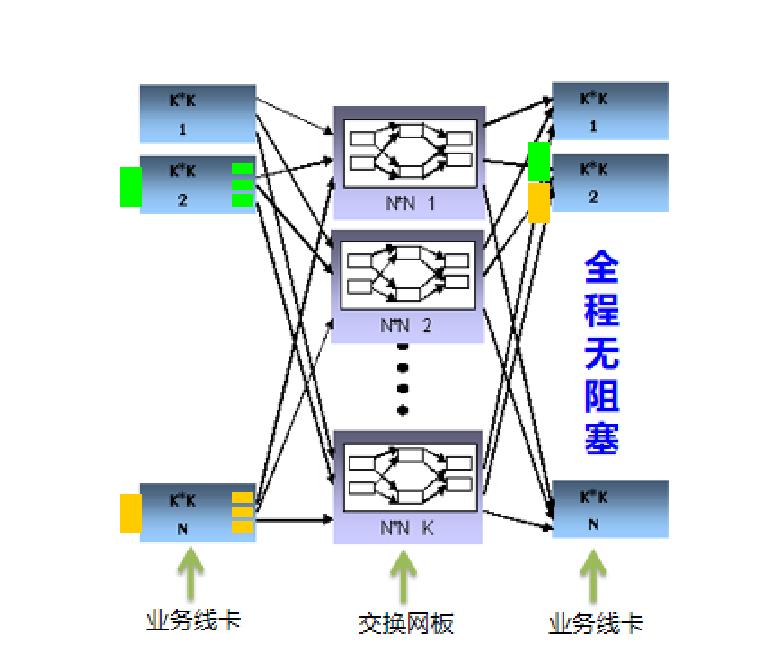
转发方式(基于动态路由的转发方式)
因为这个转发方式需要将数据包切成cell进行转发,所以也叫做基于Cell的动态负载。
1. 第一级线卡,每个业务流可通过Round-robin或随机方式均匀发送到k条连到第二级的路径上
2.入方向线卡将数据包切分为N个cell,其中:N=下一跳可用线路数量;
3. 交换网板采用动态路由方式,即根据下一级各链路的实际可用交换能力,动态选路和负载均衡,通过多条路径将分片发送到出方向线卡;
4. 出方向线卡重组报文。
动态负载关键点在于能负载分担地均衡利用所有可达路径,由此实现了无阻塞交换。
动态路由关键点在于能负荷分担地均衡利用所有可达路径。对于第一级,每个业务流可通过Round-robin或随机方式均匀发送到k条连到第二级的路径上(通常基于信元的发送);到达第二级的业务流将基于信元自路由技术(Cell-based Self-routing),根据交换网路由选择相应路径交换到第三级目的端口。第三级收到所有来自第二级的信元时,把信元重组成报文,并保证报文顺序正确。动态路由方式由此实现了严格的无阻塞交换,并有利于减小加速比从而提高有效端口容量。
动态路由方式有一个突出优点,即平滑支持更高速率的网络端口,比如40GE/100GE。这是因为它可以充分利用所有可用路径形成一个大的数据流通道,比如24条3.125Gbps通道可以支持100GE数据流。相反,静态路由方式则受限于单条路径的带宽,比如基于XAUI接口的Crossbar交换,网络端口速率最高只能达到10Gbps,无法支持40GE和100GE。
基于动态路由的CLOS架构,再结合合适的业务调度机制,就可以支持完善的QoS。采用CLOS交换架构的典型设备有:锐捷N18000统一交换架构核心交换机,Juniper T1600核心路由器。在2009年2月初,Juniper刚刚发布了TX-Matrix Plus,通过多框互联技术支持把16台T1600构建成一个25Tbps的无阻塞交换系统,显示了CLOS架构卓越的可扩展性。2004年,Cisco发布了其路由器旗舰产品CRS-1,采用了三级动态自路由的Benes交换架构,支持72个机架的互联,达到46T/92T的系统容量。Benes交换实质上是CLOS交换架构的一个特例。
由于CLOS交换系统容量很大,物理实现上,通常采用N+1个独立的交换网槽位,与主控板控制平面彻底分离,一方面提高了系统容量可扩展性,另一方面极大程度上提高了转发平面的可靠性,避免了控制平面出现故障或进行倒换时对转发平面的影响。
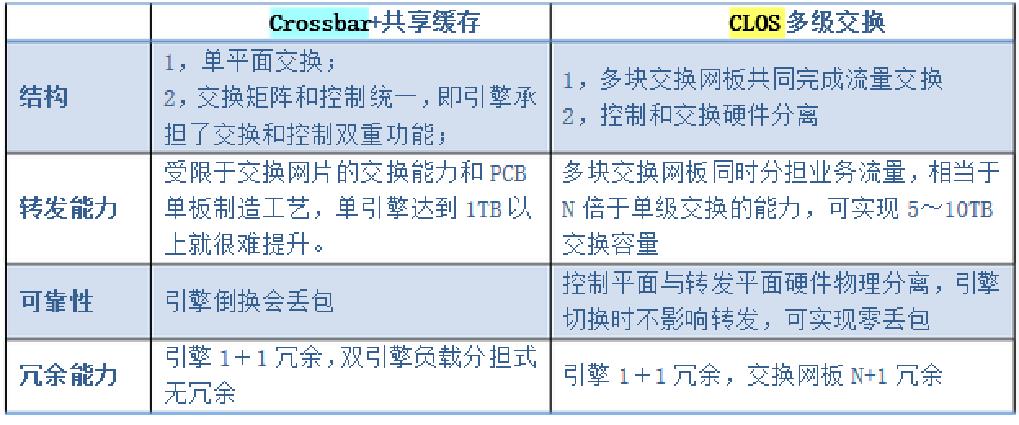
CLOS与Crossbar的对比:
业界典范:
华为CE12800系列
H3C S12500-X、S12500-X-AF系列
锐捷 N18000+C类交换网板、N18000-X系列
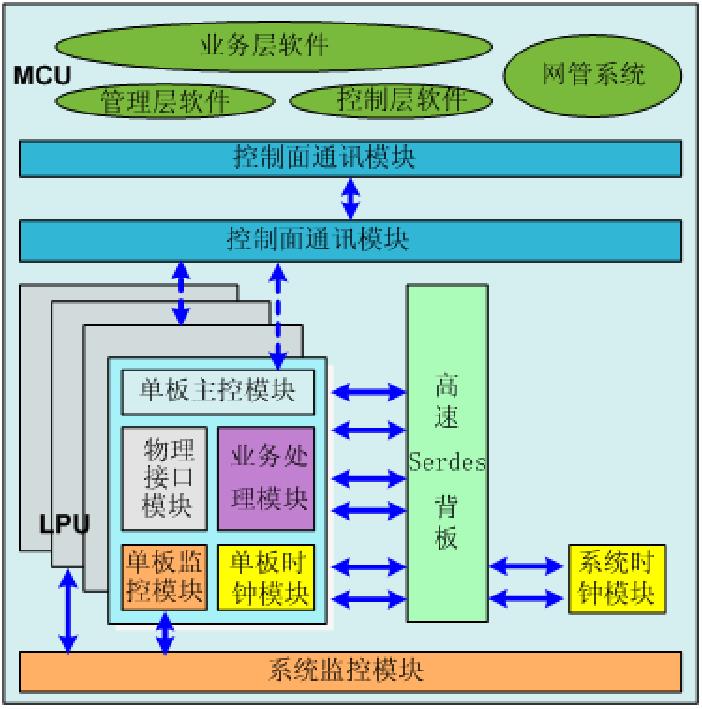
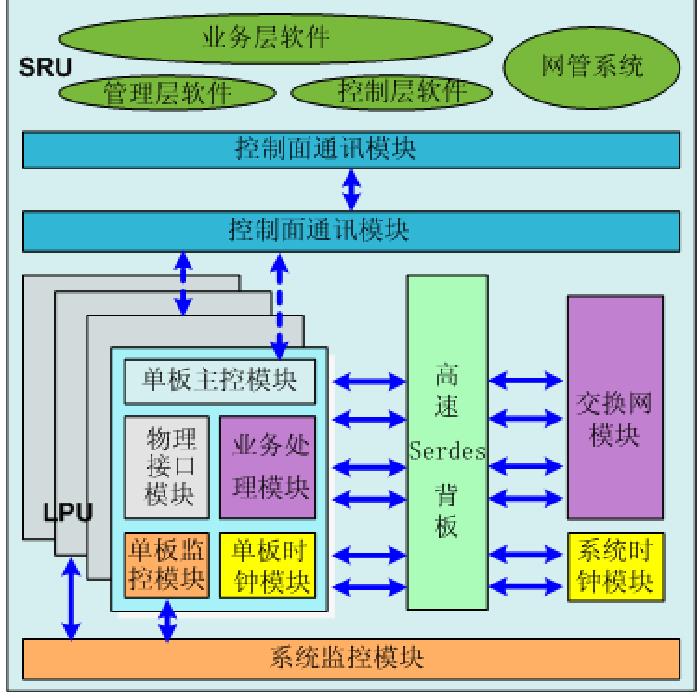
四、交换机网板设计
交换网板主要有三种设计,分别是非正交背板,正交背板,正交零背板

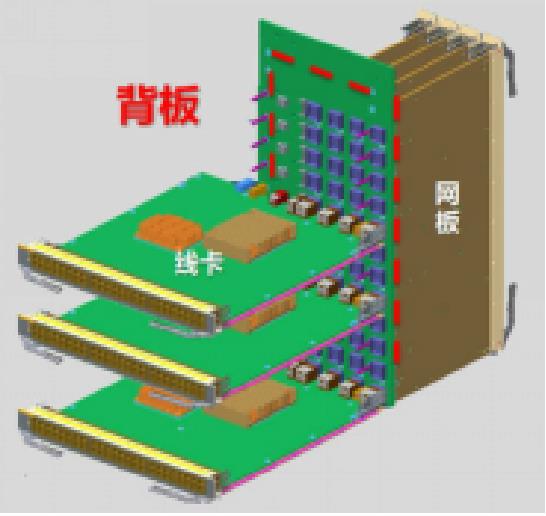
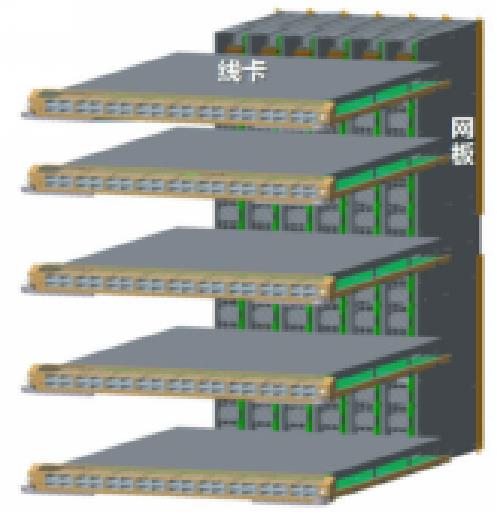
图一 图二 图三
如图1所示,非正交背板结构,业务线卡与交换网板互相平行,板卡之间通过背板走线连接。因为背板走线会带来信号干扰,背板设计也限制了带宽的升级,同时,背板上PCB的走线要求很高,从背板开孔就成了奢望,这直接导致纯前后的直通风道设计瓶颈一直无法突破。所以背板带宽限制了带宽的升级,同时也增加了散热的难度。
我们发现正交结构能够很好的减少背板走线,降低了信号衰减。因此将非正交背板改成了正交背板。 但是同非正交背板设计一样,背板带宽限制了带宽的升级,同时也增加了散热的难度。因此我们就考虑,是不是可以不要背板呢?正交零背板的方式因此出现。
正交设计能减少背板走线带来的高速信号衰减,提高了硬件的可靠性,无背板设计能够解除背板对容量提升的限制,当需要更大带宽的时候,只需要更换相应板卡即可,大大缩短业务升级周期,并且因为没有了背板的限制,交换机直通风道散热问题迎刃而解,匹配数据中心机房空气流的走向,形成了贯穿前后板卡的高速、通畅的气流。由于正交结构的优势,我们逐步转变为了正交背板结构。
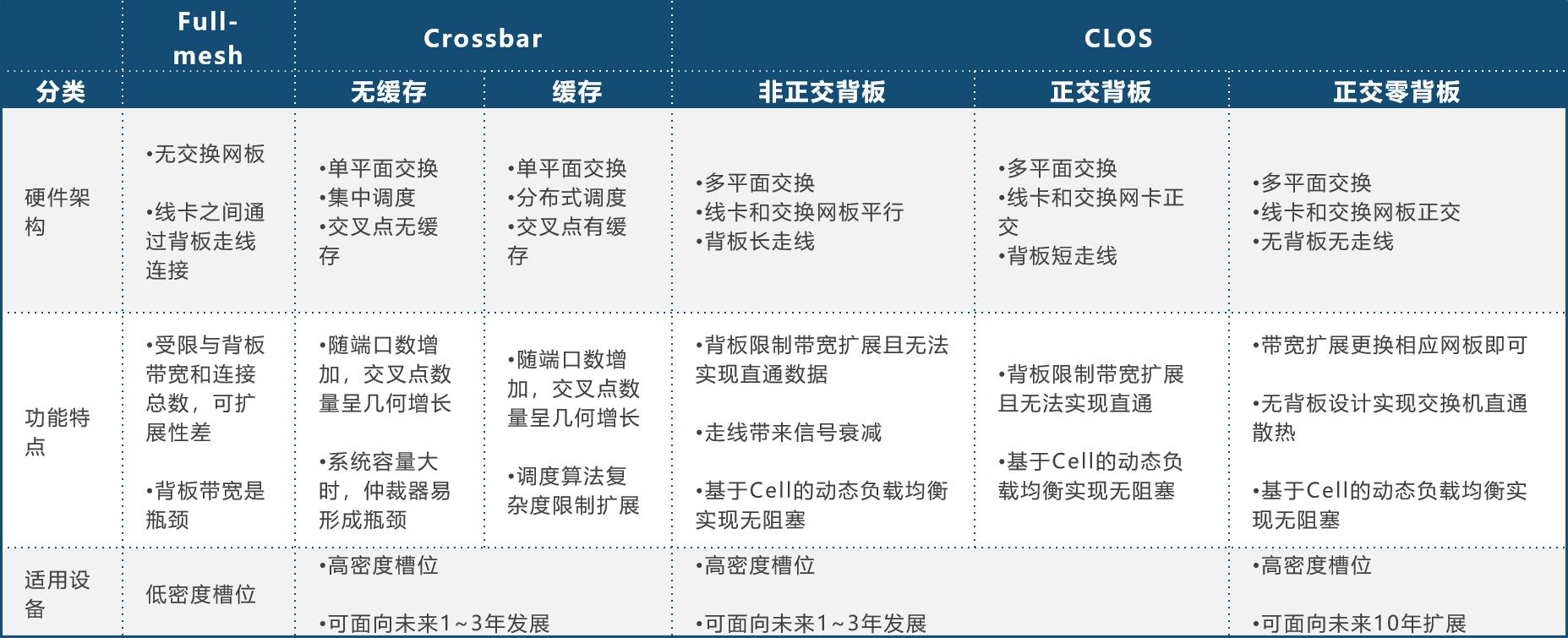
五、总结——架构对比一览
RabbitMQ整体架构
参考技术A如下图,生产者和消费者通过交换器绑定,消息从生产者到达交换器后按照交换器指定的规则发送的特定的队列中,消费者再去队列中消费。
RabbitMQ常用的交换器类型有: fanout 、direct 、topic 、headers 四种。
会把所有发送到该交换器的消息路由到所有与该交换器绑定的队列中,就像风扇一样,把消息“吹到”所有地方。
direct类型的交换器路由规则很简单,它会把消息路由到那些BindingKey和RoutingKey完全匹配的队列中。
topic类型的交换器在direct匹配规则上进行了扩展,也是将消息路由到BindingKey和RoutingKey相匹配的队列中,这里的匹配规则稍微不同,它约定:
BindingKey和RoutingKey一样都是由"."分隔的字符串;BindingKey中可以存在两种特殊字符“ ”和“#”,用于模糊匹配,其中" "用于匹配一个单词,"#"用于匹配多个单词(可以是0个)。
headers类型的交换器不依赖于路由键的匹配规则来路由信息,而是根据发送的消息内容中的headers属性进行匹配。这种类型不建议在生产环境中使用,只需要知道有这种类型就可以了。
RabbitMQ消息有两种类型,持久化消息和非持久化消息,两种消息都会被写入磁盘。
持久化消息在到达队列时写入磁盘,同时会内存中保存一份备份,当内存吃紧时,消息从内存中清除。这会提高一定的性能。
非持久化消息一般只存于内存中,当内存压力大时数据刷盘处理,以节省内存空间。
RabbitMQ存储层包含两个部分,队列索引和消息存储,如下图所示:
索引维护队列的落盘消息的信息,如存储地点、是否已被给消费者接收、是否已被消费者ack等。每个队列都有相对应的索引。
索引使用顺序的段文件来存储,后缀为.idx,文件名从0开始累加,每个段文件中包含固定的segment_entry_count 条记录,默认值是16384。每个index从磁盘中读取消息的时候,至少要在内存中维护一个段文件,所以设置queue_index_embed_msgs_below 值得时候要格外谨慎,一点点增大也可能会引起内存爆炸式增长。
消息以键值对的形式存储到文件中,一个虚拟主机上的所有队列使用同一块存储,每个节点只有一个。存储分为持久化存储(msg_store_persistent)和短暂存储(msg_store_transient)。持久化存储的内容在broker重启后不会丢失,短暂存储的内容在broker重启后丢失。
store使用文件来存储,后缀为.rdq,经过store处理的所有消息都会以追加的方式写入到该文件中,当该文件的大小超过指定的限制(file_size_limit)后,将会关闭该文件并创建一个新的文件以供新的消息写入。文件名从0开始进行累加。在进行消息的存储时,RabbitMQ会在ETS(Erlang TermStorage)表中记录消息在文件中的位置映射和文件的相关信息。
消息(包括消息头、消息体、属性)可以直接存储在index中,也可以存储在store中。最佳的方式是较小的消息存在index中,而较大的消息存在store中。这个消息大小的界定可以通过queue_index_embed_msgs_below 来配置,默认值为4096B。当一个消息小于设定的大小阈值时,就可以存储在index中,这样性能上可以得到优化。一个完整的消息大小小于这个值,就放到索引中,否则放到持久化消息文件中。
如果消息小于这个值,就在索引中存储,也就是存储于<num>.idx索引文件中,如果消息大于这个值就在store中存储,也就是存储在msg_store_persistent目录中的<num>.rdq文件中。
以上是关于交换机——交换架构的主要内容,如果未能解决你的问题,请参考以下文章