ChatGPT对话数据备份
Posted 如果皮卡会coding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ChatGPT对话数据备份相关的知识,希望对你有一定的参考价值。
ChatGPT对话数据备份
文章目录
1. 背景
之前在ChatGPT更新时有好几天都无法查看过往对话,而在服务器爆满宕机的时候更是不能登录回顾自己的对话。
所以有了缓存自己对话的需要,做好数据的备份。
2. 其他(失败的)方法
2.1 右键另存为
第一个想到最便捷的方法无疑是直接在浏览器端右键“另存为”:
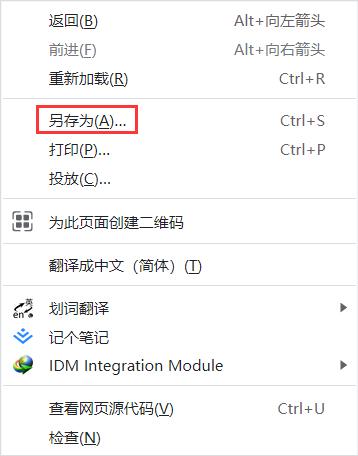
然而这种方法会额外下载许多资源文件:并放在一个目录上。

关键是当你双击页面进入时,只会出现首页,根本没有保存到对话:
(猜测是因为router:每次进入都是先进入该首页,随后再进行路由跳转到对应的对话。)
2.2 直接copy html代码
学过前端基础的小伙伴就知道,我们右键“检查”可以打开控制台,在“元素”栏目上找到整个对话的html代码——即main标签,随后粘贴到本地的html文件中进行重现。
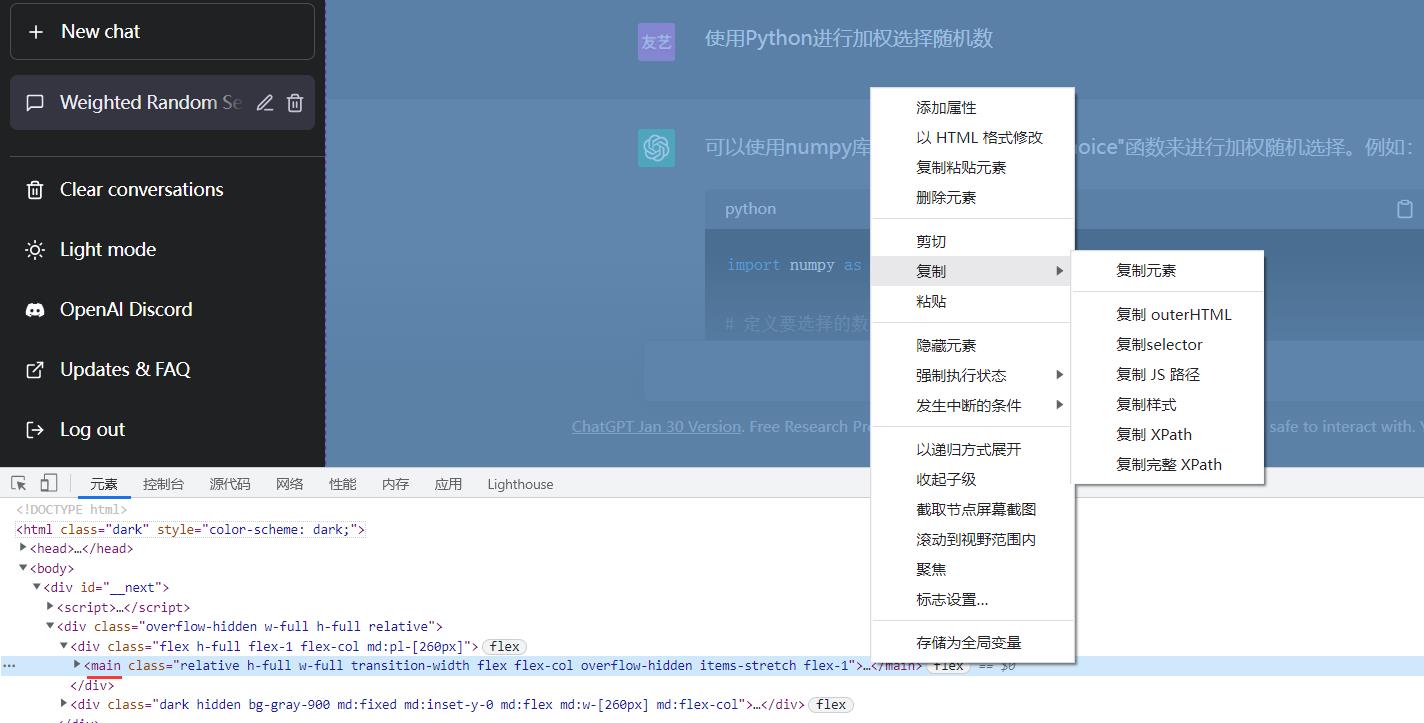
这种方式可以得到我们对话的数据,当然,因为仅有main标签,所以损失了对应的样式和copy code的功能。

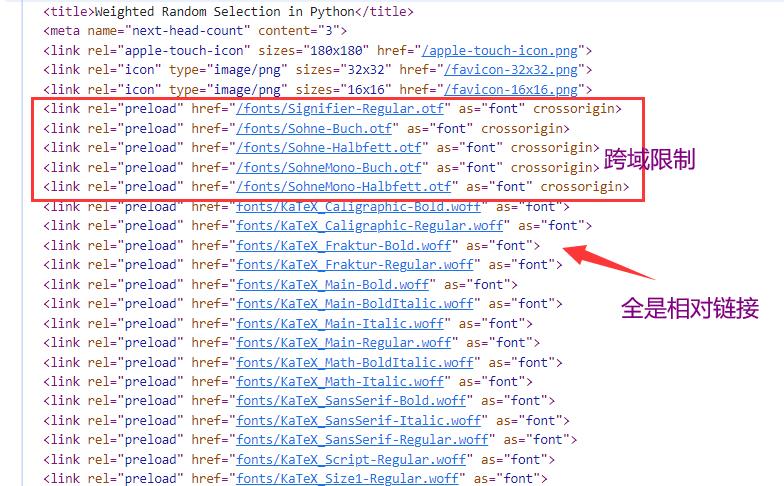
即便是copy整份html代码也是如此。
原因就是源代码上的script标签和样式链接基本都是相对链接,而且部分资源还有跨域限制。
3. 编写javascript脚本
至此,为了省去不必要的麻烦。同时也是脚本优化的功能所在:
-
一键下载当前对话的html,不额外下载其他静态资源。
-
自动转化所有的相对链接为绝对链接。
-
保留样式风格:
light mode以及dark mode。 -
保证隐私:去除了原页面所有的script脚本,仅保留自己实现的
copy code功能。
3.1 思路过程
- 操作DOM对象
- 仅保留<head>标签和<main>标签、去除侧边栏、底部
- 对DOM对象内部所有的“相对链接”都转成“绝对链接”
- 通过正则提取内部所有的<script>标签并去除,自己写一个
copy code的<script>标签引入。
- 小细节:需要对页面DOM对象进行深拷贝,否则会影响原本的页面。
3.2 安装教程
- 下载浏览器端脚本管理器(如Tampermonkey,暴力猴)。
- 脚本下载途径:(两种)
- 下载Gitee仓库js文件夹内的downloadgpt.js,并将该脚本导入到管理器。
- 通过
Greasyfork网站直接下载:https://greasyfork.org/zh-CN/scripts/459853-download-chatgpt-record
3.3 使用说明
下载脚本后进入ChatGPT聊天,右下角出现download按钮,点击即可保存当前的对话记录。
3.4 最终效果
保存后的html文件页面如下:
和ChatGPT对话学习使用时序数据库
前言和小结
从昨天的文章来看【和ChatGPT对话】就让它帮我做完成绩数据分析、【和ChatGPT对话】帮助新手批量提取图片文字信息到文件,ChatGPT 完成基本的数据处理业务已经在行了。那么继续往下,是不是能完成数据库的构建,开发持久的数据服务呢?本文选取时序数据库进行尝试。
时序数据库是当前物联网服务的热门数据库,其建表和查询逻辑和传统关系型数据库不同。从实际问答和编码来看,ChatGPT 也可以轻松搞定建表、写数据、查询、编码开发的任务。 其中比较有意思的是,如果是直接建表,那么优先使用中文字段名称;如果是要一次性编程,那么就会使用英文字段名称。翻译结果还是一目了然,虽然没有增加注释,但不影响阅读。
Q1 时序数据库有什么特点,比较流行的是哪些,目前发展势头最好的是哪个
时序数据库(Time Series Database,TSDB)是一种专门用于处理时间序列数据的数据库系统。时序数据是按时间顺序采集或生成的数据集合,例如传感器数据、日志数据、监控数据、金融数据等。
时序数据库的主要特点包括:
- 专注于处理时序数据:时序数据库专门针对时间序列数据设计和优化,可以高效地存储、查询和分析大规模的时序数据集。
- 支持高并发和大规模数据:时序数据库通常可以支持大规模的数据存储和高并发的数据读写操作,以满足大规模时序数据处理的需求。
- 支持复杂的查询和分析:时序数据库通常支持基于时间窗口、聚合函数、时间序列预测、异常检测等复杂的查询和分析操作。
- 具备高可用性和容错能力:时序数据库通常具备高可用性和容错能力,可以在节点故障、网络异常等情况下保证系统的正常运行。
目前比较流行的时序数据库包括:
- InfluxDB:一个开源的、分布式的时序数据库,采用Go语言编写,支持SQL查询和类似于HTTP的API接口。
- Prometheus:一个开源的、针对监控数据的时序数据库,采用Go语言编写,支持高效的指标存储和查询。
- OpenTSDB:一个开源的、基于Hadoop和HBase的时序数据库,支持大规模数据存储和高效的数据查询。
- TimescaleDB:一个开源的、基于PostgreSQL的时序数据库,支持SQL查询和与PostgreSQL兼容的API接口。
目前发展势头最好的时序数据库可能是InfluxDB。InfluxDB具有出色的性能和扩展性,支持大规模的数据存储和高效的查询操作,还具备强大的数据处理和分析能力。此外,InfluxDB的开发团队积极推进新功能的开发和优化,持续不断地为用户提供更好的体验。
Q2 现在使用 InfluxDB,创建一个交通路口抓拍车辆的数据表,记录城市名称,路口名称,车辆号牌,红绿灯状态,通行速度和时间戳,需要记录100个路口,按照路口比较繁忙考虑,后续需要对路口车辆分组统计,对城市分组统计,每分钟车辆数量统计
可以按照以下步骤在 InfluxDB 中创建交通路口抓拍车辆的数据表:
- 创建数据库:首先需要在 InfluxDB 中创建一个新的数据库,可以使用 InfluxDB CLI 或者 Web 界面进行创建。
CREATE DATABASE traffic_data
- 创建数据表:然后可以创建一个名为 intersection_traffic 的数据表,用于存储交通路口抓拍车辆的数据。
CREATE RETENTION POLICY "one_month" ON "traffic_data" DURATION 30d REPLICATION 1 DEFAULT
CREATE CONTINUOUS QUERY "cq_1_minute_intersection_traffic" ON "traffic_data" BEGIN SELECT count("车辆号牌") INTO "traffic_data"."one_month"."1_minute_intersection_traffic_count" FROM "intersection_traffic" GROUP BY time(1m), "城市名称", "路口名称" END
CREATE CONTINUOUS QUERY "cq_1_hour_intersection_traffic" ON "traffic_data" BEGIN SELECT count("车辆号牌") INTO "traffic_data"."one_month"."1_hour_intersection_traffic_count" FROM "intersection_traffic" GROUP BY time(1h), "城市名称", "路口名称" END
CREATE CONTINUOUS QUERY "cq_1_day_intersection_traffic" ON "traffic_data" BEGIN SELECT count("车辆号牌") INTO "traffic_data"."one_month"."1_day_intersection_traffic_count" FROM "intersection_traffic" GROUP BY time(1d), "城市名称", "路口名称" END
注意这里使用了 InfluxQL 语句来定义数据表的字段和标签,其中标签 城市名称 和 路口名称 可以用于后续的分组统计。
CREATE TABLE "intersection_traffic" (
"城市名称" TAG,
"路口名称" TAG,
"车辆号牌" STRING,
"红绿灯状态" STRING,
"通行速度" INTEGER,
"时间戳" TIME
) WITH (
"measurement" = "intersection_traffic",
"retention_policy" = "one_month"
)
- 插入数据:可以使用 InfluxDB CLI 或者 API 接口向数据表中插入数据,例如:
INSERT INTO "intersection_traffic" ("城市名称", "路口名称", "车辆号牌", "红绿灯状态", "通行速度", "时间戳")
VALUES (上海, 人民广场, 沪A00001, 绿灯, 50, 2023-02-16T10:00:00Z)
- 分组统计:可以使用 InfluxQL 语句对数据进行分组统计,例如:
对路口进行分组统计:
SELECT count("车辆号牌") FROM "intersection_traffic" GROUP BY "城市名称", "路口名称"
对城市进行分组统计:
SELECT count("车辆号牌") FROM "intersection_traffic" GROUP BY "城市名称"
- 每分钟车辆数量统计:为了每分钟车辆数量统计
可以使用 InfluxDB 的 Continuous Queries 功能,将数据按照每分钟进行聚合,并将结果存储在新的数据表中,可以使用以下 InfluxQL 语句创建每分钟车辆数量统计的 Continuous Query:
CREATE CONTINUOUS QUERY "cq_1_minute_intersection_traffic" ON "traffic_data"
BEGIN
SELECT count("车辆号牌") INTO "traffic_data"."one_month"."1_minute_intersection_traffic_count"
FROM "intersection_traffic"
GROUP BY time(1m), "城市名称", "路口名称"
END
该语句将在 traffic_data 数据库中创建一个名为 1_minute_intersection_traffic_count 的数据表,用于存储每分钟车辆数量的统计结果,结果将按照 城市名称 和 路口名称 进行分组,存储时会以 UTC 时间为准。
查询每分钟车辆数量统计结果的示例 InfluxQL 语句:
SELECT COUNT("count") AS "车辆数量"
FROM "traffic_data"."one_month"."1_minute_intersection_traffic_count"
WHERE time >= now() - 30m AND "城市名称" = 上海 AND "路口名称" = 人民广场
GROUP BY time(1m)
该语句将返回最近 30 分钟内,上海人民广场这个路口每分钟的车辆数量统计结果。
Q3 在数据达到1亿条时,统计某个城市每个月的车辆数量,耗时大约秒?统计某一个路口每天的车辆数量,耗时大约多少秒?
InfluxDB 的查询性能受多个因素影响,如数据量、查询条件、索引和硬件配置等。因此,无法给出具体的耗时估计。但是,以下是一些可以提高查询性能的建议:
使用适当的时间范围进行查询:尽可能缩小查询的时间范围,可以减少需要扫描的数据量。
创建索引:在查询字段上创建索引,可以加快查询速度。可以在 InfluxDB 中创建索引,例如:
CREATE INDEX ON "traffic_data"."one_month"."1_minute_intersection_traffic_count"("城市名称")
该语句将在 1_minute_intersection_traffic_count 数据表中创建一个 城市名称 字段的索引。
使用合适的硬件配置:InfluxDB 的查询性能还受到硬件配置的影响,建议使用具有足够计算能力和存储容量的服务器或云服务。
基于以上建议,在数据量达到1亿条时,如果对某个城市每个月的车辆数量进行统计,可能需要几秒甚至几十秒的时间,而统计某一个路口每天的车辆数量可能需要更长的时间。然而,实际耗时取决于具体的查询条件、硬件配置和数据库性能。
Q4 最快能到多少?你可以租赁云服务器,给一个部署方案
InfluxDB 的查询性能取决于多个因素,如查询条件、数据量、索引和硬件配置等。在实际生产环境中,可以通过以下方式来提高 InfluxDB 的查询性能,从而缩短查询时间:
选择合适的硬件配置:建议选择 CPU、内存和磁盘容量都比较高的云服务器或物理服务器,并将 InfluxDB 部署在 SSD 存储设备上,以确保高速读写。
- 创建索引:在查询字段上创建索引,可以显著加速查询。因此,在设计数据表时,应根据实际需要创建索引。
- 选择适当的时间范围:尽量缩小查询时间范围,以减少需要扫描的数据量。
- 使用查询优化:InfluxDB 提供了一些查询优化功能,如 limit、time() 函数等,可以加速查询。
基于以上建议,如果使用高性能的硬件和合理的索引,可以在数百毫秒的时间内完成查询。但是,实际查询性能仍然受到多个因素的影响,例如查询的数据量和查询条件等。
针对本次问题,如果需要在云服务器上部署 InfluxDB,建议选择在亚洲地区较为靠近自己所在地的云服务商,例如阿里云、腾讯云等。在选择云服务器时,可以选择具有高性能 CPU、大内存和高速 SSD 存储的实例,并根据实际需要选择合适的存储容量。在 InfluxDB 的部署中,还需要考虑到监控、备份、故障恢复等方面的问题,以确保系统的高可用性和可靠性。
Q5 使用 go 实现刚才例子中数据的写入和查询,发布为 api
好的,这里提供一个使用 Golang 语言实现数据写入和查询的示例代码,并使用 Gin 框架将其发布为 API。
- 数据库连接 首先,需要引入 github.com/influxdata/influxdb-client-go 包,并创建一个 InfluxDB 客户端。
import (
"time"
"github.com/influxdata/influxdb-client-go/v2"
)
// InfluxDB 数据库连接信息
const (
influxUrl = "http://localhost:8086"
influxToken = "your_token"
influxOrg = "your_org"
influxBucket = "your_bucket"
)
// 创建 InfluxDB 客户端
func createInfluxClient() influxdb2.Client
client := influxdb2.NewClient(influxUrl, influxToken)
return client
- 数据写入 在进行数据写入之前,需要先定义数据结构,这里我们定义一个名为 TrafficData 的结构体,包含城市名称、路口名称、车辆号牌、红绿灯状态、通行速度和时间戳。
// TrafficData 交通数据结构体
type TrafficData struct
CityName string `influx:"city_name"`
Intersection string `influx:"intersection"`
LicensePlate string `influx:"license_plate"`
LightStatus string `influx:"light_status"`
Speed float64 `influx:"speed"`
Timestamp time.Time `influx:"time"`
然后,我们定义一个数据写入函数 writeData,接收一个 TrafficData 结构体的切片作为参数,将数据写入 InfluxDB 数据库中。
// 写入 TrafficData 数据
func writeData(data []TrafficData) error
client := createInfluxClient()
defer client.Close()
// 创建写入器
writeAPI := client.WriteAPIBlocking(influxOrg, influxBucket)
// 将 TrafficData 数据写入数据库
for _, item := range data
p := influxdb2.NewPointWithMeasurement("traffic_data").
AddTag("city_name", item.CityName).
AddTag("intersection", item.Intersection).
AddTag("license_plate", item.LicensePlate).
AddTag("light_status", item.LightStatus).
AddField("speed", item.Speed).
SetTime(item.Timestamp)
writeAPI.WritePoint(p)
return nil
- 数据查询 接下来,我们定义一个数据查询函数 queryData,用于根据查询条件从 InfluxDB 数据库中查询数据。
// 根据查询条件查询 TrafficData 数据
// 根据查询条件查询 TrafficData 数据
func queryData(cityName string, startTime, endTime time.Time) ([]TrafficData, error)
client := createInfluxClient()
defer client.Close()
// 创建查询器
queryAPI := client.QueryAPI(influxOrg)
// 构建查询语句
query := fmt.Sprintf(
`from(bucket:"%s")
|> range(start: %d, stop: %d)
|> filter(fn: (r) => r._measurement == "traffic_data"`,
influxBucket,
startTime.UnixNano(),
endTime.UnixNano(),
)
if cityName != ""
query += fmt.Sprintf(` and r.city_name == "%s"`, cityName)
query += ")"
// 执行查询
result, err := queryAPI.Query(context.Background(), query)
if err != nil
return nil, err
// 处理查询结果
var data []TrafficData
for result.Next()
record := result.Record()
fields := record.Values()
timestamp := fields["_time"].(time.Time)
city := fields["city_name"].(string)
intersection := fields["intersection"].(string)
plate := fields["license_plate"].(string)
light := fields["light_status"].(string)
speed := fields["speed"].(float64)
data = append(data, TrafficData
CityName: city,
Intersection: intersection,
LicensePlate: plate,
LightStatus: light,
Speed: speed,
Timestamp: timestamp,
)
return data, nil
这个方法接受三个参数:cityName 表示要查询的城市名称,startTime 和 endTime 表示要查询的时间范围。它会根据这些条件构建查询语句,执行查询并将结果转换为 TrafficData 数组。如果查询出错,会返回一个错误。
- 主函数
func main()
// 创建 InfluxDB 客户端
client := influxdb2.NewClient(influxUrl, influxToken)
defer client.Close()
// 创建 Gin 实例
r := gin.Default()
// 定义数据写入接口
r.POST("/traffic", func(c *gin.Context)
// 解析请求参数
var data []TrafficData
if err := c.BindJSON(&data); err != nil
c.JSON(http.StatusBadRequest, gin.H"error": err.Error())
return
// 写入 TrafficData 数据
if err := writeData(data); err != nil
c.JSON(http.StatusInternalServerError, gin.H"error": err.Error())
return
c.Status(http.StatusOK)
)
// 定义数据查询接口
r.GET("/traffic", func(c *gin.Context)
// 解析请求参数
cityName := c.Query("city_name")
startTime, err := time.Parse(time.RFC3339, c.Query("start_time"))
if err != nil
c.JSON(http.StatusBadRequest, gin.H"error": "invalid start_time")
return
endTime, err := time.Parse(time.RFC3339, c.Query("end_time"))
if err != nil
c.JSON(http.StatusBadRequest, gin.H"error": "invalid end_time")
return
// 根据查询条件查询 TrafficData 数据
result, err := queryData(cityName, startTime, endTime)
if err != nil
c.JSON(http.StatusInternalServerError, gin.H"error": err.Error())
return
c.JSON(http.StatusOK, result)
)
// 启动 HTTP 服务
if err := r.Run(":8080"); err != nil
log.Fatal(err)
Q6 你知道 tdengine 吗
是的,我了解 TDengine。TDengine是一个开源的时序数据库,最初由中国公司TD Tech开发并维护。它的特点是高性能、高可用性、高稳定性和高扩展性,适合处理大量的时序数据。TDengine支持SQL查询、数据备份和恢复、集群管理等功能,并提供了C、Java、Python等多种编程语言的API。在工业物联网、金融交易、能源管理等领域得到了广泛应用。
Q7 使用 tdegine 如何刚才例子中的数据表
使用TDengine创建类似的时序数据表,可以按照以下步骤操作:
-
安装TDengine:根据官方文档进行安装和配置。
-
创建数据库:登录TDengine客户端,并执行以下命令来创建数据库:
create database traffic_data;
- 创建数据表:执行以下命令来创建 TrafficData 表:
create table traffic_data (
ts timestamp,
city binary(20),
intersection binary(20),
license_plate binary(10),
light_status binary(10),
speed float
) tags (city, intersection) ;
这个命令创建了一个名为 traffic_data 的数据表,包含六个字段:ts、city、intersection、license_plate、light_status 和 speed。其中,ts 是时间戳字段,city 和 intersection 是标签,用于对数据进行分组。tags(city, intersection) 语句将这两个字段定义为标签。
- 插入数据:使用 insert 语句将数据插入 TrafficData 表。假设要插入一条记录,可以执行以下命令:
insert into traffic_data
using traffic_data.tags(city, intersection)
values(now, 上海, 南京路口, 沪A12345, 红灯, 50);
这个命令将一条数据插入 TrafficData 表中,同时指定了标签值。其中,now 表示当前时间戳,上海 和 南京路口 分别表示城市和路口名称,沪A12345 是车牌号码,红灯 是红绿灯状态,50 是通行速度。
- 查询数据:使用 select 语句查询 TrafficData 表中的数据。例如,可以执行以下命令来查询所有车牌号码以 沪A 开头的记录:
select * from traffic_data where license_plate like 沪A%;
这个命令将返回所有车牌号码以 沪A 开头的记录,包括时间戳、城市名称、路口名称、车牌号码、红绿灯状态和通行速度。
Q8 按天、周、日、分钟的路口车辆数量查询
要查询按天、周、月、分钟的路口车辆数量,可以使用TDengine的时间聚合函数,例如按天聚合使用 date_trunc 函数,按周聚合使用 date_trunc(week, ts) 函数,按月聚合使用 date_trunc(month, ts) 函数,按分钟聚合使用 date_trunc(minute, ts) 函数。下面是查询样例:
按天查询某路口的车辆数量:
select date_trunc(day, ts) as day, city, intersection, count(*) as total_count
from traffic_data
where city = 上海 and intersection = 南京路口
group by day, city, intersection
order by day;
按周查询某路口的车辆数量:
select date_trunc(week, ts) as week, city, intersection, count(*) as total_count
from traffic_data
where city = 上海 and intersection = 南京路口
group by week, city, intersection
order by week;
按月查询某路口的车辆数量:
select date_trunc(month, ts) as month, city, intersection, count(*) as total_count
from traffic_data
where city = 上海 and intersection = 南京路口
group by month, city, intersection
order by month;
按分钟查询某路口的车辆数量:
select date_trunc(minute, ts) as minute, city, intersection, count(*) as total_count
from traffic_data
where city = 上海 and intersection = 南京路口
group by minute, city, intersection
order by minute;
以上查询语句中,where 子句用于限定查询条件,group by 子句用于按时间聚合和按城市路口分组,order by 子句用于按时间排序。count(*) 函数用于计算车辆数量。这些语句将返回按天、周、月、分钟聚合的某个路口的车辆数量统计结果。
Q9 统计最近5分钟,最近1小时,最近24小时,最近48小时的车辆数量,统计5分钟内,30分钟内,1小时内最繁忙的20个路口
要查询最近5分钟、最近1小时、最近24小时、最近48小时的车辆数量,可以使用 now() 函数获取当前时间,然后减去对应时间间隔得到起始时间,再按时间进行分组聚合。下面是查询样例:
统计最近5分钟的车辆数量:
SELECT COUNT(*) FROM traffic
WHERE time > NOW() - 5m
GROUP BY city, intersection
统计最近1小时的车辆数量:
SELECT COUNT(*) FROM traffic
WHERE time > NOW() - 1h
GROUP BY city, intersection
统计最近24小时的车辆数量:
SELECT COUNT(*) FROM traffic
WHERE time > NOW() - 24h
GROUP BY city, intersection
统计最近48小时的车辆数量:
SELECT COUNT(*) FROM traffic
WHERE time > NOW() - 48h
GROUP BY city, intersection
统计5分钟内、30分钟内、1小时内最繁忙的20个路口,可以结合时间窗口函数和TDengine的TOP-K查询来实现。
统计5分钟内最繁忙的20个路口:
SELECT city, intersection, COUNT(*) FROM traffic
WHERE time > NOW() - 5m
GROUP BY city, intersection
ORDER BY COUNT(*) DESC LIMIT 20
统计30分钟内最繁忙的20个路口:
SELECT city, intersection, COUNT(*) FROM traffic
WHERE time > NOW() - 30m
GROUP BY city, intersection
ORDER BY COUNT(*) DESC LIMIT 20
统计1小时内最繁忙的20个路口:
SELECT city, intersection, COUNT(*) FROM traffic
WHERE time > NOW() - 1h
GROUP BY city, intersection
ORDER BY COUNT(*) DESC LIMIT 20
需要注意的是,在进行TOP-K查询时,需要按照COUNT(*)的值进行降序排序,然后取前20个结果。如果在这些时间段内有相同数量的车辆通过某个路口,那么这些路口都会出现在TOP-K结果中。
Q10 优化统计5分钟内,30分钟内,1小时内最繁忙的20个路口
对于统计5分钟内、30分钟内、1小时内最繁忙的20个路口,可以通过TDengine的实时聚合功能来进行优化。TDengine支持在数据写入时实时计算聚合结果,然后将结果存储在聚合表中。这样,在进行聚合查询时,只需要从聚合表中读取结果,而不需要重新计算。
以下是对统计5分钟内、30分钟内、1小时内最繁忙的20个路口的优化:
创建聚合表:
CREATE TABLE traffic_agg
(city NCHAR(64), intersection NCHAR(64), timestamp TIMESTAMP, count INT, interval INT, PRIMARY KEY(city, intersection, timestamp, interval))
在写入数据时实时计算聚合结果,将结果存储到聚合表中。以下是写入数据时计算5分钟聚合结果的示例:
INSERT INTO traffic_agg(city, intersection, timestamp, count, interval)
SELECT city, intersection, FLOOR(time TO 5m), COUNT(*), 5 FROM traffic
GROUP BY city, intersection, FLOOR(time TO 5m)
在进行聚合查询时,只需要从聚合表中读取结果,而不需要重新计算。以下是从聚合表中读取5分钟聚合结果的示例:
SELECT city, intersection, count FROM traffic_agg
WHERE timestamp > NOW() - 5m
AND interval = 5
ORDER BY count DESC
LIMIT 20
以上优化方案可以提高查询的效率,减少查询的响应时间。由于聚合表是在写入时计算聚合结果,因此需要根据实际业务需求,选择合适的聚合粒度和计算频率,以确保聚合表中的数据能够满足查询需求。
Q11 再介绍一下实时聚合计算,要怎么部署
实时聚合计算是指在数据写入时,对数据进行聚合计算,并将聚合结果实时存储到聚合表中,从而可以提高查询效率。TDengine提供了实时聚合计算功能,用户可以在创建表时,通过设置实时计算参数来开启实时聚合计算功能。
以下是在TDengine中如何开启实时聚合计算功能的步骤:
- 创建聚合表 首先需要创建聚合表,聚合表的定义和普通表类似,需要指定表名、列名、主键等信息。在创建表时,需要设置实时计算参数,包括计算粒度、计算函数、聚合表名称等。
例如,以下是创建一个traffic实时聚合表的示例:
CREATE TABLE traffic_agg
(city NCHAR(64), intersection NCHAR(64), timestamp TIMESTAMP, count INT, interval INT,
PRIMARY KEY(city, intersection, timestamp, interval))
WITH
realtime=1,
source=traffic,
granularity=5m,
function=count(*),
filter=city=Shanghai
在上述代码中,通过设置realtime=1,开启了实时计算功能;通过设置source=traffic,指定了聚合表的数据源为traffic表;通过设置granularity=5m,指定了聚合粒度为5分钟;通过设置function=count(),指定了计算函数为count(),即统计每个5分钟内的记录数;通过设置filter=city=Shanghai,指定了计算的数据过滤条件,即只计算城市为Shanghai的数据。
- 写入数据 在写入数据时,TDengine会自动对数据进行实时聚合计算,并将聚合结果存储到聚合表中。以下是向traffic表中写入数据的示例:
INSERT INTO traffic(city, intersection, plate_number, light_status, speed, time)
VALUES (Shanghai, Intersection1, 沪A88888, 1, 50, NOW())
在上述代码中,当写入一条数据时,TDengine会自动对该数据进行实时聚合计算,并将聚合结果存储到聚合表traffic_agg中。
- 查询聚合表 在查询聚合表时,可以直接从聚合表中读取聚合结果,而不需要重新计算。以下是查询聚合表traffic_agg中某个时间范围内的聚合结果的示例:
SELECT city, intersection, count FROM traffic_agg
WHERE timestamp > 2023-02-16 00:00:00 AND timestamp <= 2023-02-16 00:05:00
AND interval = 300
ORDER BY count DESC
LIMIT 20
在上述代码中,通过设置timestamp和interval条件,可以查询某个时间范围内的聚合结果;通过设置ORDER BY和LIMIT条件,可以按照聚合结果进行排序和分页。
以上是关于ChatGPT对话数据备份的主要内容,如果未能解决你的问题,请参考以下文章