大数据:Spark Standalone 集群调度多Master节点的可用性
Posted raintungli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据:Spark Standalone 集群调度多Master节点的可用性相关的知识,希望对你有一定的参考价值。
1. Master 单节点可用性
Master节点在Spark中所承载的作用是分配Application到Worker节点,维护Worker节点,Driver,Application的状态。 在Spark中,Master本身也提供了基于硬盘的单节点的可用性,也就是可以直接通过重启Master,Master通过读取硬盘里保存的状态,进行单节点的恢复。In order to enable this recovery mode, you can set SPARK_DAEMON_JAVA_OPTS in spark-env using this configuration:
| System property | Meaning |
|---|---|
spark.deploy.recoveryMode | Set to FILESYSTEM to enable single-node recovery mode (default: NONE). |
spark.deploy.recoveryDirectory | The directory in which Spark will store recovery state, accessible from the Master's perspective. |
备注:恢复节点的方式与多节点可用性后续的处理方式基本类似,就不在此具体讨论细节了
2. Master 多节点可用性
单节点的问题很明显,虽然有恢复的方案,很明显在重启的过程中,是无法继续对资源调度和分配的,而磁盘也是具有单节点特性(假使没有构建磁盘阵列),同样也不具备高可用性的特点 Spark引入了多Master节点来提高集群可用性 设置多Master节点的方式:-Dspark.deploy.recoveryMode=ZOOKEEPER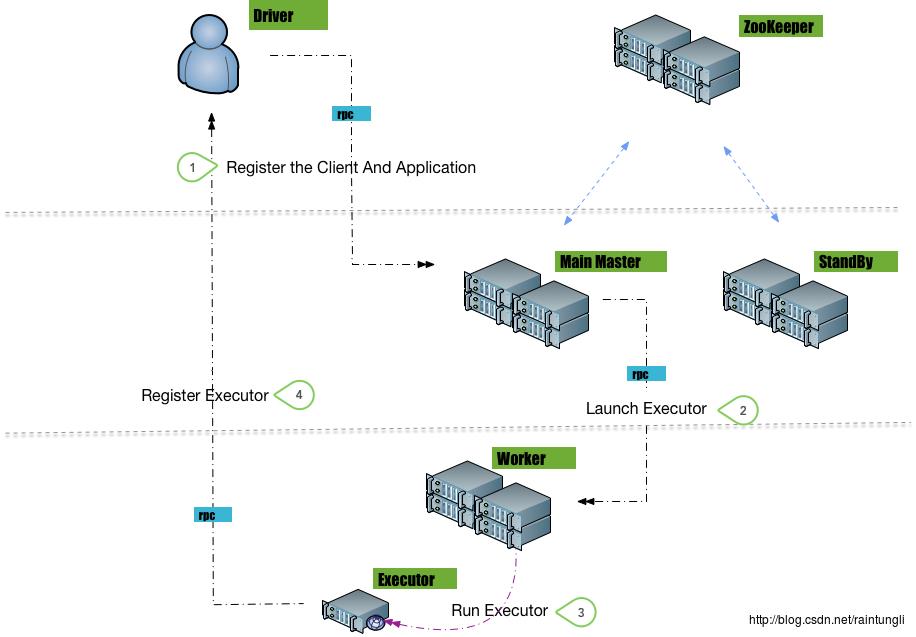
2.1 StandBy Master 节点
在Spark的多Master节点设计中,分为两个角色,一个是主Master节点提供服务,另一个角色是备用Master节点 当Master节点处于备用的状态时候,是 不提供服务的 ,备用节点只是在处于等待状态,只有当主Master节点crash掉后,备用节点才升级成为主Master提供服务主备节点互相不感知,不提供负载均衡,不是对等节点,在上图可以看到每个提交任务的Client并不提交任务到StandBy节点
2.2 ZooKeeper 选举Main Master节点
在Master多节点中,只有Main Master才是提供服务的,这个设计就象选举Leader,这种方式非常适合使用Zookeeper的Watch模式。Spark并没有直接使用Zookeeper,而是使用了curator 框架(基于Zookeeper)进行Master的选举。由于Zookeeper的操作比较底层,操作的是数据结构和节点的状态,curator在上面封装了一层,以应用与不同的应用情景。
在使用Leader模式下,curator的框架开发代码非常简单。使用LeaderLatch, 实现LeaderLatchListener的监听器
override def isLeader()
synchronized
// could have lost leadership by now.
if (!leaderLatch.hasLeadership)
return
logInfo("We have gained leadership")
updateLeadershipStatus(true)
override def notLeader()
synchronized
// could have gained leadership by now.
if (leaderLatch.hasLeadership)
return
logInfo("We have lost leadership")
updateLeadershipStatus(false)
isLeader 和 notLeader 分别代表成为Leader或者失去Leader, 在Spark的ZookeeperLeaderElectionAgent.scala里跟新leader的状态
private def updateLeadershipStatus(isLeader: Boolean)
if (isLeader && status == LeadershipStatus.NOT_LEADER)
status = LeadershipStatus.LEADER
masterInstance.electedLeader()
else if (!isLeader && status == LeadershipStatus.LEADER)
status = LeadershipStatus.NOT_LEADER
masterInstance.revokedLeadership()
调用的是在Master.scala的
override def electedLeader()
self.send(ElectedLeader)
override def revokedLeadership()
self.send(RevokedLeadership)
也就是发了消息ElectedLeader, RevokeLeaderShip 给自己的Netty
Zookeeper上默认的leader节点路径 /spark/leader_election
ls /spark/leader_election
[_c_6b494d00-cf91-4d69-8828-942377bafdf1-latch-0000000217, _c_c1f4c10f-9479-4a55-b660-0497c0b54f89-latch-0000000218]
前面应该是UUID后面有一个序列号,由后面的序列号前后来决定谁是 leader, 而序列号前后的生成取决于Master连接zookeeper的顺序,熟悉zookeeper的知道这些节点是ephemeral节点。
2.3 StandBy Master 节点的恢复
在前面章节里已经描述了如何选为Main Master, 当Main Master 当机后,备用的Master通过选举成为了 Main Master,备用的Master Netty收到了ElectedLeader的消息,在成为主Master节点前,先检查集群状态并准备进行恢复 case ElectedLeader =>
val (storedApps, storedDrivers, storedWorkers) = persistenceEngine.readPersistedData(rpcEnv)
state = if (storedApps.isEmpty && storedDrivers.isEmpty && storedWorkers.isEmpty)
RecoveryState.ALIVE
else
RecoveryState.RECOVERING
logInfo("I have been elected leader! New state: " + state)
if (state == RecoveryState.RECOVERING)
beginRecovery(storedApps, storedDrivers, storedWorkers)
recoveryCompletionTask = forwardMessageThread.schedule(new Runnable
override def run(): Unit = Utils.tryLogNonFatalError
self.send(CompleteRecovery)
, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS)
2.3.1 获取具体的信息
首先从持久化层获取Application, Drivers, Worker 的信息,也就是通过Curator 的框架获取原Master保存的信息Zookeeper上默认的master状态路径 /spark/master_status
ls /spark/master_status
[worker_worker-20170329184022-192.168.121.101-55109, worker_worker-20170330035822-192.168.121.102-41307]
Apps, Driver, Workers 的信息都会被保存在master_status节点里,而每个子节点的内容就是序列化过的ApplicationInfo, DriverInfo, WorkInfo
获选的主Master通过获取Zookeeper上的节点的值,反序列化重构Application, Driver, Worker的信息
2.3.2 恢复Application,Driver,Workers
private def beginRecovery(storedApps: Seq[ApplicationInfo], storedDrivers: Seq[DriverInfo],
storedWorkers: Seq[WorkerInfo])
for (app <- storedApps)
logInfo("Trying to recover app: " + app.id)
try
registerApplication(app)
app.state = ApplicationState.UNKNOWN
app.driver.send(MasterChanged(self, masterWebUiUrl))
catch
case e: Exception => logInfo("App " + app.id + " had exception on reconnect")
for (driver <- storedDrivers)
// Here we just read in the list of drivers. Any drivers associated with now-lost workers
// will be re-launched when we detect that the worker is missing.
drivers += driver
for (worker <- storedWorkers)
logInfo("Trying to recover worker: " + worker.id)
try
registerWorker(worker)
worker.state = WorkerState.UNKNOWN
worker.endpoint.send(MasterChanged(self, masterWebUiUrl))
catch
case e: Exception => logInfo("Worker " + worker.id + " had exception on reconnect")
2.3.2.1 恢复Application
在前面一章说过如何分配Executor,里面也说到了ApplicationInfo 结构。在Master做Recovery的时候,把保存在Zookeeper里的Applications 重新在Master里重新注册 这里有几个注意点: 1. Zookeeper 里保存的是正在运行的Applications,但在Spark里并没有进行细粒度的控制,只要是在运行的Applications,都会 重新进行被分配executor,哪怕正在分配或者已经在计算了。 2. 注册完Application 并没有马上进行Application的调度,直到恢复完Worker,Driver才开始进行进行 private def completeRecovery()
// Ensure "only-once" recovery semantics using a short synchronization period.
if (state != RecoveryState.RECOVERING) return
state = RecoveryState.COMPLETING_RECOVERY
// Kill off any workers and apps that didn't respond to us.
workers.filter(_.state == WorkerState.UNKNOWN).foreach(removeWorker)
apps.filter(_.state == ApplicationState.UNKNOWN).foreach(finishApplication)
// Reschedule drivers which were not claimed by any workers
drivers.filter(_.worker.isEmpty).foreach d =>
logWarning(s"Driver $d.id was not found after master recovery")
if (d.desc.supervise)
logWarning(s"Re-launching $d.id")
relaunchDriver(d)
else
removeDriver(d.id, DriverState.ERROR, None)
logWarning(s"Did not re-launch $d.id because it was not supervised")
state = RecoveryState.ALIVE
schedule()
logInfo("Recovery complete - resuming operations!")
在completeRecovery 的函数里,只有当Master的节点的状态RecoveryState.ALIVE的时候,Master才调用了Schedule重新调度已经注册的Application
2.3.2.2 恢复Worker
第一步:注册Worker,这里只是简单的确认了Worker地址(ip+port)的格式是否正确和是否已经注册过了。 第二步:设置Worker的状态为UNKNOW 第三步:发送MasterChange消息给Worker 第四步:Worker将自己的Application ID, Executor的信息WorkerSchedulerStateResponse发回给Master 第五步:Master的跟新信息中ApplicationInfo中的Executor信息第三步到第五步都是通过消息来异步消息恢复的,在没有收到WorkerScheduleStateResponse回复,是无法开始准确进行Application调度的,此时的Worker的里的信息不准确,例如用了多少核
2.3.3 完成Recovery
因为要完成worker信息的传递,而Recovery的过程是在Netty的接收ElectedLeader消息的线程中进行的,而比如Worker汇报消息的不能被堵塞,在这里Master起了一个定时任务去触发任务的完成,定时任务的时间就是worker连接的超时时间,在这里的前提是所有的workers会在超时间段内回复消息。recoveryCompletionTask = forwardMessageThread.schedule(new Runnable
override def run(): Unit = Utils.tryLogNonFatalError
self.send(CompleteRecovery)
, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS)对Master发送了CompleteRecovery的消息,在CompleteRecovery的消息中重新调度了Application。
2.3.4 Recovery中的几个状态
Master节点在recovery中有四个状态:RecoveryState.ALIVE
RecoveryState.RECOVERING
RecoveryState.COMPLETING_RECOVERY
RecoveryState.STANDBY
在整个Recovery的恢复过程中状态是 从 STANDBY => RECOVERING => COMPLETING_RECOVERY => ALIVE 1. 在整个Recovery的恢复过程中可以接受Register Application(但并不进行调度),当然必须Elected_Leader的消息函数块运行完,因为在同一个线程中 2. 在整个Recovery的恢复过程中只有在进入ALIVE的状态,才能进行Application的调度
3 Submit 如何设置多个Master
Spark的master是主和Standby的状态,对submit任务来说,并不能知道目前集群上主Master是那个,提交到Standby的master并不接受任务,容易导致提交任务失败。 Spark 提供了一种简单的方式: 在submit 或者在sparkconf里可以设置多个Master, 格式注意是用逗号分隔--master spark://raintungmaster:7077,raintungslave1:7077当然你也可以设置一个局域网的DNS,通过 healthcheck来判断哪个Master挂了,DNS就指向谁
以上是关于大数据:Spark Standalone 集群调度多Master节点的可用性的主要内容,如果未能解决你的问题,请参考以下文章