应用TF-Slim快速实现迁移学习
Posted JeemyJohn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了应用TF-Slim快速实现迁移学习相关的知识,希望对你有一定的参考价值。
作者:张旭
编辑:张欢
这是一篇以实践为主的入门文章,目的在于用尽量少的成本组织起来一套可以训练和测试自己的分类任务的代码,其中就会用到迁移学习,TF-Slim库的内容,所以我们分为下面几个步骤介绍::
什么是迁移学习;
什么是TF-Slim;
TF-Slim实现迁移学习的例程;
应用自己的数据集完成迁移学习。
操作系统:Win10
开发语言:Python3.5
算法:TensorFlow1.1
1
什么是迁移学习:
一般在初始化CNN的卷积核时,使用的是正态随机初始化,此时训练这个网络的话就是在从头训练,然而既然反正都要初始化核参数,那么为什么不干脆拿一个在其他任务中训练好的参数进行初始化呢?一般认为如果一个网络在某个更为复杂的任务上表现优异的话(这需要大量的数据与长时间的训练),那么它的参数是具有比较好的特征抽取能力的,又因为CNN的前几层提取的一般为较低级的特征(边缘,轮廓等),所以这些参数即使换一个任务的话,也会有不错的效果(起码在前几层是这样,而且起码比正态随机初始化要好)。在一个数据量比较大的任务中完成训练的过程就是pre-train,用pre-train的参数初始化一个新的网络,并对这些参数再次训练(微调),使之适用于新任务的过程就是fine-tune。一般情况下,我们会选择ImageNet数据集上训练好的网络,因为它经过大数据量与长时间的训练。好在TensorFlow已经提供了各种pre-train model:
https://github.com/tensorflow/models/tree/master/research/slim

然后我们举个例子说下Google是怎么训练这些模型,在ImageNet数据集上,用128GB内存+8个NVIDIA Tesla K40 GPU训练Inception网络,耗时100个小时,Top1达到73.5%。
2
什么是TF-Slim:
TF-slim是用于定义,训练和评估复杂模型的TensorFlow(tensorflow.contrib.slim)的新型轻量级高级API。可以把它理解为TensorFlow提供的一种更高级的封装吧,其实它和迁移学习没什么关系,只是在后面的内容中会用到,所以在这里提一下。
具体内容可以查看:https://github.com/tensorflow/models/tree/master/research/slim
翻译:http://blog.csdn.net/chaipp0607/article/details/74139895
3
TF-Slim实现迁移学习的例程
在TensorFlow的github网址中提供了一个包含了数据准备+训练+预测的例程—Flowers,它只需我们运行几个脚本或命令行,不需要该任何代码就可以,我们先把这个例程解释一下:
1.准备工作:
首先我们需要在https://github.com/tensorflow/models把TensorFlow-models下载下来,放在本地一个位置上,比如D盘根目录。
2.转化TFRecord文件:
TFRecord文件是一种TensorFlow提供的数据格式,它可以将图片二进制数据和图片其他数据(如标签,尺寸等等)存储在同一个文件中,有种格式更加利于TensorFlow的读取机制。所以我们需要先生成Flowers数据集的TFRecord文件。
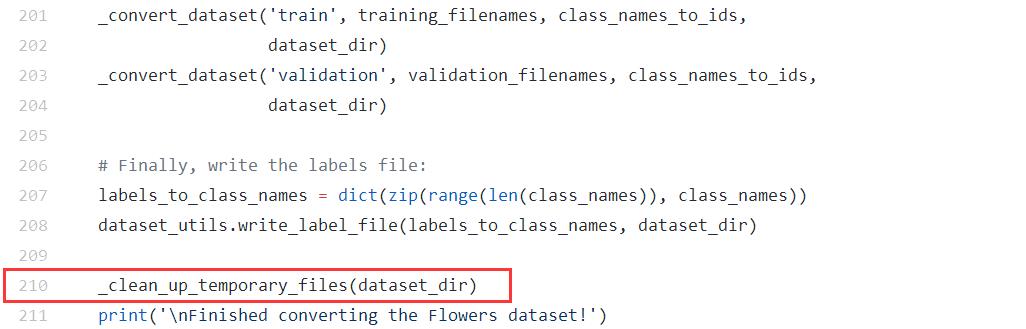
TensorFlow-models内提供了一个download_and_convert_data.py文件,我们可以利用这个代码完成数据准备工作,但是在此之前,建议把download_and_convert_flowers.py文件中的210行代码注释掉,这样一来解压缩之后的原始数据就可以留下来了,这样方便我们查看。
然后我们就可以运行这个文件了,注意一下我们要运行的是download_and_convert_data.py文件,要修改的是download_and_convert_flowers.py文件。因为我的系统是Windows,所以在这里我就直接使用命令行了,使用Linux的同学可以直接运行.sh文件,我们只需要进入slim后执行:
python download_and_convert_data.py --dataset_name=flowers --dataset_dir=D:/models-master/research/slim/flowers_5
其中floewers_5是文件夹的名字,代码将在该文件加内下载flowers数据集的压缩包,解压后生产TFRecord文件,压缩包大小大概有200多M的样子吧。


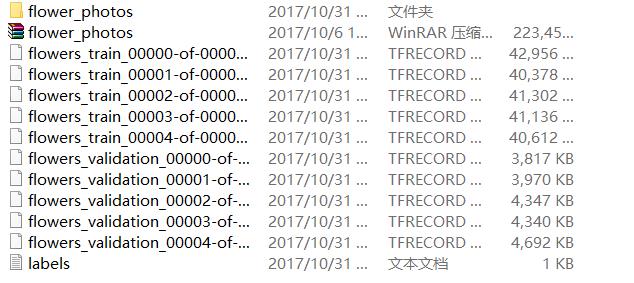
下载完成之后,代码会随机的抽取350张图片组成验证集,剩下的3320张组成训练集,并分别打成5个TFRecord文件。再回到floewers_5文件夹中,我们就可以看到下面这些东西,一个压缩文件,一个解压缩之后的文件夹,10个TFRecord文件和一个labels文件。
3.迁移Inception-V4训练新任务:
数据集准备完成后,我们就可以进行训练,这里使用TF提供的Inception-V4网络,首先我们需要在上面提到的那个图里下载下来Inception-V4模型文件解压缩,我放在了D:\\models-master\\research\\slim\\pre_train下。
然后我们可以直接执行train_image_classifier.py文件:
python train_image_classifier.py
--dataset_name=flowers
--dataset_dir=D:/models-master/research/slim/flowers_5
--checkpoint_path=D:/models-master/research/slim/pre_train/inception_v4.ckpt
--model_name=inception_v4
--checkpoint_exclude_scopes=InceptionV4/Logits,InceptionV4/AuxLogits/Aux_logits
--trainable_scopes=InceptionV4/Logits,InceptionV4/AuxLogits/Aux_logits
--train_dir=D:/models-master/research/slim/flowers_5/my_train
--learning_rate=0.001
--learning_rate_decay_factor=0.76
--num_epochs_per_decay=50
--moving_average_decay=0.9999
--optimizer=adam
--ignore_missing_vars=True
--batch_size=32
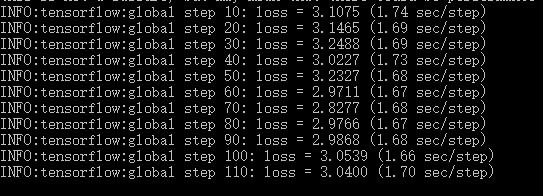
运行结果:
4.准确率验证:
短暂的训练之后,我们就可以测试下验证集上的准确率了,执行eval_image_classifier.py文件:
python eval_image_classifier.py
--dataset_name=flowers
--dataset_dir=D:/models-master/research/slim/flowers_5
--dataset_split_name=validation
--model_name=inception_v4
--checkpoint_path=D:/models-master/research/slim/flowers_5/my_train
--eval_dir=D:/models-master/research/slim/flowers_5/validation_result
--batch_size=32

可以看到,一个5分类数据集经过短暂的训练后,top1只有17%,top5没有意义,必然是1。
4
应用自己的数据集完成迁移学习
在上面我们没有改动一行代码(改了一行是为了方便看数据),就完成了从数据准备到训练再到预测的全部过程,现在终于到了最关键的地方,就是怎么跑通我们自己的数据集,在组织数据的过程中,最天然的方式肯定就是按照数据的类别放进不同的文件夹里,这也就是为什么我们要选择Flowers这个数据集,下面我们就把刚刚下载的数据删除一个类别,重新重复一遍刚才的过程,在下面的过程中我们需要修改一些代码。
1.准备工作:
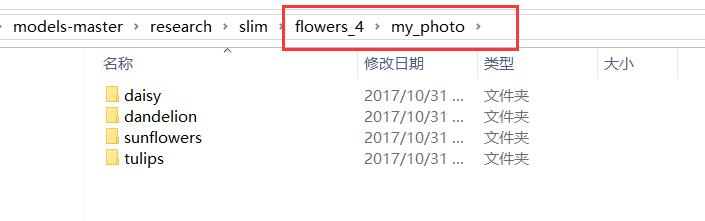
把之前下载并解压的flower_photos文件夹复制到新建的flower_4文件夹中,把玫瑰的数据删掉,这样我们的数据就变成了4分类,图片总数为3028个,顺便把flower_photos文件夹的名字改成my_photo。
2.转化TFRecord文件:
修改download_and_convert_flowers.py文件代码如下:
43行_NUM_VALIDATION = 300 验证集的图片数量
49行_NUM_SHARDS = 4 TFRecord的数量
83行flower_photos换成my_photo 数据的文件夹名称
注释190行 不再下载数据集
注释210行 不删除压缩文件和解压缩后的文件
命令行换成如下,然后执行:
python download_and_convert_data.py --dataset_name=flowers --dataset_dir=D:/models-master/research/slim/flowers_4
再回到floewers_4文件夹中,我们就可以看到下面这些东西,我们放进去的my_photo文件,8个TFRecord文件和一个labels文件。
3.迁移Inception-V4训练新任务:
修改文件flowers.py代码如下:
34行SPLITS_TO_SIZES= 'train': 2728, 'validation': 300 数据个数
36行 _NUM_CLASSES= 4 类别数
修改命令行执行train_image_classifier.py文件:
python train_image_classifier.py
--dataset_name=flowers
--dataset_dir=D:/models-master/research/slim/flowers_4
--checkpoint_path=D:/models-master/research/slim/pre_train/inception_v4.ckpt
--model_name=inception_v4
--checkpoint_exclude_scopes=InceptionV4/Logits,InceptionV4/AuxLogits/Aux_logits
--trainable_scopes=InceptionV4/Logits,InceptionV4/AuxLogits/Aux_logits
--train_dir=D:/models-master/research/slim/flowers_4/my_train
--learning_rate=0.001
--learning_rate_decay_factor=0.76
--num_epochs_per_decay=50
--moving_average_decay=0.9999
--optimizer=adam
--ignore_missing_vars=True
--batch_size=32
4.准确率验证:
测试新的数据,不需要修改代码,改下命令行就可以了:
python eval_image_classifier.py
--dataset_name=flowers
--dataset_dir=D:/models-master/research/slim/flowers_4
--dataset_split_name=validation
--model_name=inception_v4
--checkpoint_path=D:/models-master/research/slim/flowers_4/my_train
--eval_dir=D:/models-master/research/slim/flowers_5/validation_result
--batch_size=32

可以看到,由于我们的数据少了1分类,top1也上升到了24%。
到这里,我们只修改了7行代码和对应的命令行文件就完成一个从数据准备到最后测试的过程,当代码跑通之后,我们就可以回去看源码了,然后可以重新组织和修改代码建立一个自己的工程。
扫描个人微信号,
拉你进机器学习大牛群。
福利满满,名额已不多…

以上是关于应用TF-Slim快速实现迁移学习的主要内容,如果未能解决你的问题,请参考以下文章
容器云原生DevOps学习笔记——第二期:如何快速高质量的应用容器化迁移