饱和预测——大作业系列
Posted Love And Program
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了饱和预测——大作业系列相关的知识,希望对你有一定的参考价值。
👦👦一个帅气的boy,你可以叫我Love And Program
🖱 ⌨个人主页:Love And Program的个人主页
💖💖如果对你有帮助的话希望三连💨💨支持一下博主

饱和预测
☝☝前言
本文采用Prophet模型对时间序列进行饱和预测,饱和预测通俗一点理解就是在对一系列参数进行预测时会达到一个顶点,我们需要研究的就是预测这个饱和点。
👏👏详解
Prophet允许我们使用逻辑斯蒂模型进行预测,并具有一定承载能力,本文数据集采用维基百科R语言访问的日志次数来详细介绍。
分析数据
首先打开数据集对其进行分析,共分为ds和y两行
"ds","y"
"2008-01-30",5.97635090929793
"2008-01-16",6.04973345523196
"2008-01-17",6.01126717440416
"2008-01-14",5.95324333428778
"2008-01-15",5.91079664404053
"2008-01-12",5.40717177146012
...
然后读取数据并手动设置一个承载能力cap:8.5
(注意:cap不能随便设定,需要根据市场数据或专业知识设定,也可以是一个序列,并不是恒定的)
df = pd.read_csv('example_wp_log_R.csv')
df['cap'] = 8.5
数据集划分
将训练集和测试集分为9:1两份
test_ratio = 0.1
test_size = int(df.shape[0]*test_ratio)
train_size = df.shape[0] - test_size
train_set = df[:train_size]
test_set = df[train_size:]
print(test_set)
建立模型
上面已经说过,本文使用逻辑斯蒂模型进行预测,所以growth='logistic'这句代码指定模型,然后用fit函数进行训练
m = Prophet(growth='logistic')
m.fit(df)
模型预测
我们想预测未来测试集变化则需要先制作一个数据框,然后指定未来容量,这里我们加入一个序列。
future = m.make_future_dataframe(periods=test_size)
future['cap'] = 8.5
future['cap1'] = 9.0
fcst = m.predict(future)
fig = m.plot(fcst)
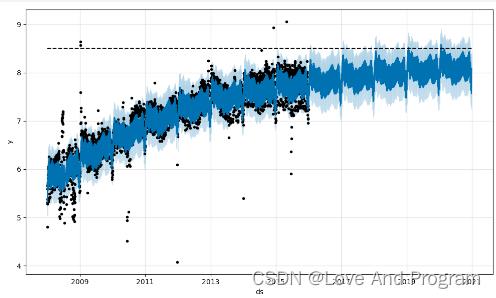
我们可以看到虚线为即将饱和的地方。

同样,我们为了更清晰看到数据预测结果,我们也可以单独拿出预测结果来与原数据进行比较.
WeiLai = fcst[['yhat']][train_size:]
plt.plot(Normal)
plt.plot(WeiLai,color="red")
plt.show()
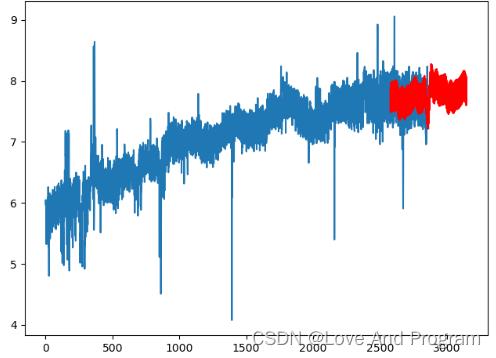

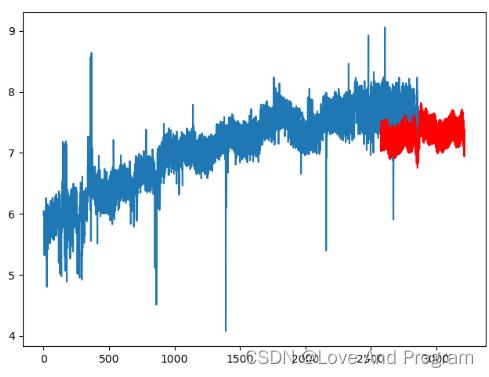
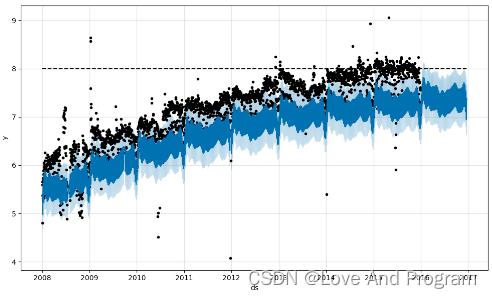
我们也可以预测未来一年的信息,但是你要知道,预测的越久它的准确性就越低,更改代码位置
future = m.make_future_dataframe(periods=356)
可以看出第二张图片继续趋于饱和。
源码
import pandas as pd
import numpy as np
from prophet import Prophet
import matplotlib.pyplot as plt
df = pd.read_csv('example_wp_log_R.csv')
Normal = pd.DataFrame(df,columns=['y'])
df['cap'] = 8.5
test_ratio = 0.1
test_size = int(df.shape[0]*test_ratio)
train_size = df.shape[0] - test_size
train_set = df[:train_size]
test_set = df[train_size:]
print(test_set)
m = Prophet(growth='logistic')
m.fit(df)
future = m.make_future_dataframe(periods=test_size)
future['cap'] = 8.5
future['cap1'] = 9.0
fcst = m.predict(future)
fig = m.plot(fcst)
plt.show()
WeiLai = fcst[['yhat']][train_size:]
plt.plot(Normal)
plt.plot(WeiLai,color="red")
plt.show()
这是一个相对简单的大作业,只能说到及格,但是胜在简单易懂,如果实在来不及可以用这个哦,对你有帮助的话可以给博主点赞收藏支持一下咩 🥰🥰
以上是关于饱和预测——大作业系列的主要内容,如果未能解决你的问题,请参考以下文章