系统架构 之 高性能数据传输系统的框架设计
Posted 祁峰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了系统架构 之 高性能数据传输系统的框架设计相关的知识,希望对你有一定的参考价值。
- 作者:邹祁峰
- 邮箱:Qifeng.zou.job@hotmail.com
- 博客:http://blog.csdn.net/qifengzou
- 日期:2014.05.04
- 转载请注明来自"祁峰"的CSDN博客
1 引言
随着互联网和物联网的高速发展,使用网络的人数和电子设备的数量急剧增长,其也对互联网后台服务程序提出了更高的性能和并发要求。本文的主要目的是阐述在单机上如何进行高并发、高性能消息传输系统的框架设计,以及该系统的常用技术,但不对其技术细节进行讨论。如您有更好的设计方案和思路,望共分享之![注:此篇用select来讲解,虽在大并发的情况下,epoll拥有更高的效率,但整体设计思路是一致的]
首先来看看课本和学习资料上关于处理并发网络编程的三种常用方案,以及对应的大体思路和优缺点:
1) IO多路复用模型
->思路:单进程(非多线程)调用select()函数来处理多个连接请求。
->优点:单进程(非多线程)可支持同时处理多个网络连接请求。
->缺点:最大并发为1024个,当并发数较大时,其处理性能很低。
2) 多进程模型
->思路:当连接请求过来时,主进程fork产生一个子进程,让子进程负责与客户端连接进行数据通信,当客户端主动关闭连接后,子进程结束运行。
->优点:模式简单,易于理解;连接请求很小时,效率较高。
->缺点:当连接请求过多时,系统资源很快被耗尽。比如:当连接请求达到10k时,难道要启动10k个进程吗?
3) 多线程模型
->思路:首先启动多个工作线程,而主线程负责接收客户端连接请求,工作线程负责与客户端通信;当连接请求过来时,ACCEPT线程将sckid放入一个数组中,工作线程中的空闲线程从数组中取走一个sckid,对应的工作线程再与客户端连接进行数据通信,当客户端主动关闭连接后,此工作线程又去从指定数组中取sckid,依次重复运行。
->优点:拥有方案2)的优点,且能够解决方案2)的缺点。
->缺点:不能支持并发量大的请求和量稍大的长连接请求。
通过对以上三种方案的分析,以上方案均不能满足高并发、高性能的服务器的处理要求。针对以上设计方案问题的存在,该如何设计才能做到高并发、高性能的处理要求呢?
2 设计方案
2.1 大体框架
为提高并发量和处理性能,在此采用2层的设计架构。第一层由接收线程组成,负责接收客户端数据;第二层由工作线程组成,负责对接收的数据进行相应处理。为了减少数据的复制和IO操作,将接收到的客户端数据使用队列进行存储;工作线程收到处理指令后,从指令中提取相应的参数,便可知道到哪个线程的队列中获取数据。因此,系统的大体架构如下所示:1) 框架-1
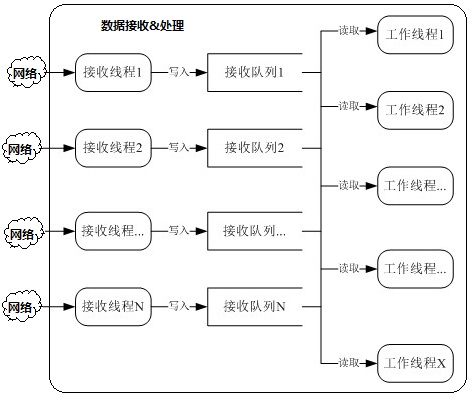
图1 大体框架-01
[注:接收线程数:接收队列数:工作线程数 = N:N:X]
优点:
1)、有效避免接收线程之间出现锁竞争的情况。
每个接收线程对应一个接收队列,每个接收线程将接收到的数据只放在自己对应的队列中;
2)、在数据量不是很大的情况下,此框架结构还是能够满足处理要求。
缺点:
1)、在连接数量很少、而数据量很大时,将会造成锁冲突严重,致使性能急剧下降。
假如:当前系统中只有1个TCP连接,由Recv线程2负责接收该连接中的所有数据。Recv线程2每收到一条数据,就将随机通知工作线程到该队列上取数据。在某个时刻,该连接的客户端发来大量数据,将造成所有工作线程同时到Recv队列2中来取数据。此时将会出现严重的锁冲突现象,性能急剧下降。
2) 框架-2
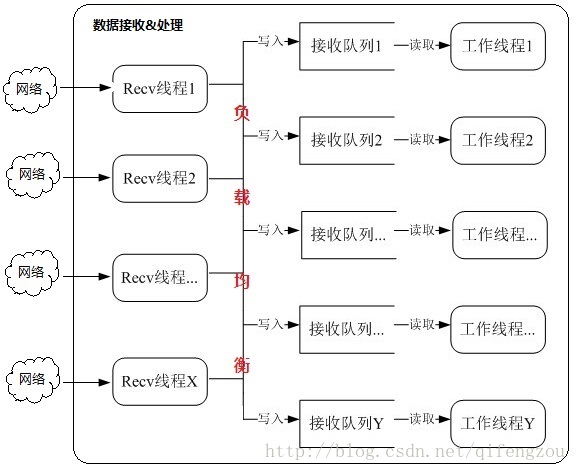
图2 大体框架-02
[注:接收线程数:接收队列数:工作线程数 = X:Y:Y]
优点:
1)、有效避免工作线程之间出现锁竞争的情况。
每个工作线程对应一个接收队列,每个接收线程将接收到的数据只放在自己对应的队列中;
2)、工作线程数 >= 2*接收线程数 时,能够有效的减少接收线程之间的锁竞争的情况
在这种情况下,我想你可以得到你想要的处理性能!
缺点:
1)、需要为更高的性能,付出更多的系统资源(主要:内存和CPU)。
2.2 如何提高并发量?
“并发量”是指系统可接受的TCP连接请求数。首先需要明确的是:"高并发"只是一个相对概念。如:有些系统1K并发就算是高并发,而有些系统100K并发也不能满足要求。因此,在此只给出提高并发量的设计思路。
众所周知,IO多路复用中1个select函数最多可管理FD_SETSIZE(该值一般为1024)个SOCKET套接字,而如果要求并发量达到100K时,显然已大大超过了1个select的管理能力,那该如何解决?
答案是:使用多个select可以有效的解决以上问题。100K约等于100 * 1024,故需大约100个select才能有效管理100k并发。那该如何调用100个select来管理100k的并发呢?
因FD的管理在进程之间是独立的,虽然子进程在创建之时,会继承父进程的FD,但后续连接产生的FD却无法让子进程继续继承,因此,要实现对100k并发的有效管理,使用多线程实现高并发是理想的选择。即:每个线程调用1个select,而每个select可以管理1024个并发。
在理想情况下,启动N个接收线程,系统便可处理N *1024的并发。如:启动100个接收线程,单机便可处理100 * 1024 = 100k的网络并发。但需要注意的是:线程越多,消耗的资源越多,操作系统调度的开销越大,如果调度开销超过多线程带来的性能提升,随着线程的增加,将导致系统性能越低。(如果要求处理5k以上的请求,我将毫不犹豫的选择"多线程+epoll"的方式)
2.3 如何提高处理性能?
1) Recv流程为了提高Recv线程接收来自客户端的数据的性能,其处理过程需要使用到:IO多路复用技术,非阻塞IO技术、内存池技术、加锁技术、事件触发机制、负载均衡策略、UNINX-UDP技术、设计模式等,这需要研发人员对各技术有深刻的认识和理解。Recv线程的大体处理流程:
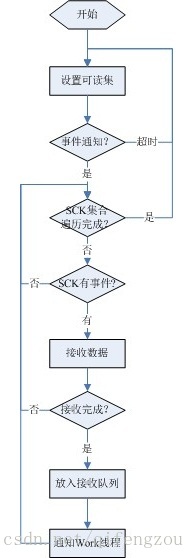
图2 Recv线程处理流程
为了减少数据的复制,可以在接收数据开始时,Recv线程就为将要接收的数据从接收队列中分配一块空间。当Recv线程接收到一条完整的客户端数据后,则通过UNINX-UDP发送消息,告知某一Work线程到指定接收队列中取走数据进行处理。Recv线程通知Work线程的过程需要采用负载均衡策略。
2) Work流程
在无处理消息到来之前,一直处在阻塞状态,当有Recv线程的处理通知时,则接收消息内容,对消息进行分析,再根据消息的内容到指定的接收队列中取数据,再对数据进行相应的处理。其大体流程如下图所示:
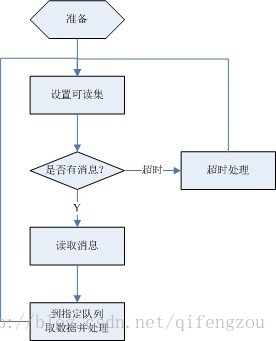
图3 Work线程处理流程
2.3 链路分发
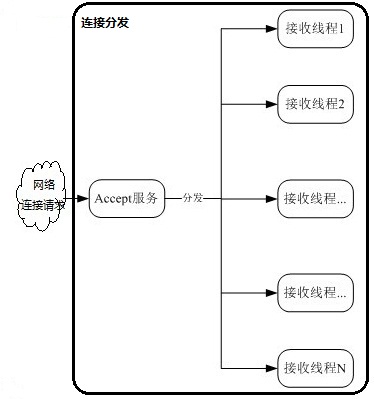
说了这么多,但一直未提到各Recv线程是如何分配和获取客户端通信SOCKET的。众所周知,当一个线程通过TCP方式绑定指定端口后,其他线程或进程想再次绑定该端口时,必将返回错误。而如果让一个Listen套接字同时加入到多个Recv线程的select的可读集合进行监听,又会出现“惊群"现象:当有1个新的客户端连接请求到来时,所有的Recv线程都会被惊醒 —— 这显然是应该避免的。为了避免"惊群"的出现,通常有如下2种方案: 方案1) 创建链路分发模块 当有客户端连接请求过来时,该线程调用accept接收来自客户端的连接,再将新SOCKET-FD分发给某1个Recv线程,该Recv线程再将FD加入select的FD_SET中进行监听,从而实现Recv线程与客户端的通信。 方案2) Lsn套接字流转侦听当一个线程/进程抢占到该Listen套接字后,该线程/进程将会开始接收来自客户端的连接请求和监听产生的套接字以及后续的数据接收等工作,当该线程接收的套接字超过一定量时,该线程将会主动放弃对Listen套接字的监听,而让其他线程/进程去抢占Listen套接字。nginx采用的就是此方案。
在此采用的是方案1)的解决办法:Listen线程将接收的客户端请求产生的通信SOCKET均衡的分发给RECV线程[采用UNINX-UDP的方式发送]。其大体框架如下:
3 方案总结
以上设计方案适合客户端向服务端传输大量数据的场景,如果需要服务端反馈最终的处理结果,则需为Recv线程增加一个与之对应发送队列,在此不再赘述。总之,要做到高并发、高性能的网络通信系统,往往需要以下技术做支撑,这需要研发人员对以下技术拥有深刻的理解和认识,当然这还远远不够。
1)IO多路复用技术 2)非阻塞IO技术 3)事件驱动机制 4)线程池技术 5)负载均衡策略 6)内存池技术 7)缓存技术 8)锁技术 9)设计模式 10)高效算法和技巧的使用等等
以上是关于系统架构 之 高性能数据传输系统的框架设计的主要内容,如果未能解决你的问题,请参考以下文章