RabbitMQ整体架构
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RabbitMQ整体架构相关的知识,希望对你有一定的参考价值。
参考技术A如下图,生产者和消费者通过交换器绑定,消息从生产者到达交换器后按照交换器指定的规则发送的特定的队列中,消费者再去队列中消费。
RabbitMQ常用的交换器类型有: fanout 、direct 、topic 、headers 四种。
会把所有发送到该交换器的消息路由到所有与该交换器绑定的队列中,就像风扇一样,把消息“吹到”所有地方。
direct类型的交换器路由规则很简单,它会把消息路由到那些BindingKey和RoutingKey完全匹配的队列中。
topic类型的交换器在direct匹配规则上进行了扩展,也是将消息路由到BindingKey和RoutingKey相匹配的队列中,这里的匹配规则稍微不同,它约定:
BindingKey和RoutingKey一样都是由"."分隔的字符串;BindingKey中可以存在两种特殊字符“ ”和“#”,用于模糊匹配,其中" "用于匹配一个单词,"#"用于匹配多个单词(可以是0个)。
headers类型的交换器不依赖于路由键的匹配规则来路由信息,而是根据发送的消息内容中的headers属性进行匹配。这种类型不建议在生产环境中使用,只需要知道有这种类型就可以了。
RabbitMQ消息有两种类型,持久化消息和非持久化消息,两种消息都会被写入磁盘。
持久化消息在到达队列时写入磁盘,同时会内存中保存一份备份,当内存吃紧时,消息从内存中清除。这会提高一定的性能。
非持久化消息一般只存于内存中,当内存压力大时数据刷盘处理,以节省内存空间。
RabbitMQ存储层包含两个部分,队列索引和消息存储,如下图所示:
索引维护队列的落盘消息的信息,如存储地点、是否已被给消费者接收、是否已被消费者ack等。每个队列都有相对应的索引。
索引使用顺序的段文件来存储,后缀为.idx,文件名从0开始累加,每个段文件中包含固定的segment_entry_count 条记录,默认值是16384。每个index从磁盘中读取消息的时候,至少要在内存中维护一个段文件,所以设置queue_index_embed_msgs_below 值得时候要格外谨慎,一点点增大也可能会引起内存爆炸式增长。
消息以键值对的形式存储到文件中,一个虚拟主机上的所有队列使用同一块存储,每个节点只有一个。存储分为持久化存储(msg_store_persistent)和短暂存储(msg_store_transient)。持久化存储的内容在broker重启后不会丢失,短暂存储的内容在broker重启后丢失。
store使用文件来存储,后缀为.rdq,经过store处理的所有消息都会以追加的方式写入到该文件中,当该文件的大小超过指定的限制(file_size_limit)后,将会关闭该文件并创建一个新的文件以供新的消息写入。文件名从0开始进行累加。在进行消息的存储时,RabbitMQ会在ETS(Erlang TermStorage)表中记录消息在文件中的位置映射和文件的相关信息。
消息(包括消息头、消息体、属性)可以直接存储在index中,也可以存储在store中。最佳的方式是较小的消息存在index中,而较大的消息存在store中。这个消息大小的界定可以通过queue_index_embed_msgs_below 来配置,默认值为4096B。当一个消息小于设定的大小阈值时,就可以存储在index中,这样性能上可以得到优化。一个完整的消息大小小于这个值,就放到索引中,否则放到持久化消息文件中。
如果消息小于这个值,就在索引中存储,也就是存储于<num>.idx索引文件中,如果消息大于这个值就在store中存储,也就是存储在msg_store_persistent目录中的<num>.rdq文件中。
RabbitMQ的架构模型
本章主要讨论RabbitMQ的架构模型,AMQP协议是什么,以及RabbitMQ和AMQP之间的关系,还会讨论消息从生产者发出和送达到消费者这一过程要经历哪些步骤。
RabbitMQ整体上是生产者与消费者模型,主要负责接收、存储、转发消息。
RabbitMQ的整体架构如图2-1所示。
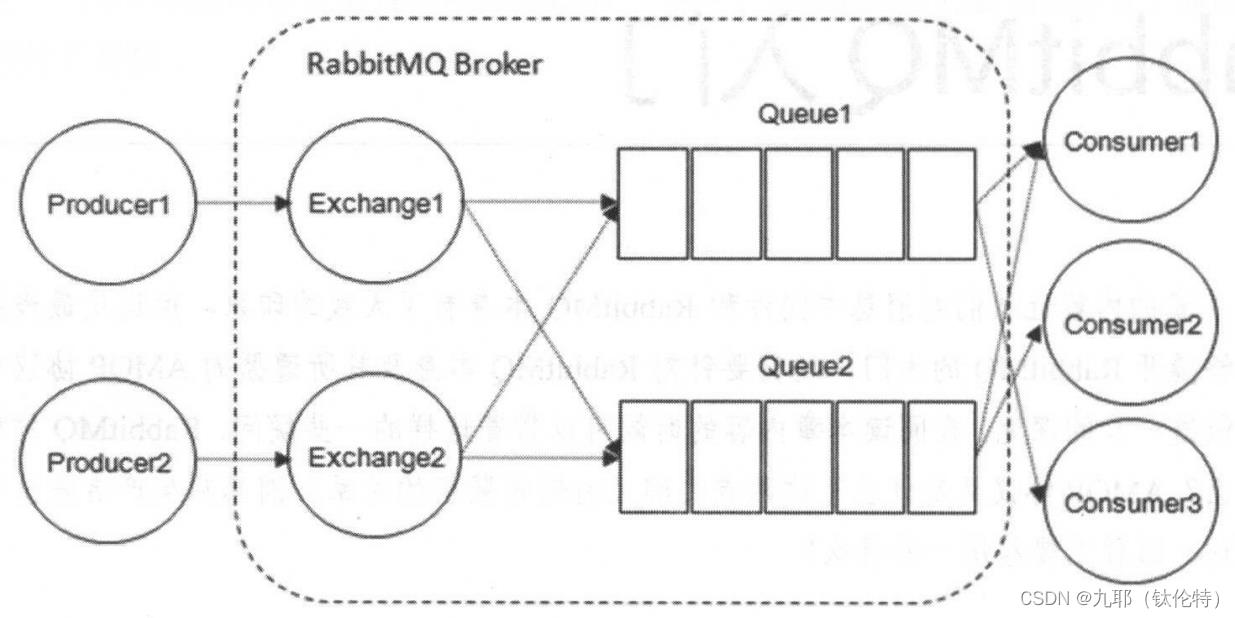
图2-1 RabbitMQ整体模型架构
后面的章节开始对图中的组件进行详细介绍。
2.1 消息生产者-消息消费者-Broker
(1)Producer:生产者,负责创建并投递消息。
生产者创建消息,然后发布到RabbitMQ中。消息一般可以包含2个部分:消息体和标签(Label):
(A)消息体也可以称之为payload,在实际应用中,消息体一般是业务数据,比如JSON字符串。
(B)消息的标签(Label)用来描述消息的信息,包含交换器的名称和路由键。生产者把消息交给RabbitMQ,RabbitMQ之后会根据标签的内容把消息发送给消费者(Consumer)。
(2)Consumer:消费者,负责接收和处理消息。
消费者连接到RabbitMQ服务器并订阅指定的消息队列。消息队列中的消息只保留了消息的消息体(payload),因为在消息路由的过程中,消息的标签(Label)会被丢弃,存入到消息队列中的消息只有消息体,消费者并不知道消息的生产者是谁。
(3)Broker:消息中间件的服务节点。
一个RabbitMQ Broker可以简单地看作是一个RabbitMQ服务节点,一个RabbitMQ服务实例,一个RabbitMQ服务器。
图2-2展示了生产者将消息存入RabbitMQ Broker,以及消费者从RabbitMQ Broker中消费的整个流程。
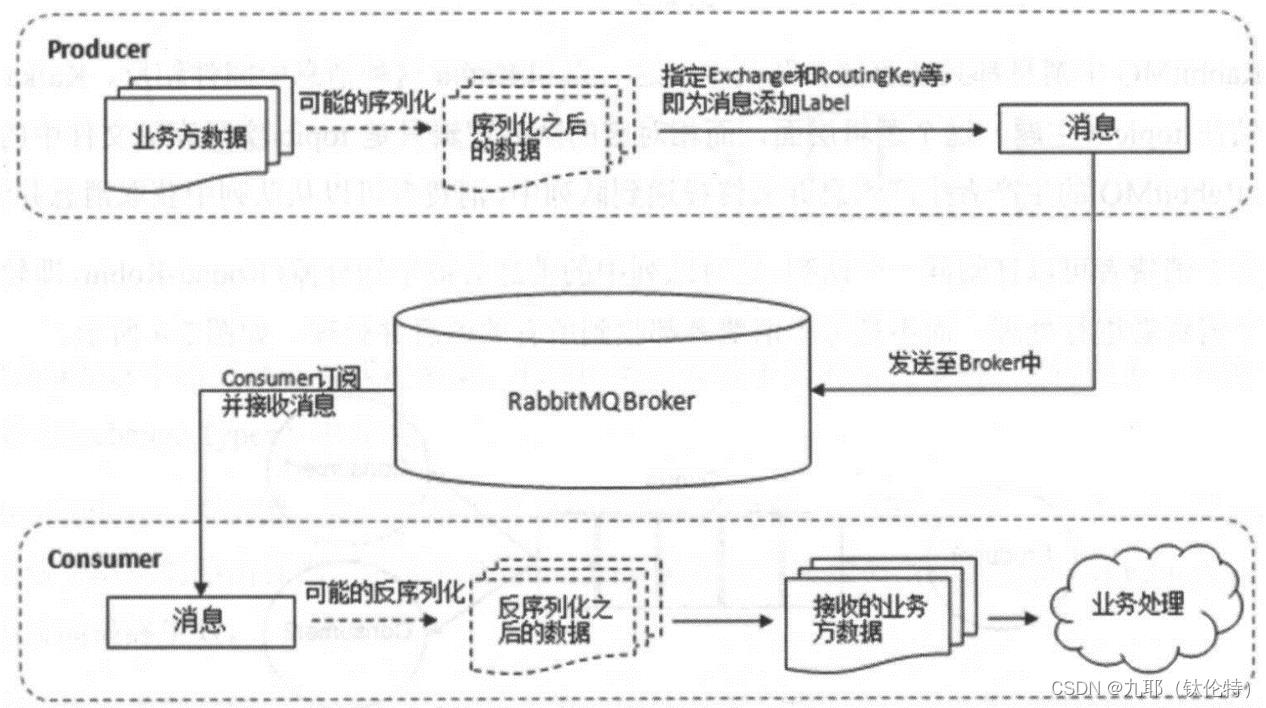
图2-2 消息队列的运转过程
首先生产者将业务数据封装成消息并发送(AMQP协议里对应的命令为Basic.Publish)到Broker中。消费者订阅并接收消息(AMQP协议里对应的命令为Basic.Consume和Basic.Get),获得消息中原始的业务数据后开始加工。为了MQ的运行效率,处理业务数据的线程并不一定和接收消息的线程是同一个线程,消费者进程可以使用A线程去接收消息,存入到内存中(比如使用Java中的BlockingQueue),再使用B线程从内存中读取数据进行业务处理,实现解耦,以异步执行的方式提高整个应用的数据处理效率。
如果你觉的这篇文章对你有用,记得点赞收藏,以防找不到我哦~
以上是关于RabbitMQ整体架构的主要内容,如果未能解决你的问题,请参考以下文章