Spark SQL 快速入门(第二集)
Posted 技术能量站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark SQL 快速入门(第二集)相关的知识,希望对你有一定的参考价值。
1. 前言
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。
1.1 Spark SQL 的作用
- Spark SQL 的一种用途是执行 SQL 查询
- Spark SQL 也可用于从现有 Hive 安装中读取数据
1.2 Hive 和spark SQL 的关系
SparkSQL 的前身是 Shark,给熟悉 RDBMS 但又不理解 MapReduce 的技术人员提供快 速上手的工具。
Hive 是早期唯一运行在 Hadoop 上的 SQL-on-Hadoop 工具。但是 MapReduce 计算过程 中大量的中间磁盘落地过程消耗了大量的 I/O,降低的运行效率,为了提高 SQL-on-Hadoop 的效率,大量的 SQL-on-Hadoop 工具开始产生,其中表现较为突出的是: Drill 、Impala 、Shark。
对于开发人员来讲,SparkSQL 可以简化 RDD 的开发,提高开发效率,且执行效率非 常快,所以实际工作中,基本上采用的就是 SparkSQL。Spark SQL 为了简化 RDD 的开发, 提高开发效率,提供了 2 个编程抽象,类似 Spark Core 中的 RDD的DataFrame、DataSet。
1.3 Spark SQL 的特点
- 易整合: 无缝的整合了 SQL 查询和 Spark 编程
- 统一数据访问: 使用相同的方式连接不同的数据源
- 兼容Hive: 在已有的仓库上直接运行 SQL 或者 HiveQL
- 标准数据连接: 通过 JDBC 或者 ODBC 来连接
2. 夯实基础
使用Spark SQL 首先我们就要了解两个核心类:DataFrame、DataSet。
2.1 DataFrame
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中 的二维表格。DataFrame 与 RDD 的主要区别在于,前者带有 schema 元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型。这使得 Spark SQL 得以洞察更多的结构 信息,从而对藏于 DataFrame 背后的数据源以及作用于 DataFrame 之上的变换进行了针对性 的优化,最终达到大幅提升运行时效率的目标。反观 RDD,由于无从得知所存数据元素的 具体内部结构,Spark Core 只能在 stage 层面进行简单、通用的流水线优化。
同时,与 Hive 类似,DataFrame 也支持嵌套数据类型(struct、array 和 map)。从 API 易用性的角度上看,DataFrame API 提供的是一套高层的关系操作,比函数式的 RDD API 要 更加友好,门槛更低。

上图直观地体现了 DataFrame 和 RDD 的区别。
- 左侧的 RDD[Person]虽然以 Person 为类型参数,但 Spark 框架本身不了解 Person 类的内 部结构。
- 右侧的 DataFrame 却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道 该数据集中包含哪些列,每列的名称和类型各是什么。
DataFrame 是为数据提供了 Schema 的视图。可以把它当做数据库中的一张表来对待 DataFrame 也是懒执行的,但性能上比 RDD 要高,主要原因:优化的执行计划,即查询计 划通过 Spark catalyst optimiser 进行优化。
2.2 DataSet
DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame 的一个扩展。它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换(操作 map,flatMap,filter 等等)。
- DataSet 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象
- 用户友好的 API 风格,既具有类型安全检查也具有 DataFrame 的查询优化特性;
- 用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到 DataSet 中的字段名称;
- DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person]。
- DataFrame 是 DataSet 的特列,DataFrame=DataSet[Row] ,所以可以通过 as 方法将 DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的 表结构信息都用 Row 来表示。获取数据时需要指定顺序。
3. 实战应用
3.1 案例编码
引入maven,实际上仍然放在前一章节的Spark小例子的项目里即可,增加spark-sql_2.12这个包
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.2.1</version>
</dependency>
</dependencies>
主方法,SparkSQL基础一些操作,读取json文件数据,输出数据,分组等基础操作
package com.sparkwordcount;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import static org.apache.spark.sql.functions.col;
public class SparkSQLMain
public static void main(String[] args)
// 初始化SparkSQl的环境变量,为后边执行提供初始化环境
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate();
// 读取json数据,不光可以从json文件,同样可以从csv,txt读取数据源
Dataset<Row> df = spark.read().json("/test/input/people.json");
// 从csv读取,我已经写了另一份csv文件,大家可以解开注释测试这部分
// Dataset<Row> df = spark.read().format("csv").option("header", "true").load("/test/input/people.csv");
// 输出所有数据
df.show();
// 输出表结构的树形结构
df.printSchema();
// 只展示name的列数据
df.select("name").show();
// 展示出所有数据,把每一个年龄展示+1
df.select(col("name"), col("age").plus(1)).show();
// 展示出所有数据年龄大于21的数据
df.filter(col("age").gt(21)).show();
// 按照age分组统计个数
df.groupBy("age").count().show();
// 将这部分数据存储到临时表中,当本次SparkSession结束后,表也就没有了
df.createOrReplaceTempView("people");
// 通过SQL方式查询
Dataset<Row> sqlDF = spark.sql("SELECT * FROM people");
sqlDF.show();
通过csv读数据,存入临时表,通过SQl的方式读取
package com.sparkwordcount;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class SparkSQLGlobalTempMain
public static void main(String[] args) throws Exception
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL basic example global create")
.config("spark.some.config.option", "some-value")
.getOrCreate();
// csv读取数据
Dataset<Row> df = spark.read().format("csv").option("header", "true").load("/test/input/people.csv");
// 输出所有数据
df.show();
// 将这部分数据存储到Global临时表中,当本次SparkSession结束后,表存在于Global中
df.createOrReplaceGlobalTempView("people");
// 刚建立了Global临时表,需要通过global_temp的SQL方式查询
Dataset<Row> sqlDF = spark.sql("SELECT * FROM global_temp.people");
sqlDF.show();
3.2 项目打包
设定Artifacts打包
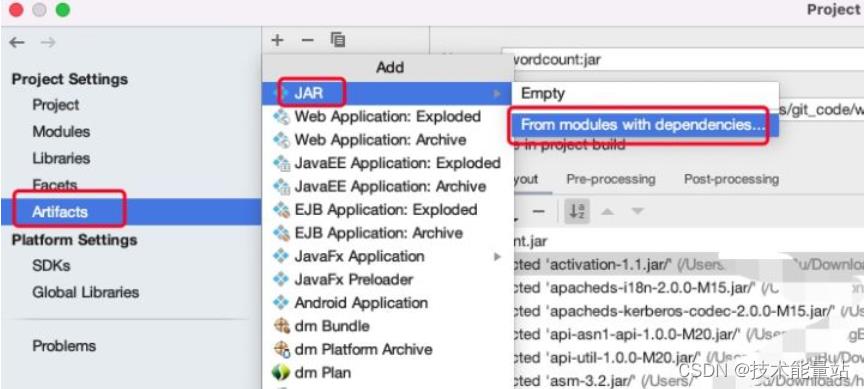
执行Build Artifaces打包

会在指定目录生成jar包SparkWordCount.jar
3.3 上传到docker并运行
按下面命令操作,注意使用自己的目录。
#在宿主机(docker运行的计算机上)上传刚才打包的jar包到docker中
docker cp /Users/SparkWordCount/out/SparkWordCount.jar master:/usr/local
#进入docker
#进入docker
docker exec -it master bash
#进入Spark目录
cd /usr/local/spark-3.0.3-bin-hadoop2.7
#编辑数据文件json格式的,注意一行一条数据,换行就报错
vi people.json
"age":1,"name":"Jim"
"age":30,"name":"Andy"
"age":19,"name":"Justin"
#编辑数据文件,注意一行一条数据,换行就报错
vi people.csv
age,name
1,Jim
30,Andy
19,Justin
#将json和csv上传到hdfs中
hadoop fs -put ./people.json /test/input
hadoop fs -put ./people.csv /test/input
#进入spark目录执行
cd /usr/local/spark-3.0.3-bin-hadoop2.7
#执行SparkSQLMain
./bin/spark-submit \\
--class com.sparkwordcount.SparkSQLMain \\
--master local \\
../SparkWordCount.jar \\
100
#输出结果,忽略一大堆乱七八糟的日志
#df.show();结果
+---+------+
|age| name|
+---+------+
| 1| Jim|
| 30| Andy|
| 19|Justin|
+---+------+
#df.printSchema();结果
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
#df.select("name").show();结果
+------+
| name|
+------+
| Jim|
| Andy|
|Justin|
+------+
#df.select(col("name"), col("age").plus(1)).show();结果
+------+---------+
| name|(age + 1)|
+------+---------+
| Jim| 2|
| Andy| 31|
|Justin| 20|
+------+---------+
#df.filter(col("age").gt(21)).show();结果
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
#df.groupBy("age").count().show();结果
+---+-----+
|age|count|
+---+-----+
| 19| 1|
| 1| 1|
| 30| 1|
+---+-----+
#sqlDF.show();输出,
+---+------+
|age| name|
+---+------+
| 1| Jim|
| 30| Andy|
| 19|Justin|
+---+------+
#执行SparkSQLGlobalTempCreateMain
./bin/spark-submit \\
--class com.sparkwordcount.SparkSQLGlobalTempCreateMain \\
--master local \\
../SparkWordCount.jar \\
100
#df.show();输出
+---+------+
|age| name|
+---+------+
| 1| Jim|
| 30| Andy|
| 19|Justin|
+---+------+
#sqlDF.show();输出
+---+------+
|age| name|
+---+------+
| 1| Jim|
| 30| Andy|
| 19|Justin|
+---+------+
4. 总结
因此实际上,SparkSQL就是能够作为一种使用SQL方式方便大家对数据进行统计计算排序等的操作,使大家更加方便的处理数据,以及方便从各种数据源json,csv,txt等文件直接读取数据进行处理,十分的方便。更多详细内容可以查看官网文档:https://spark.apache.org/docs/latest/quick-start.html
 开发者涨薪指南
开发者涨薪指南
 48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系
以上是关于Spark SQL 快速入门(第二集)的主要内容,如果未能解决你的问题,请参考以下文章